Command Palette
Search for a command to run...
Déploiement En Un Clic De Gemma 4 31B, Avec jusqu'à 256K De Contexte, Comparable En Capacités À Qwen 3.5 397B.

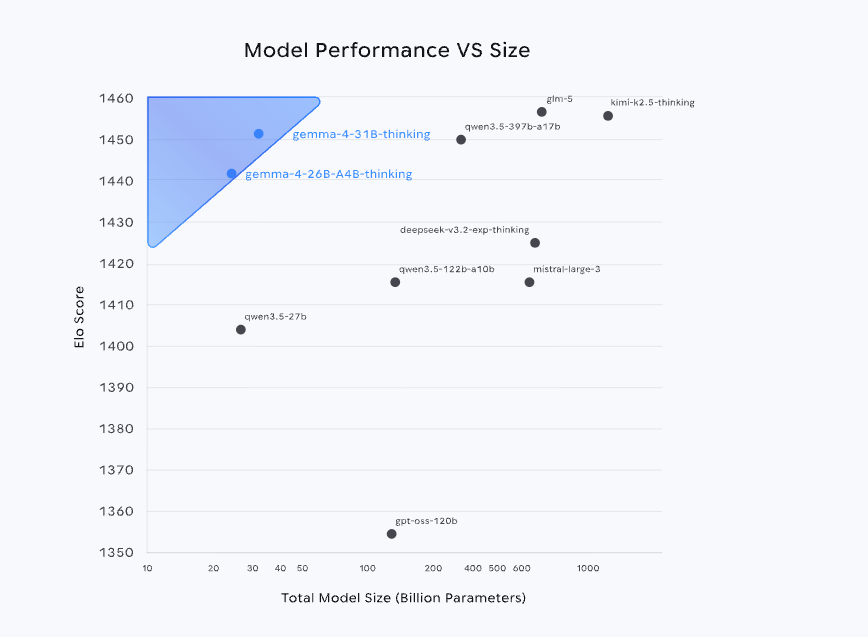
Récemment,Google DeepMind a rendu open source la série de modèles Gemma 4.S'appuyant sur la même technologie que Gemini 3, ce modèle figure parmi les trois meilleurs au niveau mondial dans le classement Arena AI et atteint des performances proches, voire supérieures, à celles de modèles plus volumineux, avec un nombre de paramètres bien inférieur à celui de ses concurrents. De plus, sa stratégie open source, basée sur la licence Apache 2.0, abaisse encore davantage les seuils d'application, renforçant considérablement son potentiel de déploiement en production.
Du point de vue de la forme du produitGemma 4 n'est pas un modèle unique, mais un système multi-tailles couvrant E2B, E4B, 26B, A4B à 31B.Ces modèles sont conçus pour différents scénarios, notamment les appareils mobiles, les déploiements locaux et les environnements de calcul haute performance. Le principe de base de cette architecture en couches est d'équilibrer « échelle, performance et coût » afin de répondre à des besoins différenciés : les modèles plus petits privilégient la légèreté et les performances en temps réel, tandis que les modèles plus grands se concentrent sur l'inférence complexe et les tâches de haute précision.
Parmi elles, la version 31B, qui représente le haut de gamme de la série actuelle, offre des capacités comparables à celles de la Qwen 3.5 397B. En termes de scénarios d'application,La version 31B prend en charge la saisie et l'affichage d'images et de texte, dispose d'une fenêtre contextuelle pouvant contenir jusqu'à 256 000 jetons, et gère nativement l'inférence, les appels de fonctions et les invites système. Elle prend également en charge plus de 140 langues, ce qui la rend idéale pour des applications telles que la réponse à des questions de haute qualité, l'assistance à la programmation et les services d'agents.
Actuellement, la section tutoriels du site officiel d'HyperAI (hyper.ai) a lancé le « déploiement en un clic de Gemma-4-31B-it » pour aider les développeurs à découvrir des modèles avancés avec de faibles barrières à l'entrée.
Exécutez en ligne :
Essai de démonstration
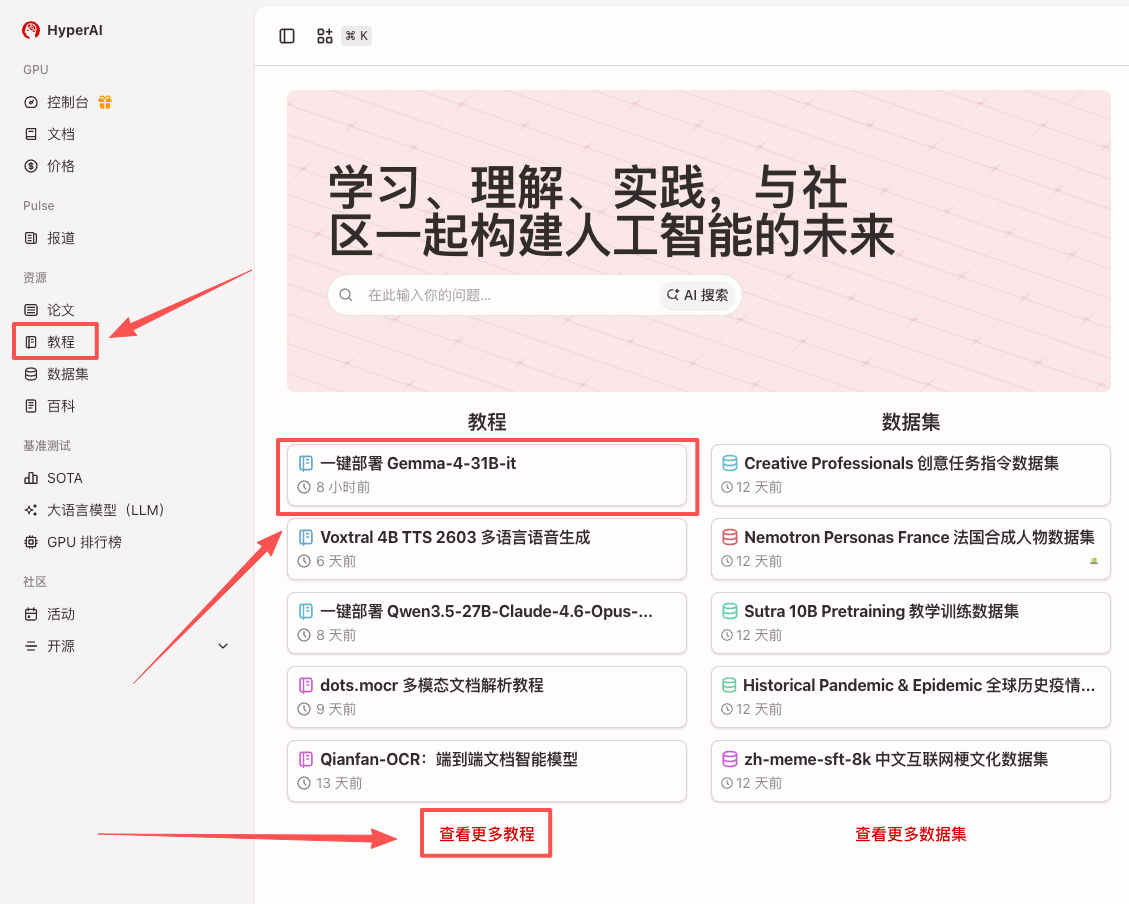
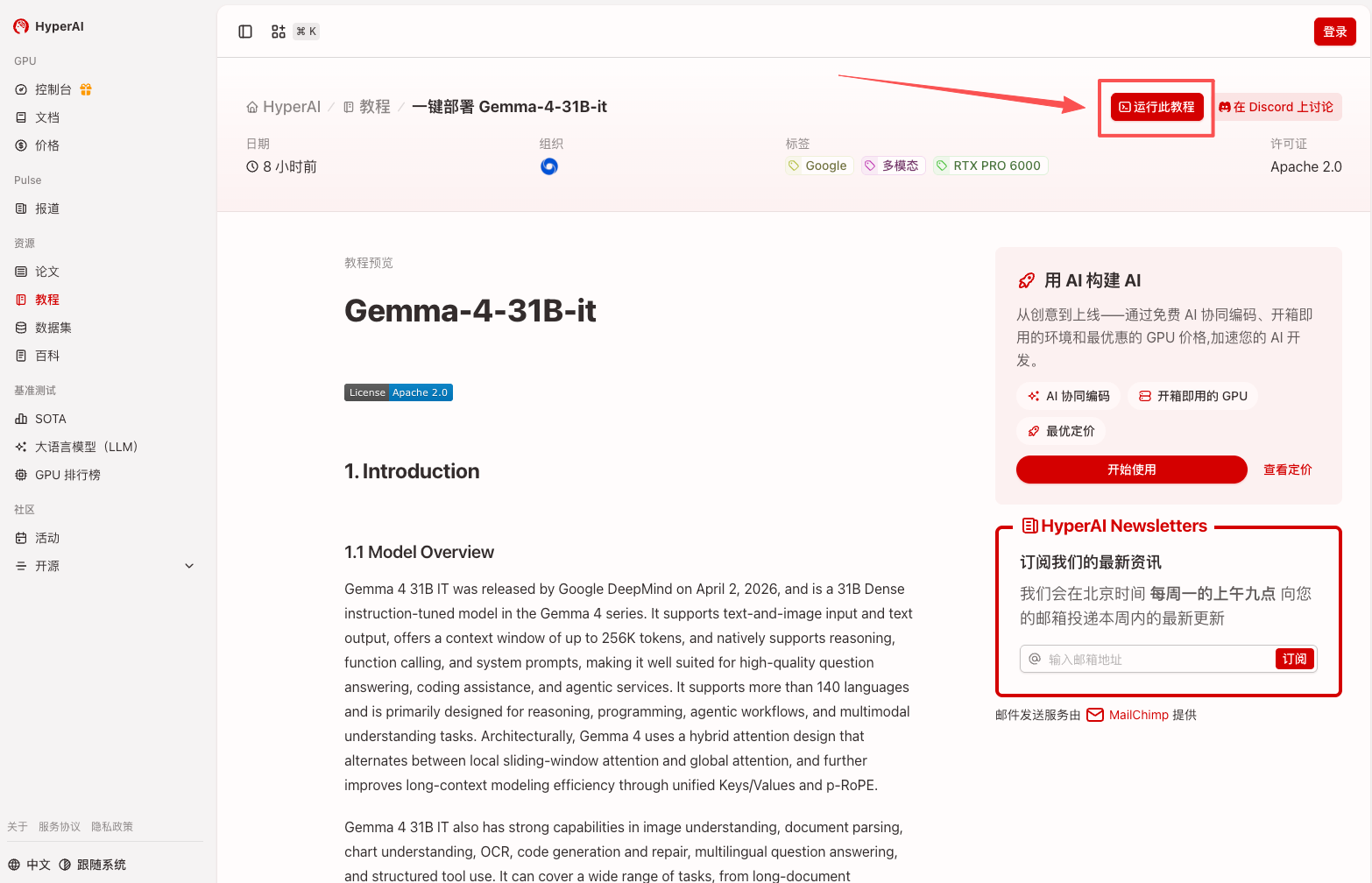
1. Après avoir accédé à la page d'accueil hyper.ai, sélectionnez la page « Tutoriels », ou cliquez sur « Voir plus de tutoriels », sélectionnez « Déploiement en un clic de Gemma-4-31B-it », et cliquez sur « Exécuter ce tutoriel ».
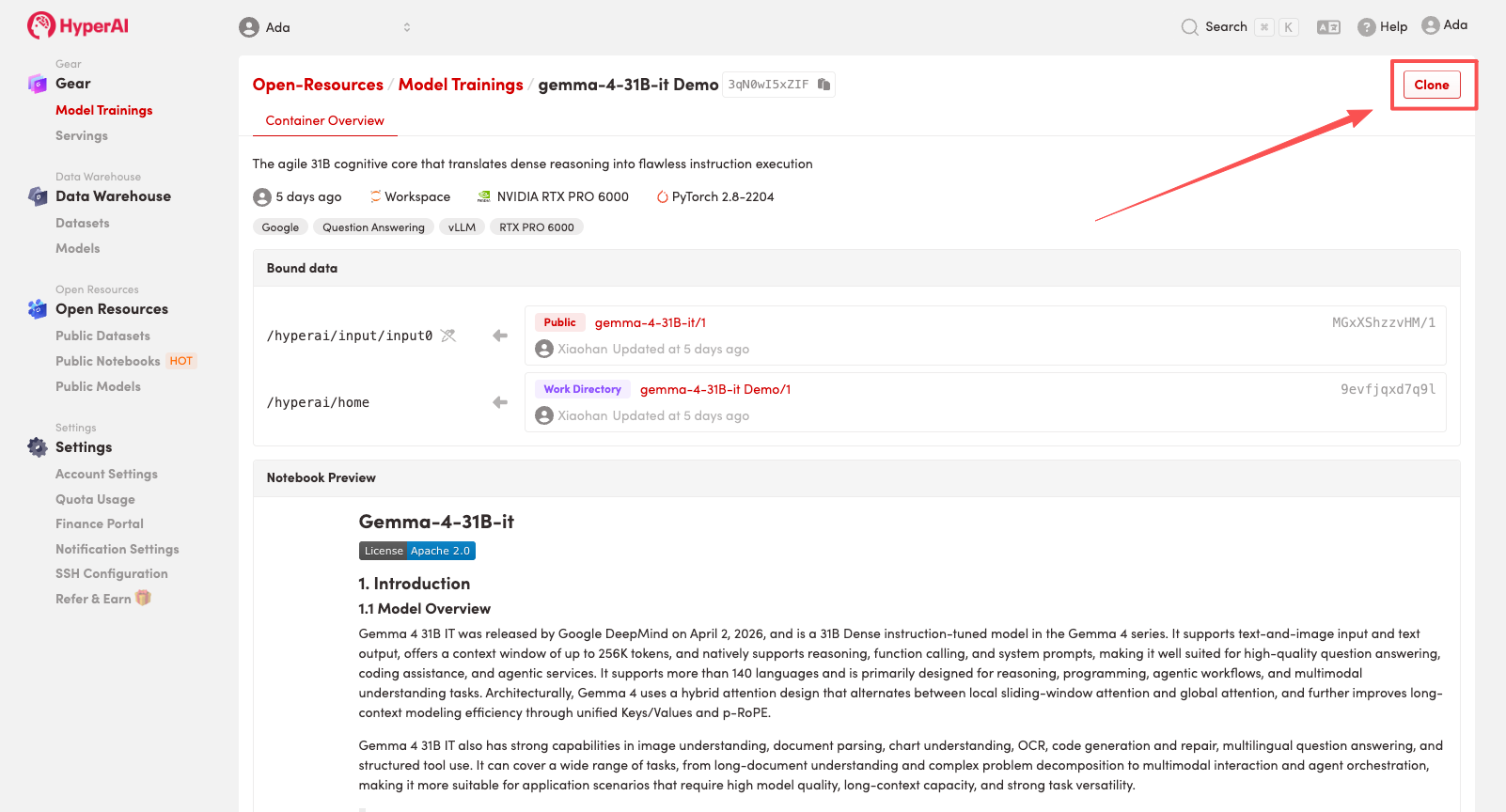
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
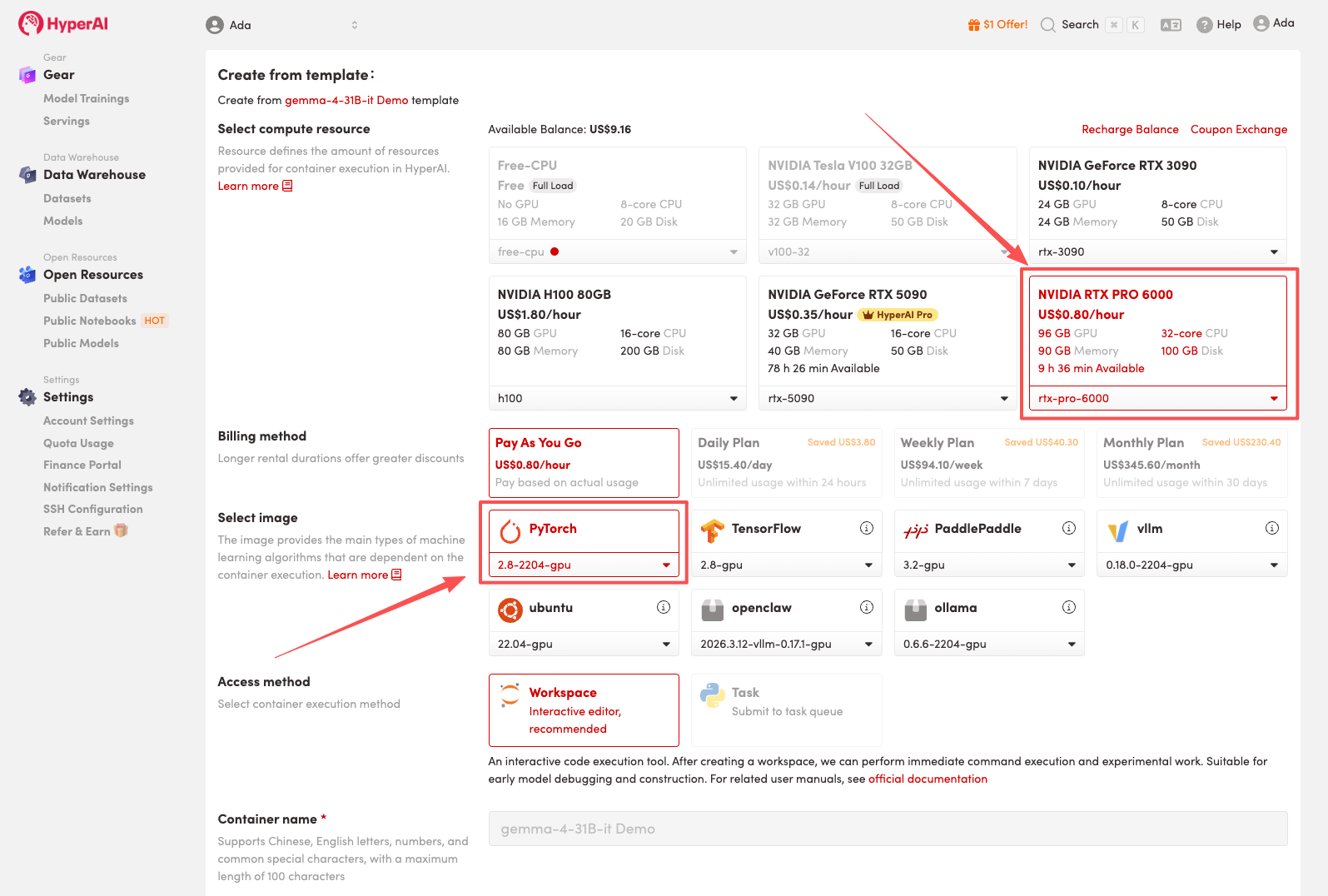
3. Sélectionnez les images « NVIDIA RTX PRO 6000 » et « PyTorch », puis cliquez sur « Continuer l'exécution de la tâche ».
HyperAI propose un bonus d'inscription pour les nouveaux utilisateurs : pour seulement $1, vous pouvez obtenir 20 heures de puissance de calcul RTX 5090 (au lieu de $7), et les ressources sont valables indéfiniment.
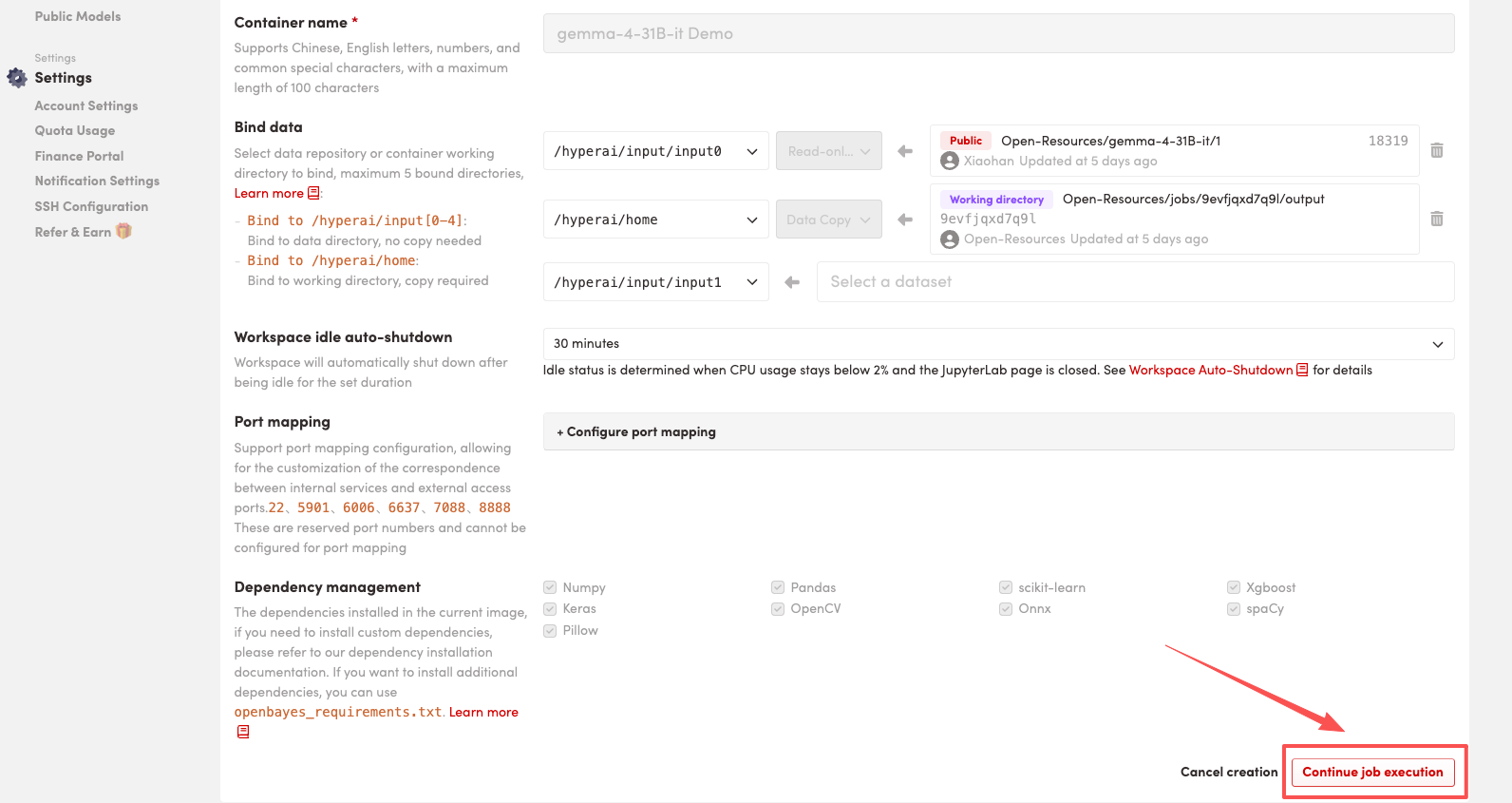
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
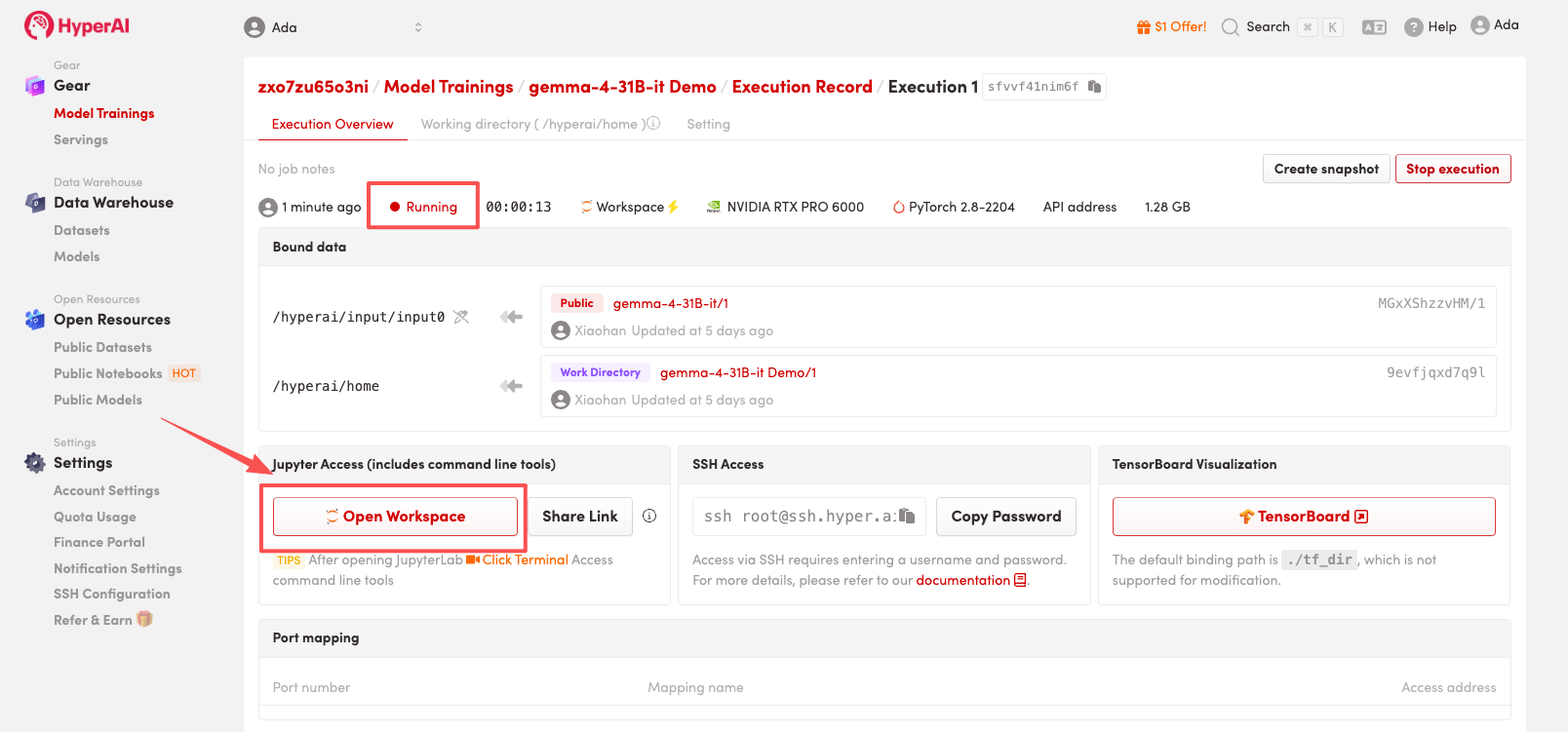
Affichage des effets
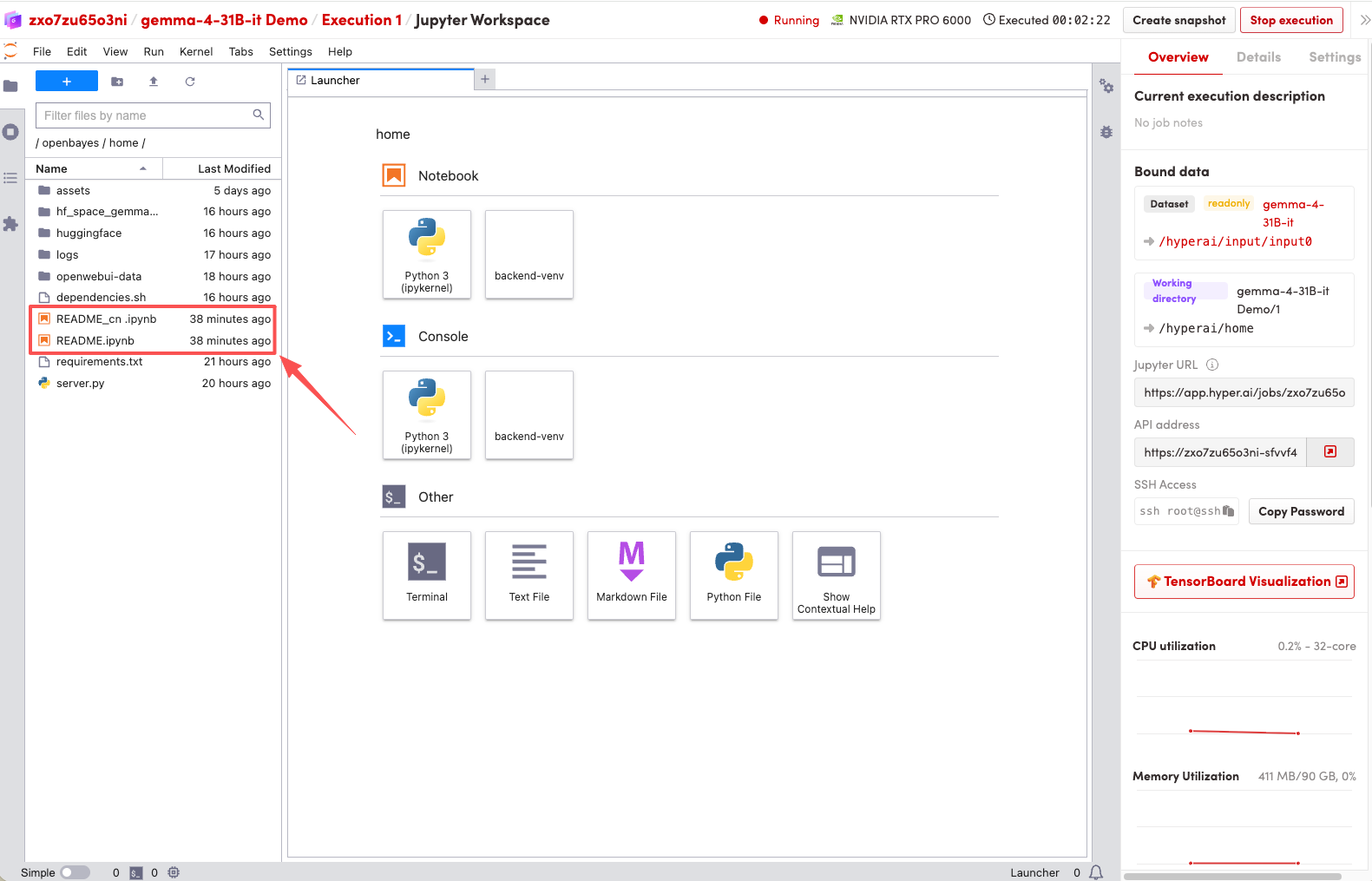
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
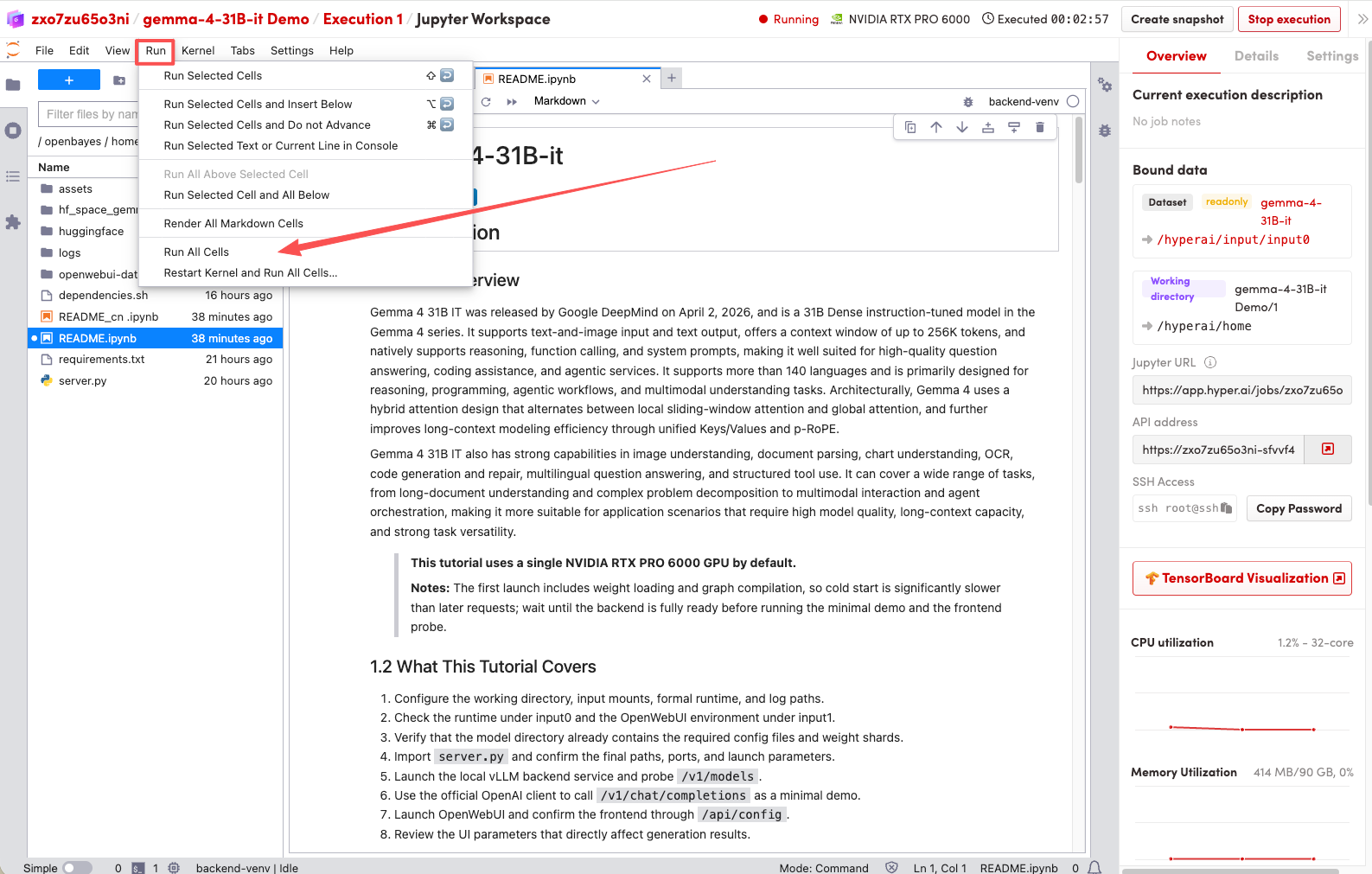
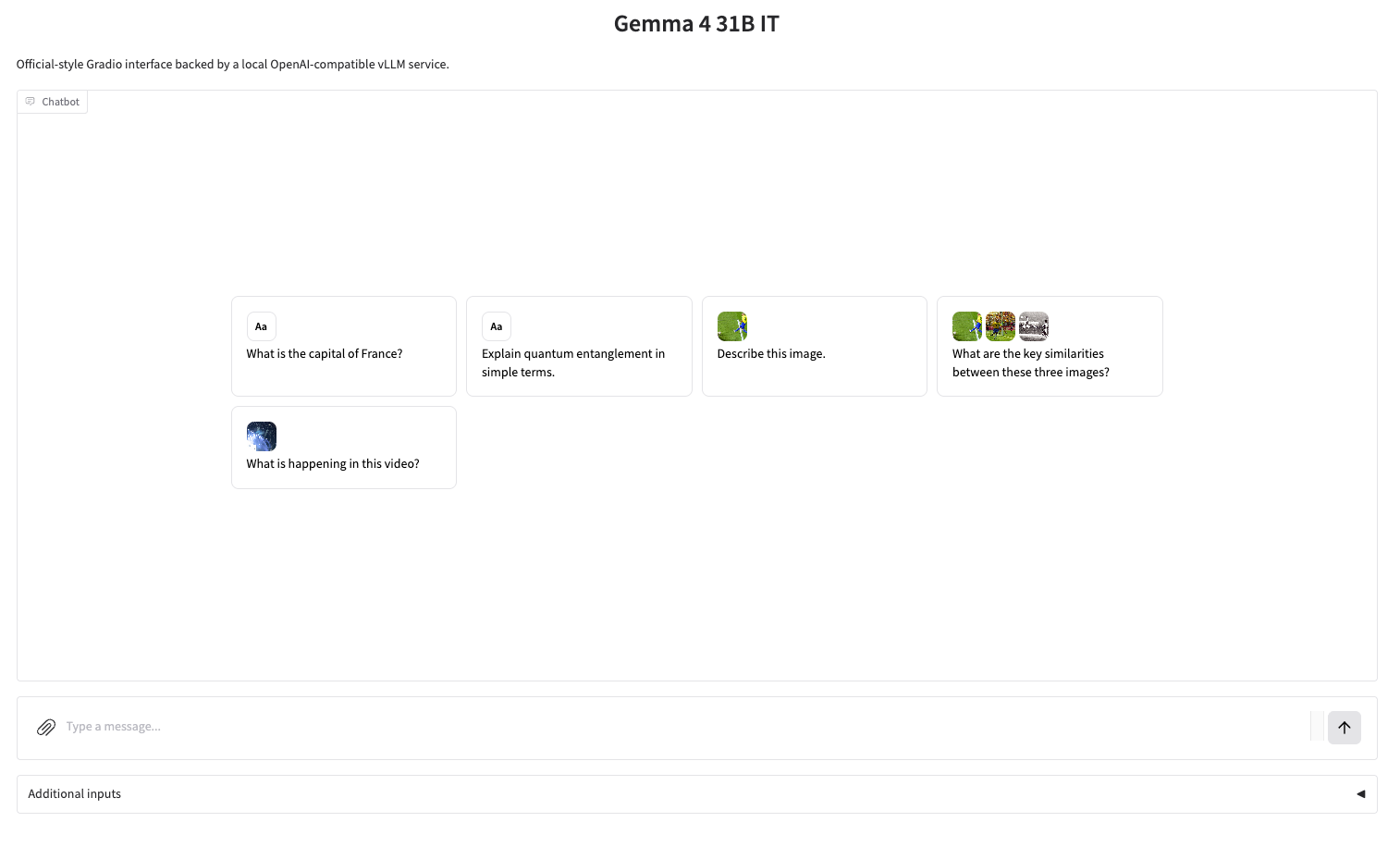
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour accéder à la page de démonstration.