Command Palette
Search for a command to run...
Tutoriel En Ligne | Améliorations De l'analyse Des Formules Et Des Tableaux Dans DeepSeek-OCR 2 : Gain De Performance De Près De 41 TP3T Avec Un Faible Coût De Traitement Visuel

Dans le développement des modèles de langage visuel (MLV), la reconnaissance optique de caractères (OCR) de documents s'est toujours heurtée à des difficultés majeures, telles que l'analyse de la mise en page complexe et l'alignement de la logique sémantique. Les modèles traditionnels utilisent généralement un ordre de balayage raster fixe, de haut en bas et de gauche à droite, pour traiter les jetons visuels. Ce processus rigide contredit le schéma de balayage sémantique du système visuel humain, en particulier lors du traitement de documents contenant des formules et des tableaux complexes, ce qui peut facilement entraîner des erreurs d'analyse dues à la négligence des relations sémantiques. La capacité des modèles à « comprendre » la logique visuelle comme les humains représente une avancée majeure pour l'amélioration de la compréhension des documents.
DeepSeek-AI a récemment lancé DeepSeek-OCR 2, qui fournit les réponses les plus récentes.Son élément central est l'adoption de la toute nouvelle architecture DeepEncoder V2 :Ce modèle abandonne l'encodeur visuel CLIP traditionnel et introduit un paradigme d'encodage visuel de type LLM. En fusionnant l'attention bidirectionnelle et l'attention causale, il réalise un réarrangement sémantique des jetons visuels, construisant ainsi une nouvelle voie de « raisonnement causal 1D en deux étapes » pour la compréhension d'images 2D.
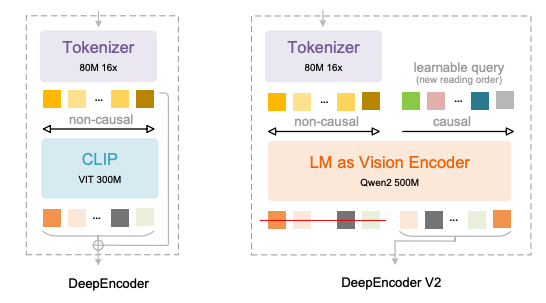
Les principales innovations de DeepEncoder V2 se reflètent dans quatre aspects :
* Remplacer CLIP par Qwen2-0.5B LLM compact pour permettre des capacités de raisonnement causal par encodage visuel à une échelle d'environ 500 millions de paramètres ;
* Introduction de la « requête de flux causal » avec la même longueur que le nombre de jetons visuels, qui utilise un masque d'attention personnalisé pour maintenir les jetons visuels globalement conscients tout en permettant aux jetons de requête de réorganiser sémantiquement l'ordre visuel ;
* Prend en charge plusieurs stratégies d'élagage pour 256 à 1 120 jetons visuels, s'alignant sur le budget de jetons des grands modèles courants tout en maintenant l'efficacité ;
* En utilisant une structure concaténée de « jeton visuel + requête causale », le réordonnancement sémantique et la génération autorégressive sont découplés, s'adaptant naturellement au mécanisme d'attention unidirectionnel de LLM.
Cette conception élimine efficacement le biais d'ordre spatial des modèles traditionnels, permettant au modèle d'organiser dynamiquement le texte, les formules et les tableaux en fonction des relations sémantiques, tout comme la lecture humaine, plutôt que de suivre mécaniquement les positions des pixels.
Il a été vérifié que dans le test de performance OmniDocBench v1.5,DeepSeek-OCR 2 a atteint une précision globale de 91,091 TP3T avec une limite de jetons visuels de 1 120.Comparativement au modèle précédent, les performances ont progressé de 3,731 TP3T, tandis que la distance d'édition de l'ordre de lecture (ED) a été réduite de 0,085 à 0,057, ce qui témoigne d'une nette amélioration de la compréhension de la logique visuelle. Pour des tâches spécifiques, la précision de l'analyse syntaxique des formules a progressé de 6,171 TP3T, les performances de compréhension des tableaux ont progressé de 2,51 à 3,051 TP3T et la distance d'édition de texte a diminué de 0,025, ce qui représente un progrès significatif pour tous les indicateurs clés.
Par ailleurs, sa praticité technique est également remarquable : tout en maintenant un taux de compression visuelle des jetons de 16 fois, le taux de répétition des services en ligne a été réduit de 6,25% à 4,17%, et le taux de répétition du traitement par lots de PDF a été réduit de 3,69% à 2,88%, prenant en compte à la fois l’innovation académique et les besoins des applications industrielles.Comparé à des modèles similaires, DeepSeek-OCR 2 obtient des résultats proches, voire supérieurs, à ceux des modèles à paramètres élevés avec des coûts de jetons visuels inférieurs.Elle offre une solution plus économique pour la reconnaissance optique de caractères (OCR) de documents de haute précision dans des contextes aux ressources limitées.
Le tutoriel « DeepSeek-OCR 2 : Visual Causal Flow » est actuellement disponible dans la section « Tutoriels » du site web d'HyperAI. Cliquez sur le lien ci-dessous pour accéder au tutoriel d'installation en un clic ⬇️
Lien du tutoriel :https://go.hyper.ai/2ma8d
Voir les articles connexes :https://go.hyper.ai/hE1wW
Démonstration de l'effet :
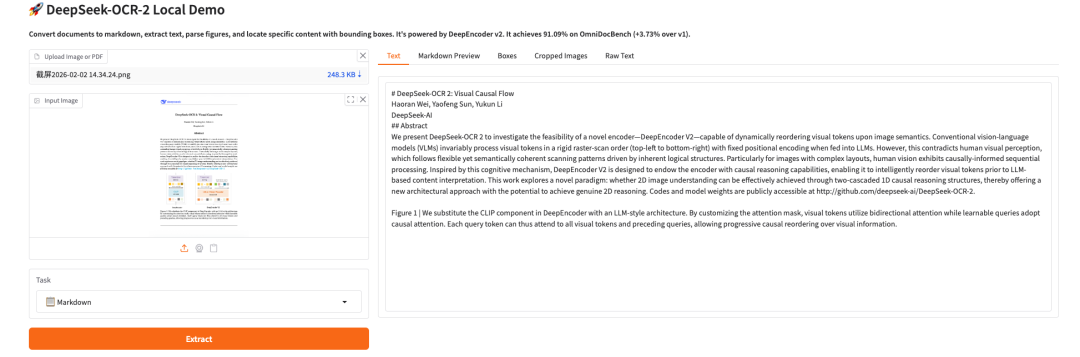
Essai de démonstration
1. Après avoir accédé à la page d'accueil de hyper.ai, sélectionnez la page « Tutoriels », ou cliquez sur « Voir plus de tutoriels », sélectionnez « DeepSeek-OCR 2 Visual Causal Flow », puis cliquez sur « Exécuter ce tutoriel en ligne ».

2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
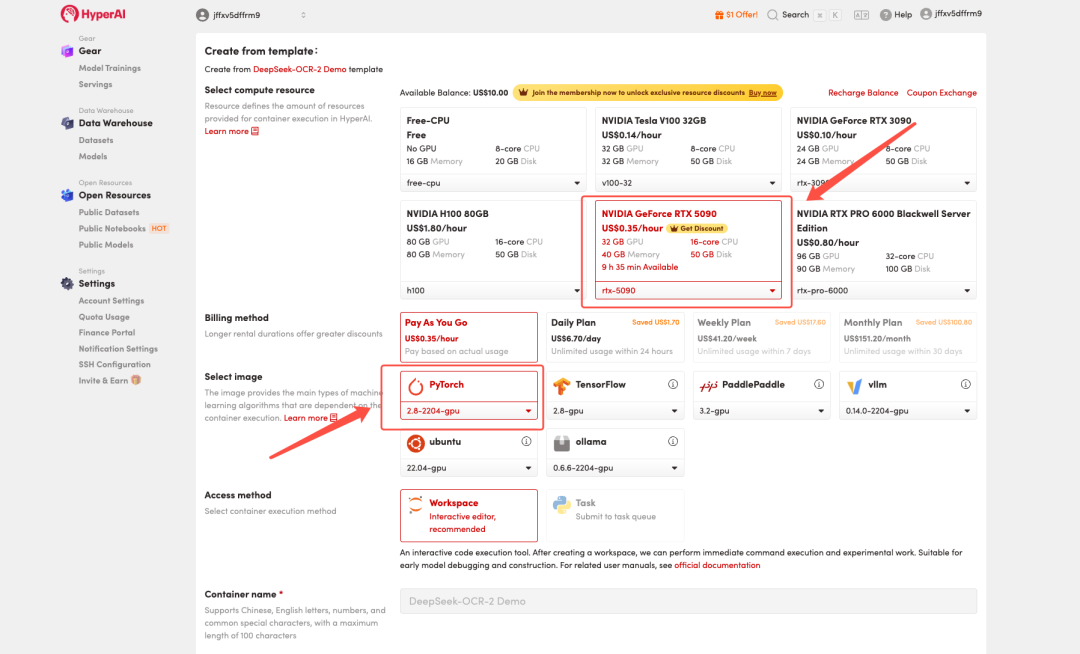
3. Sélectionnez les images « NVIDIA GeForce RTX 5090 » et « PyTorch », puis choisissez « Pay As You Go » ou « Daily Plan/Weekly Plan/Monthly Plan » selon vos besoins, puis cliquez sur « Continuer l’exécution de la tâche ».
HyperAI offre des avantages à l'inscription pour les nouveaux utilisateurs.Obtenez une RTX 5090 pour seulement 1 TP4T1. Taux de hachage(Prix d'origine $7)La ressource est valide en permanence.
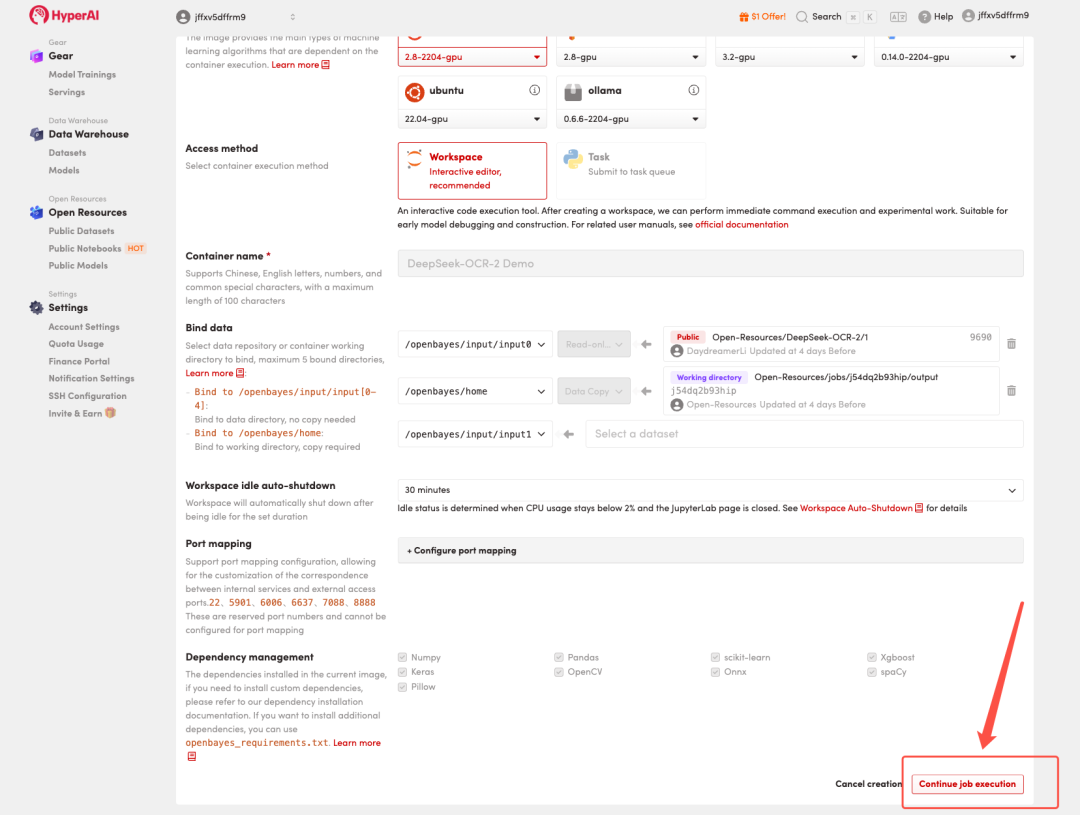
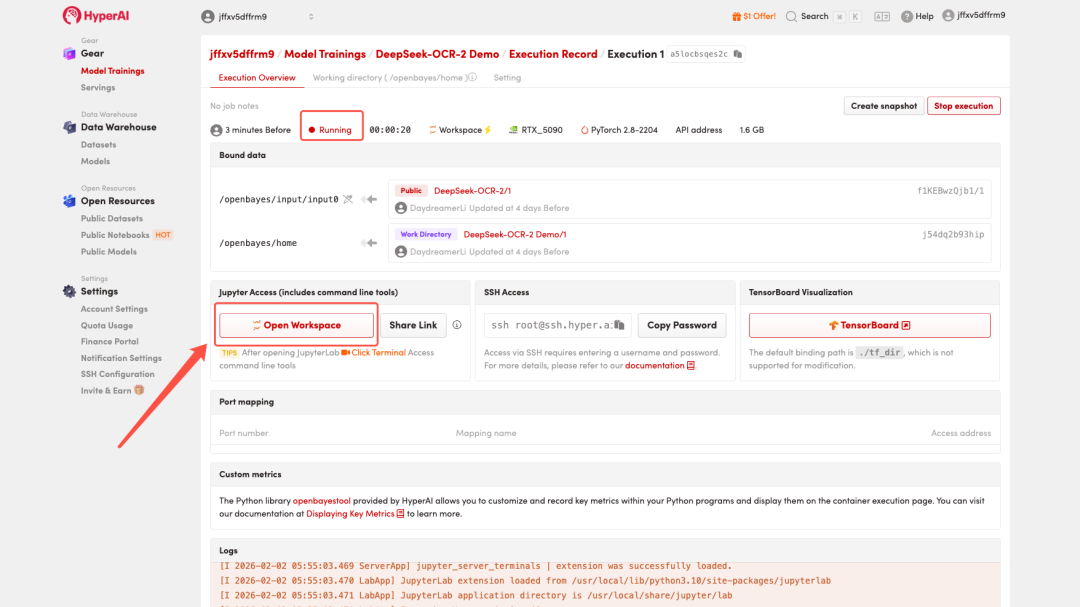
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
Démonstration d'effet
Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
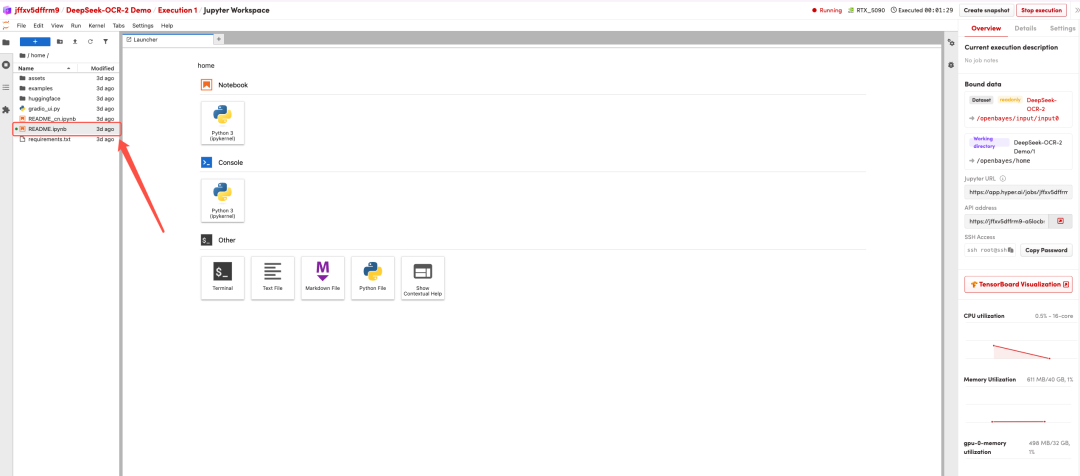
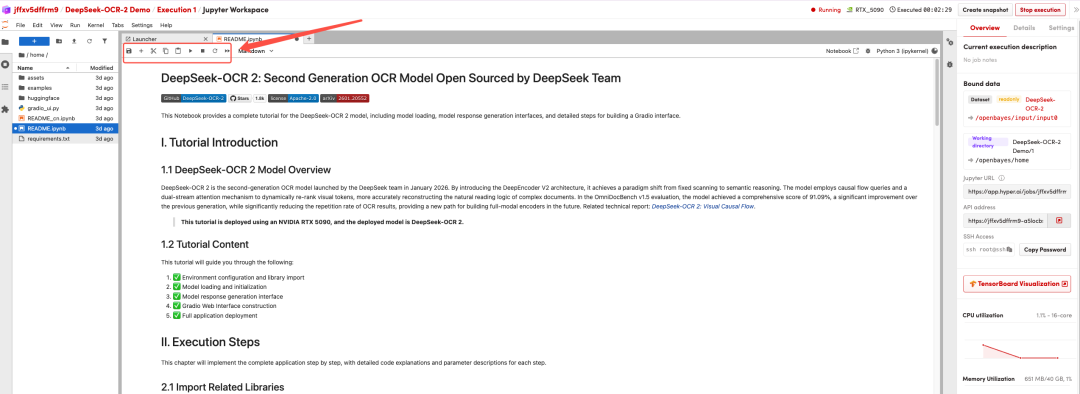
Une fois le processus terminé, cliquez sur l'adresse de l'API à droite pour accéder à la page de démonstration.
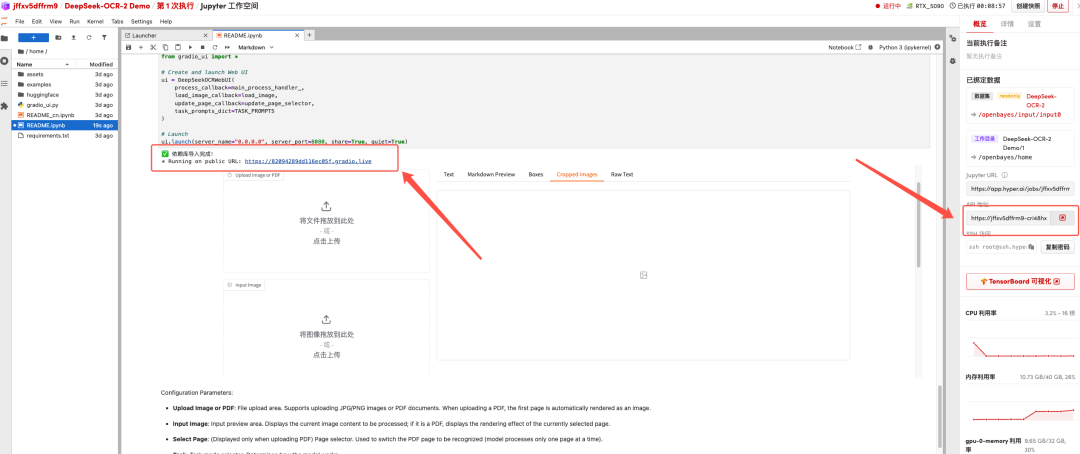
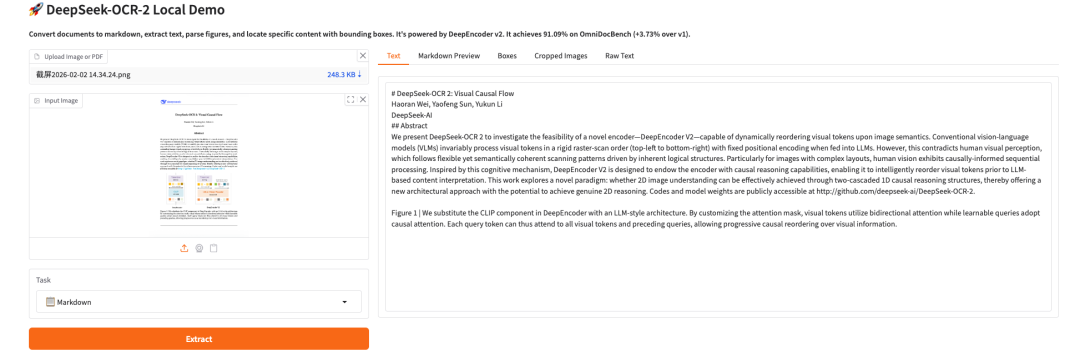
Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
Lien du tutoriel :https://go.hyper.ai/2ma8d








