Command Palette
Search for a command to run...
MOSS-TTS : Un Modèle De Génération De Parole Découplé Et De Qualité Professionnelle Basé Sur L’architecture CAT ; Lever Les Barrières De L’analyse Unicellulaire : Construction D’un Atlas Immunitaire inter-cancer De Référence À L’aide De L’ensemble De Données scRNA-Seq pancancéreux.

Actuellement, les modèles de synthèse vocale uniques se révèlent insuffisants face aux exigences complexes du monde réel. En pratique, une voix doit non seulement imiter fidèlement un timbre spécifique, mais aussi adapter naturellement son style d'élocution selon le contenu et rester stable tout au long d'un récit de plusieurs dizaines de minutes. De plus, elle doit prendre en charge différents formats tels que le dialogue, le jeu de rôle et l'interaction en temps réel. Ces exigences dépassent largement les capacités d'un modèle unique.
Dans ce contexte,MOSI.AI et OpenMOSS ont lancé la famille de modèles de génération vocale MOSS-TTS.Au lieu de construire un modèle unique et massif, cette famille de modèles décompose le flux de travail de génération vocale en cinq modèles de qualité professionnelle, incluant la synthèse vocale haute fidélité MOSS-TTS et le modèle de dialogue multilocuteur MOSS-TTSD. Sa technologie de base repose sur le tokenizer audio à grande échelle MOSS Audio-Tokenizer (1,6 milliard de paramètres), utilisant une architecture Transformer pure (CAT, Causal Audio Tokenizer with Transformer) pour une reconstruction audio haute fidélité. Cette série de modèles résout de nombreux problèmes d'application dans des scénarios complexes, offrant une chaîne d'outils pour la génération vocale directement intégrable au flux de travail de création.
Le site web d'HyperAI propose désormais « MOSS-TTS : un modèle de génération vocale multi-scènes haute fidélité ». Essayez-le !
Utilisation en ligne :https://go.hyper.ai/AtKvk
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 2 au 6 mars :
* Jeux de données publics de haute qualité : 3
* Sélection de tutoriels de haute qualité : 8
* Interprétation d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en mars : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données pour la détection audio des sons de drones
Ce jeu de données contient des enregistrements audio de deux catégories : sons inconnus et drones. Il est conçu pour les tâches de classification audio binaire afin de détecter les sons de drones dans des environnements réels. Les fichiers audio sont fournis dans des formats standards (tels que WAV), compatibles avec des techniques de prétraitement comme l’extraction de spectrogrammes Mel, l’extraction de coefficients MFCC, la transformée de Fourier à court terme (STFT) et l’apprentissage profond appliqué aux signaux bruts.
Utilisation directe :https://go.hyper.ai/vKHJC
2. Ensemble de données de simulation des effets indésirables des médicaments
Cet ensemble de données est conçu pour reproduire les rapports de pharmacovigilance relatifs aux effets indésirables des médicaments (EIM) et vise à soutenir la recherche, les expériences d'apprentissage automatique et le développement d'algorithmes pour la surveillance de la sécurité des médicaments. Les rapports de sécurité des cas (RSC) sont générés artificiellement, inspirés des systèmes de pharmacovigilance existants tels que FDA FAERS et EMA EudraVigilance.
Utilisation directe :https://go.hyper.ai/Jex4v
3. Jeu de données de l'atlas transcriptionnel unicellulaire scRNA-Seq pancancéreux
Cet ensemble de données contient des données d'expression transcriptomique de 7 930 cellules uniques, couvrant trois états biologiques différents : un état immunitaire sain de base, une tumeur liquide (leucémie myéloïde) et un microenvironnement tumoral solide (mélanome). Il vise à établir un référentiel d'analyse unicellulaire intégré et inter-cohortes afin de fournir une base de référence pour l'évaluation des performances des algorithmes et la comparaison méthodologique, la correction des effets de lot inter-cohortes, l'analyse de l'état d'épuisement immunitaire et l'identification de biomarqueurs inter-types de tumeurs.
Utilisation directe :https://go.hyper.ai/CnZTc
Tutoriels publics sélectionnés
1. ACE-Étape 1.5 : Démo de génération musicale
ACE-Step 1.5 est un modèle de base open source pour la génération de musique, développé conjointement par ACE Studio et StepFun, visant à repousser les limites des capacités de génération musicale open source. Ce modèle utilise une architecture de génération innovante en deux étapes, permettant la production de contenu musical de haute qualité et de longue durée grâce à l'intégration collaborative d'un transformateur de diffusion (DiT) et d'un modèle de langage (LM).
Exécutez en ligne :https://go.hyper.ai/QZ6oi

2.Qwen3-ASR-1.7B : un système de reconnaissance vocale de nouvelle génération
Qwen3-ASR est une nouvelle génération de modèles de reconnaissance vocale automatique (ASR) open source de bout en bout, développée par l'équipe Tongyi Qianwen d'Alibaba Cloud. Basé sur le modèle multimodal Qwen3-Omni et un encodeur vocal AuT développé en interne, ce modèle vise à obtenir une transcription vocale en texte de haute précision, multilingue et adaptée aux enregistrements audio longs, qu'ils soient en flux continu ou non. Prenant en entrée des signaux audio bruts, le modèle les convertit directement en texte structuré grâce à une architecture de bout en bout, tout en prenant en charge l'alignement temporel au niveau des caractères et des mots, avec une précision de la milliseconde. Il convient à de nombreux scénarios tels que la transcription de réunions, le sous-titrage intelligent, l'archivage vocal du service client et l'interaction vocale prenant en compte les dialectes.
Exécutez en ligne :https://go.hyper.ai/zb0Vi

3.Déploiement de vLLM+Open WebUI avec Qwen3-Coder-Next
Qwen3-Coder-Next est un modèle de génération de code léger et open source développé par Tongyi Qianwen d'Alibaba Cloud. Il est conçu pour l'assistance à la programmation et la génération de code dans tous les contextes. Ses principaux atouts sont ses hautes performances, sa facilité d'utilisation et son déploiement aisé. Basé sur l'architecture optimisée du modèle de langage Qwen3, il intègre des données pré-entraînées spécifiques au domaine (couvrant plus de 80 langages de programmation courants et plus d'un milliard d'extraits de code) et l'optimisation de l'alignement du code par apprentissage par renforcement avec retour d'information humain (RLHF). Il a atteint des performances de premier ordre parmi les modèles open source sur les trois benchmarks de code de référence : HumanEval+, MBPP et MultiPL-E, avec des performances proches de celles de CodeLlama-70B. Il convient à divers scénarios de programmation, notamment l'écriture d'algorithmes, la génération de code métier, le commentaire de code, la conversion de code interlangages et la correction de bogues.
Exécutez en ligne :https://go.hyper.ai/ukxPt
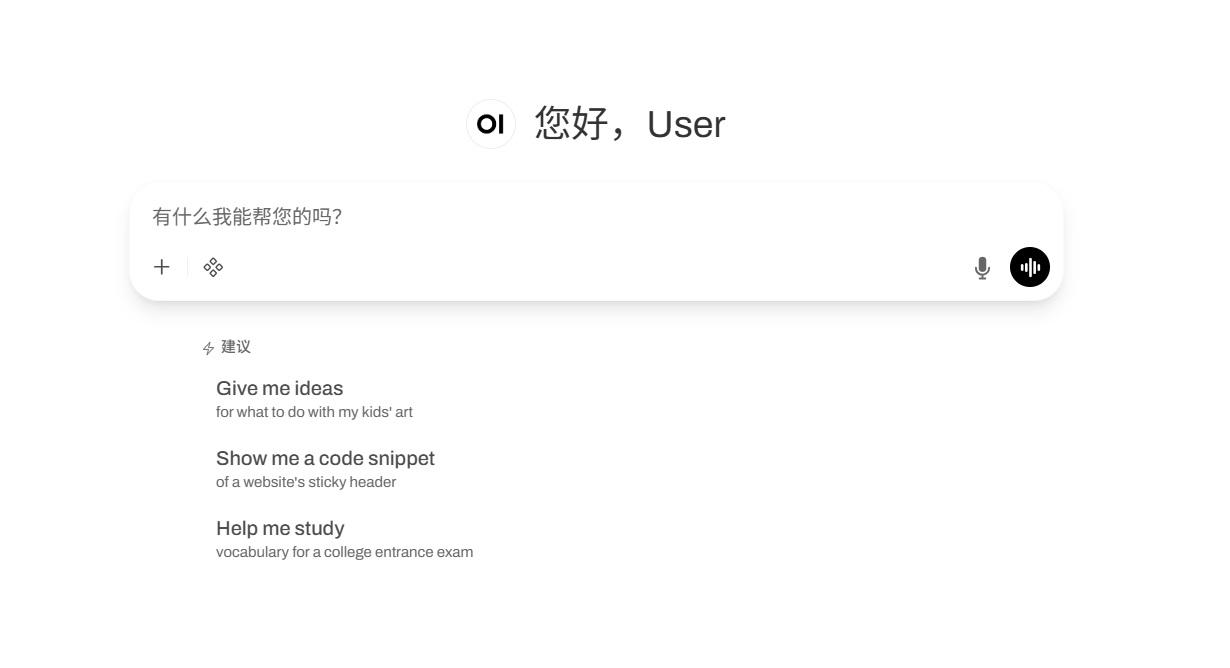
4. VibeVoice-ASR : Démonstration de reconnaissance vocale multifonctionnelle de bout en bout
VibeVoice-ASR est un modèle de reconnaissance vocale (ASR) de bout en bout, multifonctionnel et performant, développé en open source par Microsoft. Conçu pour fournir des services de transcription vocale structurés et contextuels pour les contenus audio longs, ce modèle utilise une architecture de modélisation audio unifiée et avancée, capable de traiter des fichiers audio jusqu'à 60 minutes. Il génère des sorties structurées contenant l'identité du locuteur (Qui), les horodatages (Quand) et le contenu transcrit (Quoi), et permet aux utilisateurs de fournir des informations contextuelles pour améliorer la précision de la reconnaissance. Ses principales innovations technologiques résident dans ses capacités de modélisation efficaces des longues séquences et son mécanisme d'apprentissage multitâche multilingue, résolvant ainsi les problèmes d'alignement temporel et de cohérence sémantique des modèles ASR traditionnels lors du traitement de fichiers audio longs.
Exécutez en ligne :https://go.hyper.ai/8eMFX
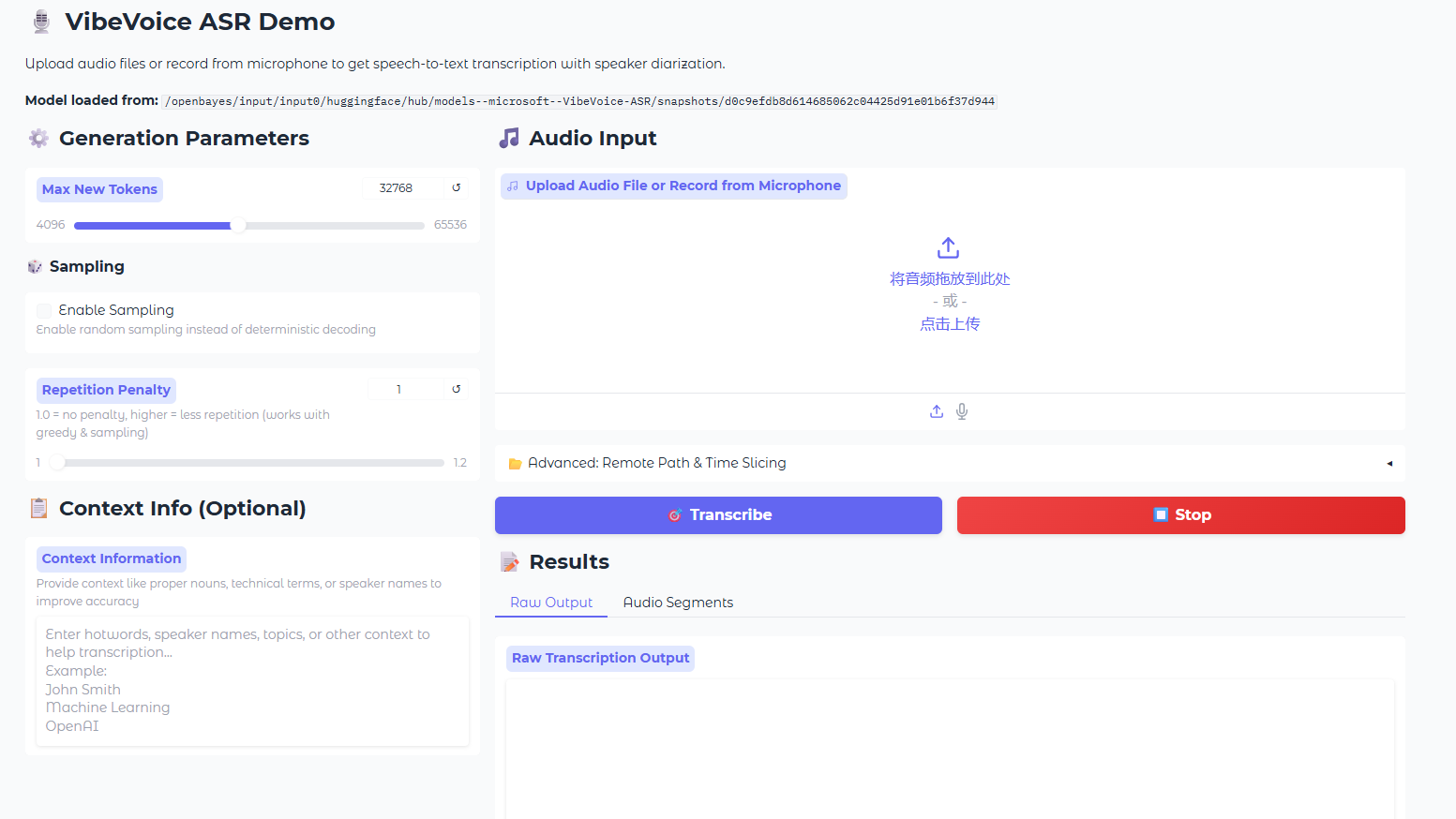
5. MOSS-TTS : Un modèle de génération vocale multi-scènes haute fidélité
La série MOSS-TTS est une suite de modèles de synthèse vocale open source développée par MOSI.AI et l'équipe OpenMOSS. Lorsqu'un segment audio doit sonner naturel, avec une prononciation précise de chaque mot, une capacité à adapter son style d'élocution à différents contenus, une stabilité pendant plusieurs dizaines de minutes et la prise en charge du dialogue, du jeu de rôle et de l'interaction en temps réel, un modèle TTS unique s'avère souvent insuffisant. C'est pourquoi ce projet décompose le flux de travail de génération vocale en cinq modèles de qualité professionnelle, utilisables indépendamment ou combinés : le modèle de base MOSS-TTS, le modèle de dialogue multilingue MOSS-TTSD, le modèle de conception vocale MOSS-VoiceGenerator, le modèle de génération d'effets sonores MOSS-SoundEffect et le modèle d'interaction en temps réel MOSS-TTS-Realtime. Cette série prend en charge 20 langues et s'adresse principalement aux défis des applications concrètes tels que le clonage vocal haute fidélité sans échantillon, la synthèse stable de longs textes jusqu'à une heure, la génération multilingue et mixte chinois-anglais, et le contrôle précis de la durée et de la prononciation au niveau des phonèmes dans des scénarios complexes.
Exécutez en ligne :https://go.hyper.ai/AtKvk
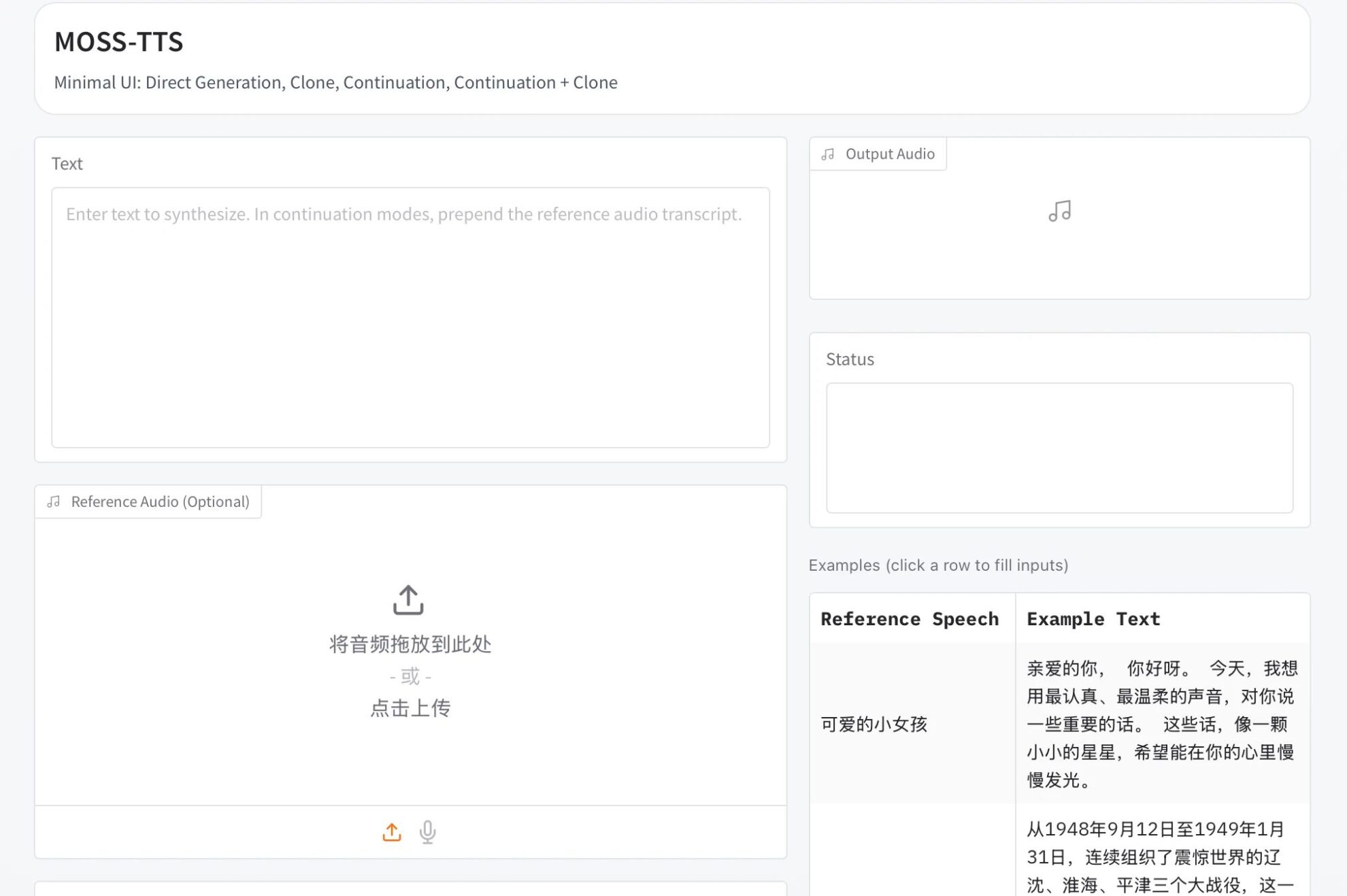
6.Z-Image : modèle d'image textuel open source d'Alibaba avec 6 milliards de paramètres
Z-Image est un modèle de génération d'images haute performance de nouvelle génération, lancé par l'équipe Tongyi Qianwen d'Alibaba Cloud. Après le succès de la version optimisée Z-Image-Turbo, qui s'est hissée au sommet du classement des modèles open source d'analyse artificielle, l'équipe Z-Image a officiellement publié en open source la version Standard. Modèle de base principal de la série Z-Image, la version Standard est un modèle complet et non optimisé, qui excelle en termes de qualité de génération, de diversité de styles et de prise en charge des développements secondaires. Elle vise à fournir aux développeurs de la communauté une plateforme de génération d'images puissante et flexible, ouvrant ainsi la voie à de nombreuses possibilités de personnalisation et d'optimisation.
Exécutez en ligne :https://go.hyper.ai/SsDMv
7. Qwen3-TTS : Démonstration de synthèse vocale multilingue de haute qualité et contrôlable
Qwen3-TTS-12Hz-1.7B-CustomVoice est un modèle de synthèse vocale (TTS) de nouvelle génération et de haute qualité, développé par l'équipe Alibaba Tongyi. Ce modèle vise à réaliser une synthèse vocale multilingue, la gestion de plusieurs locuteurs (CustomVoice), l'ajustement du style et des émotions en fonction du texte, ainsi qu'une génération de parole naturelle et à faible latence, le tout dans un cadre unifié. Basé sur un modèle acoustique à 12 Hz avec 1,7 milliard de paramètres, il offre d'excellentes performances en termes d'intelligibilité, de cohérence prosodique et de stabilité interlingue. Grâce au mécanisme CustomVoice, le modèle peut basculer directement entre les locuteurs prédéfinis lors de l'inférence, sans apprentissage supplémentaire. Combiné à des instructions stylistiques en langage naturel, il permet un contrôle plus précis des expressions.
Exécutez en ligne :https://go.hyper.ai/xWsQ6
8. Système de questions-réponses vidéo FoundationMotion
FoundationMotion est un système de compréhension vidéo et de questionnement développé conjointement par NVIDIA et le MIT, basé sur l'optimisation de Qwen2.5-VL. Il vise à comprendre et à interpréter les mouvements spatiaux dans les vidéos. Grâce à l'intégration d'une technologie de pré-entraînement du langage visuel, le modèle peut analyser intelligemment le contenu vidéo téléchargé et répondre aux questions s'y rapportant.
Exécutez en ligne :https://go.hyper.ai/JlGZk
Interprétation des articles communautaires
1. Dépasser les limites de l'intégration multimodale traditionnelle ! Le MIT propose le cadre APOLLO, qui permet une séparation claire entre les informations partagées par les cellules et les informations spécifiques à chaque cellule.
Face à l'évolution constante des technologies unicellulaires et à l'explosion du volume de données, l'intégration efficace et automatique de données multimodales, tout en dissociant clairement les informations partagées des informations spécifiques à chaque modalité, est devenue un enjeu majeur de la biologie unicellulaire. Pour relever ce défi, une équipe de recherche conjointe du MIT et de l'ETH Zurich a proposé APOLLO (Autoencoder with a Partially Overlapping Latent Space Learned through Latent Optimization), un cadre de calcul d'apprentissage profond général. Ce cadre offre une voie technique viable pour une analyse plus complète et précise des états cellulaires et de leur logique de régulation, grâce à la modélisation explicite des informations partagées et spécifiques à chaque modalité.
Voir le rapport complet :https://go.hyper.ai/jaCKf
2. Tutoriel en ligne | Basé sur 5 millions d'heures de données vocales, Qwen3-TTS réalise un clonage vocal et un réglage précis en 3 secondes.
Lorsque l'IA générative ne se contente plus de « générer du texte » mais commence à véritablement « produire du son », la parole évolue d'un simple canal d'information à un moyen d'expression programmable et malléable. Dans cette perspective d'évolution technologique, la nouvelle génération de modèles s'efforce de dépasser les limites de la synthèse vocale traditionnelle, en visant non seulement une fidélité accrue, mais aussi en privilégiant la généralisation multilingue et un contrôle précis. Qwen3-TTS, récemment mis à disposition en open source par l'équipe Qwen, repose sur une architecture de modèle de langage à double voie, permettant un contrôle précis de la parole produite tout en la synthétisant simultanément en temps réel.
Voir le rapport complet :https://go.hyper.ai/eKr7T
3. Le MIT développe le modèle Pichia-CLM pour apprendre le « langage » de l'ADN de la levure, ce qui pourrait augmenter la production de protéines exogènes jusqu'à 3 fois.
Actuellement, divers outils et méthodes d'optimisation des codons basés sur les CUB de l'hôte ont été développés dans l'industrie, mais ces méthodes ne permettent pas toujours d'obtenir des constructions hautement exprimées. Ces dernières années, grâce au développement de l'intelligence artificielle, et notamment des technologies de modélisation des séquences, les chercheurs ont commencé à considérer les séquences génétiques comme une sorte de « langage », cherchant à en apprendre les règles implicites par des méthodes similaires au traitement automatique du langage naturel. Dans ce contexte, une équipe de recherche du MIT a proposé Pichia-CLM, un modèle de langage basé sur l'apprentissage profond, pour l'optimisation des codons chez la plante hôte industrielle Pichia pastoris, afin d'améliorer le rendement des protéines recombinantes.
Voir le rapport complet :https://go.hyper.ai/a4H2G
Articles populaires de l'encyclopédie
1. Modèle de langage visuel (VLM)
2. Hyperréseaux
3. Attention contrôlée
4. Intervention humaine dans la boucle (HITL)
5. Champ de rayonnement neuronal (NeRF)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
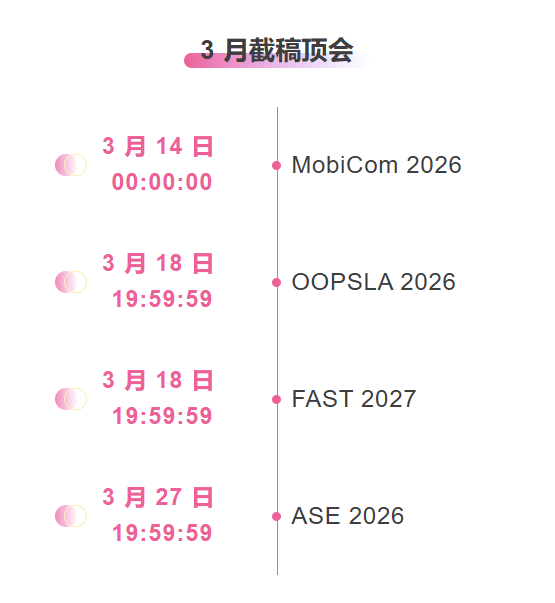
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








