Command Palette
Search for a command to run...
Tutoriel En Ligne | Qwen 3.5 27B Distillation Des Capacités d'inférence De Claude 4.6 Opus : Équilibre Entre Production De Haute Qualité Et Déploiement À Faible Barrière

Ces dernières années, les modèles à grande échelle ont évolué de manière continue vers des capacités de raisonnement plus robustes et une efficacité accrue. Améliorer la qualité de la résolution des problèmes complexes tout en préservant la puissance expressive du modèle est devenu un enjeu majeur pour l'industrie. Dans ce contexte, une nouvelle génération de modèles, intégrant une distillation de raisonnement de haute qualité à une optimisation par pensée structurée, s'impose progressivement comme la voie de recherche dominante.
Mars 2026,Jackrong a mis en open source un modèle d'inférence haute performance, Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled.Construit sur l'infrastructure Qwen3.5-27B, il intègre des capacités de raisonnement avancées issues de Claude-4.6 et d'Opus, améliorant considérablement les performances de résolution de problèmes complexes et d'interaction de dialogue à plusieurs tours tout en conservant ses solides capacités originales de compréhension et d'expression du langage.
Au niveau de compétence de baseCe modèle améliore considérablement les capacités de raisonnement grâce à l'introduction d'une technologie de distillation de la chaîne de pensée de haute qualité, ce qui le rend particulièrement performant dans des domaines tels que la dérivation mathématique, l'analyse logique, la planification et la prise de décision, ainsi que la décomposition de tâches en plusieurs étapes. Comparé aux modèles traditionnels, ce système peut non seulement générer des réponses, mais aussi analyser les problèmes étape par étape de manière structurée, en décomposant les tâches complexes en étapes logiques claires et exécutables. Il améliore ainsi la stabilité globale du raisonnement et la fiabilité des résultats.
En termes d'expérience interactive,Ce modèle prend en charge un mécanisme de génération de dialogues en flux continu basé sur des jetons, permettant une sortie quasi instantanée, mot à mot, pour une expérience de dialogue plus naturelle et fluide. Parallèlement, le système offre des options de paramétrage flexibles, notamment des éléments de configuration clés tels que la température, le nombre maximal de mots et la longueur maximale de sortie, permettant aux développeurs d'ajuster le style de génération et la stratégie de sortie en fonction des différents scénarios d'application.
En termes de mise en œuvre technique,Ce modèle offre un équilibre optimal entre performance et efficacité grâce à ses 27 milliards de paramètres, garantissant ainsi une qualité de rendu élevée et une grande facilité de déploiement. De plus, il prend en charge les invites système personnalisées, permettant aux utilisateurs de définir des rôles et des styles d'interaction adaptés à leurs besoins, pour une expérience utilisateur hautement personnalisée. Parallèlement, le système dispose de fonctionnalités complètes de gestion de session, assurant la continuité du contexte et permettant d'effacer et de reprendre une conversation, ce qui améliore la stabilité lors des échanges prolongés.
Dans les applications pratiques,Ce modèle offre une assistance au dialogue intelligent performante dans de nombreux domaines. Par exemple, il possède d'excellentes capacités d'analyse logique pour les tâches de raisonnement complexes ; il peut être utilisé pour l'interprétation d'articles scientifiques et la conception d'expériences ; il prend en charge la génération de code et les suggestions de débogage en programmation ; et il peut servir à répondre à des questions approfondies et à expliquer des connaissances dans un contexte éducatif.
à l'heure actuelle,La section tutoriels du site web HyperAI (hyper.ai) propose désormais « Déploiement en un clic de Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled ».Venez découvrir notre modèle d'inférence haute performance !
Exécutez en ligne :
Essai de démonstration
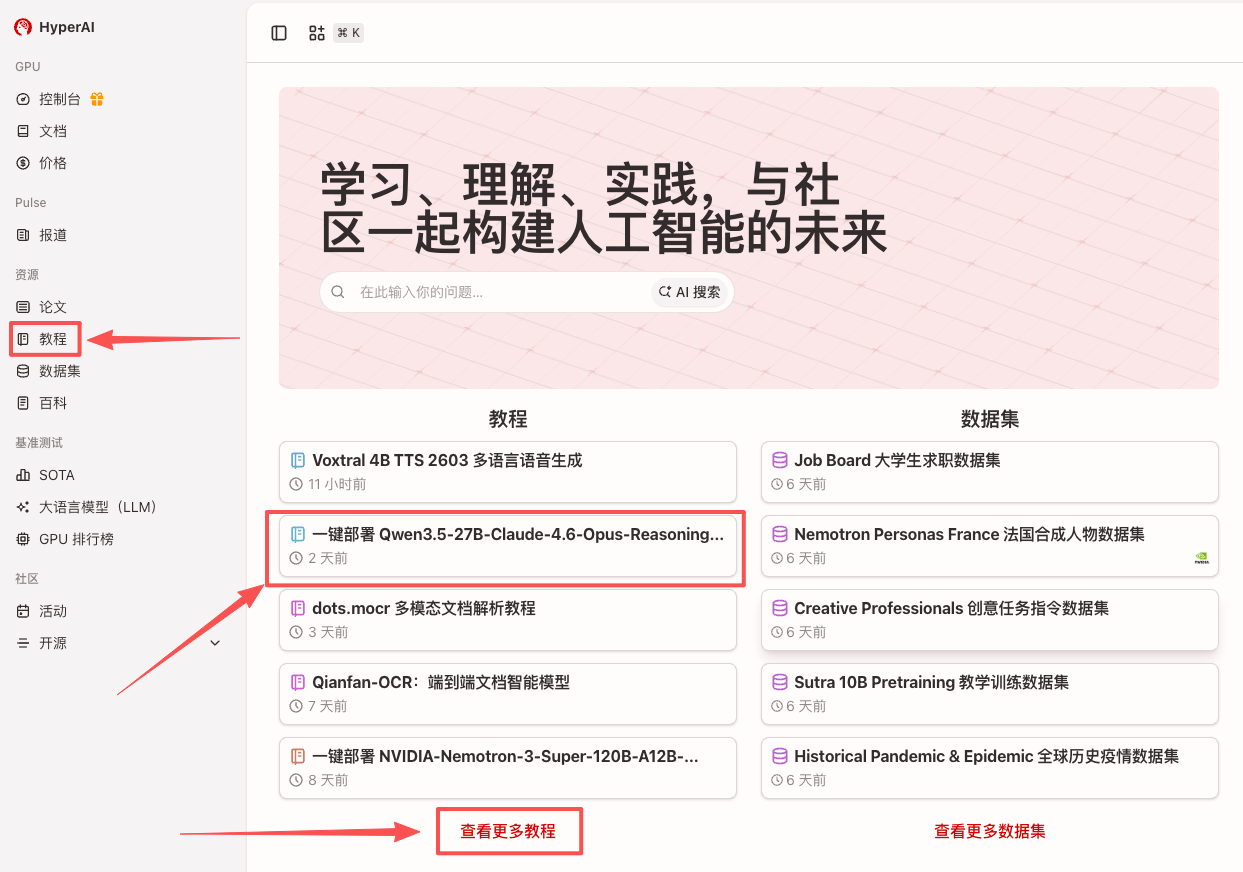
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels » ou cliquez sur « Voir plus de tutoriels », sélectionnez « Déploiement en un clic de Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled » et cliquez sur « Exécuter ce tutoriel en ligne ».
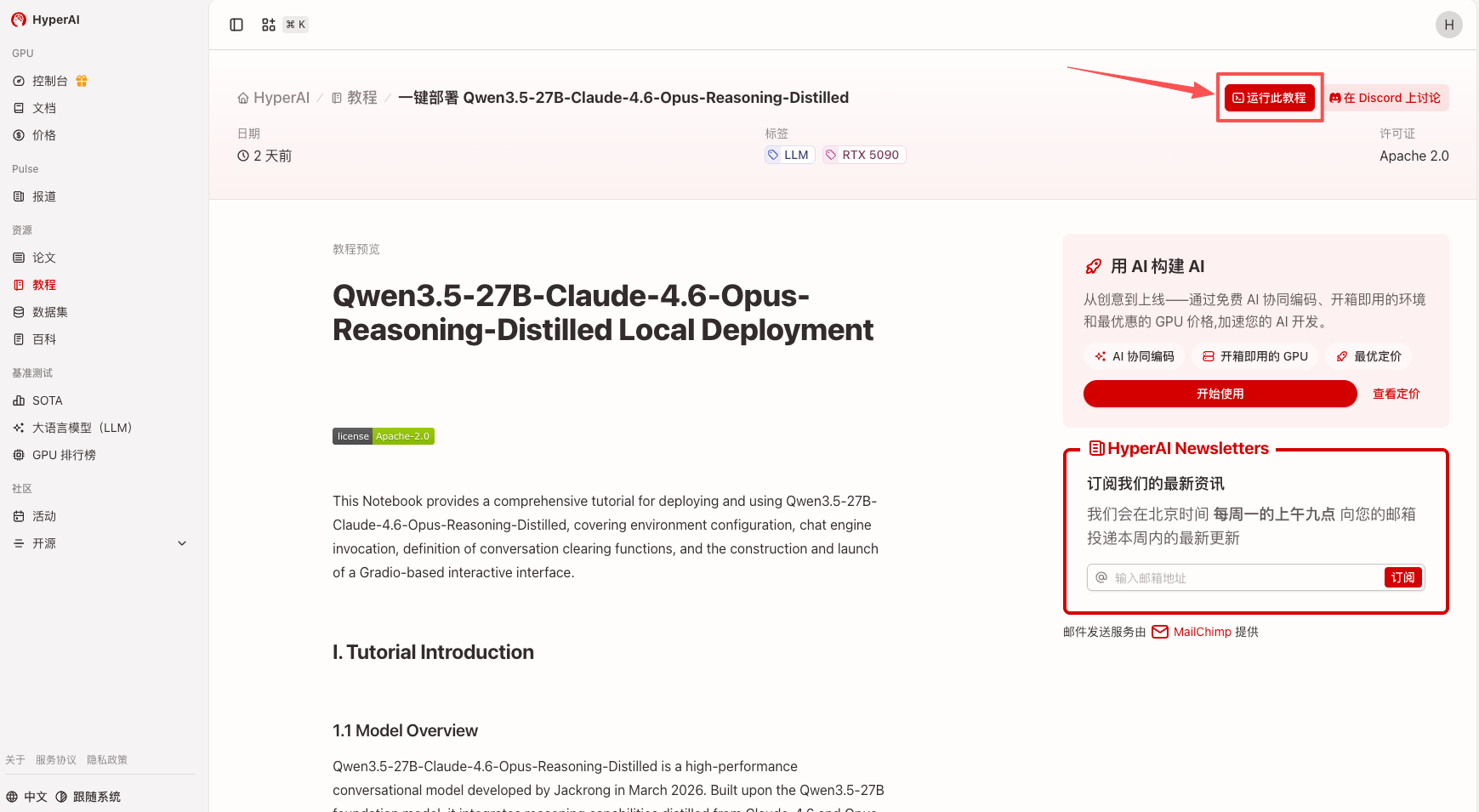
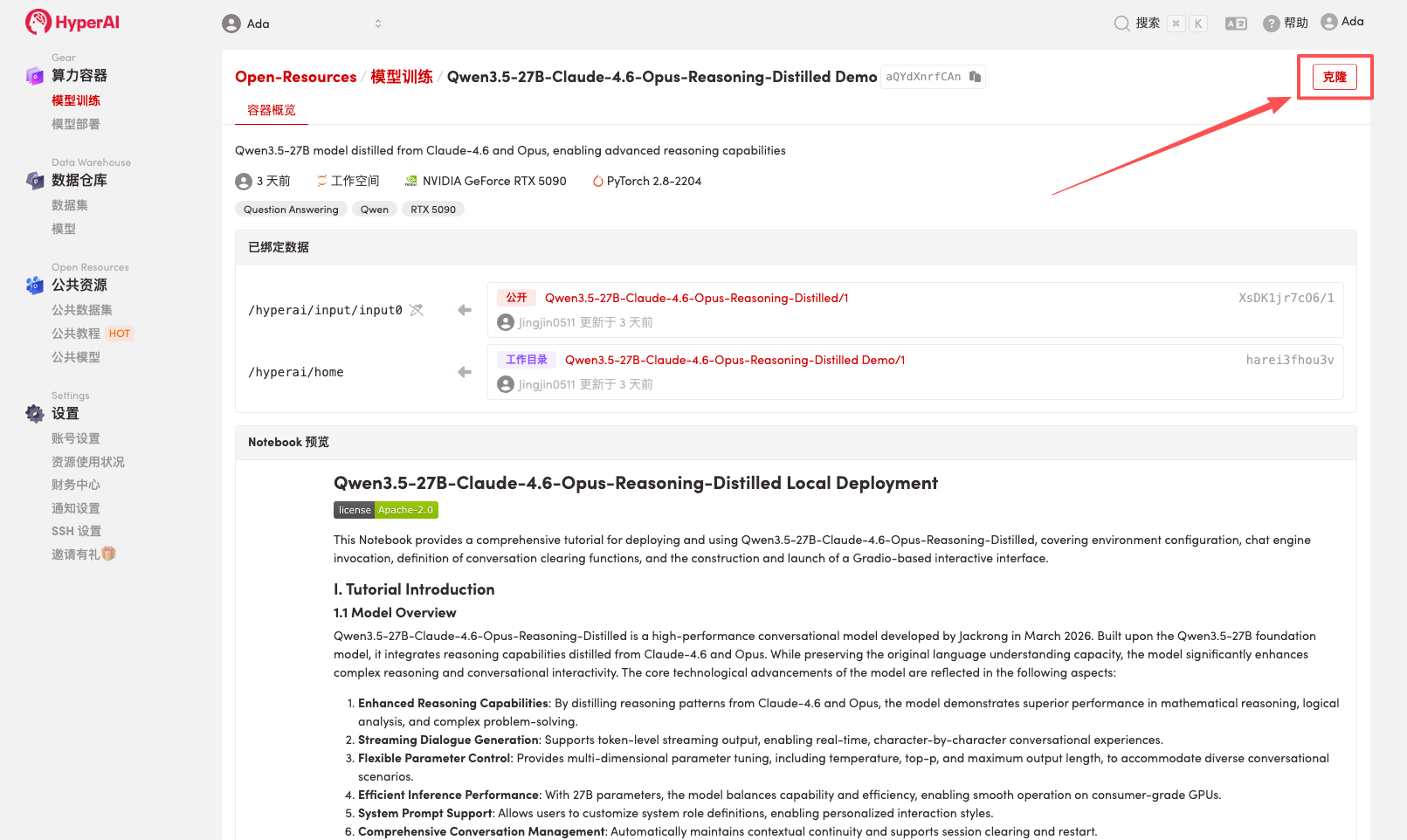
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
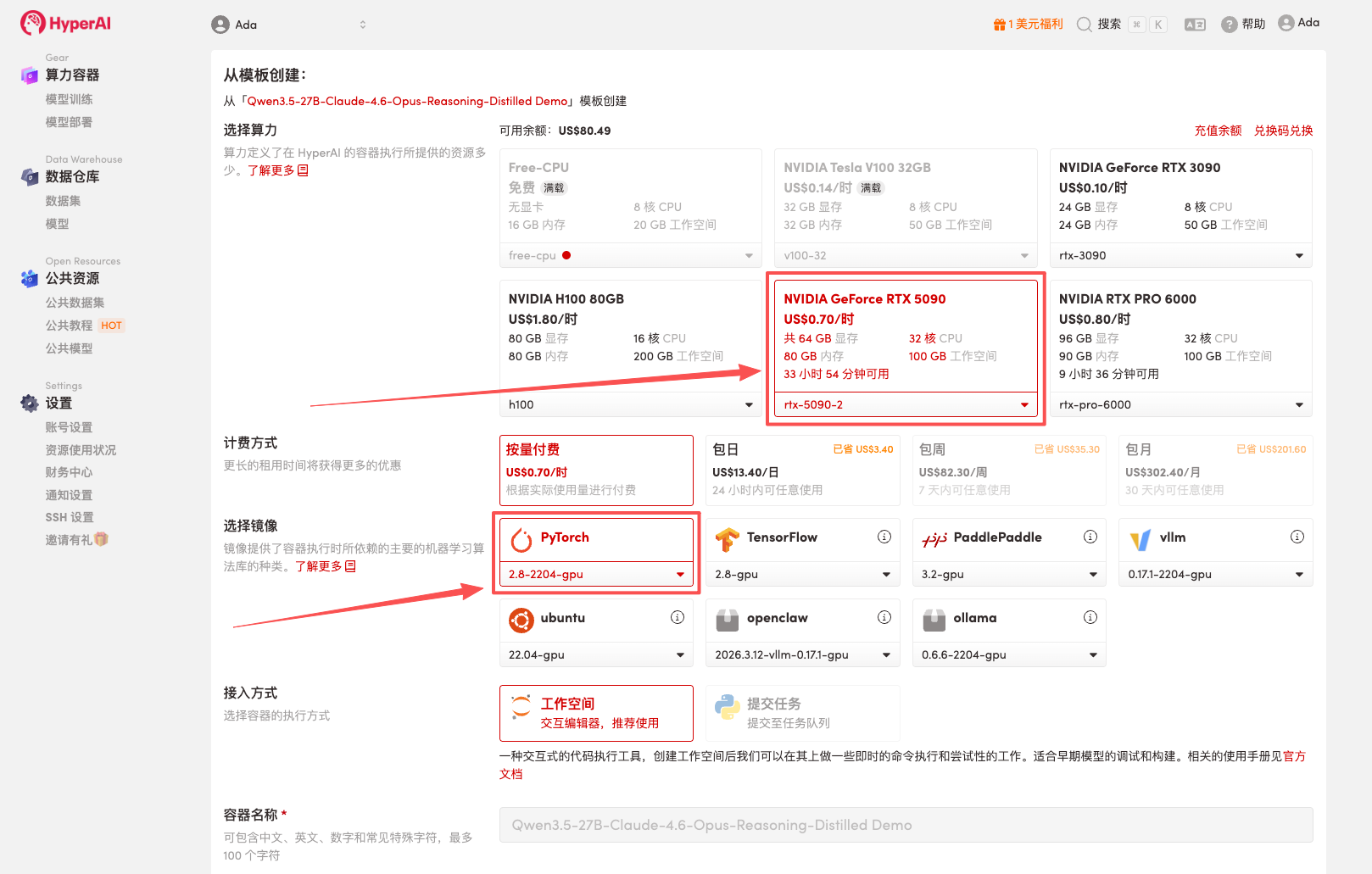
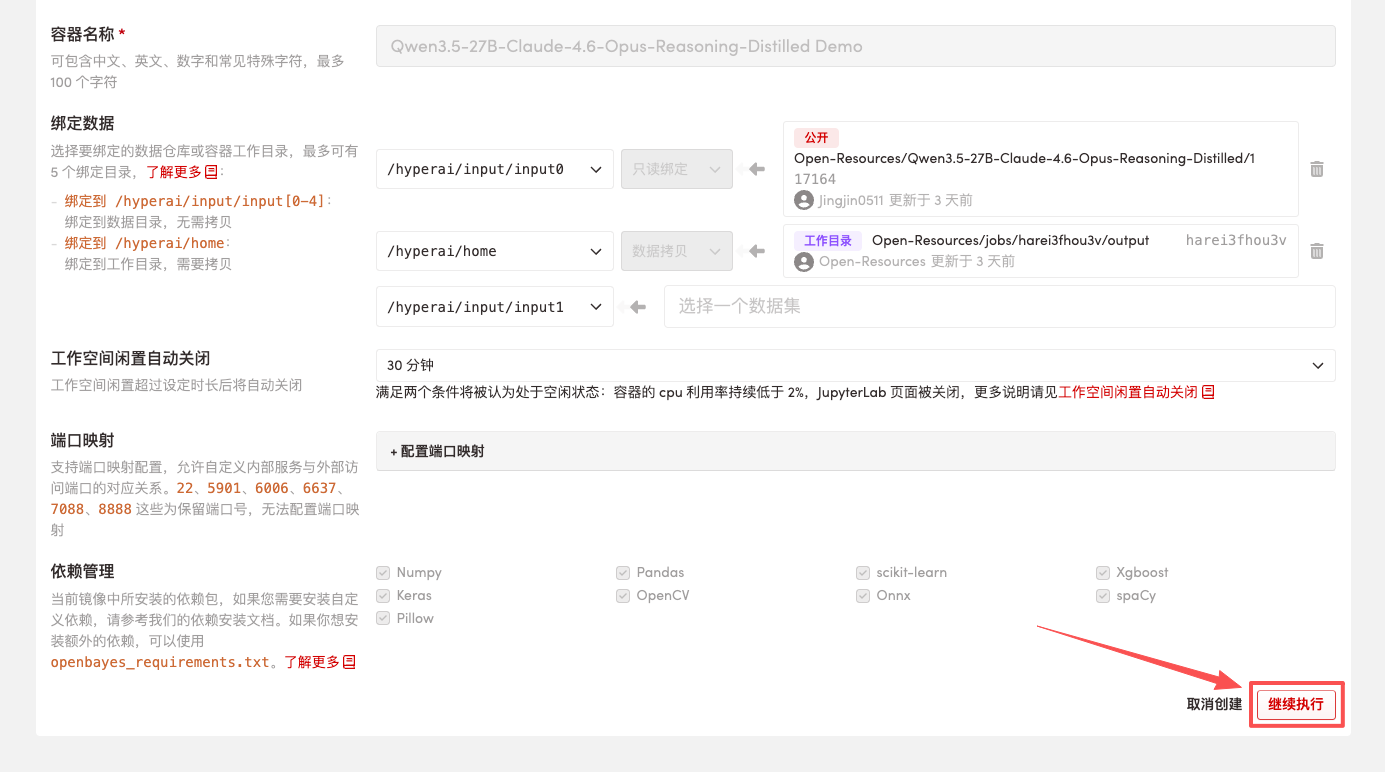
3. Sélectionnez les images « NVIDIA RTX 5090 » et « PyTorch », puis cliquez sur « Continuer l'exécution de la tâche ».
HyperAI propose un bonus d'inscription pour les nouveaux utilisateurs : pour seulement $1, vous pouvez obtenir 20 heures de puissance de calcul RTX 5090 (au lieu de $7), et les ressources sont valables indéfiniment.
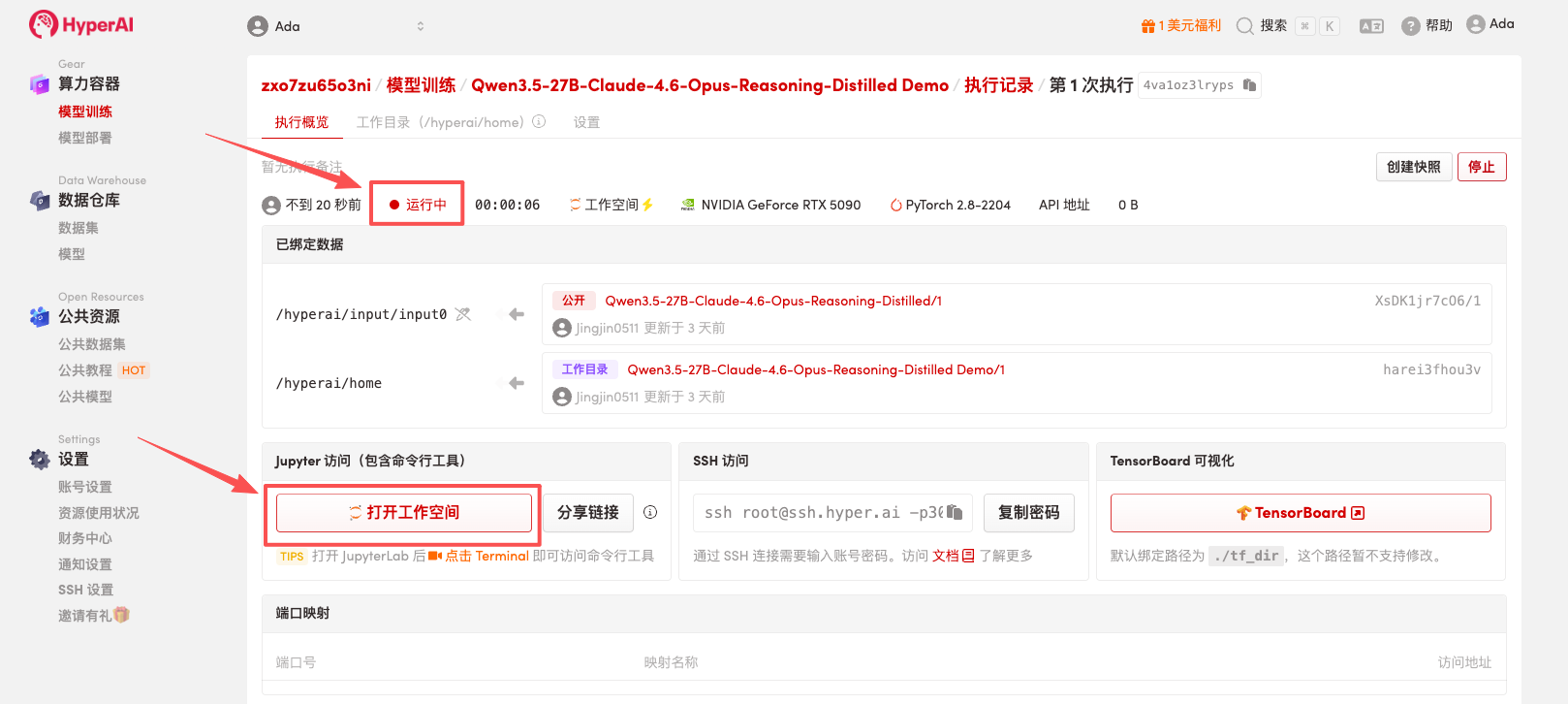
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
Affichage des effets
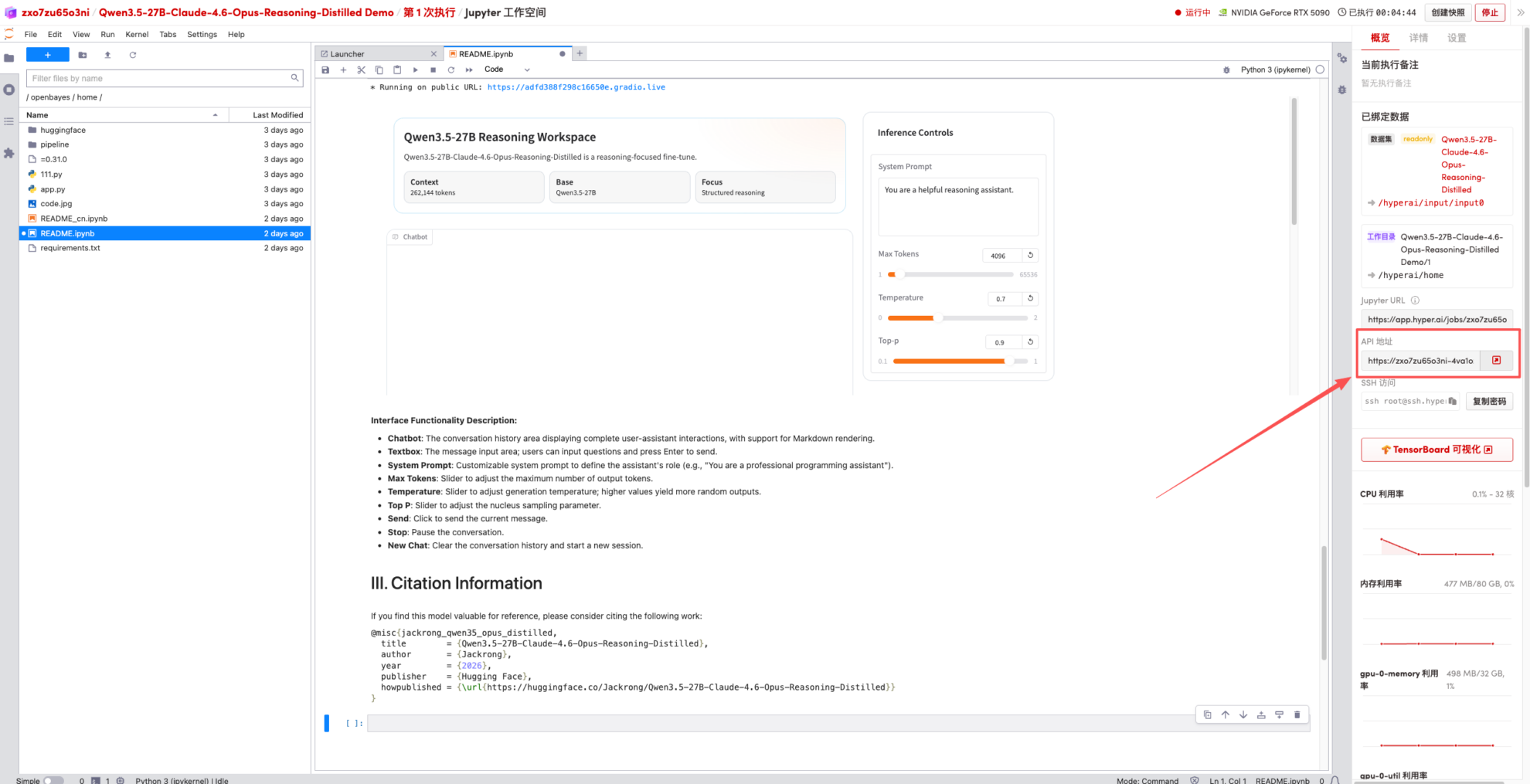
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
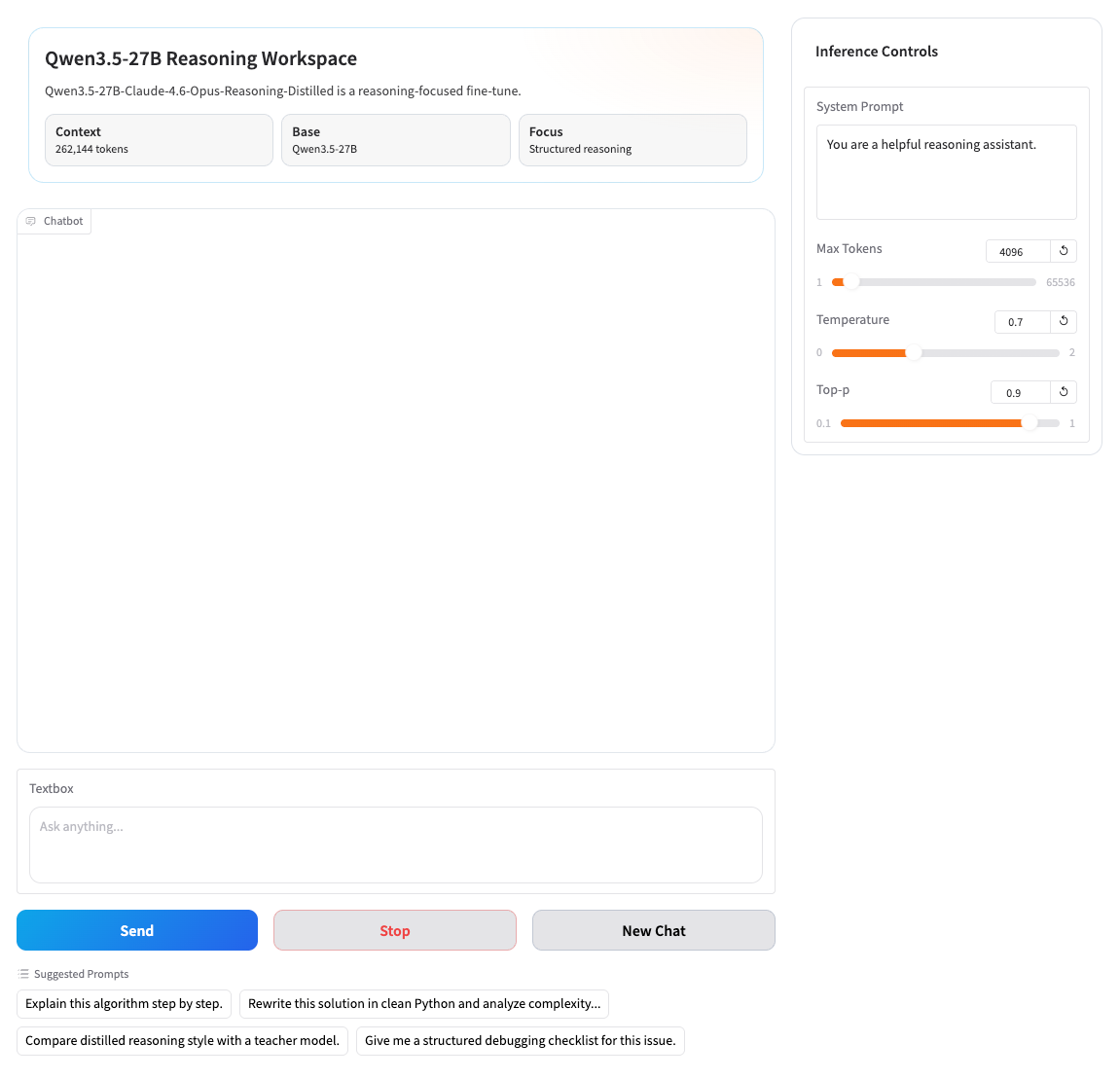
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour accéder à la page de démonstration.