Command Palette
Search for a command to run...
Tutoriels En Ligne | Déploiement Rapide Avec Des Ressources CPU Gratuites, Couvrant Des Modèles open-source Populaires Tels Que Qwen 3.5/DeepSeek-R1/Gemma 3/Llama 3.2, etc.

Le rythme d'itération des modèles open source s'accélère de façon exponentielle. Des géants de la tech aux startups en passant par les équipes de recherche, de nouveaux modèles émergent constamment lors de divers tests de performance. Cependant, dans cette ère de l'IA en pleine effervescence, des obstacles persistent pour les développeurs souhaitant adopter les technologies innovantes.
Aujourd'hui, la communauté open source développe rapidement un écosystème de modélisation très actif. Dans ce contexte, de plus en plus de développeurs souhaitent déployer et tester de nouveaux modèles plus facilement et plus rapidement afin d'évaluer leurs capacités et d'explorer des scénarios d'application potentiels. Cependant, en pratique…Le coût des ressources GPU, la complexité des configurations d'environnement et les importantes limitations matérielles restent des obstacles majeurs pour de nombreux développeurs qui tentent de déployer des modèles.
En effet, grâce à l'optimisation continue des techniques de quantification et des cadres de raisonnement,De nombreux modèles open source courants sont déjà capables d'effectuer des inférences de base et des vérifications fonctionnelles dans un environnement CPU.Cela offre aux développeurs de nouvelles possibilités d'expérimentation sur les modèles et de développement de prototypes à moindre coût.
Il convient de mentionner que, afin de faciliter un déploiement rapide et sans obstacles des projets pour les développeurs du monde entier,HyperAI offre des quotas de processeur gratuits, les utilisateurs de la version Basic pouvant exécuter une seule tâche pendant 12 heures en continu et les utilisateurs de la version Pro pendant 24 heures en continu.Parallèlement, la section « Tutoriels » d'HyperAI propose désormais des tutoriels en ligne pour exécuter sur CPU des modèles open source populaires tels que Qwen, DeepSeek, Gemma, Llama et GLM. Ces tutoriels décrivent le processus de déploiement complet, de la préparation de l'environnement au téléchargement du modèle, en passant par l'inférence et l'exécution. Ils permettent ainsi aux utilisateurs de se familiariser avec l'inférence de modèles et d'effectuer des tests de développement de base sans avoir à déployer un environnement local complexe.
Cliquez ici pour en savoir plus sur HyperAI Pro :Utilisation gratuite du processeur / 30 heures de crédit d'utilisation du GPU / 70 Go de stockage ultra-large, HyperAI Pro est officiellement lancé !
Déploiement du processeur Qwen3.5-9B-GGUF :
Déploiement du processeur de Qwen2.5-14B-Instruct-GGUF :
Déploiement du processeur de Qwen2.5-3B-Instruct-GGUF :
Déploiement du processeur DeepSeek-R1-Distill-Qwen-1.5B-GGUF :
Déploiement du processeur DeepSeek-Coder-V2-Lite-Instruct-GGUF :
Déploiement CPU de Gemma-3-1b-it-GGUF :
Déploiement du processeur de Llama-3.2-3B-Instruct-GGUF :
Déploiement CPU de gpt-oss-20b-GGUF :
Déploiement sur CPU de Phi-4-mini-instruct-GGUF :
Déploiement CPU de GLM-4-9B-chat-GGUF :
Cet article utilisera « Déploiement de Qwen3.5-9B-GGUF sur CPU » comme exemple pour illustrer le tutoriel.
Essai de démonstration
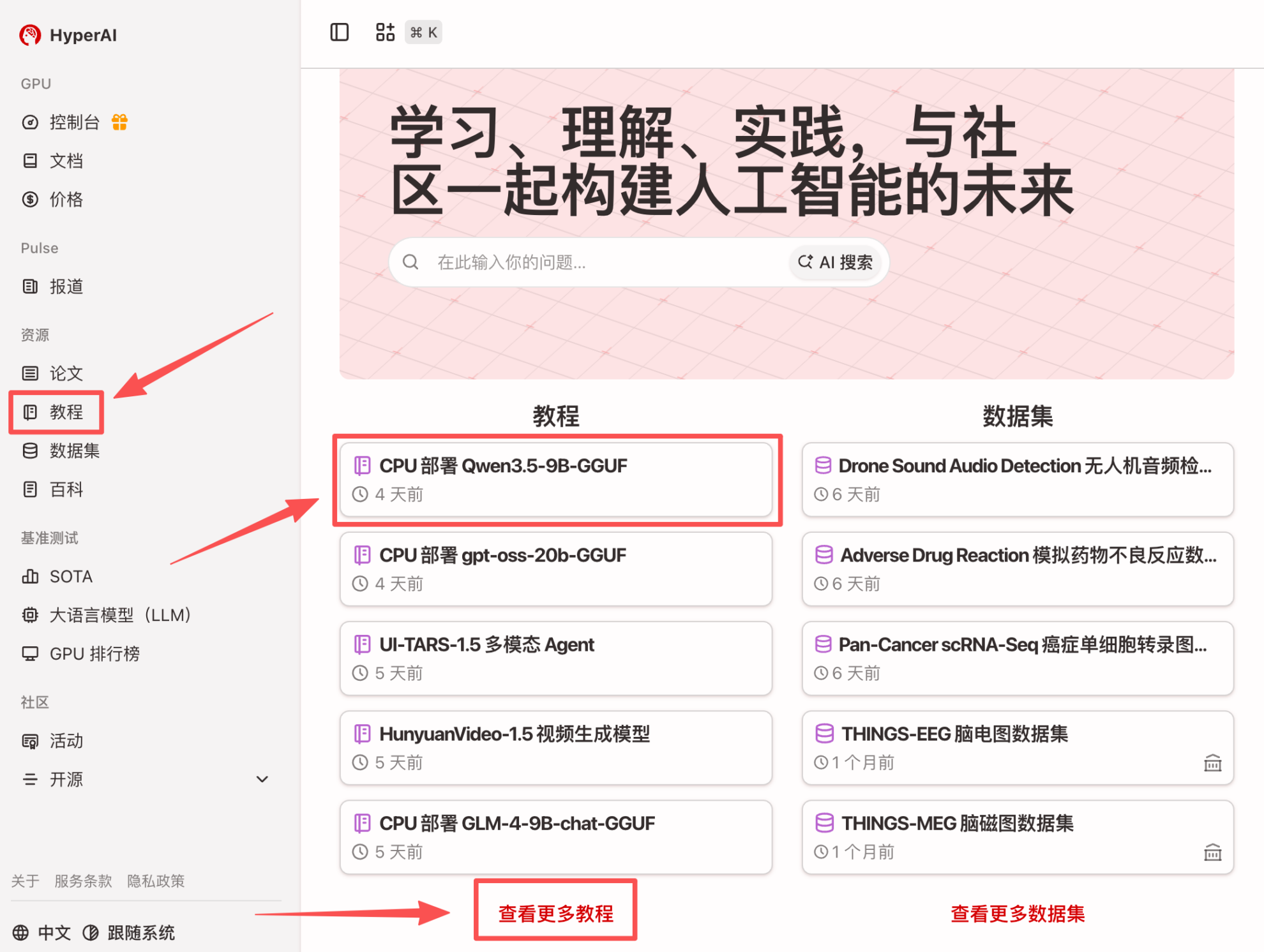
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels », ou cliquez sur « Voir plus de tutoriels », sélectionnez « Déploiement CPU Qwen3.5-9B-GGUF », puis cliquez sur « Exécuter ce tutoriel en ligne ».
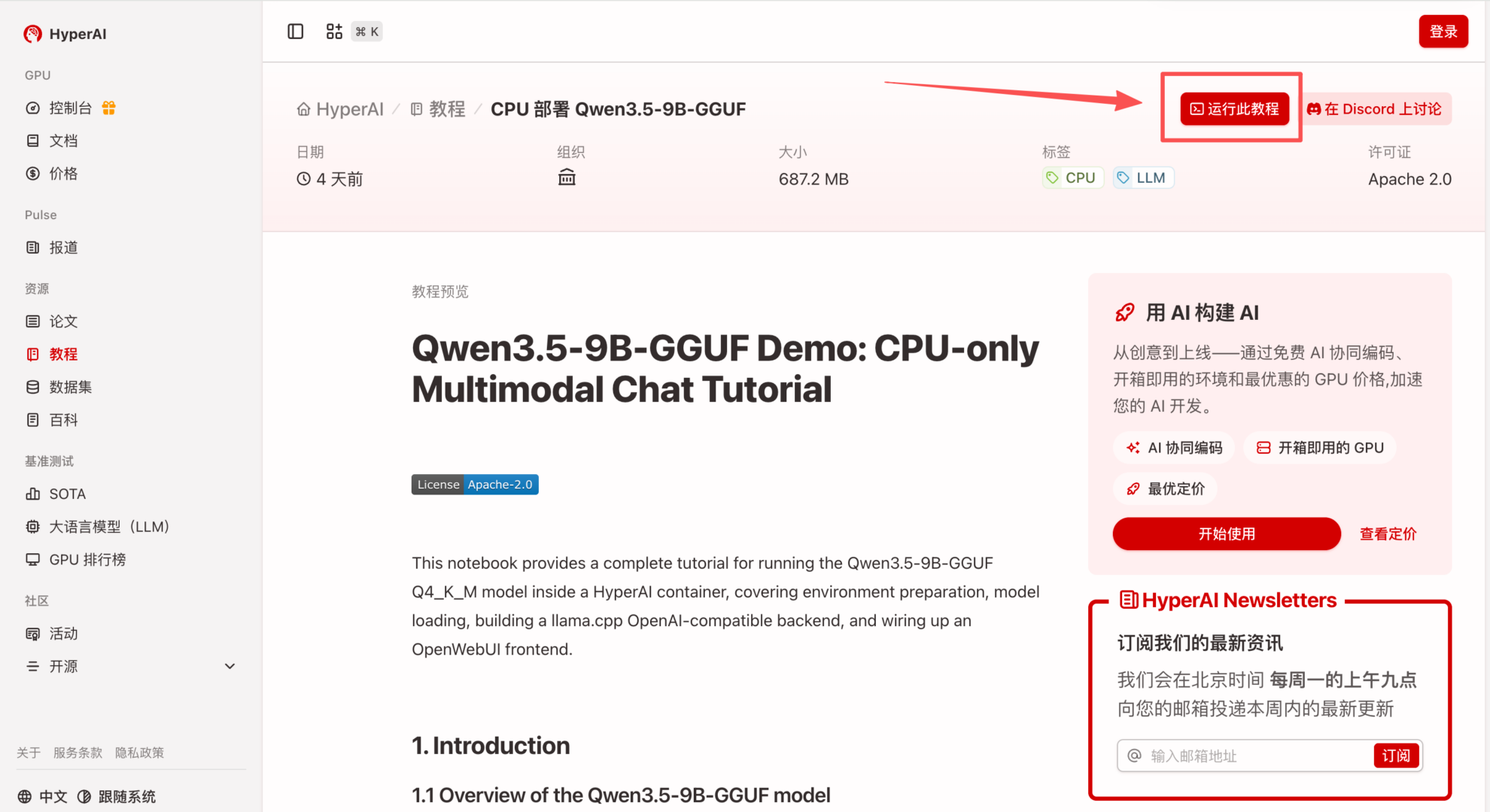
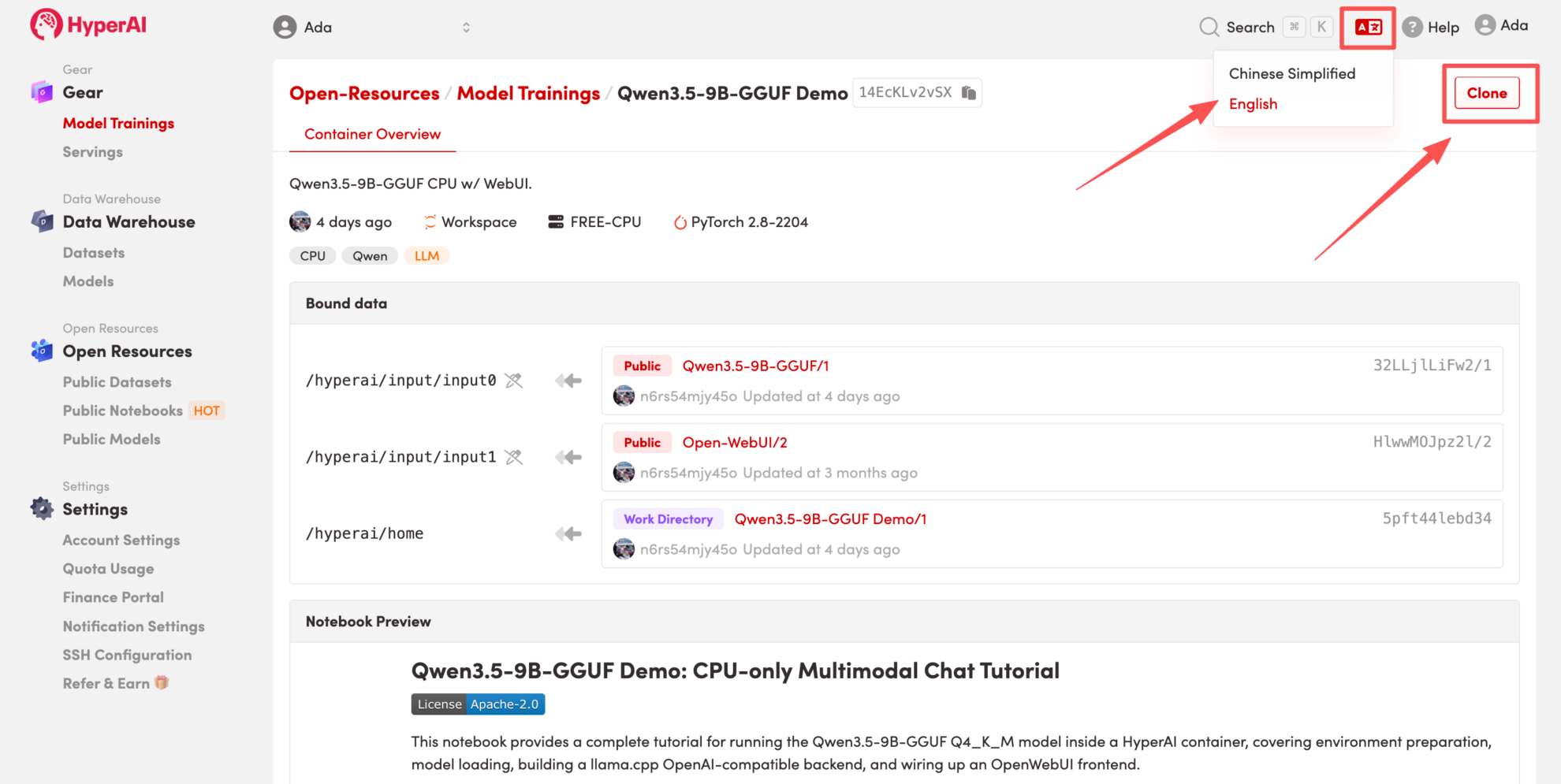
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
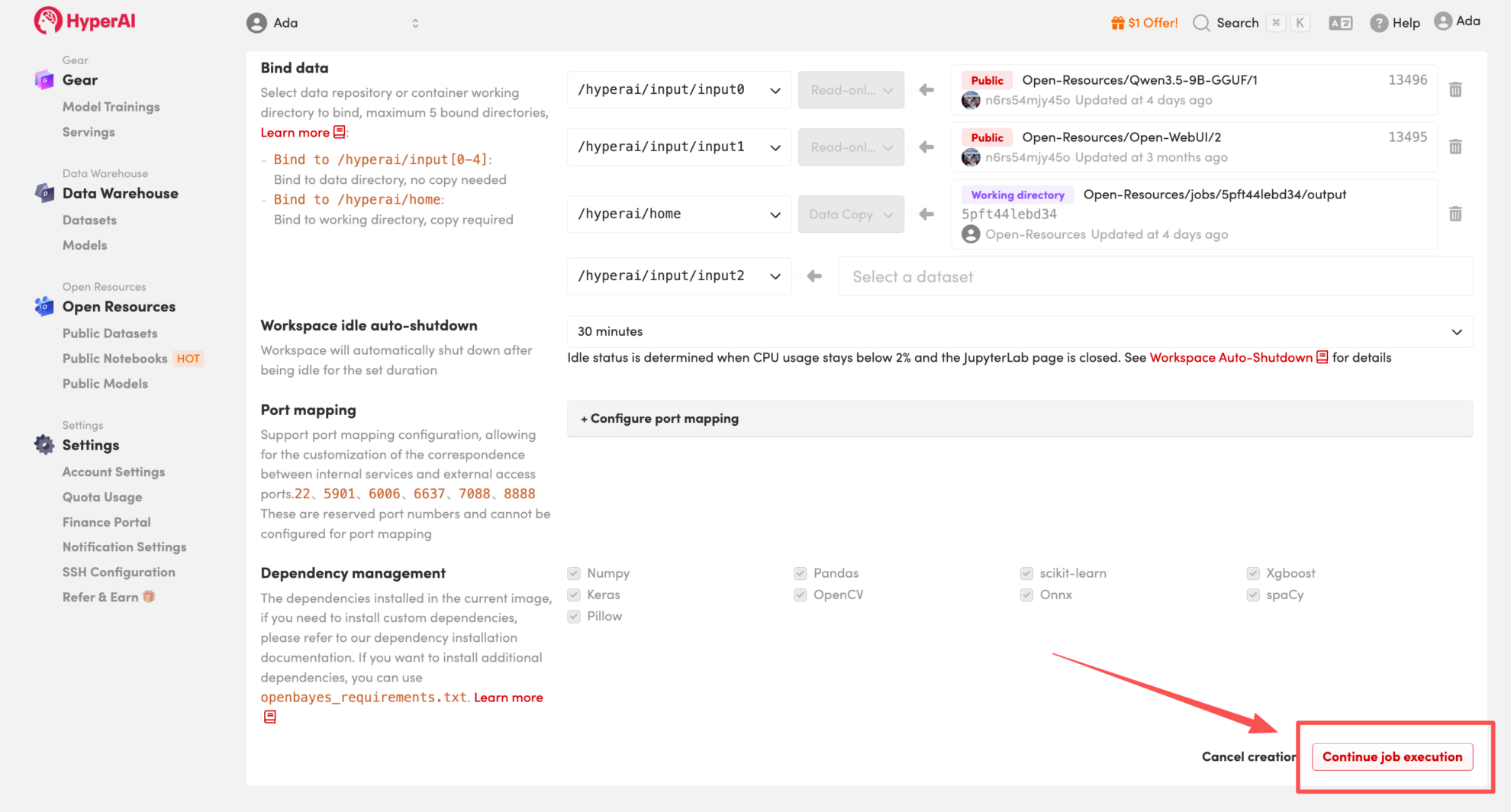
3. Sélectionnez les images « Free-CPU » et « PyTorch », puis cliquez sur « Continuer l'exécution de la tâche ».
HyperAI offre des avantages à l'inscription pour les nouveaux utilisateurs.Pour seulement $1, vous pouvez obtenir 20 heures de puissance de calcul RTX 5090 (prix d'origine $7).La ressource est valide en permanence.
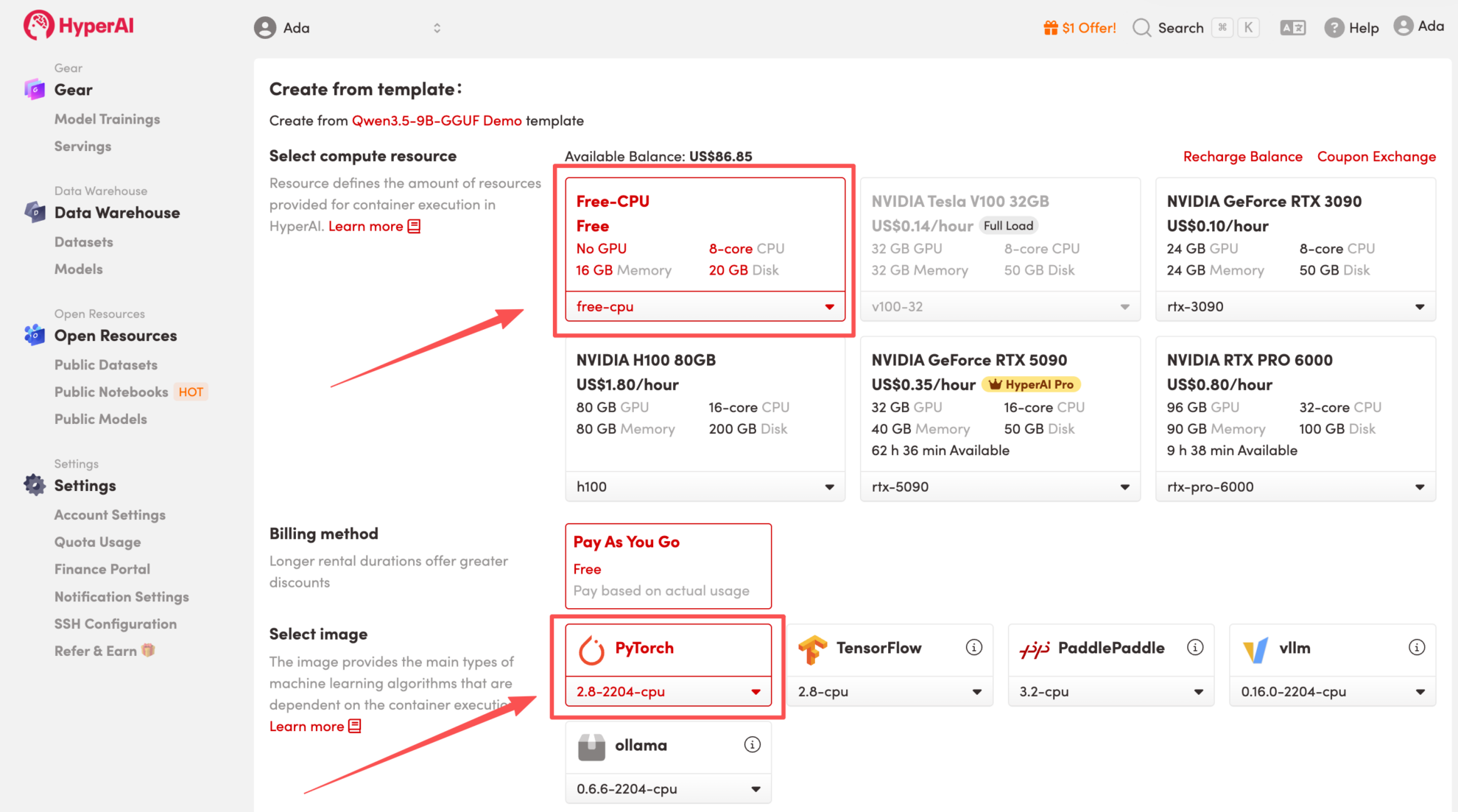
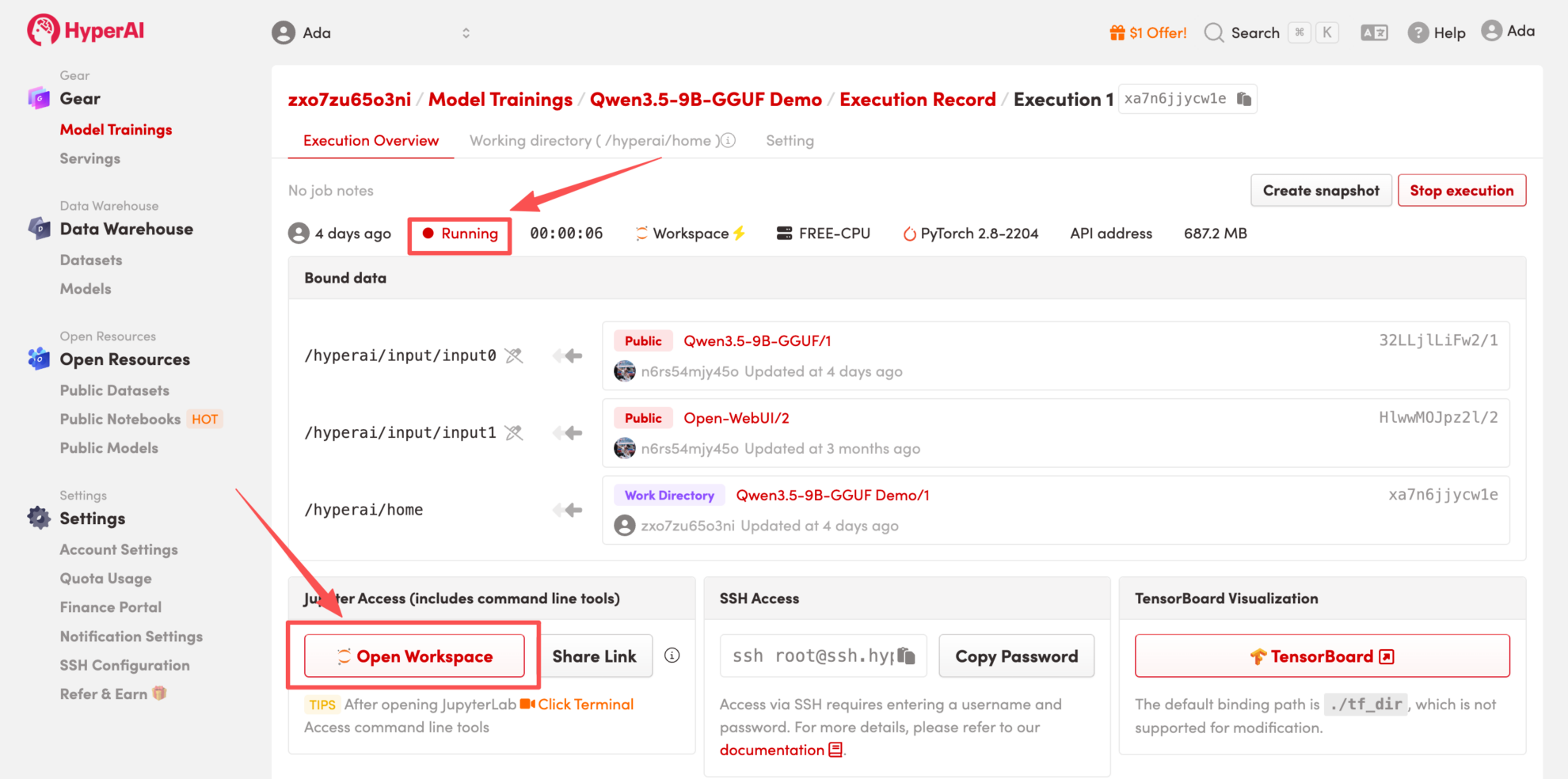
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
Démonstration d'effet
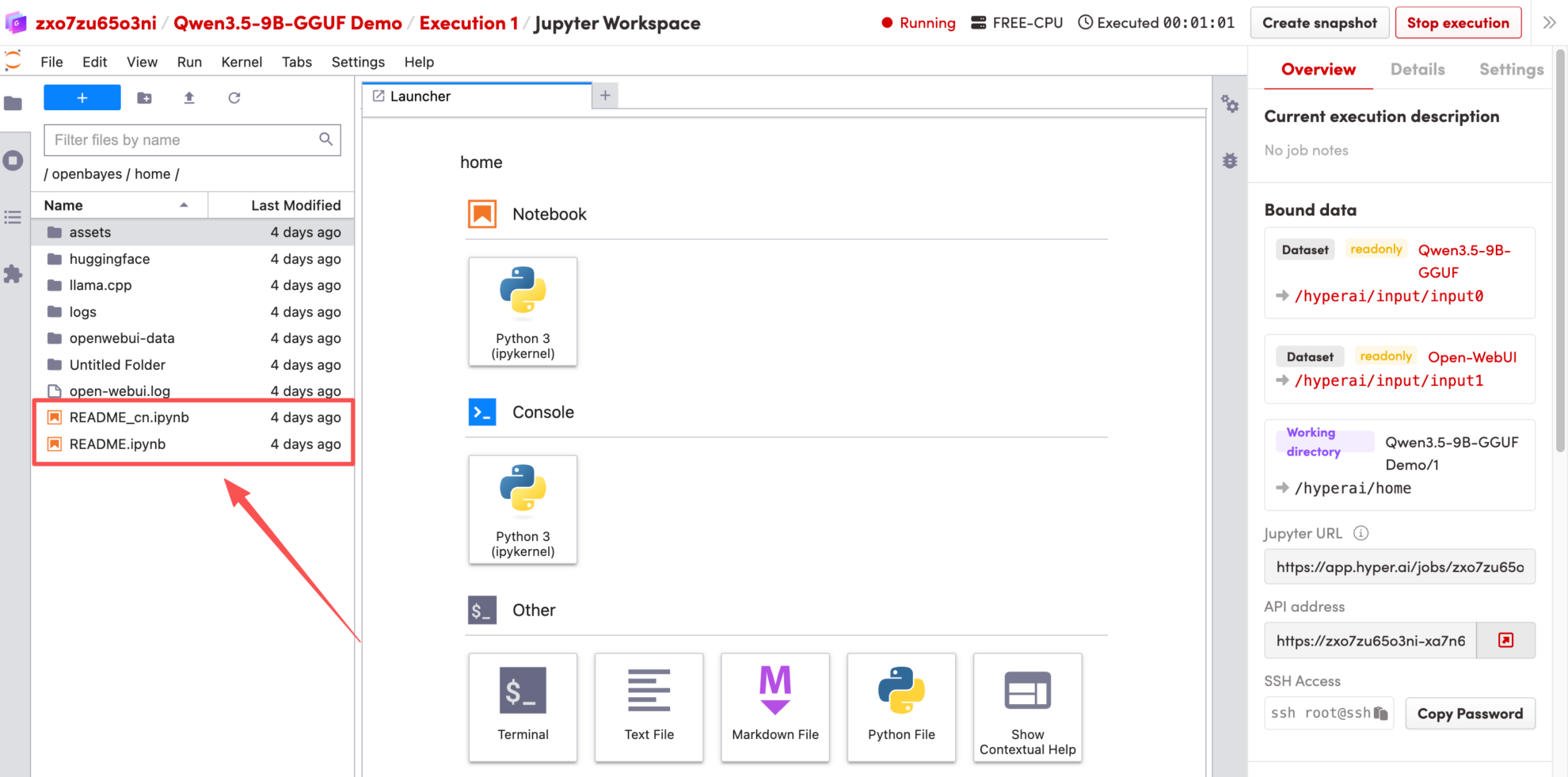
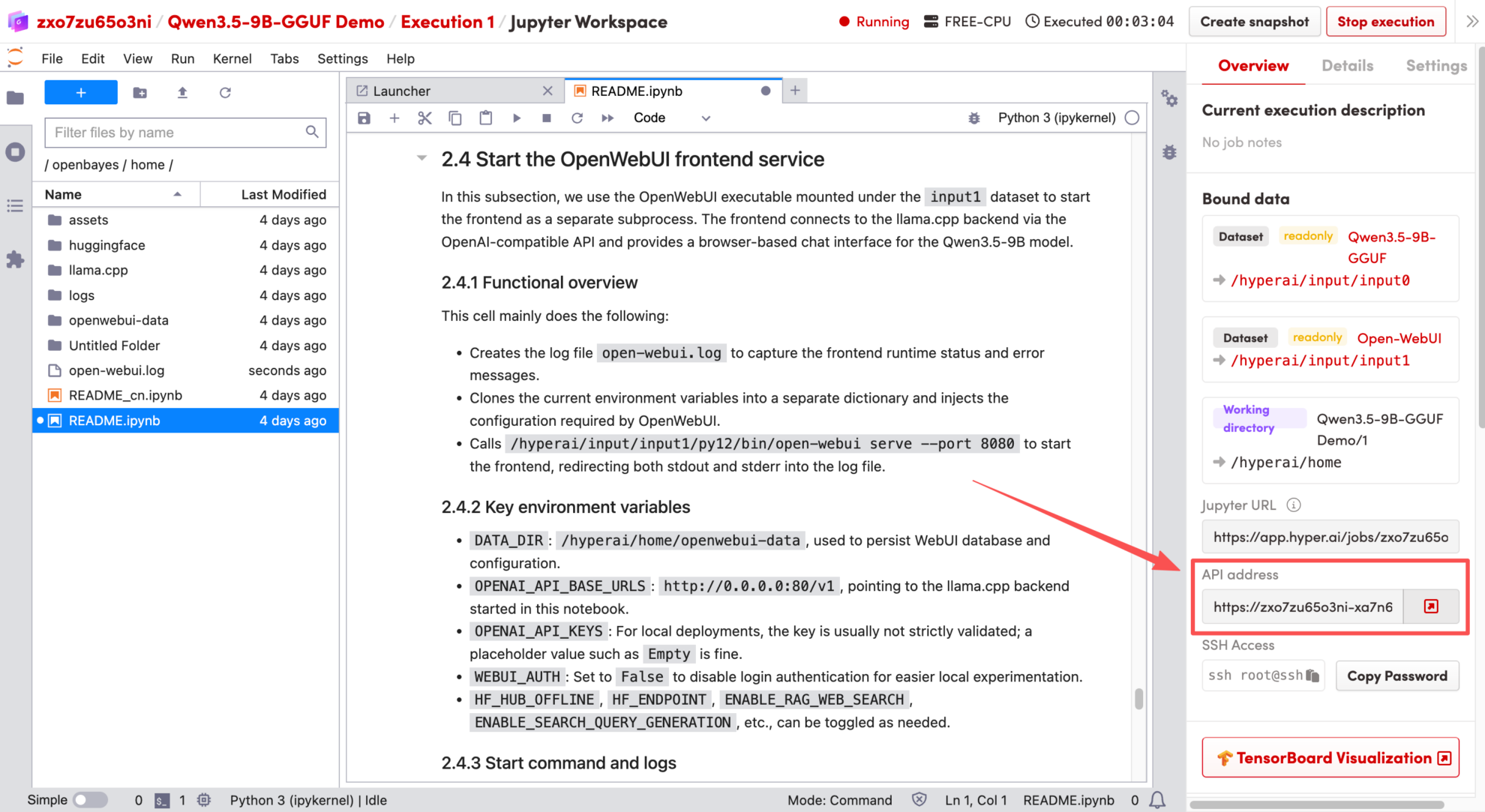
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur Exécuter en haut de la page.
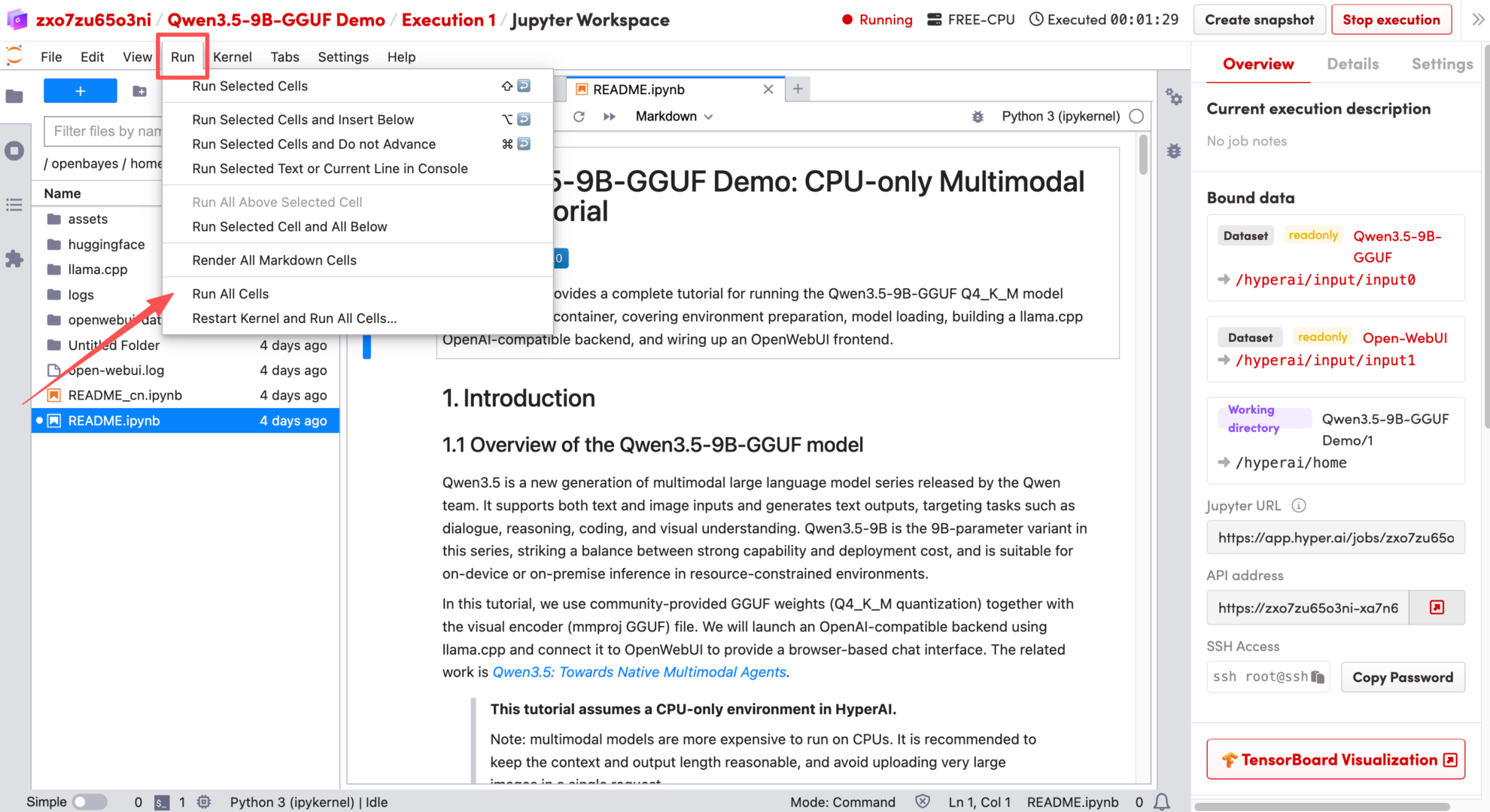
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour accéder à la page de démonstration.

Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !








