Command Palette
Search for a command to run...
Avec Une Précision d'estimation De Profondeur Atteignant 0,9, Meta a Proposé VLM³, Démontrant Que Les Modèles Visuels Sont Intrinsèquement Capables d'apprendre La 3D Et De Réaliser Une Modélisation Unifiée Pour De Multiples Tâches Basée Sur Qwen3-VL-4B.

La perception spatiale tridimensionnelle est une capacité fondamentale dans des domaines tels que la conduite autonome, la robotique et la reconstruction 3D. Son objectif est de reconstituer la structure spatiale, les informations d'échelle et les relations géométriques du monde réel à partir d'images bidimensionnelles. Comparée aux tâches de vision bidimensionnelle telles que la classification d'images et la détection d'objets,La perception tridimensionnelle requiert non seulement des capacités de compréhension sémantique, mais aussi un raisonnement spatial précis et une modélisation géométrique.C’est pourquoi elle est considérée depuis longtemps comme l’une des pistes de recherche les plus stimulantes dans le domaine de la vision par ordinateur.
Ces dernières années, les modèles visuels et de langage (VLM) ont réalisé des progrès significatifs dans les tâches 2D telles que la classification, la détection et la segmentation grâce à leur architecture unifiée et à leur pré-entraînement à grande échelle. Cependant, dans les tâches fines exigeant un raisonnement spatial précis, comme l'estimation de profondeur, la mise en correspondance de pixels et la détermination de la pose de la caméra, les performances des VLM standard restent inférieures à celles des modèles 3D spécialisés. Actuellement,Le domaine de la vision 3D n'a pas encore développé de modèle de base universel comparable à celui de la vision 2D. Les méthodes courantes reposent encore sur des modèles experts conçus pour des tâches spécifiques.Cela inclut des structures de réseau spécialisées, des fonctions de perte et des stratégies d'entraînement.
Des recherches récentes ont montré que le modèle de langage visuel (VLM) standard, sans modifications 3D spécifiques, présente déjà une certaine capacité de perception de la profondeur au niveau du pixel. Ce phénomène suggère que les modèles de langage visuel généralistes pourraient posséder des capacités de représentation 3D plus performantes qu'on ne le pensait, et soulève une question qui mérite d'être approfondie : le VLM standard peut-il gérer un plus large éventail de tâches de perception 3D fines sans introduire d'encodeurs, d'indices visuels ou de modules spécifiques supplémentaires ?
Pour résoudre ce problème,Meta, en collaboration avec l'Université de Princeton, a proposé le cadre VLM³ (VLM Cubed).S’appuyant sur le modèle de langage visuel standard, cette étude propose une modélisation unifiée pour quatre types de tâches : la compréhension 3D au niveau objet, l’estimation de profondeur métrique, la mise en correspondance de pixels et la résolution de la pose de la caméra, grâce à une méthode d’organisation des données et un paradigme d’apprentissage unifiés. Elle évalue également de manière systématique les limites de capacité du modèle de langage visuel standard en matière de perception 3D fine.
Les résultats de recherche associés, intitulés « VLM3 : Les modèles de langage visuel sont des apprenants 3D natifs », ont été publiés sur la plateforme de prépublication arXiv.
Points saillants de la recherche :
* Sur le benchmark SpatialRGPT, le VLM³-4B surpasse le SpatialRGPT-8B plus grand avec une architecture plus rationalisée, ne nécessitant aucun encodeur supplémentaire.
* Comparé au précédent meilleur modèle de langage visuel, DepthLM-7B, VLM³-4B améliore la précision moyenne δ₁ de 0,84 à 0,90, atteignant des performances comparables à celles du modèle d'estimation de profondeur professionnel UnidepthV2.
* VLM³ réduit l'erreur de point final (EPE) des modèles de langage visuel de base d'un ordre de grandeur, surpassant les modèles experts classiques tels que DKM et RoMa.
* VLM³ améliore considérablement la métrique AUC₃₀° d'un niveau quasi aléatoire de 5% à 94%, surpassant VGGT et atteignant un niveau comparable à DA3-Giant.
Voir le document :
https://hyper.ai/papers/2605.30561
Ensembles de données hybrides pour la perception 3D multitâche
Les tâches de perception 3D impliquent divers facteurs tels que l'échelle de la scène, les changements de point de vue, les paramètres de la caméra et les relations géométriques, ce qui exige une qualité et une couverture élevées des données d'entraînement. Afin de faciliter l'apprentissage de capacités de représentation 3D unifiées,Cette étude construit un système de données hybride couvrant des scènes à vue unique et à vues multiples, englobant trois types de tâches : l’estimation de profondeur métrique, la compréhension 3D au niveau de l’objet, et la correspondance des pixels et l’estimation de la pose de la caméra.
Dans la tâche d'estimation de profondeur métriqueLes chercheurs ont utilisé un vaste ensemble de données hybrides multi-scènes. Les données de base proviennent de DepthLM et incluent des données de scènes 3D courantes telles que Argoverse2, Waymo, NuScenes, ScanNet++, Taskonomy, HM3D et Matterport3D. De plus, 10 millions d'images de scènes de rue extérieures, créées spécifiquement pour ce projet, ont été ajoutées, portant ainsi la taille de l'ensemble d'entraînement de 16 à 26 millions d'images.L'entraînement du modèle final a utilisé environ 32 millions d'images et 320 millions d'annotations de profondeur.Il couvre une variété de scénarios, notamment des scènes d'intérieur, d'extérieur, de rue et des environnements ouverts complexes.
Contrairement aux travaux existants, VLM³ n'utilise pas de stratégie d'échantillonnage uniforme. Au lieu de cela, il conçoit des pondérations d'entraînement différenciées en fonction de la taille de l'ensemble de données, de la difficulté d'apprentissage et de la capacité de généralisation. Les expériences montrent que les petits ensembles de données sont plus sujets au surapprentissage lors d'un entraînement mixte, et qu'une simple augmentation du nombre de sources de données n'entraîne pas nécessairement d'amélioration des performances. Par conséquent, l'équipe de recherche a réduit de manière appropriée les pondérations d'entraînement de certains petits ensembles de données afin d'améliorer la capacité de généralisation globale.
La tâche de compréhension 3D au niveau objet utilise le même ensemble de données standard que SpatialRGPT.Il comprend environ un million d'images d'entraînement ainsi que des exemples de questions-réponses qualitatives et quantitatives. Cet ensemble de données est devenu une référence importante pour les tâches actuelles de compréhension 3D au niveau objet. Un grand nombre d'images ne comportent pas d'informations intrinsèques à la caméra, ce qui les rapproche des scénarios d'application réels et reflète ainsi plus fidèlement les capacités de raisonnement spatial du modèle.
Pour les tâches de correspondance de pixels et d'estimation de la pose de la caméra, l'équipe de recherche a construit un ensemble de données d'entraînement multivue unifié.Ce jeu de données intègre 14 sources de données majeures, dont BlendedMVS, DynamicReplica, SailVOS3D et ScanNet++, et contient environ 9,9 millions de paires d'images. Afin de garantir la qualité de l'entraînement, les chercheurs n'ont conservé que les échantillons présentant un chevauchement visuel supérieur à 251 TP3T entre les images et ont réservé 30 scènes indépendantes de ScanNet++ comme ensemble de test dédié, évitant ainsi toute fuite de données entre les ensembles d'entraînement et de test. Les pondérations du jeu de données sont configurées en fonction du nombre initial de paires d'images de chaque source, ce qui renforce la stabilité et l'adaptabilité du processus d'entraînement.
Modèle VLM³ : Apprentissage 3D unifié selon le principe de modification minimale
L'objectif de VLM³ n'est pas de concevoir une nouvelle architecture de vision 3D, mais d'évaluer ses capacités potentielles pour des tâches 3D de haute précision, tout en conservant la structure originale des modèles de langage visuel standard. Par conséquent, l'ensemble du cadre respecte le principe de modification minimale, sans introduire d'encodeurs supplémentaires, de fonctions de perte propriétaires ni de modules spécifiques à une tâche.L'accent est plutôt mis sur l'optimisation de trois aspects : la représentation des données d'entrée, les méthodes de positionnement spatial et les stratégies d'organisation des données.
Cette étude utilise Qwen3-VL-4B comme modèle de base et emploie le paradigme standard d'ajustement fin supervisé (SFT) tout au long du processus d'entraînement, assurant ainsi la cohérence avec le flux de travail de pré-entraînement et d'ajustement fin des modèles de langage visuel existants. Cette conception garantit la compatibilité directe du cadre avec les principaux systèmes de modélisation du langage visuel sans nécessiter la création d'un pipeline d'entraînement dédié supplémentaire.
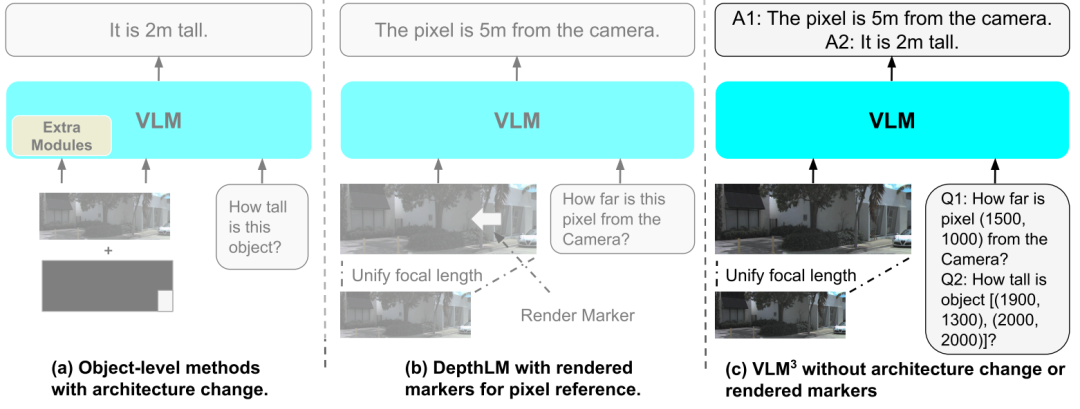
Premièrement, concernant le problème des paramètres de caméra incohérents entre différentes sources de données,VLM³ propose une stratégie unifiée de normalisation des images.Des recherches ont montré que des différences significatives existent souvent entre les paramètres intrinsèques des caméras des ensembles de données 3D multi-sources, certaines images de réseaux étant même dépourvues d'informations sur ces paramètres. Cela affecte directement la capacité du modèle à apprendre les relations géométriques spatiales. Par conséquent,Ce cadre de travail mappe toutes les images d'entrée sur un espace de longueur focale standard et estime les paramètres intrinsèques manquants à l'aide de modèles d'étalonnage d'image unique existants.Cela réduit le décalage de distribution causé par les différences de conditions d'imagerie.
Deuxièmement,VLM³ adopte un paradigme unifié de positionnement spatial textuel.Les modèles de vision 3D traditionnels s'appuient généralement sur des indices visuels supplémentaires, des marqueurs rendus ou des modules d'encodage positionnel spécialement conçus pour réaliser une localisation au niveau du pixel. VLM³, en revanche, normalise les coordonnées de l'image dans un espace de coordonnées unifié et exprime les relations positionnelles sous forme textuelle. De cette manière, le modèle peut exploiter les capacités natives de modélisation du langage pour effectuer la localisation au niveau du pixel, la localisation de régions et l'apprentissage de la correspondance entre les vues sans introduire de modules visuels supplémentaires. Simultanément, une seule image peut contenir plusieurs exemples de réponses aux questions de localisation, ce qui améliore considérablement l'efficacité de l'entraînement. Dans les tâches d'estimation de profondeur,La quantité de signal de supervision qu'un seul échantillon peut fournir est environ 10 fois supérieure à celle des schémas traditionnels, tandis que le coût de calcul reste quasiment inchangé.
Le troisième élément de conception principal est une stratégie sophistiquée de mélange de données.Contrairement à de nombreuses méthodes qui s'appuient sur des structures de réseau complexes pour améliorer les performances, VLM³ concentre ses efforts d'optimisation sur l'organisation des données. Grâce à de nombreuses expériences, l'équipe de recherche a constaté qu'augmenter la taille des données sans discernement ou utiliser un entraînement mixte à pondération égale conduit souvent à une saturation, voire à une dégradation, des performances. En revanche, la conception de stratégies d'échantillonnage différenciées, basées sur la taille des données et les caractéristiques de la tâche, permet d'améliorer plus efficacement les capacités de représentation tridimensionnelle du modèle. Par conséquent, l'allocation des données est considérée comme un élément crucial de l'ensemble du cadre, et non comme un simple facteur auxiliaire du processus d'entraînement.
D'après le modèle ci-dessusVLM³ permet en outre une modélisation unifiée pour quatre types de tâches 3D.L'estimation de profondeur construit des échantillons supervisés par localisation textuelle des pixels ; la compréhension 3D au niveau de l'objet utilise des boîtes de coordonnées textuelles au lieu d'encodeurs de masque dédiés ; la mise en correspondance des pixels transforme les correspondances entre vues en problèmes de prédiction de coordonnées ; et l'estimation de la pose de la caméra décompose les paramètres géométriques complexes en formats de questions-réponses textuels tels que la distance de translation, la direction de translation et l'angle de rotation. Les tâches qui reposaient initialement sur différents modèles de traitement sont finalement unifiées dans le cadre génératif autorégressif du VLM standard.
Pour la première fois, le modèle de langage visuel standard a permis une compréhension 3D de haute précision sur de multiples tâches 3D fines.
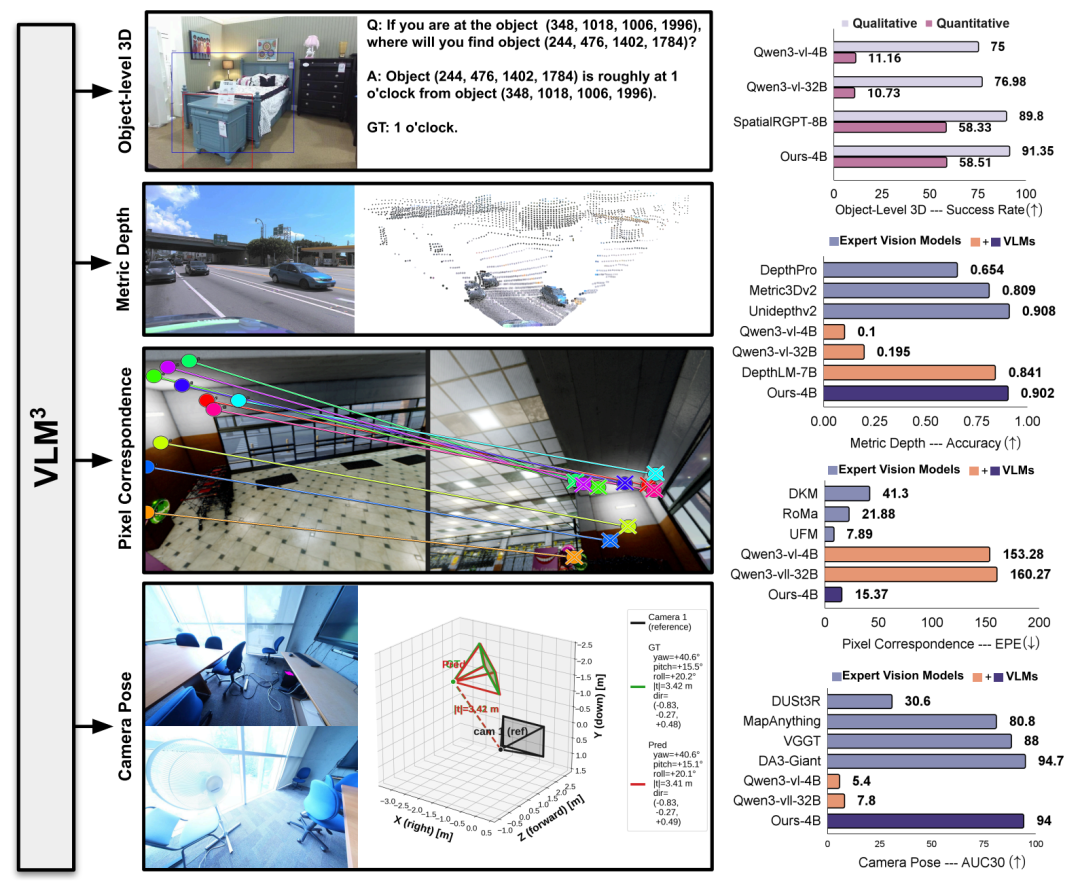
Afin d’évaluer systématiquement l’efficacité de VLM³,L'équipe de recherche a mené des expériences sur quatre types de tâches : l'estimation de la profondeur métrique, la compréhension 3D au niveau de l'objet, la correspondance des pixels et l'estimation de la pose de la caméra.Il est comparé aux modèles de langage visuel généraux et aux modèles experts dominants actuels.
Dans la tâche d'estimation de profondeur métriqueL'étude sélectionne neuf ensembles de données publics pour les comparer à un VLM général et les évalue par rapport au modèle expert de pointe actuel sur cinq benchmarks représentatifs.En utilisant δ₁ comme principal critère d'évaluation, les résultats sont présentés dans le tableau ci-dessous. VLM³-4B surpasse nettement la méthode de référence précédente, DepthLM-7B.La précision moyenne est passée de 0,84 à 0,90, établissant un nouveau record sur plusieurs ensembles de données.Dans le même temps, ses performances globales ont atteint le niveau des modèles professionnels d'estimation de profondeur tels que UnidepthV2 et MoGe-2.
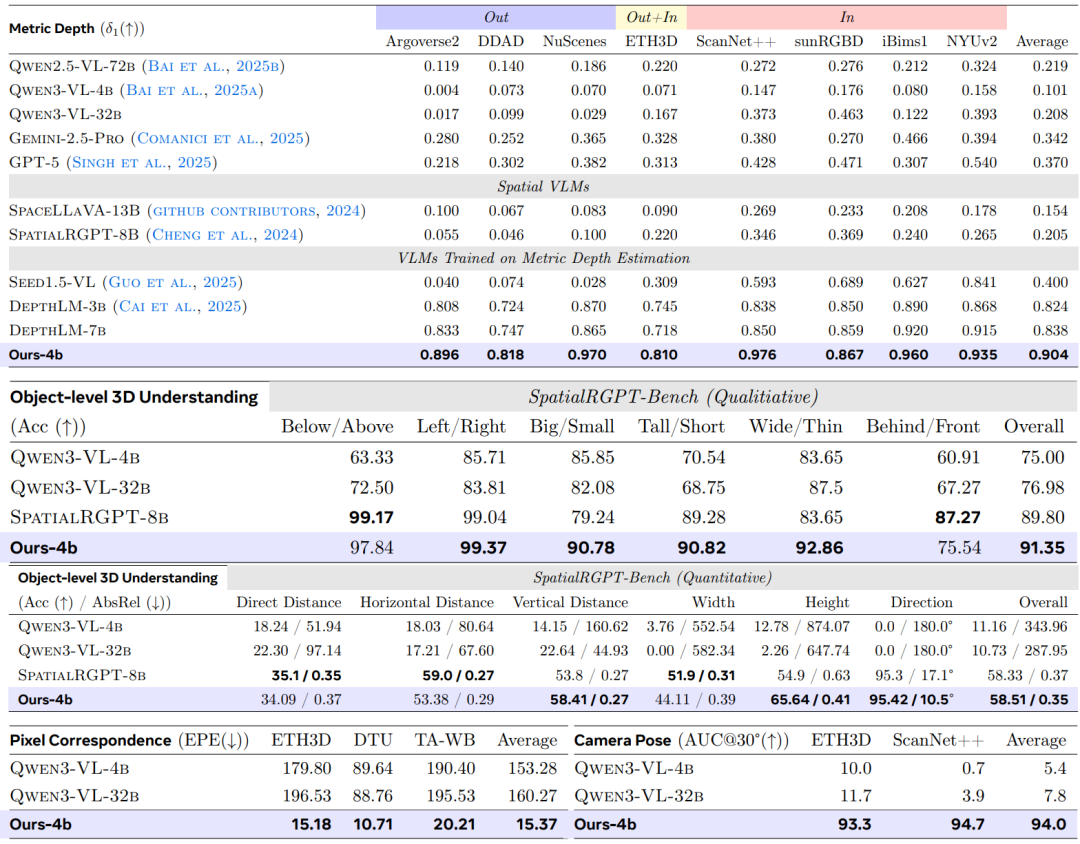
Dans la tâche de compréhension 3D au niveau objet, l'étude a intégralement réutilisé le cadre d'évaluation de SpatialRGPT. Les résultats montrent que…Le VLM³, avec une taille de paramètre de seulement 4B, surpasse le SpatialRGPT, qui a une taille de 8B, dans les évaluations qualitatives et quantitatives.Ce dernier s'appuie sur un encodeur de masque supplémentaire pour compléter la localisation spatiale, tandis que VLM³ peut obtenir de meilleurs résultats en s'appuyant uniquement sur le mécanisme de localisation de texte unifié, indiquant que la modélisation textuelle unifiée a une grande efficacité dans les tâches de raisonnement spatial.
La tâche de correspondance de pixels utilise le système d'évaluation UFM, avec l'erreur de point final (EPE) comme métrique principale. Les résultats expérimentaux montrent que VLM³ réduit l'erreur d'un ordre de grandeur par rapport à VLM de base, surpasse les modèles experts classiques tels que DKM et RoMa, et se situe légèrement en dessous de la méthode de pointe actuelle, UFM. Ceci indique que…L'approche de modélisation unifiée basée sur le texte n'est pas seulement applicable aux scènes à vue unique, mais peut également apprendre efficacement les correspondances géométriques entre les vues.
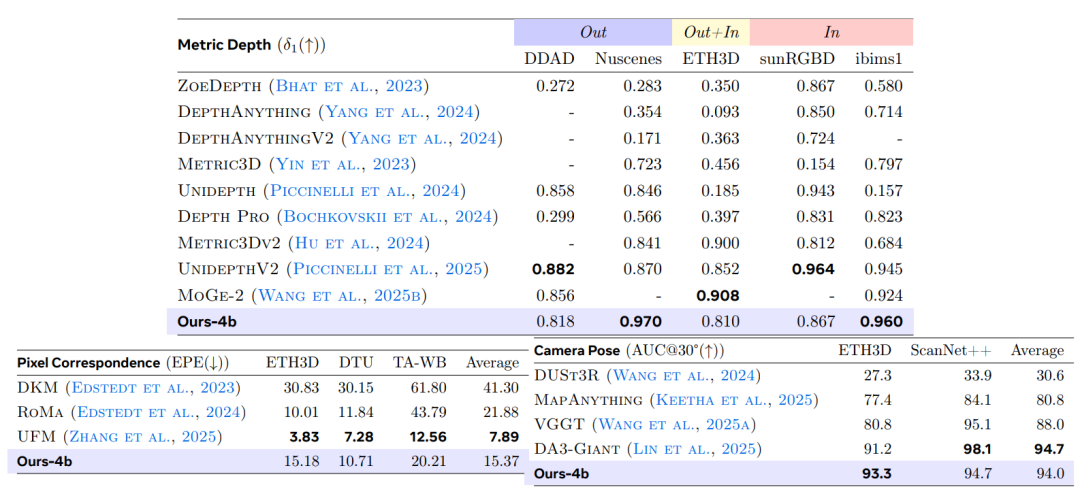
Pour l'estimation de la pose de la caméra, l'étude utilise la métrique AUC₃₀° pour l'évaluation sur les jeux de données ETH3D et ScanNet++. Les résultats montrent que…VLM³ améliore les performances du VLM de base, passant de niveaux de prédiction quasi aléatoires à une AUC₃₀° de 94%.Elle surpasse les méthodes courantes telles que VGGT et MapAnything, et se rapproche du niveau de performance du meilleur modèle actuel, DA3-Giant.
Derniers mots
Pendant longtemps, la recherche en vision 3D a principalement suivi une approche « axée sur la tâche » : la conception de modèles dédiés à différentes tâches telles que l’estimation de profondeur, la mise en correspondance de pixels ou la résolution de poses. VLM³, cependant, démontre une autre possibilité : sans introduire d’encodeurs supplémentaires, de fonctions de perte propriétaires ou de mécanismes complexes de repérage visuel, un modèle de langage visuel standard peut atteindre des performances comparables, voire supérieures, à celles de certains modèles experts sur de multiples tâches 3D fines, simplement grâce à un traitement d’image standardisé, une modélisation spatiale textuelle et des stratégies de données affinées. Ce résultat de recherche suggère que les capacités de représentation 3D d’un modèle de langage visuel général peuvent largement dépasser les attentes précédentes et fournit de nouvelles preuves empiriques du passage, en vision 3D, d’une « optimisation spécifique à la tâche » à un « modèle de base unifié ».