Command Palette
Search for a command to run...
Résumé Du Tutoriel | Les Petits Modèles Open Source Atteignent Une Intelligence Globale Comparable À GPT-5 ; Évaluation Unique Des Modèles Populaires Tels Que Qwen 3.5/Gemma 4.

Le 14 avril, l'organisme de test tiers Artificial Analysis a publié un rapport comparatif sur les modèles open source de moins de 32 octets, montrant que…Les Qwen3.5 27B et Gemma 4 31B, deux modèles de petite taille, ont rattrapé le GPT-5 correspondant en termes d'intelligence globale.Parmi eux, Qwen3.5 27B (version d'inférence) a obtenu 42 points sur l'indice d'intelligence, ce qui est comparable à GPT-5 (moyen) ; Gemma 4 31B (version d'inférence) a obtenu 39 points, ce qui correspond à GPT-5 (faible).
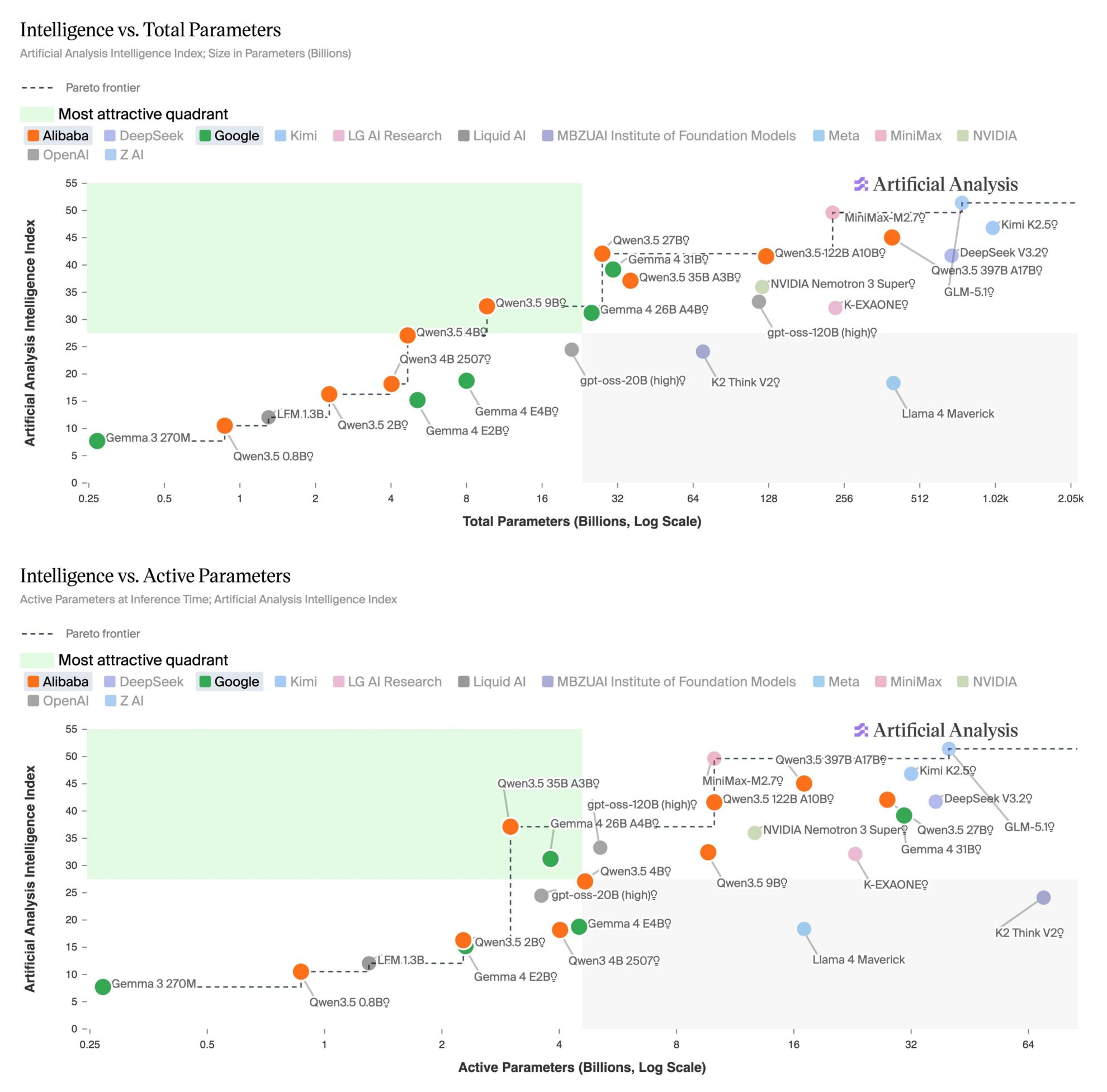
Le rapport indique que cette génération de modèles 32B présente des améliorations significatives en matière de raisonnement et de performances des agents. Qwen3.5 27B a obtenu un score de 55 à l'Agentic Index, surpassant ainsi les 46 points de GPT-5 (niveau moyen) ; Gemma 4 31B surpasse également GPT-5 (niveau faible) sur des tâches complexes telles que TerminalBench Hard et HLE. De plus, les deux modèles prennent en charge nativement les entrées multimodales et figurent parmi les meilleurs modèles open source de leur catégorie pour des tâches de compréhension visuelle comme MMMU-Pro.
Cependant, le modèle le plus petit reste nettement en retrait en termes de précision des connaissances et de contrôle des illusions. Les deux modèles obtiennent respectivement -42 et -45 à l'indice AA-Omniscience, tandis que la version liée à GPT-5 obtient -10, ce qui démontre l'impact persistant de la taille des paramètres sur la capacité de rétention des connaissances.
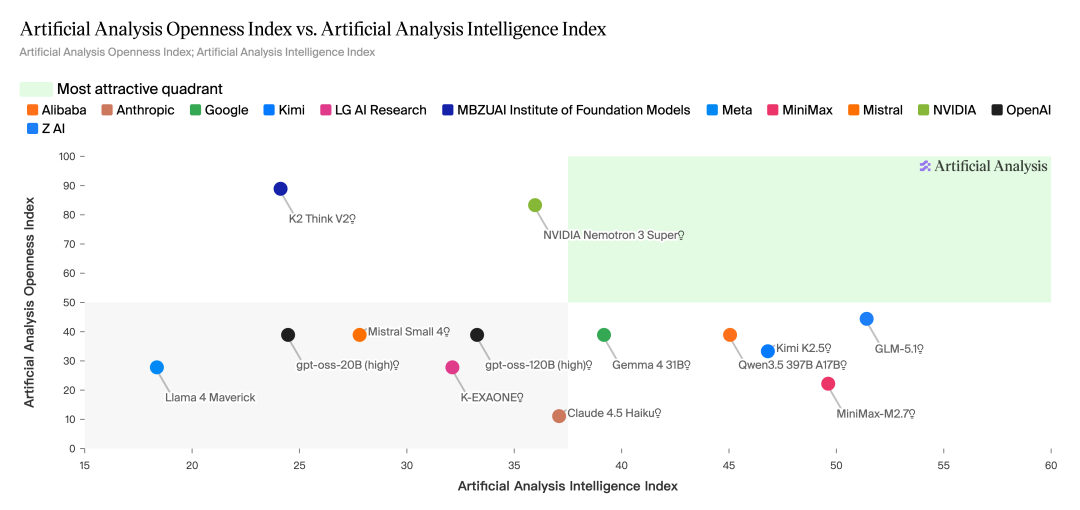
Au niveau du déploiement, la praticité de ces modèles a été considérablement améliorée. Les deux modèles mentionnés ci-dessus peuvent s'exécuter sur une seule carte NVIDIA H100 et être déployés localement sur des appareils personnels grâce à la quantification, ce qui facilite leur adoption. Parallèlement, la communauté open source de pondération dans son ensemble rattrape rapidement son retard, avec des modèles complexes tels que GLM-5.1 qui réduisent l'écart à des scores inférieurs à 10.
Tout au long,Pour aider les développeurs à démarrer rapidement et à valider les derniers modèles open source, HyperAI met à jour en permanence les tutoriels de déploiement en ligne pour les modèles populaires dans la section « Tutoriels » de son site web officiel.Cet article présente les modèles open source de haute qualité mentionnés dans le rapport d'Analyse Artificielle, ainsi que leurs tutoriels de déploiement en un clic. Découvrez des performances exceptionnelles, comparables à celles des modèles propriétaires !
Plus de tutoriels en ligne :
Bienvenue sur notre site web officiel pour plus d'informations :
NVIDIA-Nemotron-3-Super-120B
Le NVIDIA Nemotron 3 Super NVFP4 a été lancé par NVIDIA Corporation en mars 2026. Ce modèle est un grand modèle de langage avec 120 paramètres au total et 12 paramètres d'activation, utilisant une architecture hybride LatentMoE et prenant en charge des contextes jusqu'à 1 million de jetons.
Ce modèle est conçu pour les scénarios impliquant un raisonnement contextuel étendu, des flux de travail d'agents, des appels d'outils, des RAG (Rational Aggregation Groups) et un système de questions-réponses à haut débit. Côté interaction, il permet d'activer ou de désactiver un mode de raisonnement et de basculer entre le mode de questions-réponses classique et le mode de raisonnement amélioré grâce à des paramètres de modèles de conversation standardisés.
Exécutez en ligne :

Qwen3.5-27B-Claude-4.6-Opus–Raisonnement distillé
En mars 2026, Jackrong a publié en open source un modèle de raisonnement haute performance, Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled. Basé sur l'architecture Qwen3.5-27B, il intègre des capacités de raisonnement avancées issues de Claude-4.6 et d'Opus. Tout en conservant les puissantes capacités originales de compréhension et d'expression du langage, il améliore considérablement la résolution de problèmes complexes et la gestion des dialogues à plusieurs tours de parole.
Au niveau des capacités fondamentales, ce modèle améliore considérablement le raisonnement grâce à l'introduction d'une technologie de distillation de la chaîne de pensée de haute qualité. Il excelle notamment dans des domaines tels que la dérivation mathématique, l'analyse logique, la planification et la prise de décision, ainsi que la décomposition de tâches en plusieurs étapes. Comparé aux modèles traditionnels, ce système ne se contente pas de générer des réponses ; il analyse également les problèmes étape par étape de manière structurée, décomposant les tâches complexes en étapes logiques claires et exécutables. Il améliore ainsi la stabilité globale du raisonnement et la fiabilité des résultats.
Exécutez en ligne :
Gemma-4-31B-il
Les modèles open source de la série Gemma 4 de Google DeepMind, basés sur le même système technologique que Gemini 3, se sont non seulement classés parmi les trois premiers du classement Arena AI, mais ont également atteint des performances proches, voire supérieures, à celles de modèles de plus grande taille avec une échelle de paramètres bien plus petite que celle de leurs concurrents.
Du point de vue de la conception, Gemma 4 ne se limite pas à un modèle unique, mais propose un système multi-tailles couvrant les configurations E2B, E4B, 26B, A4B et 31B, adaptées à différents scénarios tels que les appareils mobiles, les déploiements locaux et les environnements de calcul haute performance. La version 31B, fleuron de la gamme actuelle, offre des performances comparables à celles de Qwen 3.5 397B.
En termes de scénarios d'application, la version 31B prend en charge la saisie et l'affichage de texte et d'images, dispose d'une fenêtre de contexte pouvant contenir jusqu'à 256 000 jetons, et intègre nativement le raisonnement, les appels de fonctions et les invites système. Elle prend également en charge plus de 140 langues, ce qui lui permet d'être performante dans des applications telles que la réponse à des questions de haute qualité, l'assistance à la programmation et les services d'agent.
Exécutez en ligne :
Déploiement du processeur Qwen3.5-9B-GGUF
Qwen3.5 est une nouvelle génération de modèles de langage multimodaux de grande taille, développée par l'équipe Tongyi Qianwen d'Alibaba. Ce modèle prend en charge la saisie de texte et d'images et génère une sortie textuelle, pour des tâches telles que le dialogue, le raisonnement, la programmation et la compréhension visuelle. Parmi ces modèles, Qwen3.5-9B est la version à 9 milliards de paramètres, offrant un bon compromis entre performances et coût de déploiement. Elle est particulièrement adaptée aux déploiements locaux ou en périphérie de réseau dans des environnements aux ressources limitées.
Dans ce tutoriel, nous utiliserons des poids GGUF fournis par la communauté (version quantifiée Q4_K_M) avec un encodeur visuel (fichier GGUF mmproj). Nous lancerons un service backend compatible avec l'interface OpenAI via llama.cpp et nous connecterons à OpenWebUI pour proposer une interface interactive via navigateur.
Exécutez en ligne :
Découvrez d'autres tutoriels populaires :








