Command Palette
Search for a command to run...
S’appuyant Sur 25 000 Points De Données Cliniques, L’université De Stanford a Publié Merlin, Le Premier Modèle De Langage Visuel Natif Pour La Tomodensitométrie Abdominale 3D, Qui Excelle Dans 752 tâches.
La tomodensitométrie (TDM) est une technique d'imagerie couramment utilisée en diagnostic et traitement cliniques, notamment pour le diagnostic de maladies touchant différentes parties du corps. Les statistiques montrent qu'environ 300 millions de TDM sont réalisées chaque année dans le monde, dont un quart environ sont des TDM abdominales. Le diagnostic et le traitement médical étant de plus en plus dépendants de l'imagerie, la demande en diagnostic par imagerie ne cesse de croître. Or, l'interprétation d'une image TDM abdominale prend généralement 20 minutes à un radiologue, et l'efficacité diagnostique peine à suivre le rythme de l'augmentation rapide de la demande clinique. Plus grave encore est la grave pénurie de radiologues ; les données prédictives indiquent que…D’ici 2036, certaines régions seront confrontées à une pénurie de plus de 19 000 radiologues, ce qui souligne le déséquilibre croissant entre l’offre et la demande dans ce secteur.
L'apprentissage automatique, grâce à ses capacités sophistiquées de traitement des données et d'analyse à haut débit, permet d'extraire rapidement des caractéristiques et d'identifier intelligemment de vastes quantités d'images médicales, palliant ainsi les difficultés liées à l'interprétation manuelle traditionnelle d'images, telles que la faible efficacité et le manque de personnel. Plus précisément, les modèles vision-langage (VLM), basés sur la technologie de pré-entraînement contrastif langage-image (CLIP), permettent d'aligner les représentations textuelles et visuelles dans un espace d'intégration partagé, facilitant ainsi la supervision des modèles visuels par le langage naturel.En tant que modèle fondamental, ce type de modèle peut non seulement permettre un apprentissage zéro-shot, mais aussi, après avoir été combiné à un grand modèle de langage et entraîné avec des données cliniques, être rapidement adapté à l'analyse d'images et de rapports radiologiques.
Au-delà des avancées théoriques et technologiques, les méthodes actuelles basées sur les modèles de localisation virtuelle (VLM) démontrent un immense potentiel d'application en radiologie, avec des modèles tels que BiomedCLIP, LLaVA-Rad et Med-PaLMM mis en œuvre avec succès. Cependant, les progrès technologiques et la mise en œuvre des modèles ne garantissent pas une application aboutie. Les VLM se heurtent encore à de nombreux obstacles majeurs dans leurs applications pratiques, ce qui freine leur adoption généralisée et leur utilisation fiable en milieu clinique.
d'abord,Les méthodes existantes se concentrent principalement sur les images bidimensionnelles, telles que les radiographies, ce qui rend difficile le traitement efficace des images tridimensionnelles, comme les tomodensitométries abdominales. La méthode d'analyse du volume entier par agrégation de coupes est extrêmement inefficace.Deuxièmement,Actuellement, il n'existe aucun jeu de données tomodensitométrique abdominal accessible au public pour l'entraînement et l'évaluation des modèles de reconstruction 3D. Les modèles privés n'intègrent pas pleinement les données cliniques multimodales telles que les codes diagnostiques et les comptes rendus radiologiques, et il n'existe pas de référentiel unifié pour les tâches de tomodensitométrie abdominale tridimensionnelle, ce qui engendre une lacune importante dans le système d'entraînement et d'évaluation des modèles de base associés.
Au vu des défis susmentionnés,Une équipe de recherche de l'université de Stanford a proposé Merlin, le premier modèle de langage visuel 3D natif pour les tomodensitométries abdominales, ainsi qu'un ensemble de données contenant 25 494 paires de tomodensitométries abdominales et de rapports de radiologie. Merlin a été entraîné sur un seul GPU NVIDIA A6000 à l'aide de données structurées et non structurées provenant d'hôpitaux réels, incluant des paires de tomodensitométries, des codes de diagnostic des dossiers médicaux électroniques (DME) et des comptes rendus radiologiques. L'équipe de recherche a réalisé une validation interne sur 5 137 tomodensitométries et une validation externe sur 44 098 tomodensitométries et deux jeux de données publics axés sur les tomodensitométries abdominales (VerSe et TotalSegmentator). Les résultats de la validation montrent que Merlin surpasse largement les modèles de référence spécifiques sur les tâches de test.
Les résultats de cette recherche, intitulée « Merlin : un modèle et un ensemble de données de base pour la vision et le langage par tomographie informatisée », ont été publiés dans la revue Nature.
Points saillants de la recherche :
* Cette étude propose Merlin, le premier modèle de langage visuel 3D natif spécifiquement conçu pour les tomodensitométries abdominales, surmontant ainsi la limitation des modèles précédents qui se concentraient uniquement sur les images 2D.
* L'étude a publié un ensemble de données à grande échelle contenant 25 494 paires de tomodensitométries abdominales et de rapports de radiologie, comblant ainsi une lacune dans le domaine des ensembles de données.
* Cette recherche intègre de manière novatrice les données structurées des dossiers médicaux électroniques et les rapports de radiologie non structurés en tant que signaux de supervision, et propose un cadre de pré-formation en plusieurs étapes qui combine l'apprentissage multitâche et la formation par phases.

Adresse du document :
https://www.nature.com/articles/s41586-026-10181-8
Suivez notre compte WeChat officiel et répondez « Merlin » en arrière-plan pour obtenir le PDF complet.
Combler le manque de données pour la formation et l'évaluation des VLM
Pour pallier le manque de données tomodensitométriques abdominales disponibles publiquement pour l'entraînement et l'évaluation des modèles 3D de modèles de laboratoire virtuels (VLM), l'équipe de recherche a utilisé une grande quantité de données conformes provenant de véritables centres médicaux.Au final, un ensemble de données cliniques de haute qualité contenant 18 321 patients a été publié, comprenant des tomodensitométries appariées, des rapports de radiologie non structurés et des dossiers médicaux électroniques structurés.dans:
* Données du scanner :
Les données proviennent de tomodensitométries abdominales complètes, chacune comportant plusieurs séquences. La séquence présentant le plus grand nombre de coupes axiales a été sélectionnée afin d'optimiser la quantité d'informations. Ce processus a permis d'obtenir 10 628 509 images bidimensionnelles à partir de 25 528 tomodensitométries.
* Rapport radiologique :
L'étude a compilé les comptes rendus radiologiques correspondant à chaque tomodensitométrie. Ces comptes rendus comportent plusieurs parties, dont les plus importantes sont les « résultats » et les « impressions ». Les premiers comprennent des observations détaillées de chaque système organique, tandis que les seconds résument les principaux résultats cliniques. Il est à noter que, compte tenu de la précision des informations fournies et de la validité des travaux antérieurs, la formation s'est concentrée uniquement sur la section « résultats », soit un total de 10 051 571 éléments.
* DSE :
Les données ont servi à entraîner le modèle à l'aide d'informations diagnostiques sous forme de codes de la Classification internationale des maladies (CIM), associés aux dossiers de tomodensitométrie des patients correspondants. L'ensemble de données contient 954 013 codes CIM-9, dont 5 686 codes uniques, et 2 041 280 codes CIM-10, dont 10 867 codes uniques.
Concernant le partitionnement des données, l'ensemble de données de pré-entraînement a été divisé en trois sous-bases de données : 60% (15 331 scanners), 20% (5 060 scanners) et 20% (5 137 scanners), utilisées respectivement pour l'entraînement, la validation et les tests. Par précaution, les scanners multiples d'un même patient n'ont pas été inclus dans la même sous-base de données.
aussi,L'expérience a également utilisé 44 098 points de données provenant de trois institutions indépendantes pour la validation externe, qui ont tous été utilisés pour les tests.Les détails sont les suivants :
* Jeu de données externe 1 : Contient 6 997 tomodensitométries abdominales
* Jeu de données externe 2 : Contient 25 986 tomodensitométries abdominales
* Ensemble de données externes 3 : Contient 4 872 tomodensitométries abdominales et 6 243 tomodensitométries thoraciques.
Les deux autres jeux de données publics dédiés aux tomodensitométries abdominales sont VerSe et TotalSegmentator. Le jeu de données VerSe contient 160 tomodensitométries, tandis que le jeu de données TotalSegmentator en contient 401. Parmi celles-ci, 34 tomodensitométries ont été sélectionnées pour le pré-entraînement et le test de la prédiction multi-tâches et multi-maladies, et les 367 tomodensitométries restantes ont été divisées en deux groupes : 80% (293 tomodensitométries) et 20% (74 tomodensitométries), respectivement pour l’entraînement et la validation.
L'apprentissage multitâche et les stratégies de formation par étapes, ainsi que les solutions différenciées, garantissent la haute efficacité de Merlin.
En termes d'architecture du modèle,Merlin réalise l'alignement image-texte en utilisant une architecture à double encodeur composée d'un encodeur d'image et d'un encodeur de texte.L'encodeur d'images utilise I3D ResNet152, qui réutilise les poids du modèle bidimensionnel pré-entraîné par « inflation » et les copie dans la troisième dimension du noyau convolutionnel tridimensionnel. L'encodeur utilisé dans cet article est Clinical Longformer, qui possède une capacité de traitement de texte plus longue que les autres modèles biomédicaux pré-entraînés et les encodeurs CLIP classiques, prenant en charge 4 096 contextes longs et s'adaptant aux besoins des rapports textuels longs.
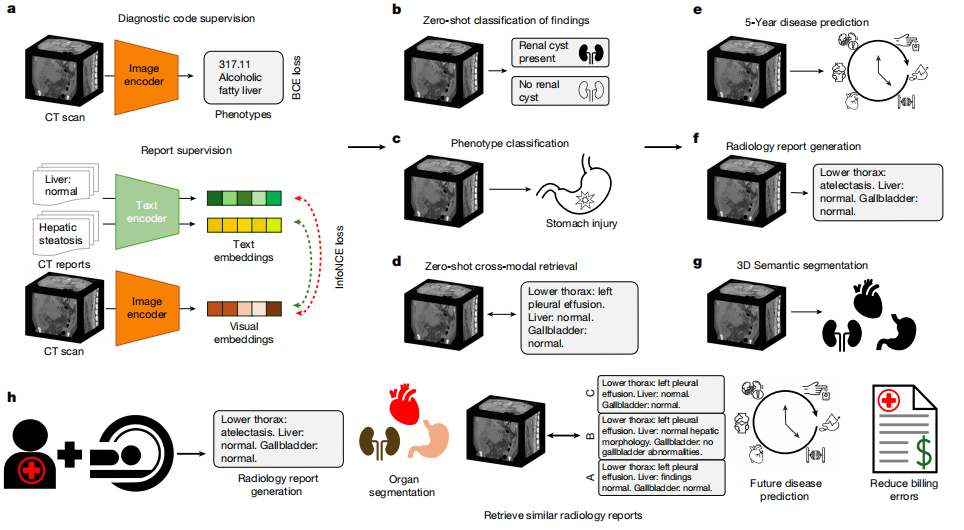
Pour l'entraînement du modèle, Merlin utilise deux fonctions de perte pour gérer respectivement la classification phénotypique et les rapports radiologiques :La fonction de perte d'entropie croisée binaire a été utilisée pour la classification phénotypique ; la fonction de perte InfoNCE a été utilisée pour l'apprentissage du contraste des rapports radiologiques.La dimension d'intégration des images et du texte a été uniformément fixée à 512, conformément à celle utilisée dans le modèle ViT-Base des expériences OpenCLIP. Par la suite, la sauvegarde des gradients a été activée pour l'encodeur visuel et l'encodeur de texte dans la stratégie d'entraînement, et un entraînement en précision mixte FP16 a été employé.
L'optimiseur utilisé était AdamW avec un taux d'apprentissage initial de 1 x 10⁻⁵ et β = (0,9 ; 0,999). Un planificateur de taux d'apprentissage cosinus a été employé, fixant à 300 le nombre d'époques d'entraînement après lesquelles le taux d'apprentissage diminuait jusqu'à 0. Le matériel était constitué d'un seul GPU A6000 de 48 Go, avec une taille de lot maximale de 18.
En plus de la formation à l'utilisation des phénotypes des dossiers médicaux électroniques et des rapports radiologiques de manière multitâche,L'étude a également pris en compte un programme de formation par étapes.Plus précisément, l'encodeur d'images Merlin est d'abord entraîné à l'aide des codes de diagnostic des dossiers médicaux électroniques (DME) lors d'une première étape ; puis, il est entraîné comparativement à l'aide de comptes rendus radiologiques lors d'une seconde étape. Afin d'éviter l'oubli des informations issues des DME apprises lors de la première étape, la fonction de perte phénotypique est intégrée avec des pondérations plus faibles lors de l'entraînement de la seconde étape.
La première étape utilise l'optimiseur AdamW avec un taux d'apprentissage initial de 1 x 10⁻⁴, β = (0,9, 0,999), un planificateur de taux d'apprentissage exponentiel avec γ = 0,99 et un seul GPU A6000 avec une taille de lot de 22. Les hyperparamètres utilisés dans la deuxième étape sont les mêmes que ceux utilisés dans l'entraînement multitâche.
En résumé, l'apprentissage multitâche et la formation par étapes permettent de différencier les stratégies, et l'équipe de recherche a apporté des améliorations à la formation par étapes afin de prévenir l'oubli. Cette stratégie de formation différenciée constitue le fondement de l'efficacité et de la rigueur de Merlin, et a été validée par des expériences d'ablation ultérieures.
Une évaluation complète de 752 catégories de tâches montre que Merlin surpasse tous les autres.
Dans le cadre du processus expérimental, l'équipe de recherche a effectué une validation interne basée sur 5 137 tomodensitométries et une validation externe basée sur 44 098 tomodensitométries et deux ensembles de données disponibles publiquement (VerSe et TotalSegmentator) axés sur les tomodensitométries abdominales.Il existe au total 6 grandes catégories de tâches d'évaluation, couvrant 752 sous-tâches spécifiques.Les principales catégories de tâches comprennent la classification zéro-shot (31 sous-tâches), la classification phénotypique (692 sous-tâches), la récupération intermodale zéro-shot (23 sous-tâches), la prédiction de la maladie à 5 ans (6 sous-tâches), la génération de rapports de radiologie et la segmentation 3D.
Dans la tâche de classification des résultats sans exemple, 30 tomodensitométries abdominales issues de données cliniques internes et externes ont été analysées.Merlin a obtenu un score F1 de 0,741 sur l'ensemble de données de validation interne (intervalle de confiance de 95%, 0,727–0,755) et un score F1 moyen de 0,647 sur l'ensemble de données de validation externe (intervalle de confiance de 95%, 0,607–0,678).Ces scores étaient significativement supérieurs à ceux du modèle OpenCLIP 2D utilisant un regroupement k=1 et du modèle BioMedCLIP 2D affiné utilisant un regroupement moyen (P < 0,001). Voir la figure ci-dessous :
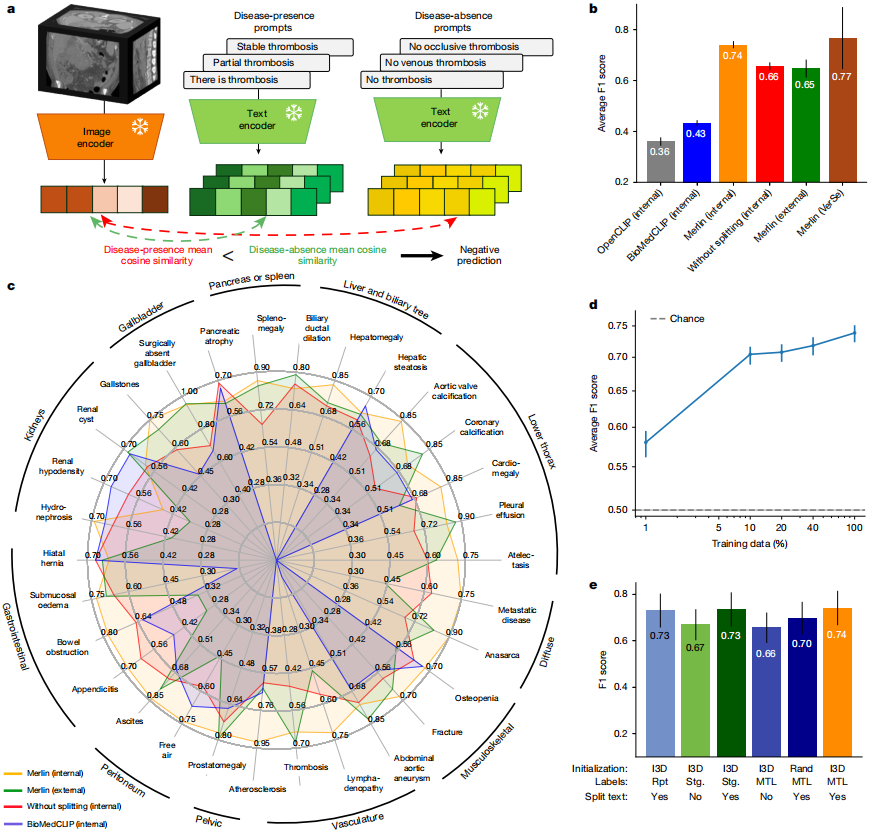
D'un point de vue qualitatif,Merlin maintient des performances élevées sur des ensembles de données externes pour les maladies présentant des caractéristiques significatives, telles que l'épanchement pleural et l'ascite.Cependant, ses performances diminuent légèrement lorsqu'il s'agit de détecter des caractéristiques fines, telles que l'appendicite et les adénopathies. De plus, sans segmentation des comptes rendus radiologiques, Merlin a obtenu un score F1 moyen de 0,656 (intervalle de confiance de 95%) sur l'ensemble de données d'évaluation externe.
Dans la comparaison de l'expérience d'ablationLe modèle Merlin initialisé avec un réseau 3D dilaté présente les meilleures performances.Le score F1 était de 0,741 (intervalle de confiance à 95% : 0,727–0,755). Lors de la segmentation des comptes rendus radiologiques, le score du modèle combinant le dossier médical électronique (DME) et les comptes rendus radiologiques était de 0,735 (intervalle de confiance à 95% : 0,719–0,748). Le modèle utilisant uniquement les comptes rendus radiologiques et mettant en œuvre la segmentation de ces comptes rendus se classait troisième, avec un score F1 de 0,730 (intervalle de confiance à 95% : 0,714–0,744). La segmentation ou non des comptes rendus radiologiques avait l’impact le plus significatif sur les performances du modèle ; sans segmentation, le score F1 du modèle Merlin diminuait en moyenne de 7,9 points (p < 0,01).
Il convient également de mentionner queMerlin sans exemple surpasse toutes les lignes de base supervisées dans les expériences supervisées sur les données d'entraînement 10% et 100%.Avec 1001 données d'entraînement (TP3T), le score F1 s'est amélioré de 291 (TP3T), tandis qu'avec 101 (TP3T), l'amélioration a atteint un niveau impressionnant de 451 (TP3T). Les expériences démontrent qu'avec 1001 (TP3T) de données d'entraînement, l'algorithme Merlin sans exemple (zero-shot) surpasse significativement l'algorithme Merlin supervisé, améliorant le score F1 de 161 (TP3T).
Dans la tâche de classification phénotypique, les performances de Merlin pour la prédiction de 692 phénotypes cliniques définis par PheWAS ont été évaluées, atteignant une aire sous la courbe ROC (AUROC) moyenne de 0,812 (intervalle de confiance à 95 % [0,808–0,816]). Au total, 258 phénotypes présentaient des valeurs d'AUROC supérieures à 0,85 et 102 phénotypes, des valeurs supérieures à 0,9. (Voir figure ci-dessous.)
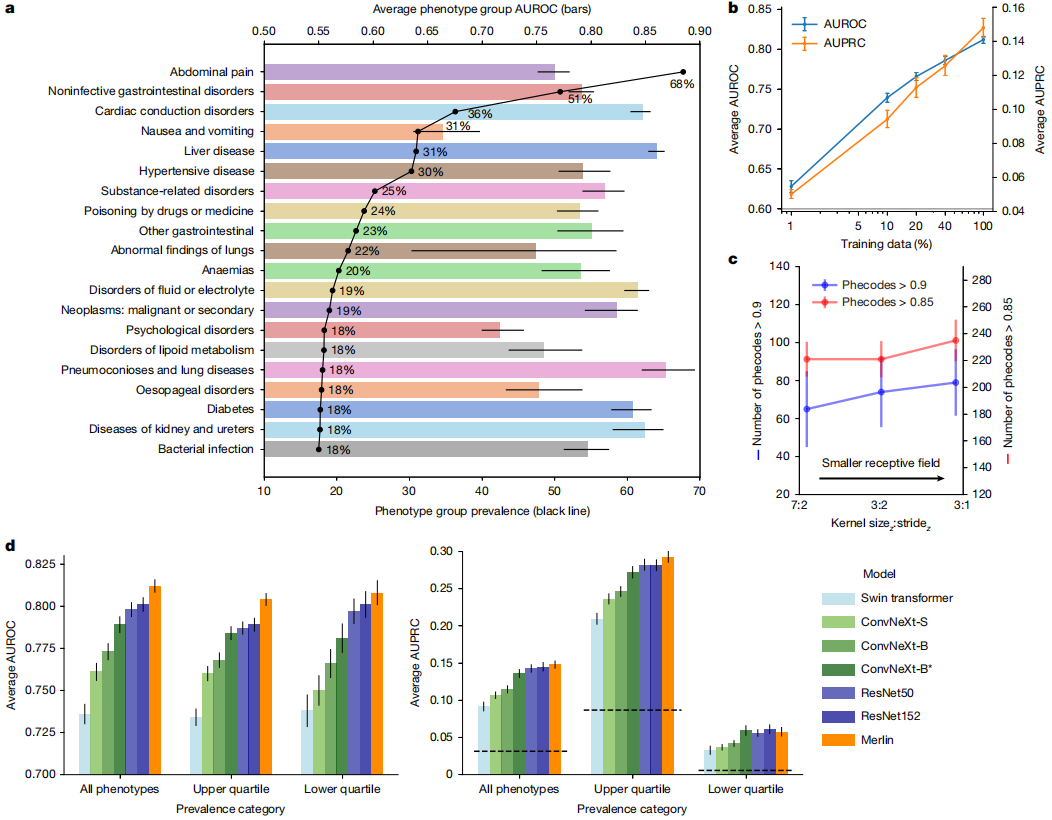
Lors de l'analyse des 20 phénotypes les plus courants présentant les taux d'incidence les plus élevés lors des tests internes,Merlin excelle dans la détection des maladies touchant plusieurs systèmes organiques, notamment le foie, les reins, les uretères et le tube digestif.
Dans la tâche de récupération croisée de modèles zéro-shot, la première étape est une tâche de récupération basée sur la « découverte d'images » avec 64 cas.Merlin présente des avantages significatifs par rapport à OpenCLIP et BioMedCLIP.Ceci est dû à l'encodeur de texte Clinical Longformer utilisé par Merlin, tandis qu'OpenCLIP et BioMedCLIP autorisent des longueurs de jetons maximales de 77 et 256 caractères, respectivement. Par ailleurs, les excellentes performances de Merlin ont également été reproduites lors de la tâche de recherche d'images de découverte, basée sur 64 cas. Voir la figure ci-dessous :
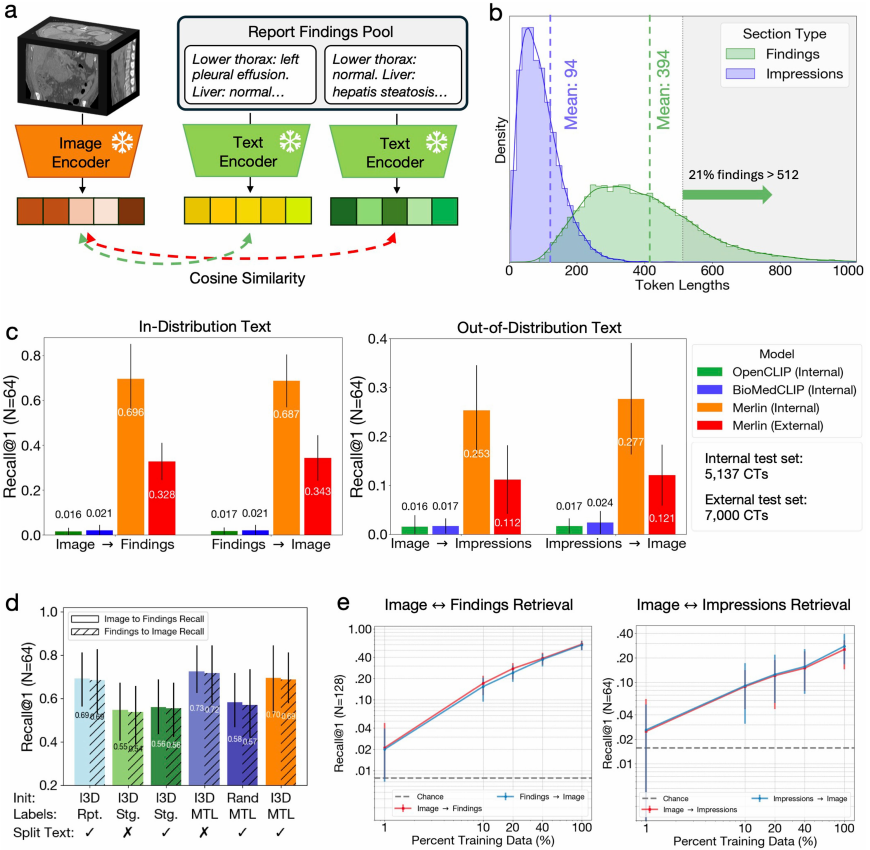
Un élément de preuve plus important encore est que Merlin, même en utilisant uniquement les « résultats » objectivement décrits dans le rapport pour l'entraînement à l'alignement visuel-langage,Même lorsqu'il s'agit d'« impressions » de rapports très généralisées, il démontre toujours un haut degré de capacité de généralisation interdomaines.Les résultats ont ensuite été vérifiés une nouvelle fois par rétro-ingénierie. De plus, bien que les performances de Merlin en matière de recherche sur l'ensemble de données de test externe aient diminué par rapport à l'ensemble de données de test interne, elles restaient 5 à 7 fois supérieures à celles d'autres méthodes de référence externes.
Dans la tâche de prédiction multi-maladies sur 5 ans, l'expérience a évalué la prédiction de Merlin concernant le risque que des patients en bonne santé développent plusieurs maladies chroniques majeures au cours des cinq prochaines années, notamment l'insuffisance rénale chronique, l'ostéoporose, les maladies cardiovasculaires, les cardiopathies ischémiques, l'hypertension et le diabète.
Après avoir peaufiné Merlin et utilisé l'étiquette en aval 100%, sa valeur AUROC pour prédire l'incidence de la maladie dans les cinq ans a atteint 0,757 (intervalle de confiance de 95%, 0,743-0,772).Cette performance est 71 TP3T supérieure à celle du modèle pré-entraîné ImageNet (I3D) qui utilise uniquement des images.Même avec seulement 101 étiquettes TP3T, l'aire sous la courbe ROC (AUROC) de Merlin pour la prédiction de l'incidence de la maladie dans les cinq ans atteint 0,708 (intervalle de confiance de 951 TP3T : 0,692-0,723), surpassant ainsi le modèle pré-entraîné sur ImageNet (4,41 TP3T). Voir la figure ci-dessous :
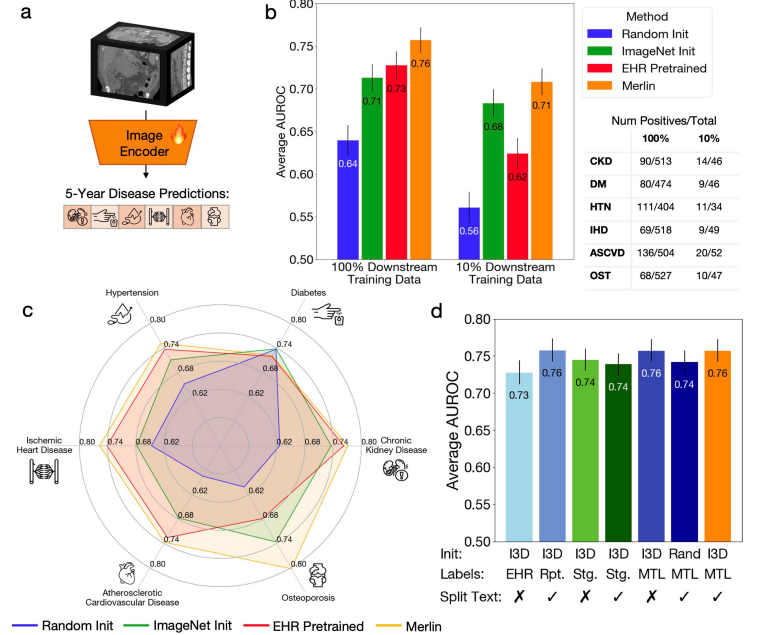
en outre,Même en utilisant seulement 1/10 des données d'entraînement, les performances de prédiction de Merlin sont comparables à celles d'un modèle pré-entraîné ImageNet entraîné sur 100% de données.Cela démontre parfaitement la capacité de Merlin à tirer sans coup et sa grande transférabilité.
Dans la tâche de génération de rapports radiologiques, comparé au modèle de référence RadFM, dans les tests basés sur des métriques quantitatives telles que RadGraph-F1, BERT Score, ROUGE-2 et BLEU,Merlin surpasse le précédent dans tous les aspects de la structure logique anatomique et dans l'ensemble des résultats de compte rendu.
En termes de qualité, Merlin génère d'excellents rapports, avec un diagnostic, une localisation et une description des symptômes d'une grande précision. Cependant, Merlin peut parfois adopter des jugements prudents, comme la sous-estimation de certains problèmes, constatée aussi bien dans les rapports générés manuellement que dans ceux issus de scanners. Ceci est dû aux premières démonstrations de rapports radiologiques générés à partir de scanners et sera amélioré à mesure que la qualité des rapports progressera.
Dans la tâche de segmentation sémantique 3D, Merlin surpasse le framework nnUNet de 4,71 TP3T en score Dice macro-moyen lorsqu'il utilise seulement 101 TP3T de données d'entraînement ; lorsqu'il utilise 1001 TP3T de données d'entraînement, le framework nnUNet est légèrement plus performant que le modèle initial de Merlin, mais la différence de score Dice n'est que de 0,006.
Sur 20 organes de l'ensemble de test, Merlin a obtenu des scores Dice plus élevés que le cadre nnUNet sur 12 organes lorsqu'il a été entraîné avec des données 10%, avec une amélioration allant jusqu'à 41% dans la segmentation de la prostate.
De plus, lors d'essais de validation externes, l'équipe de recherche a évalué Merlin sur un total de 44 098 tomodensitométries externes à l'aide d'un ensemble de données de plus de 100 000 tomodensitométries externes.Il présente des performances stables et précises sur différents sites et emplacements anatomiques, surmontant le décalage de distribution entre l'ensemble de données d'entraînement et l'ensemble de données de test externe.De plus, il a systématiquement surpassé les autres modèles de référence et a même battu les modèles de référence spécialisés en tomodensitométrie thoracique pour les tâches thoraciques.
Les modèles de langage visuel révèlent le potentiel des données médicales multimodales à grande échelle.
Outre cette étude, d'autres avancées dans le domaine des modèles de langage visuel en médecine se succèdent. Par exemple, une équipe de recherche de l'université de Stanford a proposé un transformateur multimodal avec modélisation masquée unifiée (MUSK), qui constitue également un modèle de base de langage visuel et vise à intégrer des données d'images et de textes à grande échelle, non étiquetées et non appariées.
Titre de l'article : Un modèle de base vision-langage pour l'oncologie de précision
Adresse du document :
https://www.nature.com/articles/s41586-024-08378-w
Le modèle KEEP, basé sur des cas et enrichi par les connaissances, proposé par l'Université Jiao Tong de Shanghai et d'autres chercheurs, remédie au fait que les modèles actuels s'appuient principalement sur des approches axées sur les données et manquent d'intégration explicite des connaissances médicales. Ce modèle utilise un graphe de connaissances exhaustif sur 11 454 maladies et 139 143 attributs pour réorganiser des millions de paires image-texte pathologiques en 143 000 groupes sémantiquement structurés, alignés sur la hiérarchie de l'ontologie des maladies. Cette méthode de pré-entraînement enrichie par les connaissances aligne les représentations visuelles et textuelles dans un espace sémantique hiérarchique, permettant ainsi une compréhension approfondie des relations entre les maladies et des schémas morphologiques.
Titre de la thèse : Pré-entraînement enrichi par les connaissances pour un modèle de base en pathologie visuelle et du langage appliqué au diagnostic du cancer
Adresse du document :
https://www.sciencedirect.com/science/article/pii/S1535610826000589
En résumé, les modèles de langage visuel, grâce à leurs capacités de compréhension intermodale, présentent un potentiel considérable en médecine et en radiologie. Ils permettent d'intégrer images médicales, dossiers médicaux et recommandations cliniques pour une identification intelligente des lésions, une assistance à l'analyse des cas et la génération automatique de rapports de diagnostic. Ceci offre aux médecins des outils auxiliaires performants et ouvre de nouvelles perspectives en matière de prédiction des maladies, accélérant ainsi la transition de la médecine moderne d'une approche empirique à une approche fondée sur les données.








