Command Palette
Search for a command to run...
ICLR 2026 | Réduction De 125 Fois Du Nombre De Paramètres Entraînables Par Tâche ! La Nouvelle Méthode Task Tokens Aide l'intelligence Incarnée À Améliorer Sa Capacité À Gérer Des Tâches complexes.

Ces dernières années, les progrès de l'apprentissage par imitation dans le domaine du contrôle robotique ont favorisé le développement des modèles de base comportementaux (BFM) basés sur les Transformers, permettant un contrôle multimodal d'agents humanoïdes intelligents. Ces modèles génèrent des solutions à partir d'objectifs ou d'indices généraux, comme guider un robot vers une coordonnée précise en fonction de la position de son bassin. Si les BFM excellent dans la génération de comportements robustes avec des exemples initiaux, ils nécessitent souvent une ingénierie sophistiquée des impulsions lors de l'exécution de tâches spécifiques, ce qui peut conduire à des résultats sous-optimaux.
Dans ce contexte,Une équipe de recherche du Technion – Institut de technologie d'Israël – a proposé une méthode appelée Task Tokens, qui permet d'adapter efficacement BFM à des tâches spécifiques tout en conservant sa flexibilité.Comparée aux méthodes de référence standard, la nouvelle méthode permet de réduire jusqu'à 125 fois le nombre de paramètres entraînables par tâche et d'améliorer jusqu'à 6 fois la vitesse de convergence.
Parallèlement, les chercheurs ont validé l'efficacité des Task Tokens dans diverses tâches (y compris dans des scénarios hors distribution) et démontré leur compatibilité avec d'autres méthodes d'incitation. Les résultats expérimentaux montrent que les Task Tokens, tout en conservant leurs capacités de généralisation, constituent une solution prometteuse pour adapter la modélisation basée sur les processus (BFM) à des tâches de contrôle spécifiques.
Les résultats de recherche connexes, intitulés « Task Tokens : une approche flexible pour adapter les modèles de base du comportement », ont été acceptés pour ICLR 2026.
Points saillants de la recherche :
* Adaptation spécifique à la tâche : Les jetons de tâche adaptent MaskedMimic (GC-BFM) à des tâches spécifiques grâce à un contrôle tokenisé, sans nécessiter de réglage fin du modèle de base, tout en conservant sa capacité zéro-shot.
* Paradigme de contrôle hybride : permet une intégration transparente des connaissances a priori de haut niveau définies par l’utilisateur (telles que du texte ou des objectifs conjoints) avec l’optimisation de l’apprentissage basée sur la récompense.
* Capacité de performance et de généralisation : Elle est comparable à la méthode de réglage fin complet en termes de performance de la tâche, tout en surpassant les autres méthodes en termes de robustesse aux changements de la dynamique environnementale (tels que la gravité et le frottement).

Adresse du document :
https://hyper.ai/papers/2503.22886
Consultez d'autres articles de pointe sur l'IA :
Objectif : Tester la généralité du modèle dans une série de scénarios proches de la réalité.
L’étude a conçu un ensemble de tâches standardisées pour tester la généralité et l’adaptabilité du modèle dans une gamme de scénarios proches de la réalité, chaque tâche introduisant différents niveaux de complexité dans le problème de contrôle.
Direction (marcher dans une direction spécifique)
Cette tâche consiste à faire se déplacer le personnage dans une direction précise afin de tester les capacités du modèle en matière de contrôle de la marche et d'alignement sur la cible. Le critère de réussite est que, pendant la durée de la mesure, l'écart de vitesse du modèle humanoïde par rapport à la direction cible ne dépasse pas 20% de la vitesse cible.
Pilotage
Cette tâche exige qu'un modèle humanoïde se déplace dans une direction précise tout en maintenant son bassin orienté dans une direction spécifique. Elle permet de tester des capacités de contrôle de mouvement plus fines et introduit des scénarios plus complexes. Le critère de réussite est que le personnage maintienne un écart de vitesse par rapport à la direction cible inférieur ou égal à 20%, tandis que son écart d'orientation total ne dépasse pas 45°.
Atteindre
Dans cette tâche, le modèle humanoïde doit atteindre un point de coordonnées précis avec sa main droite. Cela exige une grande précision de mouvement. Le critère de réussite est que la distance entre la position de la main droite et la position cible soit inférieure à 20 centimètres.
Grève
La tâche consiste à se rendre à proximité de la cible, puis à la faire tomber. Elle évalue non seulement la capacité de marche, mais aussi des comportements complexes liés à la réalisation d'une tâche, comme la gestion du temps et la perception spatiale. La réussite est obtenue lorsque la cible est renversée et inclinée selon une certaine posture, son angle de déviation ne dépassant pas 78° environ.
Saut en longueur
Le personnage doit courir dans un tunnel d'un mètre de large, franchir une ligne 20 mètres plus loin, puis sauter et ne plus toucher le sol après avoir franchi la ligne de départ. La réussite est conditionnée par un saut d'au moins 1,5 mètre.
Solution d'adaptation des tâches efficace basée sur l'architecture MaskedMimic
La méthode proposée dans cette étude repose sur un modèle de base de comportement conditionné par un objectif (GC-BFM) appelé MaskedMimic. Contrairement aux méthodes GCRL traditionnelles qui s'appuient sur des signaux de récompense pour l'apprentissage,MaskedMimic combine l'architecture Transformer et effectue un masquage aléatoire sur les futures cibles utilisées comme jetons d'entrée.Cela permet l'apprentissage et la reproduction de comportements semblables à ceux des humains à partir de multiples modalités, telles que les positions articulaires futures, les instructions textuelles et les objets interactifs.
Cette combinaison d'architecture et de mécanismes de contrôle fait de MaskedMimic une base idéale pour l'approche des jetons de tâche ; de plus, les chercheurs améliorent encore ses capacités en apprenant des jetons spécifiques à la tâche afin d'optimiser les performances des tâches en aval.
Jetons de tâche
Comme le montre le schéma ci-dessous, Task Tokens intègre trois types de sources d'entrée :
* Jeton Prior : Entrée facultative utilisée pour introduire des a priori comportementaux définis par l'utilisateur via des invites textuelles ou des conditions conjointes ;
* Jeton de tâche : généré par un encodeur de tâches entraîné qui traite l’observation cible actuelle ;
* Jeton d'état : représente l'état actuel de l'environnement.
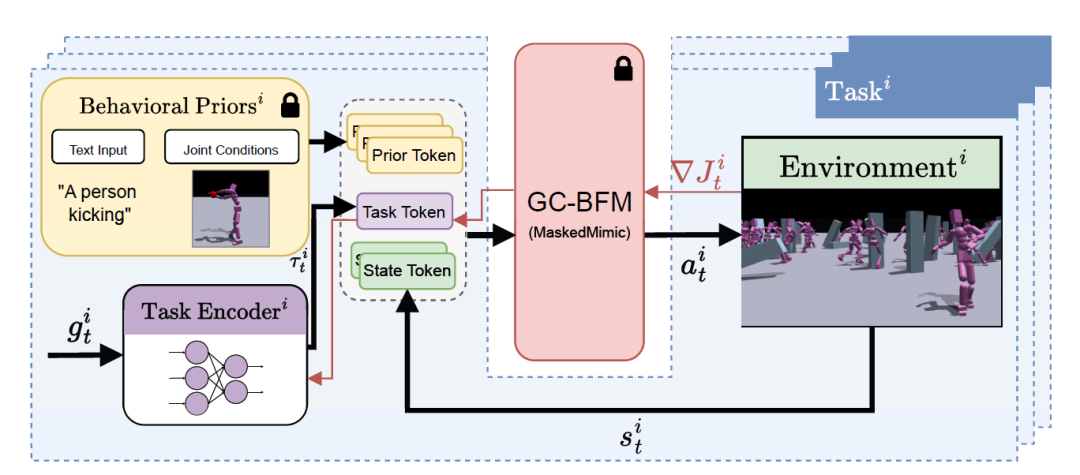
Les chercheurs ont entraîné un encodeur de tâches dédié pour chaque nouvelle tâche afin de générer des jetons uniques correspondants. Ces jetons de tâche encapsulent les exigences et contraintes spécifiques du comportement cible, fournissant des signaux de guidage concis mais informatifs au modèle de base, lui permettant ainsi de générer des sorties qui répondent aux exigences spécifiques de la tâche tout en conservant les connaissances comportementales générales.
Encodeur de tâches
L'encodeur de tâches reçoit des observations définissant l'objectif de la tâche en cours. Ces observations sont représentées en prenant l'agent comme repère, et un jeton de tâche est généré. La forme des observations varie selon la tâche ; par exemple, pour une tâche de virage, les observations incluent la direction de déplacement de la cible, son orientation et sa vitesse souhaitée.
Étant donné que MaskedMimic est entraîné sur la base de cibles de pose futures, l'encodeur de tâches reçoit également des informations proprioceptives pour s'aligner sur la représentation pré-entraînée, générant ainsi des signaux cibles significatifs.
Les chercheurs ont implémenté l'encodeur de tâches sous la forme d'un réseau neuronal à propagation avant. Sa sortie (le jeton de tâche) est concaténée avec d'autres jetons de l'encodeur dans l'espace d'entrée BFM pour former une « phrase » de jetons. Dans cette structure, les jetons produits par l'encodeur de tâches sont équivalents à des « mots » spécialisés servant à guider le modèle dans l'exécution d'une tâche spécifique, tout en préservant le naturel des actions.
Entraînement
Pour adapter l'encodeur de tâches à de nouvelles tâches en aval, les chercheurs ont utilisé l'optimisation de politique proximale (PPO). Lors de l'entraînement, le modèle BFM prédit la distribution de probabilité des actions à partir d'une combinaison de jetons d'entrée, dont le jeton de tâche. La fonction objectif de la PPO est ensuite calculée à partir de la récompense spécifique à la tâche et des probabilités d'action fournies par le modèle BFM, obtenant ainsi les gradients utilisés pour mettre à jour les paramètres de l'encodeur de tâches, tout en maintenant le modèle BFM figé.
Adapter efficacement et de manière efficiente le BFM à des tâches spécifiques
Les chercheurs ont évalué l'efficacité de la méthode des jetons de tâche à travers une série d'expériences approfondies, validant ainsi ses performances et son applicabilité sur quatre aspects clés, et la comparant à plusieurs méthodes de référence concurrentes, notamment :
Entraînement par renforcement pur : utilise uniquement la stratégie d’entraînement PPO et ne dépend d’aucun modèle de base ;
* Réglage fin de MaskedMimic : optimise l’ensemble du modèle MaskedMimic à l’aide du signal de récompense (sans figer les paramètres) ;
* MaskedMimic (condition articulaire uniquement) : Le MaskedMimic original, qui utilise uniquement les conditions articulaires comme mécanisme d'indice ;
* PULSE : Une approche hiérarchique qui réutilise l’espace de compétences latentes dans les données de capture de mouvement ;
* AMP : Utilise un discriminateur pour optimiser les performances des tâches tout en garantissant la qualité de l’action.
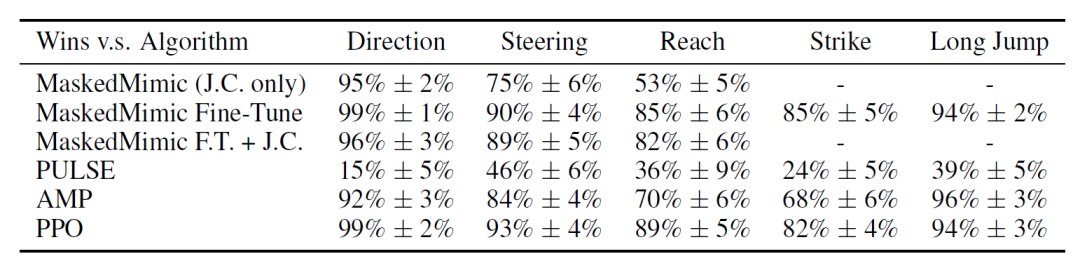
Capacité d'adaptation aux tâches
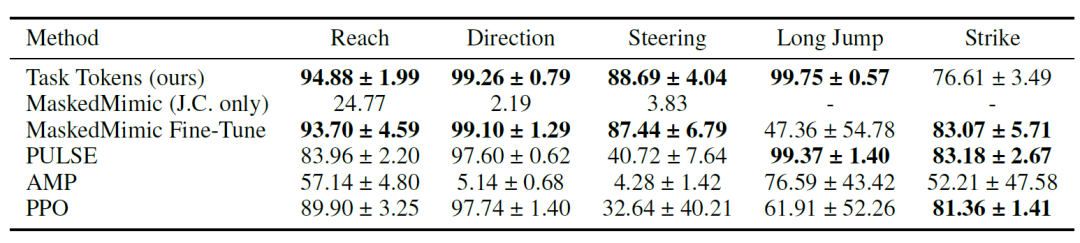
Les chercheurs ont d'abord démontré que les Task Tokens permettent d'adapter efficacement MaskedMimic aux tâches en aval ; les résultats numériques sont présentés dans le tableau ci-dessous. Ces résultats indiquent que…Les Task Tokens ont obtenu des scores élevés dans la plupart des environnements, PULSE, MaskedMimic Fine-Tune et PureRL obtenant les meilleurs scores sur la tâche Strike.
De plus, la figure ci-dessous illustre la courbe de réussite au cours du processus d'entraînement. On constate que Task Tokens converge en environ 50 millions (50M) d'étapes, tandis que PULSE nécessite environ 300 millions (300M) d'étapes pour atteindre les mêmes performances.
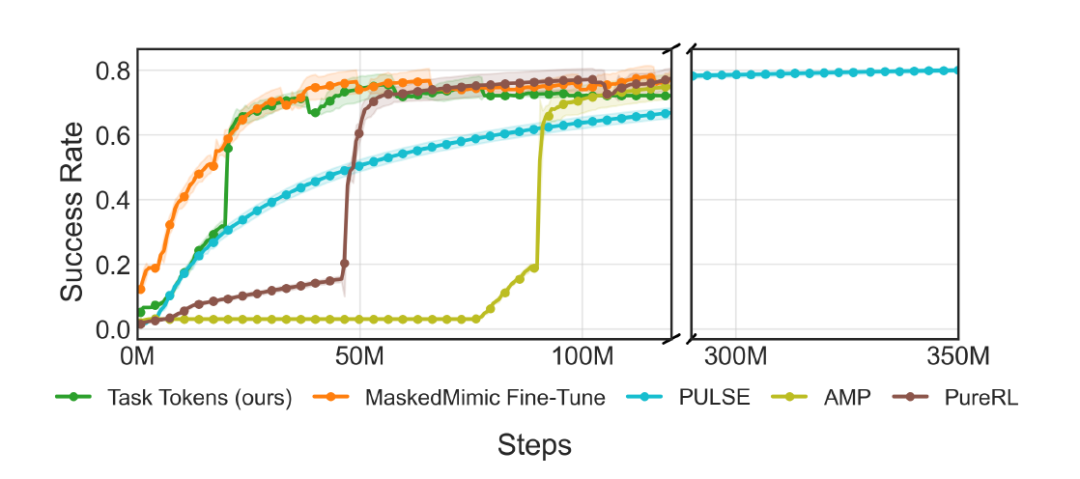
Pour atteindre les résultats ci-dessus,Les Task Tokens ne nécessitent que l'entraînement d'un seul encodeur avec environ 200 000 (~200K) paramètres.PULSE et MaskedMimic Fine-Tune nécessitent respectivement 9,3 millions (9,3M) et 25 millions (25M) de paramètres, soit environ 46,5 fois et 125 fois plus. Cette efficacité est particulièrement cruciale dans les applications concrètes, car l'entraînement de modèles à grande échelle est extrêmement coûteux.
Ces résultats démontrent que les Task Tokens peuvent adapter efficacement des modèles comportementaux fondamentaux tels que MaskedMimic à des tâches nouvelles et inédites.
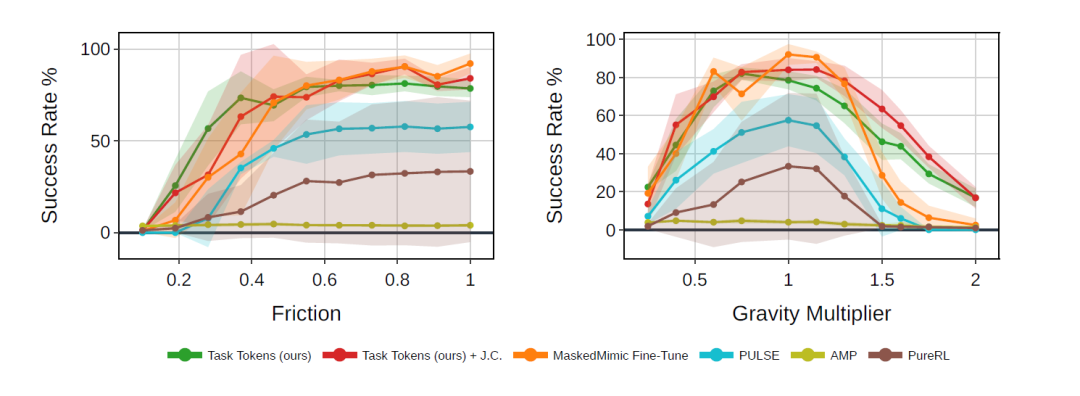
Capacité de généralisation hors distribution (OOD)
Les chercheurs ont mené des expériences comparatives dans des conditions de perturbation hors distribution (OOD), qui ne se sont pas produites lors de l'entraînement du BFM et des Task Tokens d'origine, et ont principalement considéré deux types de changements : la gravité et le frottement du sol.
Les résultats présentés dans la figure ci-dessous montrent que, grâce à BFM,Les jetons de tâche démontrent une robustesse nettement accrue dans des scénarios nouveaux et inédits.Tout d'abord, dans des conditions normales (sans perturbation), Task Tokens offre des performances quasi identiques à celles d'un MaskedMimic parfaitement optimisé et surpasse toutes les autres méthodes de référence. Ensuite, ses performances dépassent largement celles des méthodes de référence à mesure que l'intensité de la perturbation augmente. Notamment, Task Tokens conserve un taux de réussite nettement supérieur même dans des conditions de friction extrêmement faible (par exemple, ×0,4) et de gravité élevée (par exemple, ×1,5).
Étude humaine
Le tableau ci-dessous présente le pourcentage de jetons de tâche sélectionnés comme l'action la plus « humaine » pour chaque méthode de comparaison. Les résultats indiquent que…Les jetons de tâche sont nettement supérieurs à MaskedMimic (JC uniquement) et à MaskedMimic Fine-Tune.Cela indique que les conditions conçues par l'utilisateur présentent certaines caractéristiques hors distribution pour le modèle MaskedMimic de base, et que les Task Tokens constituent un moyen plus efficace de s'adapter à la qualité de l'action par rapport au réglage fin.
De plus, on peut observer que, bien que les Task Tokens soient supérieurs en termes de vitesse de convergence, de taille des paramètres et de performance des tâches, PULSE obtient un score plus élevé en termes de « similarité humaine des actions ».
D’après les résultats ci-dessus, on peut conclure que les Task Tokens offrent un bon équilibre entre efficacité, qualité des actions et robustesse.
Effet d'incitation multimodale
Enfin, les chercheurs ont exploré les effets synergiques des Task Tokens avec d'autres méthodes d'incitation, démontrant ainsi leur bonne compatibilité et leur flexibilité.
Dans la tâche de direction, la fonction de récompense encourage uniquement l'agent à se déplacer dans la bonne direction, sans tenir compte de l'orientation corporelle, similaire à celle d'un humain. Par conséquent, la politique peut converger vers une marche à reculons. Bien que ce comportement génère des récompenses plus élevées et un taux de réussite supérieur, il est clairement contraire aux attentes.
L'image ci-dessous illustre l'introduction de connaissances a priori artificiellement conçues (telles que des contraintes sur la hauteur et l'orientation de la cible de la tête).Le processus d'entraînement peut converger vers un schéma de mouvement de « marche debout ».

Dans la tâche de frappe, l'agent doit atteindre la cible. Un comportement émergent fréquent consiste pour l'agent à reculer jusqu'à la cible, puis à effectuer un mouvement de rotation sur lui-même pour l'atteindre. La figure ci-dessous illustre la combinaison de ces deux modalités.
Tout d'abord, en utilisant des conditions d'orientation similaires à celles d'une tâche de direction, l'agent est amené à toujours faire face à la cible pendant son déplacement. Ensuite, lorsqu'il s'approche de la cible, le texte « une personne effectue un coup de pied » apparaît pour guider l'agent et l'inciter à utiliser son pied pour réaliser le coup de pied.

Les chercheurs ont notamment observé que le réglage fin de l'ensemble du modèle entraîne le problème bien connu de l'oubli catastrophique, ce qui affaiblit sa capacité à retenir et à fusionner les indices multimodaux. À l'inverse, Task Tokens, en figeant le modèle de base, conserve ses capacités d'amorçage pré-entraînées, permettant ainsi aux comportements appris de se fusionner plus systématiquement avec les comportements spécifiés par l'humain.
Conclusion
Les expériences actuelles reposent principalement sur l'architecture MaskedMimic ; les travaux futurs devront valider la généralisabilité de la méthode au sein d'une architecture GC-BFM plus large. Si la conception des récompenses et des observations liées aux tâches dépend encore de l'expertise, les recherches futures pourraient explorer une conception (semi-)automatisée afin de faciliter l'accès à cette technologie. Un axe de recherche majeur consiste à adapter les stratégies basées sur les Task Tokens aux systèmes robotiques réels, à résoudre le problème du passage de la simulation à la réalité et à étendre ces stratégies à des tâches complexes du monde réel exigeant une prise de décision de haut niveau, au-delà des simples simulations d'animation.
Enfin, l'exploration d'architectures d'encodeurs de tâches plus complexes (au-delà de l'architecture actuelle de réseau à propagation directe) pourrait également permettre d'améliorer les performances. La résolution de ces problèmes permettra d'affiner le cadre des jetons de tâches et de favoriser le développement d'agents humanoïdes intelligents plus diversifiés, adaptables et performants.
Références :
https://openreview.net/forum?id=6T3wJQhvc3
https://arxiv.org/pdf/2503.22886








