Command Palette
Search for a command to run...
Lorsque l'informatique Multimodale Commence À Prendre Son Essor : MiniCPM-o-4.5, Avec Seulement 9 Octets, Couvre La Compréhension d'images En Temps Réel Et La Génération De Texte ; vLLM Omni Prend Simultanément En Charge Le Déploiement À Haut Débit Et l'architecture Orientée Services Pour Les Modèles Textuels Et multimodaux.

À ce moment critique où les grands modèles multimodaux passent de l'état « utilisable » à celui de « facile à utiliser », la taille des paramètres, le coût de l'inférence et les obstacles au déploiement deviennent aussi importants que les capacités du modèle. La dernière version d'OpenBMB, MiniCPM-o-4.5,La capacité entièrement modale d'Omni est construite à l'aide de seulement 9 milliards de paramètres, trouvant une meilleure solution entre légèreté et hautes performances.
MiniCPM-o-4.5 utilise une architecture unifiée pour modéliser et générer conjointement des sorties à partir d'entrées multimodales telles que du texte et des images, en optimisant de manière synergique l'alignement intermodal et l'efficacité de l'inférence. La taille de son modèle (9 octets) permet un déploiement sur les GPU grand public, ce qui le rend plus accessible aux développeurs en termes d'utilisation de la mémoire et de latence de réponse que les modèles propriétaires de grande envergure.
à l'heure actuelle,Le site officiel d'HyperAI est désormais en ligne."MiniCPM-o-4_5 : Modèle modal complet duplex open source de Wallfacer Intelligence"Venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/iOGzO
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 24 au 27 février :
* Jeux de données publics de haute qualité : 3
* Tutoriels de haute qualité : 14
* Entrées d'encyclopédie populaire : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Jeu de données EEG THINGS-EEG
THINGS-EEG est un ensemble de données d'électroencéphalographie (EEG) destiné à la recherche sur la cognition des objets. Publié par l'Institut national de la santé mentale (NIMH) des Instituts nationaux de la santé (NIH), l'Institut Max Planck de recherche sur la cognition humaine et les neurosciences (MHC) en Allemagne et la faculté de médecine de l'université de Giessen, entre autres institutions, il enregistre l'activité EEG de 50 sujets pendant qu'ils observent des images d'objets. Ces données permettent d'analyser la dynamique temporelle et les représentations cognitives du traitement des objets.
Utilisation directe :https://go.hyper.ai/kqejl
2. Ensemble de données de magnétoencéphalographie THINGS-MEG
THINGS-MEG est un ensemble de données de magnétoencéphalographie (MEG) destiné à la recherche sur la cognition des objets. Il a été mis à disposition par l'Institut national de la santé mentale des Instituts nationaux de la santé (NIH) aux États-Unis, l'Institut Max Planck pour la cognition humaine et les neurosciences en Allemagne, et la faculté de médecine de l'université de Giessen, entre autres institutions. Cet ensemble enregistre l'activité électromagnétique cérébrale à l'échelle de la milliseconde lorsque les sujets observent des images d'objets et sert à analyser la dynamique temporelle du traitement des objets.
Utilisation directe :https://go.hyper.ai/eBKWI
3. Ensemble de données d'imagerie par résonance magnétique fonctionnelle THINGS-fMRI
THINGS-fMRI est un ensemble de données d'imagerie par résonance magnétique fonctionnelle à haute densité destiné à la recherche sur la cognition des objets. Il a été publié conjointement par l'Institut national de la santé mentale des Instituts nationaux de la santé (États-Unis), l'Institut Max Planck pour la cognition humaine et les neurosciences (Allemagne) et la faculté de médecine de l'université de Giessen, entre autres institutions. Son objectif est de caractériser de manière systématique la représentation visuelle et sémantique des objets du monde réel par le cerveau humain.
Utilisation directe :https://go.hyper.ai/CRbiA
Tutoriels publics sélectionnés
Cette semaine, nous avons compilé 3 types de tutoriels publics de haute qualité :
* Tutoriels OCR : 4
* Tutoriels multimodaux : 6
Tutoriel sur les grands modèles de langage : 4 parties
Tutoriel OCR
1. Système de reconnaissance optique de caractères (OCR) multimodal léger GLM-OCR
GLM-OCR est un modèle OCR multimodal léger (0,9 octet) open source développé par Zhipu AI depuis février 2026. Il se concentre sur la reconnaissance de texte haute précision et l'analyse syntaxique structurée de documents complexes. Ses principaux atouts sont sa petite taille, sa haute précision et sa facilité de déploiement. Basé sur une architecture multimodale encodeur-décodeur GLM-V, il intègre l'encodeur visuel CogViT, développé en interne, et l'optimisation RLHF. Il a obtenu le meilleur score (94,62) au benchmark OmniDocBench V1.5, surpassant ainsi les performances de référence du Gemini-3-Pro. Il convient à divers usages tels que l'analyse de documents bureautiques, la reconnaissance de formules scientifiques et éducatives, la vérification de documents administratifs et financiers, et l'extraction d'extraits de code.
Exécutez en ligne :https://go.hyper.ai/kgb3n
2. PaddleOCR-VL-1.5 : OCR local basé sur vLLM
PaddleOCR-VL-1.5 est un modèle OCR multimodal de la série PaddleOCR, développé par l'équipe PaddlePaddle. Il offre des capacités de reconnaissance de texte et de compréhension de la mise en page améliorées pour les documents complexes (factures, contrats, documents papier, documents numérisés, etc.). Ce tutoriel utilise l'interface vLLM, compatible avec OpenAI, pour se connecter à ce modèle et réaliser l'ensemble du processus, du chargement des images à l'obtention des résultats de reconnaissance. Avec ses 900 millions de paramètres, il atteint une précision de nouvelle génération de 94,51 TP3T sur OmniDocBench v1.5.
Exécutez en ligne :https://go.hyper.ai/cea6x
3.LightOnOCR-2-1B Modèle OCR de bout en bout léger et haute performance
LightOnOCR-2-1B est le modèle de langage visuel de bout en bout de dernière génération de LightOn AI. Version phare de la série LightOnOCR, il unifie la compréhension de documents et la génération de texte dans une architecture compacte, dispose d'un milliard de paramètres et peut s'exécuter sur des GPU grand public. Ce modèle utilise une architecture Vision-Language Transformer et intègre la technologie d'apprentissage RLVR, ce qui lui permet d'atteindre une précision de reconnaissance et une vitesse d'inférence extrêmement élevées. Il est spécialement conçu pour les applications nécessitant le traitement de documents complexes, de textes manuscrits et de formules LaTeX.
Exécutez en ligne :https://go.hyper.ai/cLSj5
4. Flux causal visuel DeepSeek-OCR 2
DeepSeek-OCR 2 est le modèle OCR de deuxième génération développé par l'équipe DeepSeek. Grâce à l'architecture DeepEncoder V2, il opère un changement de paradigme, passant d'une lecture fixe à un raisonnement sémantique. Le modèle utilise l'interrogation de flux causaux et un mécanisme d'attention à double flux, réorganisant dynamiquement les jetons visuels afin de recréer plus fidèlement la logique de lecture naturelle des documents complexes. Sur le benchmark OmniDocBench v1.5, le modèle a obtenu un score global de 91,091 TP3T, une amélioration significative par rapport à son prédécesseur, tout en réduisant considérablement le taux de répétition des résultats de reconnaissance OCR. Il ouvre ainsi la voie à la conception future d'un encodeur multimodal.
Exécutez en ligne :https://go.hyper.ai/iOGzO
Tutoriel multimodal
1. MiniCPM-o-4.5 : Modèle full-duplex et full-modal open source de Wallfacer Intelligence
MiniCPM-o-4.5 est un modèle phare multimodal à 9 milliards de paramètres, open source et développé par Facewall Intelligence et le Laboratoire de traitement automatique du langage naturel de l'Université Tsinghua en février 2026. Il utilise une architecture de bout en bout avec siglip2, whisper, cosyvoice2 et qwen3-8b. Premier modèle du marché à prendre en charge le « dialogue libre en temps réel », il permet une interaction bidirectionnelle simultanée : les utilisateurs peuvent voir, entendre et parler en même temps, rompant ainsi avec le mode traditionnel de type « talkie-walkie » à tour de rôle. Ce modèle offre des capacités de compréhension visuelle de pointe, une génération vocale hyper-humanoïde et des capacités de clonage vocal. Il prend en charge l'interaction proactive et le traitement multimédia en flux continu en temps réel, et peut être exécuté sur des périphériques de périphérie. Compatible avec diverses puces chinoises, telles que ascend et Hygon, il peut être déployé efficacement grâce à des frameworks comme llama.cpp et vLLM.
Exécutez en ligne :https://go.hyper.ai/iOGzO
2.Déploiement de Qwen-Image-Edit à l'aide de vLLM-Omni
Qwen-Image-Edit est un modèle d'édition d'images polyvalent proposé par Alibaba. Ce modèle offre une double fonctionnalité d'édition sémantique et visuelle, permettant à la fois une édition visuelle de bas niveau (ajout, suppression ou modification d'éléments) et une édition sémantique visuelle de haut niveau (création d'images, rotation d'objets et application de styles). Il prend en charge l'édition précise de textes bilingues chinois et anglais, en modifiant le texte au sein des images tout en préservant la police, la taille et le style d'origine.
Exécutez en ligne :https://go.hyper.ai/4w6XA
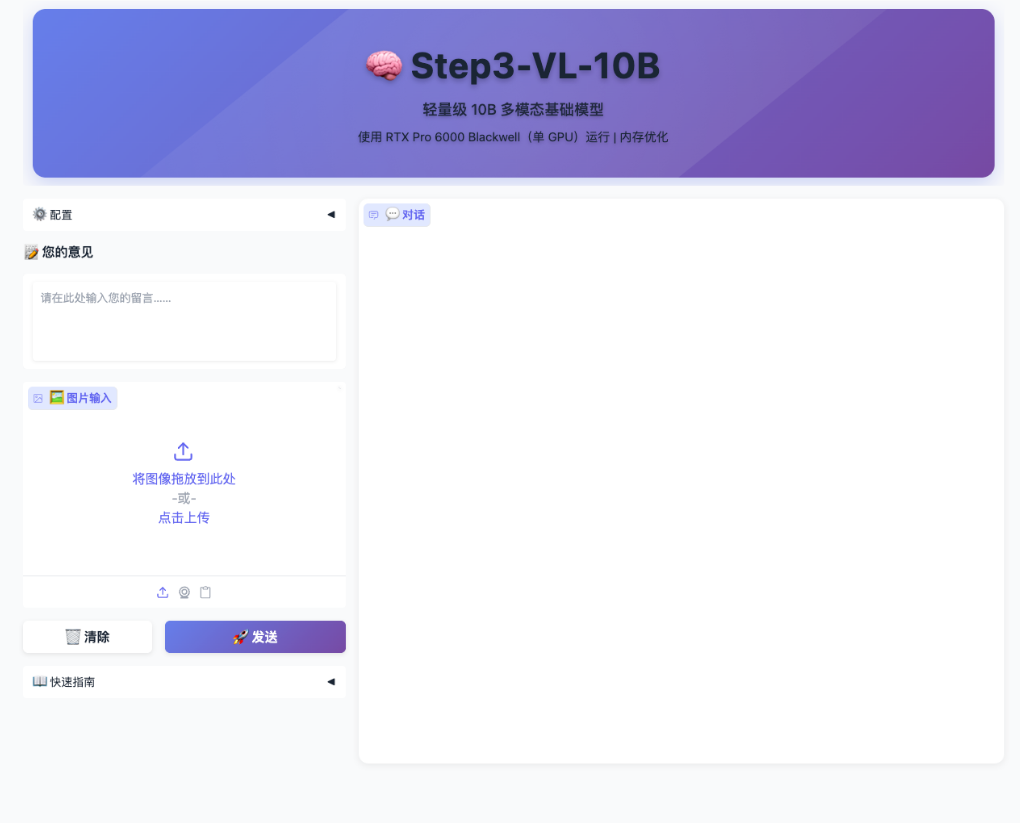
3. Étape 3-VL-10B : Compréhension visuelle multimodale et dialogue graphique
Step3-VL-10B est un modèle open source de langage visuel développé par l'équipe StepFun, conçu spécifiquement pour la compréhension multimodale et les tâches de raisonnement complexes. Ce modèle vise à redéfinir l'équilibre entre efficacité, capacité de raisonnement et qualité de la compréhension visuelle, et convient aux modèles multimodaux avec un nombre de paramètres limité. Malgré ce nombre réduit de paramètres, il affiche des performances supérieures en perception visuelle, en raisonnement complexe et en alignement avec les instructions humaines. Il surpasse systématiquement les modèles de taille similaire dans de nombreux tests de performance et rivalise avec des modèles comportant 10 à 20 fois plus de paramètres sur certaines tâches.
Exécutez en ligne :https://go.hyper.ai/RqTTW
4. Déployer Qwen-Image-2512 à l'aide de vLLM-Omni
Qwen-Image-2512 est un modèle de base de conversion texte-image au sein de la série Qwen-Image. Conçu principalement pour la génération d'images de haute qualité et l'expression de contenus multimodaux complexes, il vise à améliorer le réalisme et l'ergonomie des images générées. La génération de portraits gagne considérablement en naturel : la structure du visage, le grain de peau et l'éclairage se rapprochent davantage de photographies réalistes. Dans les scènes naturelles, le modèle génère des textures de terrain plus détaillées, des détails de végétation et des informations haute fréquence comme le pelage des animaux. Ses capacités de génération de texte et de typographie ont également été améliorées, permettant un affichage plus stable des textes lisibles et des styles de police complexes.
Exécutez en ligne :https://go.hyper.ai/JMmhs
5. TurboDiffusion : Système de génération vidéo piloté par l’image et le texte
TurboDiffusion est un système de génération de diffusion vidéo à haute efficacité développé par une équipe de l'Université Tsinghua en décembre 2025. Basé sur l'architecture Wan2.1 pour la distillation d'ordre supérieur, le système vise à résoudre les problèmes de lenteur d'inférence et de forte consommation de ressources de calcul dans les modèles vidéo à grande échelle, atteignant ainsi l'objectif de générer des vidéos de haute qualité en un minimum d'étapes.
Exécutez en ligne :https://go.hyper.ai/VvyVZ
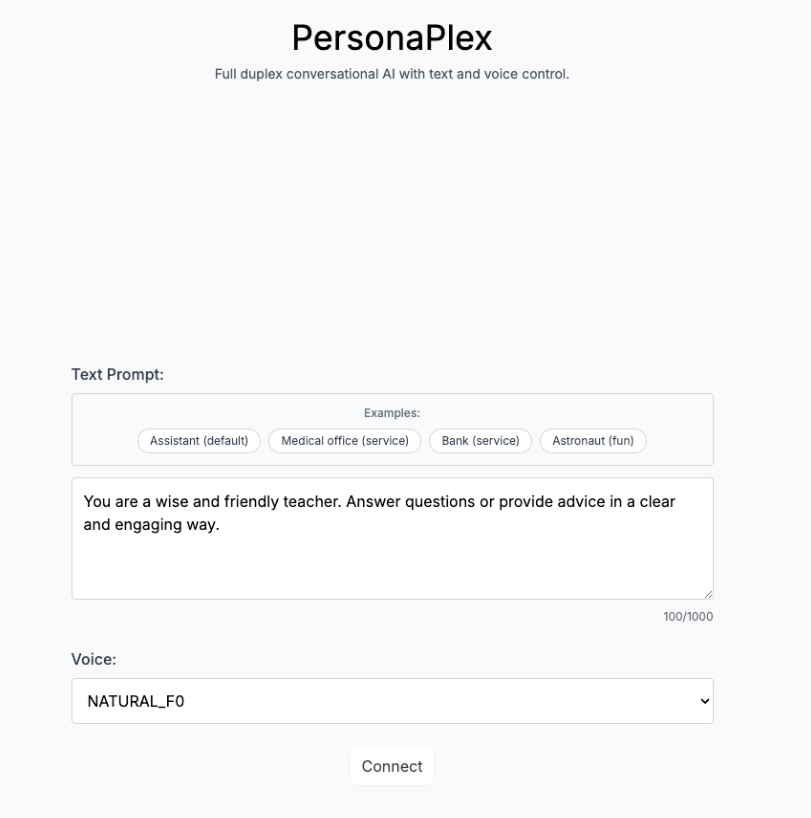
6. Personaplex-7B-v1 : Interface vocale de dialogue en temps réel et personnalisée pour chaque personnage
PersonaPlex-7B-v1 est un modèle de dialogue personnalisé multimodal à 7 milliards de paramètres, développé par NVIDIA. Conçu pour l'interaction voix/texte en temps réel, la simulation de la cohérence des personnages sur le long terme et les tâches de perception multimodale, il vise à fournir un système de démonstration immersif de jeu de rôle et d'interaction multimodale avec une vitesse de réponse de l'ordre de la milliseconde.
Exécutez en ligne :https://go.hyper.ai/ndoj0
Tutoriel sur les grands modèles de langage
1.llama.cpp+Ouvrir l'interface Web : déploiement Qwen3-VL-8B-Instruct-GGUF
Qwen3-VL-8B-Instruct-GGUF propose plusieurs variantes de modèles de langage précis et un encodeur visuel MMPROJ dédié. Ces modèles sont compatibles avec des outils tels que llama.cpp et Ollama, et conviennent à une large gamme de matériels, notamment les processeurs, les GPU NVIDIA, les puces Apple et les GPU Intel. Qwen3-VL-8B-Instruct-GGUF distingue clairement les composants de langage et visuels au format GGUF. Les développeurs peuvent ainsi choisir le niveau de quantification adapté à leur matériel, obtenant des temps de réponse acceptables même sur des processeurs aux ressources limitées, et optimisant les performances sur les systèmes équipés de GPU.
Exécutez en ligne :https://go.hyper.ai/EKryC
2. Forçage de Jacobi : une technique de décodage parallèle causale rapide et précise
Le Jacobi Forcing est une technique d'entraînement novatrice introduite par Hao AI Labs qui transforme les grands modèles de langage (LLM) en décodeurs parallèles causaux natifs. En entraînant le modèle à traiter des blocs futurs bruités le long de sa propre trajectoire de décodage Jacobi, cette technique résout le problème de correspondance entre les modèles autorégressifs et les modèles de diffusion tout en préservant l'intégrité de la structure causale autorégressive sous-jacente.
Exécutez en ligne :https://go.hyper.ai/fIad4
3.vLLM+Open WebUI Déploiement de GLM-4.7-Flash
GLM-4.7-Flash est un modèle d'inférence multimodal léger qui allie hautes performances et haut débit, prenant en charge nativement la pensée enchaînée (CoT), les appels d'outils et les fonctionnalités d'agents. GLM-4.7-Flash utilise une architecture d'expert hybride (MoE), tirant parti de mécanismes d'activation parcimonieux pour réduire considérablement le coût de calcul de chaque inférence tout en conservant la puissance d'expression des grands modèles.
Exécutez en ligne :https://go.hyper.ai/a2IN3
4. vLLM+Déploiement de l'interface utilisateur Web ouverte de LFM2.5-1.2B-Thinking
LFM2.5-1.2B-Thinking est un modèle d'architecture hybride optimisé pour le traitement en périphérie. Version de la série LFM2.5 spécifiquement optimisée pour l'inférence logique, il combine le traitement de longues séquences et des capacités d'inférence efficaces au sein d'une architecture compacte. Ce modèle prend en charge 1,2 milliard de paramètres et fonctionne de manière fluide sur les GPU grand public et même sur les périphériques de traitement en périphérie. Grâce à une architecture hybride innovante (système dynamique linéaire + attention), il atteint une efficacité mémoire et un débit extrêmement élevés, conçus spécifiquement pour les scénarios exigeant une inférence en temps réel sur le périphérique sans compromis sur l'intelligence.
Exécutez en ligne :https://go.hyper.ai/1XTsV
Interprétation des articles communautaires
1. Une équipe de recherche européenne a proposé SeaCast, un modèle régional de prévision océanique à haute résolution capable de fournir des prévisions à 15 jours en seulement 20 secondes.
La répartition irrégulière des zones terre-mer, la complexité des conditions aux limites latérales et la nécessité d'une caractérisation détaillée des variables verticalement stratifiées rendent difficile l'adaptation directe des modèles d'IA océaniques globaux existants aux tâches régionales. Pour pallier ce problème, une équipe de recherche conjointe de l'Université d'Helsinki (Finlande), du Centre de recherche sur le changement climatique méditerranéen et de l'Université de Salento (Italie) a développé SeaCast, un modèle de réseau neuronal graphique spécifiquement conçu pour la prévision océanique régionale. Ce modèle peut réaliser une prévision à 15 jours sur 18 niveaux verticaux au sein d'une grille de 1/24° en seulement 20 secondes sur un seul GPU.
Voir le rapport complet :https://go.hyper.ai/kRXnE
2. L'université Cornell propose un cadre d'IA innovant pour décoder le mécanisme chimique des électrolytes lithium-ion hautement conducteurs, atteignant un taux de réussite de prédiction supérieur à 80 % pour %.
La chimie des sels et des solvants sous-tend le comportement des électrolytes dans la plupart des systèmes de batteries lithium-ion, mais sa conception rationnelle est contrainte par un vaste espace chimique englobant d'innombrables combinaisons et des relations de couplage structure-performance non linéaires. Ce problème est encore aggravé par la rareté et l'hétérogénéité des données expérimentales, ce qui limite la capacité de généralisation des modèles. Une équipe de recherche de l'Université Cornell a développé SCAN, un cadre robuste, interprétable et économe en données, pour la modélisation et l'interprétation de la chimie des sels et des solvants. Ce cadre traite efficacement les données à longue traîne et couvre l'ensemble des formulations de sels et de solvants.
Voir le rapport complet :https://go.hyper.ai/OrHIt
3. Une nouvelle méthode de prédiction de la durée de vie de la batterie, proposée par l'Université du Michigan et d'autres, réduit le cycle de vérification de 40 fois ; « l'apprentissage par découverte » permet de gagner du temps d'évaluation pour le 98%.
La prédiction précise et efficace de la durée de vie des batteries est cruciale pour la recherche et le déploiement à grande échelle des batteries de nouvelle génération, car elle détermine directement leur fiabilité, leur sécurité et le coût total de leur cycle de vie. Récemment, des experts d'instituts de recherche tels que l'Université du Michigan ont proposé une méthode d'apprentissage automatique innovante, appelée « Apprentissage par découverte (DL) », qui intègre de manière organique l'apprentissage actif, l'apprentissage avec contraintes physiques et l'apprentissage zéro-shot afin de construire un cadre d'apprentissage en boucle fermée, similaire au raisonnement humain. Dans des conditions prudentes, comparé aux processus industriels de vérification de la durée de vie des batteries, l'apprentissage par découverte permet de réaliser un gain de temps d'évaluation de 981 TP3T et une économie d'énergie de 951 TP3T, réduisant ainsi le cycle de vérification d'environ 1 333 jours à 33 jours.
Voir le rapport complet :https://go.hyper.ai/28W2g
4. Résumé de l'article | Plus de 100 réalisations clés de l'IA pour la science : un aperçu rapide des innovations technologiques d'ici 2025
Au cours de l'année écoulée, la relation entre l'IA et la recherche scientifique a connu une transformation profonde et discrète. D'ici 2025, l'IA au service de la science ne se limitera plus à des applications technologiques éparses, mais deviendra une voie claire, systématique et réutilisable pour la recherche et l'innovation scientifiques. L'IA ne sera plus un simple outil, mais s'intégrera pleinement au paradigme de la recherche. HyperAI a rassemblé des articles issus de multiples domaines, tels que la médecine, la chimie des matériaux, la météorologie et l'astronomie, afin de faciliter la recherche et la consultation pour un public aux profils variés.
Voir le rapport complet :https://go.hyper.ai/FLJGD
Articles populaires de l'encyclopédie
1. Tri inverse combiné au RRF
2. Théorème de représentation de Kolmogorov-Arnold
3. Compréhension du langage multitâche à grande échelle (MMLU)
4. Optimiseurs de boîte noire
5. Probabilité conditionnelle de classe
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








