Command Palette
Search for a command to run...
Utilisation De La Mémoire Réduite jusqu'à 751 TP3T : Des Scientifiques Du Département De l'Énergie Des États-Unis Ont Proposé La Méthode D-CHAG, Une Méthode d'agrégation Hiérarchique Inter-canaux, Pour Permettre l'exécution d'ensembles De Données Multicanaux De Modèles À Très Grande échelle.

Les modèles scientifiques de base basés sur la vision recèlent un immense potentiel pour stimuler la découverte et l'innovation scientifiques, notamment grâce à leur capacité à agréger des données d'images provenant de sources diverses (par exemple, différents scénarios d'observation physique) et à apprendre les corrélations spatio-temporelles à l'aide de l'architecture Transformer. Cependant, la tokenisation et l'agrégation des images sont gourmandes en ressources de calcul, et les méthodes distribuées existantes telles que le parallélisme tensoriel (TP), le parallélisme de séquences (SP) ou le parallélisme de données (DP) n'ont pas encore permis de relever pleinement ce défi.
Dans ce contexte,Des chercheurs du Laboratoire national d'Oak Ridge du département américain de l'Énergie ont proposé une méthode d'agrégation hiérarchique inter-canaux distribuée (D-CHAG) pour les modèles de base.Cette méthode répartit le processus de tokenisation et emploie une stratégie hiérarchique d'agrégation des canaux, permettant ainsi l'exécution de modèles à très grande échelle sur des ensembles de données multicanaux. Les chercheurs ont évalué D-CHAG sur des tâches d'imagerie hyperspectrale et de prévision météorologique, et ont constaté que la combinaison de cette méthode avec le parallélisme tensoriel et le partitionnement du modèle réduisait l'empreinte mémoire jusqu'à 751 TP3T sur le supercalculateur Frontier et permettait d'obtenir des améliorations de débit soutenues de plus de 2x sur un maximum de 1 024 GPU AMD.
Les résultats de recherche pertinents, intitulés « Agrégation hiérarchique distribuée intercanal pour les modèles de base », ont été publiés dans SC25.
Points saillants de la recherche :
* D-CHAG résout les problèmes de goulot d'étranglement de la mémoire et d'efficacité de calcul dans l'entraînement du modèle de base multicanal.
* Comparé à l'utilisation de TP seul, D-CHAG peut atteindre une réduction de l'empreinte mémoire jusqu'à 70%, permettant ainsi un entraînement de modèle à grande échelle plus efficace.
* Les performances de D-CHAG ont été validées sur deux charges de travail scientifiques : la prévision météorologique et la prédiction du masquage d'images hyperspectrales de plantes.
Adresse du document :
https://dl.acm.org/doi/10.1145/3712285.3759870
Suivez notre compte WeChat officiel et répondez « cross-channel » en arrière-plan pour obtenir le PDF complet.
Utilisation de deux ensembles de données multicanaux typiques
Cette étude a utilisé deux ensembles de données multicanaux typiques pour valider l'efficacité de la méthode D-CHAG :Images hyperspectrales de plantes et données météorologiques ERA5.
Les données d'images hyperspectrales de plantes utilisées pour la prédiction de masques auto-supervisée ont été collectées par le Laboratoire de phénotypage avancé des plantes (APPL) du Laboratoire national d'Oak Ridge (ORNL).L'ensemble de données contient 494 images hyperspectrales de peupliers, chacune contenant 500 canaux spectraux couvrant des longueurs d'onde de 400 nm à 900 nm.
Ce jeu de données est principalement utilisé pour la recherche sur la biomasse et constitue une ressource importante pour le phénotypage des plantes et la recherche en bioénergie. Ces images servent à l'apprentissage auto-supervisé masqué, où des segments d'image sont utilisés comme jetons pour le masquage. Le modèle doit prédire le contenu manquant, apprenant ainsi la distribution des données sous-jacentes des images. Il est à noter que ce jeu de données n'utilise aucun poids pré-entraîné et est entièrement entraîné par apprentissage auto-supervisé, ce qui souligne l'applicabilité de D-CHAG aux tâches d'apprentissage auto-supervisé à grand nombre de canaux.
aussi,Dans cette expérience de prévision météorologique, l'équipe de recherche a utilisé l'ensemble de données de réanalyse haute résolution ERA5.L'étude a sélectionné cinq variables atmosphériques (hauteur géopotentielle, température, composantes u et v de la vitesse du vent, et humidité spécifique) et trois variables de surface (température à 2 m, composante u et composante v de la vitesse du vent à 10 m), couvrant plus de 10 couches de pression et générant un total de 80 canaux d'entrée. Afin de faciliter l'apprentissage du modèle, les données initiales à une résolution de 0,25° (770 × 1440) ont été rééchantillonnées à 5,625° (32 × 64) à l'aide de l'outil xESMF et d'un algorithme d'interpolation bilinéaire.
La tâche du modèle consiste à prédire les variables météorologiques pour les étapes temporelles futures, telles que la hauteur géopotentielle de 500 hPa (Z500), la température de 850 hPa (T850) et la vitesse du vent de la composante 10 m u (U10), vérifiant ainsi les performances de la méthode D-CHAG dans les tâches de prévision de séries temporelles.
D-CHAG : Combinaison de l’agrégation hiérarchique et de la tokenisation distribuée
En résumé, la méthode D-CHAG est une fusion de deux méthodes indépendantes :
Méthode de tokenisation distribuée
Lors du processus de propagation directe, chaque rang TP ne tokenise qu'un sous-ensemble des canaux d'entrée.Avant l'étape d'agrégation des canaux, une opération AllGather doit être exécutée afin d'assurer une attention croisée sur l'ensemble des canaux. Théoriquement, cette méthode permet de réduire la charge de calcul de la tokenisation par GPU.
Agrégation hiérarchique inter-canaux
Le principal avantage de cette approche réside dans la réduction de l'empreinte mémoire par couche d'attention inter-canaux, car moins de canaux sont traités par couche.Cependant, l'augmentation du nombre de couches entraîne une augmentation de la taille globale du modèle et de la consommation de mémoire. Ce compromis est plus avantageux pour les jeux de données comportant un grand nombre de canaux, car l'attention inter-canaux standard induit une surcharge de mémoire secondaire plus importante.
Bien que les deux méthodes présentent des avantages, elles comportent également des inconvénients. Par exemple, la tokenisation distribuée engendre une surcharge de communication importante entre les nœuds TP et ne résout pas le problème de la forte consommation de mémoire au niveau du canal ; quant à elle, l’agrégation hiérarchique inter-canaux augmente le nombre de paramètres du modèle par GPU. La méthode D-CHAG combine ces deux méthodes de manière distribuée, et son architecture globale est illustrée dans la figure ci-dessous :
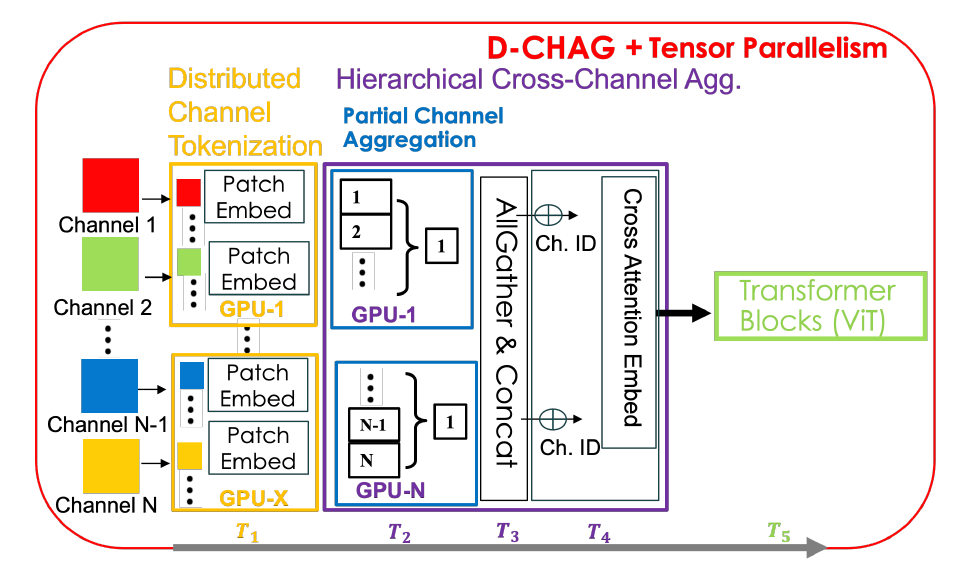
Spécifiquement,Chaque rang TP tokenise les images bidimensionnelles dans le sous-ensemble de canaux total.Chaque GPU ne gérant qu'un sous-ensemble de canaux, l'agrégation de ces canaux est effectuée localement sur ces canaux ; ce module est appelé module d'agrégation partielle de canaux. Une fois l'agrégation de canaux terminée pour chaque rang TP, les sorties sont collectées et l'agrégation finale est réalisée à l'aide d'une attention inter-canaux. Une seule opération AllGather est effectuée lors de la propagation avant ; lors de la rétropropagation, seuls les gradients pertinents pour chaque GPU sont collectés, évitant ainsi des communications supplémentaires.
La méthode D-CHAG peut tirer pleinement parti des avantages de la tokenisation distribuée et de l'agrégation hiérarchique des canaux tout en atténuant leurs inconvénients.En répartissant l'agrégation hiérarchique des canaux entre les niveaux TP, les chercheurs ont limité la communication AllGather au traitement d'un seul canal par niveau TP, éliminant ainsi toute communication nécessaire lors de la rétropropagation. De plus, en augmentant la profondeur du modèle, ils ont conservé l'avantage d'un traitement réduit des canaux par couche, tout en répartissant des paramètres supplémentaires entre les niveaux TP grâce à des modules d'agrégation partielle des canaux.
L'étude a comparé deux stratégies de mise en œuvre :
* D-CHAG-L (Couche linéaire) : Le module d'agrégation hiérarchique utilise une couche linéaire, qui a une faible consommation de mémoire et convient aux situations avec un grand nombre de canaux.
* D-CHAG-C (Couche d'attention croisée) : Utilise une couche d'attention croisée, qui a un coût de calcul plus élevé, mais améliore considérablement les performances pour les très grands modèles ou les nombres de canaux extrêmement élevés.
Résultats : D-CHAG permet d'entraîner des modèles plus grands sur des ensembles de données à grand nombre de canaux.
Après avoir construit D-CHAG, les chercheurs ont validé les performances du modèle, puis ont évalué plus en détail ses performances sur des tâches d'imagerie hyperspectrale et de prévision météorologique :
Analyse des performances du modèle
La figure suivante illustre les performances de D-CHAG sous différentes configurations de modules d'agrégation de canaux partiels :
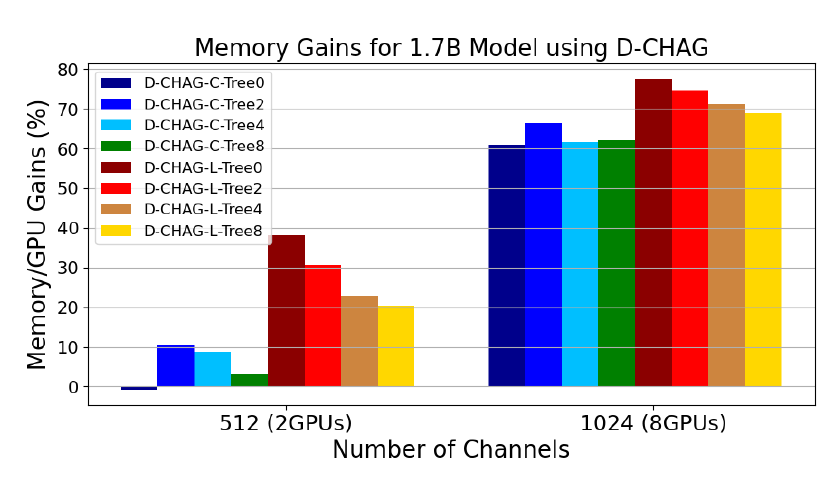
* Tree0 indique qu'il n'y a qu'un seul niveau d'agrégation dans certains modules d'agrégation, Tree2 indique deux niveaux, et ainsi de suite ;
* Les suffixes -C et -L indiquent le type de couches utilisées : -C indique que toutes les couches sont à attention croisée, et -L indique que toutes les couches sont linéaires.
Les résultats montrent :
Pour des données à 512 canaux, les performances de l'utilisation d'une seule couche d'attention croisée sont légèrement inférieures à la référence, mais elles peuvent améliorer les performances d'environ 60% pour des données à 1024 canaux.
À mesure que la structure hiérarchique s'approfondit, même les données à 512 canaux peuvent bénéficier d'améliorations significatives en termes de performances, tandis que les performances des données à 1024 canaux restent relativement stables.
L'utilisation de couches linéaires, même avec une hiérarchie peu profonde, peut améliorer les performances sur les images à 512 et 1024 canaux. En effet, les meilleures performances sont obtenues avec D-CHAG-L-Tree0, qui ne contient qu'une seule couche d'agrégation de canaux. L'ajout de couches d'agrégation augmente le nombre de paramètres du modèle et la consommation de mémoire. Bien qu'augmenter le nombre de couches semble avantageux pour les images à 512 canaux, pour les deux tailles d'images, l'utilisation d'une seule couche linéaire surpasse les configurations plus profondes.
Le D-CHAG-C-Tree0 a un léger impact négatif sur les performances avec deux GPU, mais peut atteindre une amélioration des performances de 60% lorsqu'il est mis à l'échelle à huit GPU.
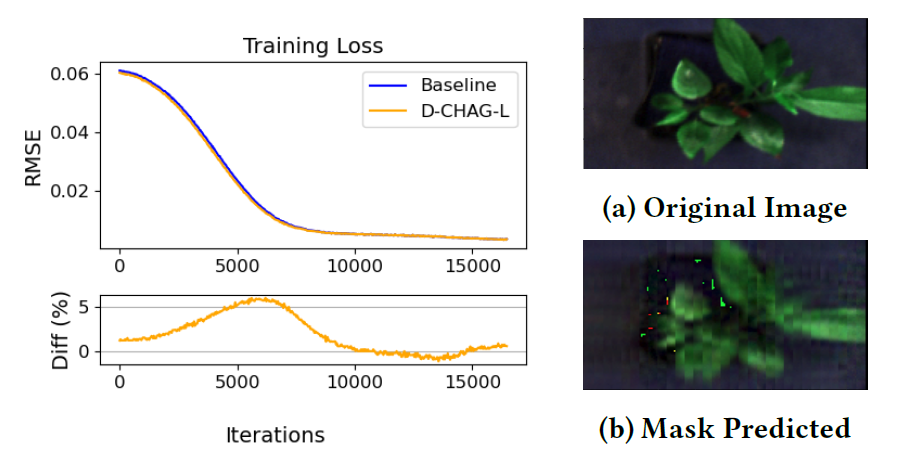
Prédiction auto-supervisée de masques d'images hyperspectrales de plantes
La figure ci-dessous compare la perte d'apprentissage de la méthode de référence et de la méthode D-CHAG dans l'application d'auto-encodeurs de masques d'images hyperspectrales de plantes. Les résultats montrent :Pendant l'entraînement, les performances de perte d'entraînement de l'implémentation mono-GPU sont très cohérentes avec celles de la méthode D-CHAG (exécutée sur deux GPU).
Larry York, chercheur principal au sein du groupe d'imagerie moléculaire et cellulaire du Laboratoire national d'Oak Ridge, a déclaré que le D-CHAG peut aider les botanistes à accomplir rapidement des tâches telles que la mesure de l'activité photosynthétique des plantes directement à partir d'images, remplaçant ainsi les mesures manuelles fastidieuses et chronophages.
Prévisions météorologiques
Des chercheurs ont mené une expérience de prévision météorologique sur 30 jours à partir du jeu de données ERA5. La figure ci-dessous compare la perte d'entraînement et l'erreur quadratique moyenne (RMSE) des trois variables de test de la méthode de référence et de la méthode D-CHAG dans des applications de prévision météorologique :
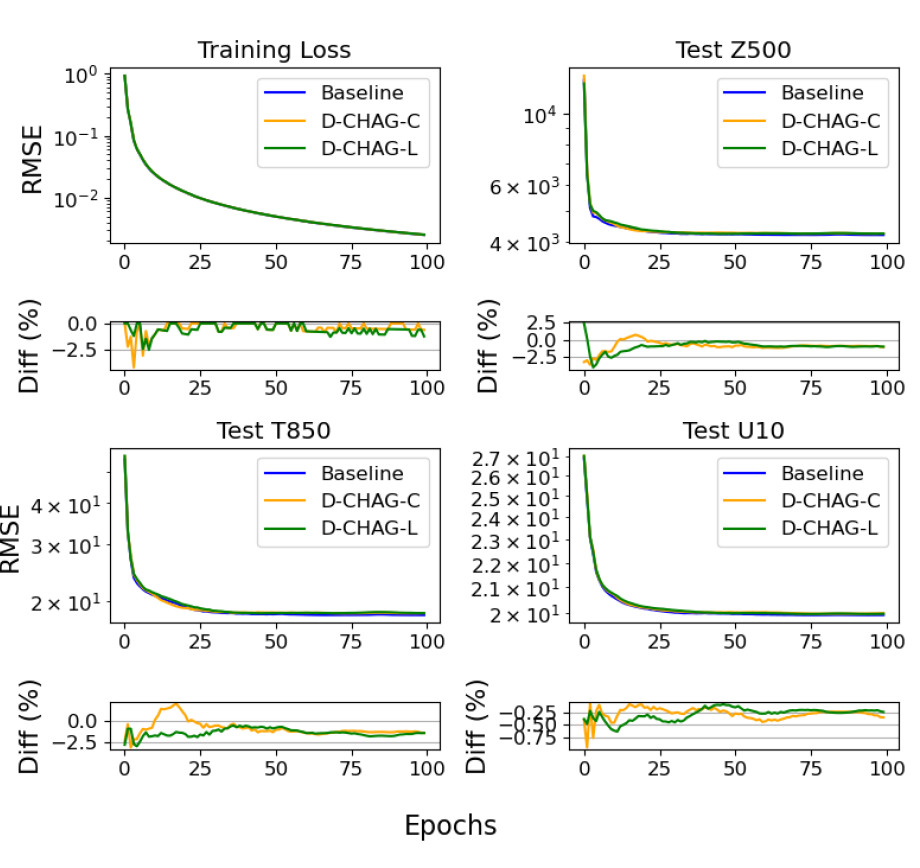
Le tableau ci-dessous présente la comparaison finale du modèle sur les tâches de prédiction à 7, 14 et 30 jours, y compris le RMSE, le MSE et le coefficient de corrélation de Pearson (wACC).
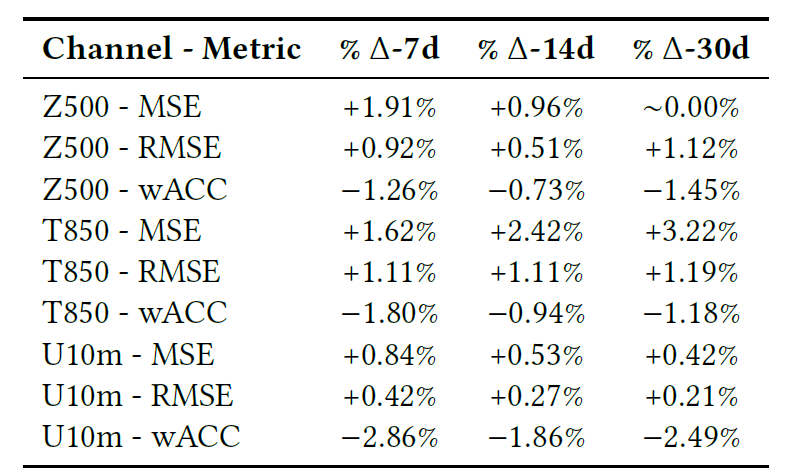
Globalement, d'après les graphiques et les tableaux, la perte d'entraînement est très cohérente avec le modèle de référence, et les écarts des différents indicateurs sont minimes.
Évolution des performances en fonction de la taille du modèle
La figure ci-dessous illustre l'amélioration des performances de la méthode D-CHAG par rapport à l'utilisation exclusive de TP pour trois tailles de modèle avec des configurations de canaux nécessitant TP :
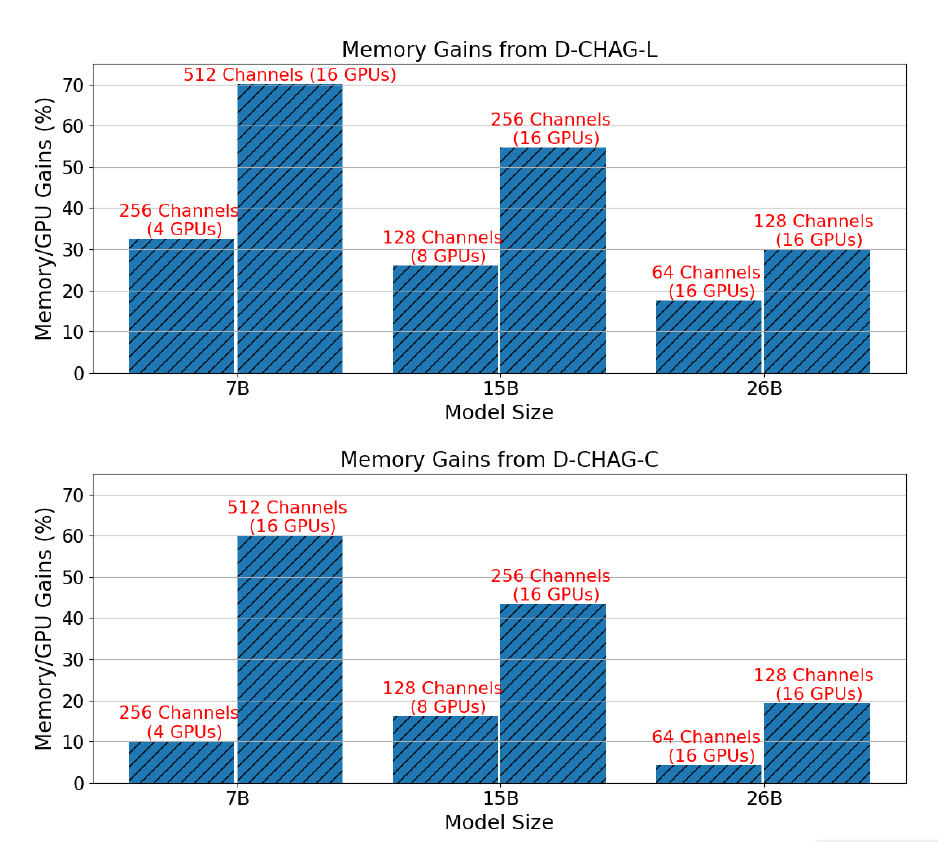
Les résultats montrent quePour le modèle à 7 paramètres,L'utilisation de couches linéaires dans le module d'agrégation de canaux partiels peut permettre une amélioration des performances de 30% à 70%, tandis que l'utilisation de couches d'attention croisée peut permettre une amélioration de 10% à 60%.Pour le modèle à 15B paramètres,Les améliorations de performances dépassent celles de 20% à 50% ;L'amélioration des performances du modèle à 26 paramètres se situe entre 10% et 30%.
De plus, à taille de modèle fixe, le gain de performance est d'autant plus significatif que le nombre de canaux augmente. En effet, dans une architecture donnée, l'augmentation du nombre de canaux n'accroît pas le coût de calcul du bloc transformateur, mais augmente la charge de travail des modules de tokenisation et d'agrégation de canaux.
En revanche, TP seul ne peut pas entraîner des images avec 26 paramètres et 256 canaux, mais la méthode D-CHAG peut entraîner un modèle avec 26 paramètres et 512 canaux en utilisant moins de 80% de mémoire disponible — cela montre que la méthode peut prendre en charge l'entraînement de modèles plus grands sur des ensembles de données à grand nombre de canaux.
ViT : IA visuelle – Des modèles perceptifs aux modèles généraux de fondement visuel
Au cours de la dernière décennie, les modèles de vision par ordinateur se sont principalement concentrés sur l'optimisation monotâche : la classification, la détection, la segmentation et la reconstruction ont été développées indépendamment. Cependant, à l'instar de l'architecture Transformer qui a donné naissance à des modèles fondamentaux tels que GPT et BERT dans le domaine du traitement automatique du langage naturel, le domaine de la vision connaît un changement de paradigme similaire : des modèles spécifiques à une tâche aux modèles fondamentaux de vision à usage général. Dans cette optique, le Vision Transformer (ViT) est considéré comme une pierre angulaire technologique essentielle des modèles fondamentaux de vision.
Vision Transformer (ViT) a été le premier à intégrer pleinement l'architecture Transformer aux tâches de vision par ordinateur. Son principe consiste à traiter une image comme une séquence de patchs et à remplacer la modélisation locale du champ réceptif des réseaux de neurones convolutifs par un mécanisme d'auto-attention. Concrètement, ViT divise l'image d'entrée en patchs de taille fixe, associe à chaque patch un jeton d'intégration, puis modélise les relations globales entre les patchs grâce à un encodeur Transformer.
Comparé aux CNN traditionnels, ViT présente des avantages particuliers pour les données scientifiques : il convient aux données multicanaux de grande dimension (telles que la télédétection, les images médicales et les données spectrales), peut gérer les structures spatiales non euclidiennes (telles que les grilles climatiques et les champs physiques) et convient à la modélisation intercanaux (couplage des relations entre différentes variables physiques), qui est également le problème central abordé dans l’article D-CHAG.
Au-delà des scénarios mentionnés dans l'étude ci-dessus, ViT démontre sa valeur ajoutée dans un nombre croissant de situations. En mars 2025, le Dr Han Gangwen, médecin-chef du service de dermatologie de l'hôpital international de l'université de Pékin, et son équipe ont développé un algorithme d'apprentissage profond appelé AcneDGNet. Cet algorithme intègre un Transformer visuel et des réseaux neuronaux convolutifs afin d'obtenir une table de caractéristiques hiérarchiques plus efficace, permettant ainsi une classification plus précise. Des évaluations prospectives montrent que l'algorithme d'apprentissage profond d'AcneDGNet est non seulement plus précis que celui des dermatologues juniors, mais aussi comparable à celui des dermatologues seniors. Il peut détecter avec précision les lésions d'acné et déterminer leur gravité dans différents contextes de soins, aidant ainsi efficacement les dermatologues et les patients à diagnostiquer et à prendre en charge l'acné, que ce soit lors de téléconsultations ou de consultations en cabinet.
Titre de l'article :
Évaluation d'un modèle de détection et de classification de la gravité des lésions d'acné pour la population chinoise dans des contextes de soins de santé en ligne et hors ligne
Adresse du document :
https://www.nature.com/articles/s41598-024-84670-z
Du point de vue industriel, Vision Transformer marque un tournant décisif dans l'évolution de l'IA visuelle, passant des modèles perceptifs aux modèles visuels fondamentaux à usage général. Son architecture Transformer unifiée offre une base universelle pour la fusion intermodale, l'extension à grande échelle et l'optimisation au niveau système, faisant des modèles visuels une infrastructure essentielle pour l'IA appliquée à la science. À l'avenir, la parallélisation, l'optimisation de la mémoire et les capacités de modélisation multicanaux de Vision Transformer deviendront des facteurs de compétitivité clés, déterminant la rapidité et l'ampleur du déploiement industriel des modèles visuels fondamentaux.
Références :
1.https://phys.org/news/2026-01-empowering-ai-foundation.html
2.https://dl.acm.org/doi/10.1145/3712285.3759870
3.https://mp.weixin.qq.com/s/JvKQPbBQFhofqlVX4jLgSA








