Command Palette
Search for a command to run...
Tutoriel En Ligne | Microsoft Ouvre VibeVoice, Permettant 90 Minutes De Dialogue Naturel Entre 4 Rôles
Ces dernières années, la technologie de synthèse vocale (TTS) a réalisé des progrès considérables, permettant la synthèse de courts énoncés de haute fidélité et au son naturel pour un seul locuteur. Cependant, la synthèse à grande échelle de dialogues audio longs et multi-locuteurs reste un défi majeur, limitant son application à des cas tels que les podcasts et les livres audio à rôles multiples.
Les méthodes traditionnelles, même lorsqu'elles génèrent un tel son par concaténation d'énoncés synthétisés indépendamment, restent insuffisantes pour parvenir à une alternance naturelle des tours de parole et à une génération prenant en compte le contenu. Face aux exigences croissantes des applications industrielles, la recherche sur la génération de la parole pour les conversations longues à plusieurs locuteurs s'est développée dans divers secteurs.Cependant, la plupart des résultats n'ont pas encore été publiés en open source, ou bien des problèmes subsistent concernant la longueur et la stabilité des données générées.
Dans ce contexte,Microsoft a rendu VibeVoice open source, dans le but de permettre une synthèse vocale multilocutrice de longue durée et évolutive. VibeVoice utilise une approche de diffusion next-token pour synthétiser de longs discours multilocuteurs, une méthode unifiée qui utilise l'autorégression de diffusion pour générer des vecteurs latents afin de modéliser des données continues.
À cette fin, l'équipe de recherche a mis au point un nouveau segmentateur de parole continue qui, comparé au modèle d'encodeur actuellement répandu, améliore la compression des données d'un facteur 80 tout en conservant des performances comparables, pour un taux de compression allant jusqu'à 3 200× (correspondant à une fréquence d'images de 7,5 Hz). Ceci améliore considérablement l'efficacité de calcul du traitement de longues séquences tout en préservant la fidélité audio.
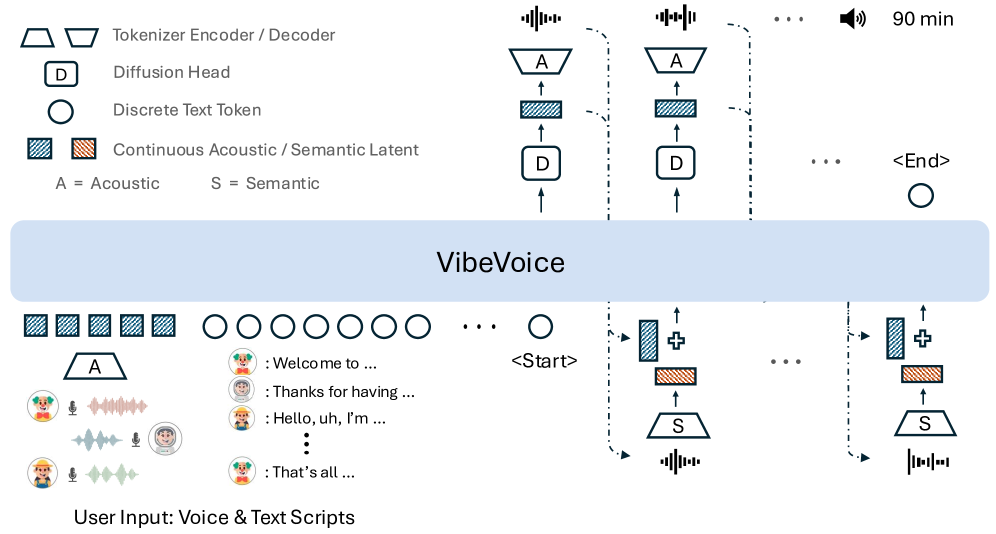
Malgré son architecture simple, VibeVoice fait preuve de capacités exceptionnelles.Il peut synthétiser jusqu'à 90 minutes de parole avec jusqu'à quatre locuteurs dans une fenêtre contextuelle de 64 kHz, produisant un timbre plus riche, une intonation plus naturelle et capturant l'atmosphère d'une véritable conversation.Il démontre une meilleure transférabilité dans les applications multilingues, et ses performances globales surpassent les modèles de dialogue open source et propriétaires existants.
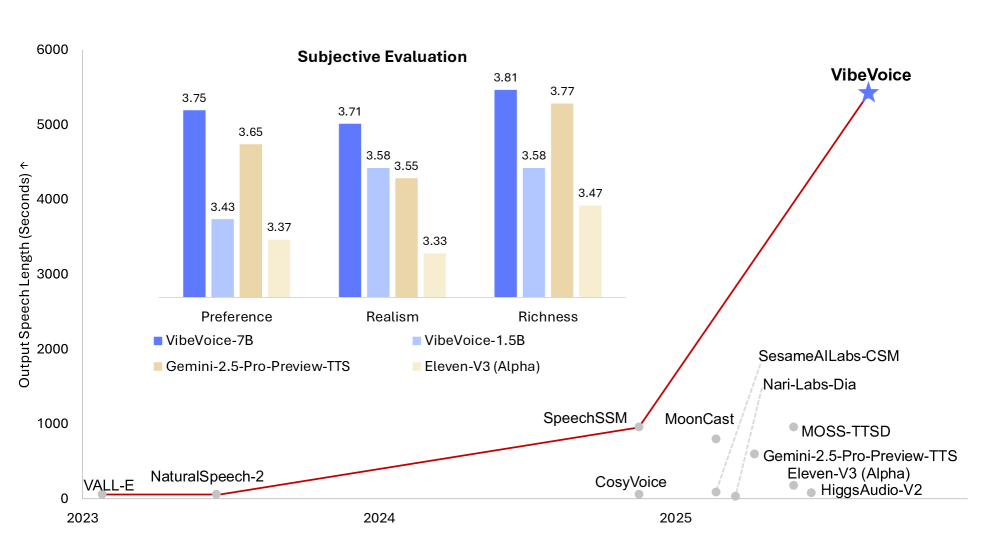
À l'approche de la fin de l'année, cet article utilise VibeVoice pour générer un extrait audio de 1 minute 20 de vœux de Nouvel An. La qualité sonore est nettement supérieure, s'éloignant du son mécanique et monotone pour offrir un timbre riche et nuancé, empreint d'émotion, pour un résultat chaleureux et vivant.
« VibeVoice - Synthèse vocale en temps réel » est désormais disponible dans la section tutoriels du site web HyperAI (hyper.ai). Déployez-le et testez-le en un seul clic !
Lien du tutoriel :
Essai de démonstration
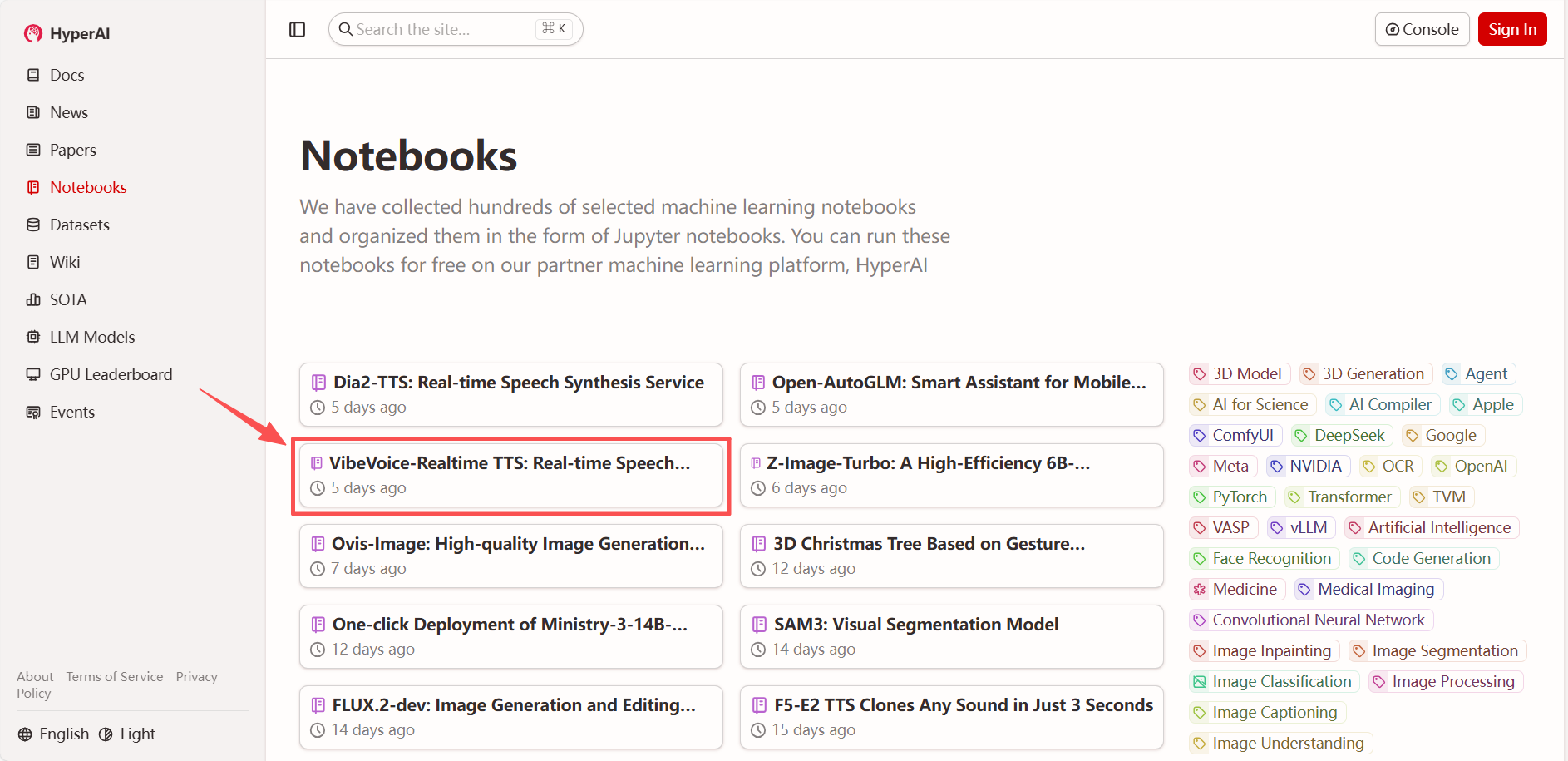
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez « VibeVoice - Synthèse vocale en temps réel » ou sélectionnez-le depuis la page « Tutoriels ». Cliquez ensuite sur « Exécuter ce tutoriel en ligne ».
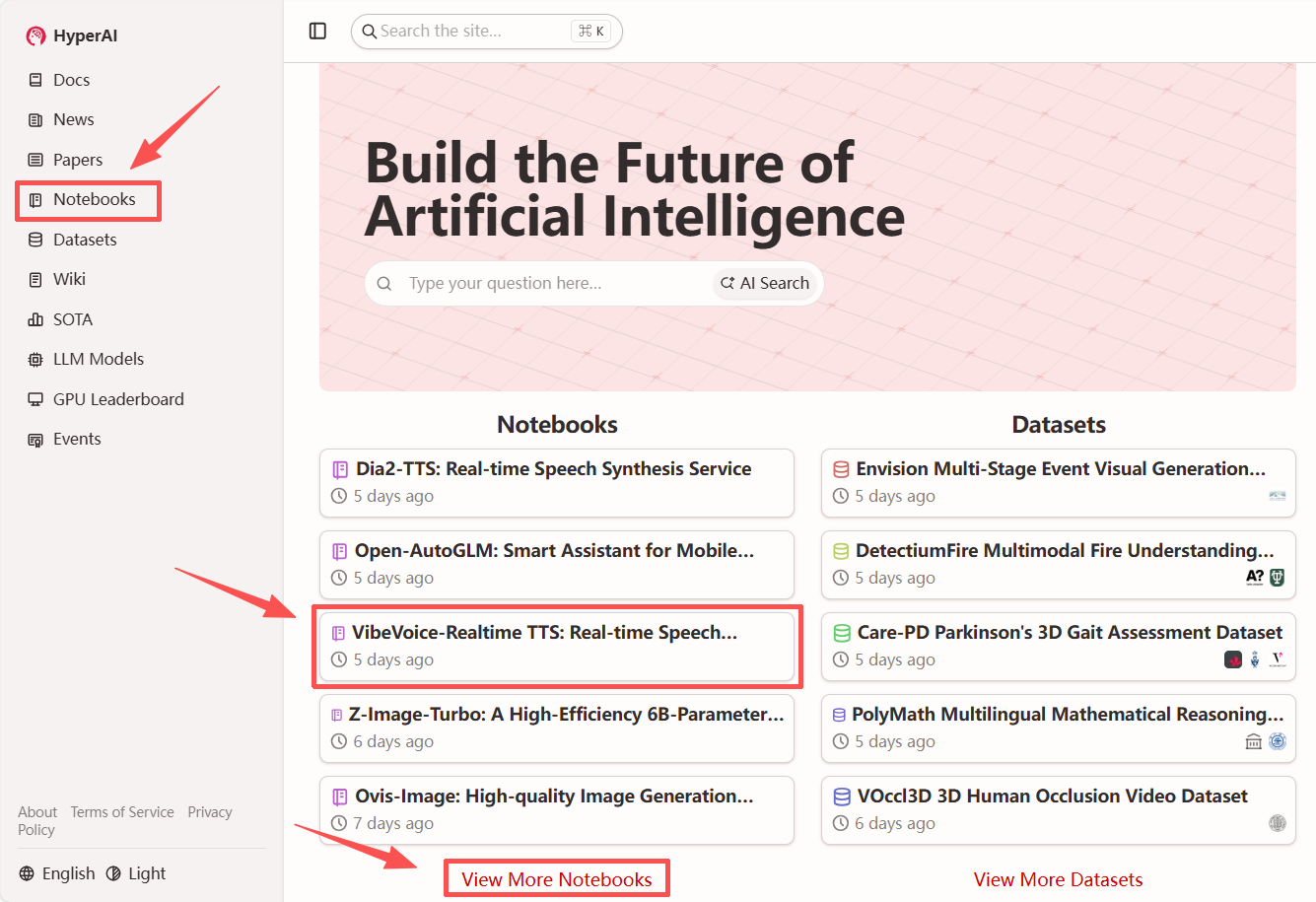
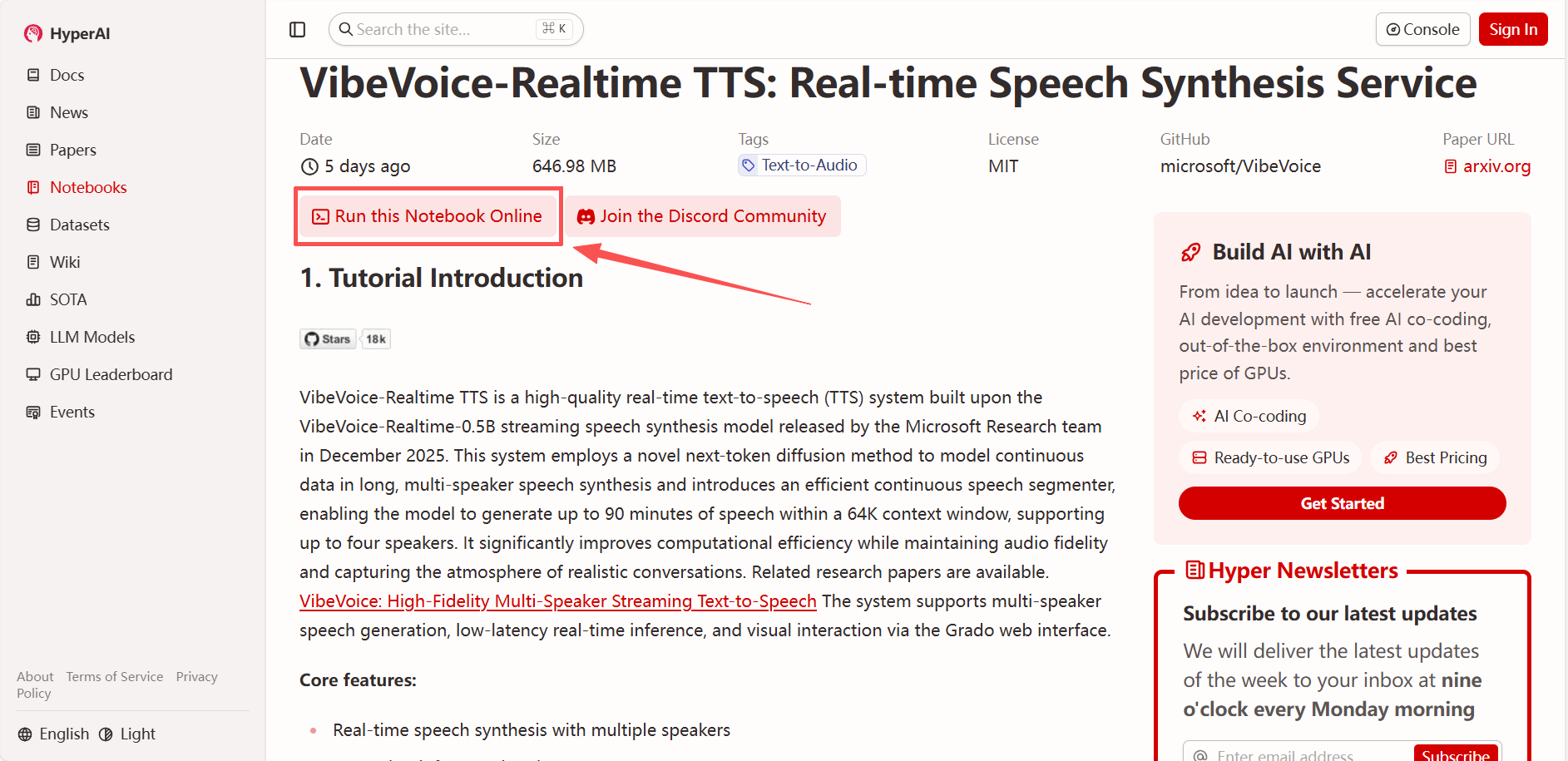
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
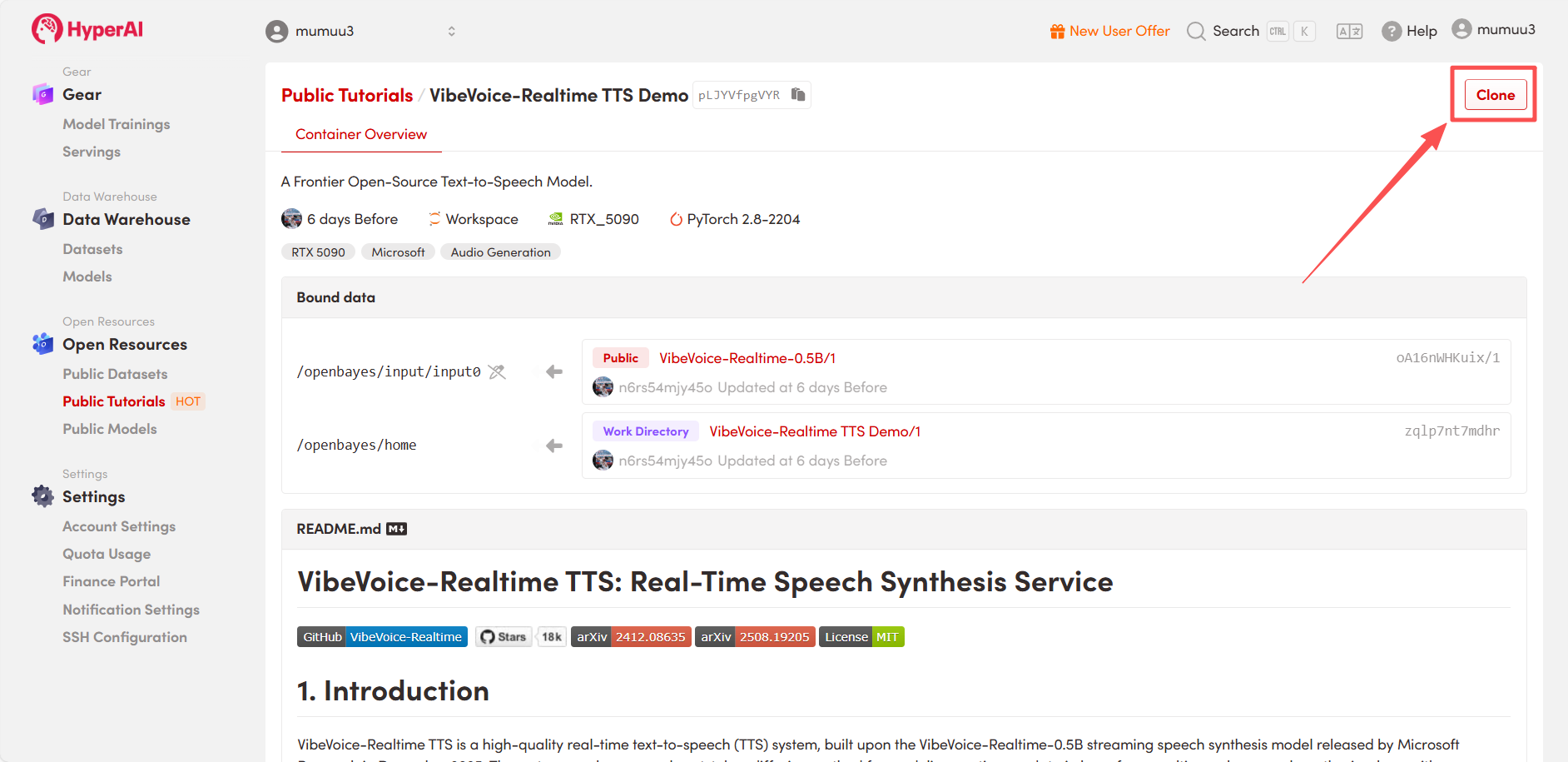
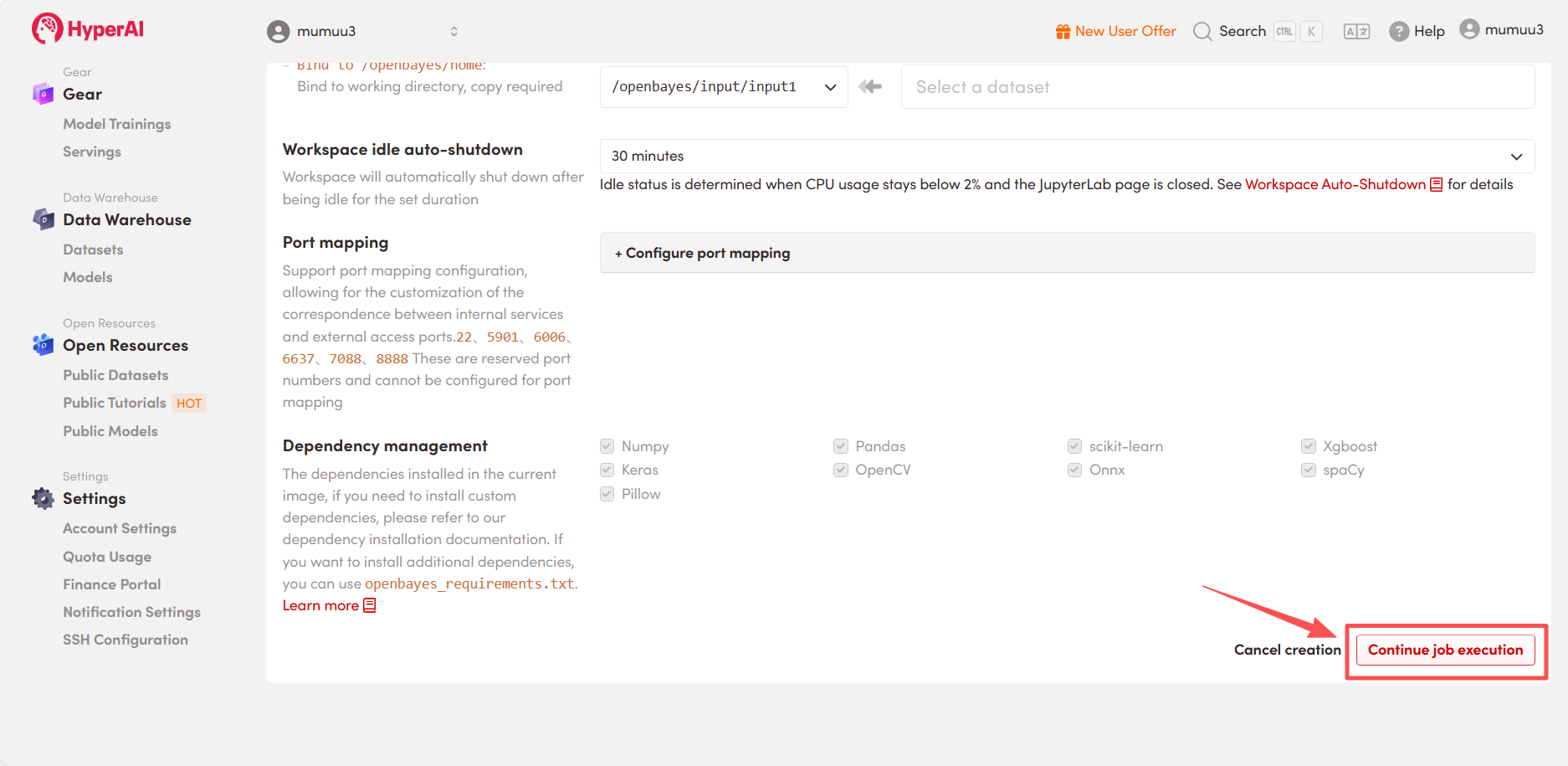
3. Sélectionnez les images « NVIDIA GeForce RTX 5090 » et « PyTorch », puis choisissez « Pay As You Go » ou « Daily Plan/Weekly Plan/Monthly Plan » selon vos besoins, puis cliquez sur « Continuer l’exécution de la tâche ».
HyperAI offre un bonus d'inscription aux nouveaux utilisateurs : pour seulement $1, vous pouvez obtenir 5 heures de puissance de calcul RTX 5090 (prix initial : $2,45), et les ressources sont valables indéfiniment.
4. Patientez pendant l'allocation des ressources. Le premier clonage prendra environ 3 minutes. Une fois l'état passé à « En cours d'exécution », cliquez sur la flèche à côté de « Adresse API » pour accéder à la page de démonstration.
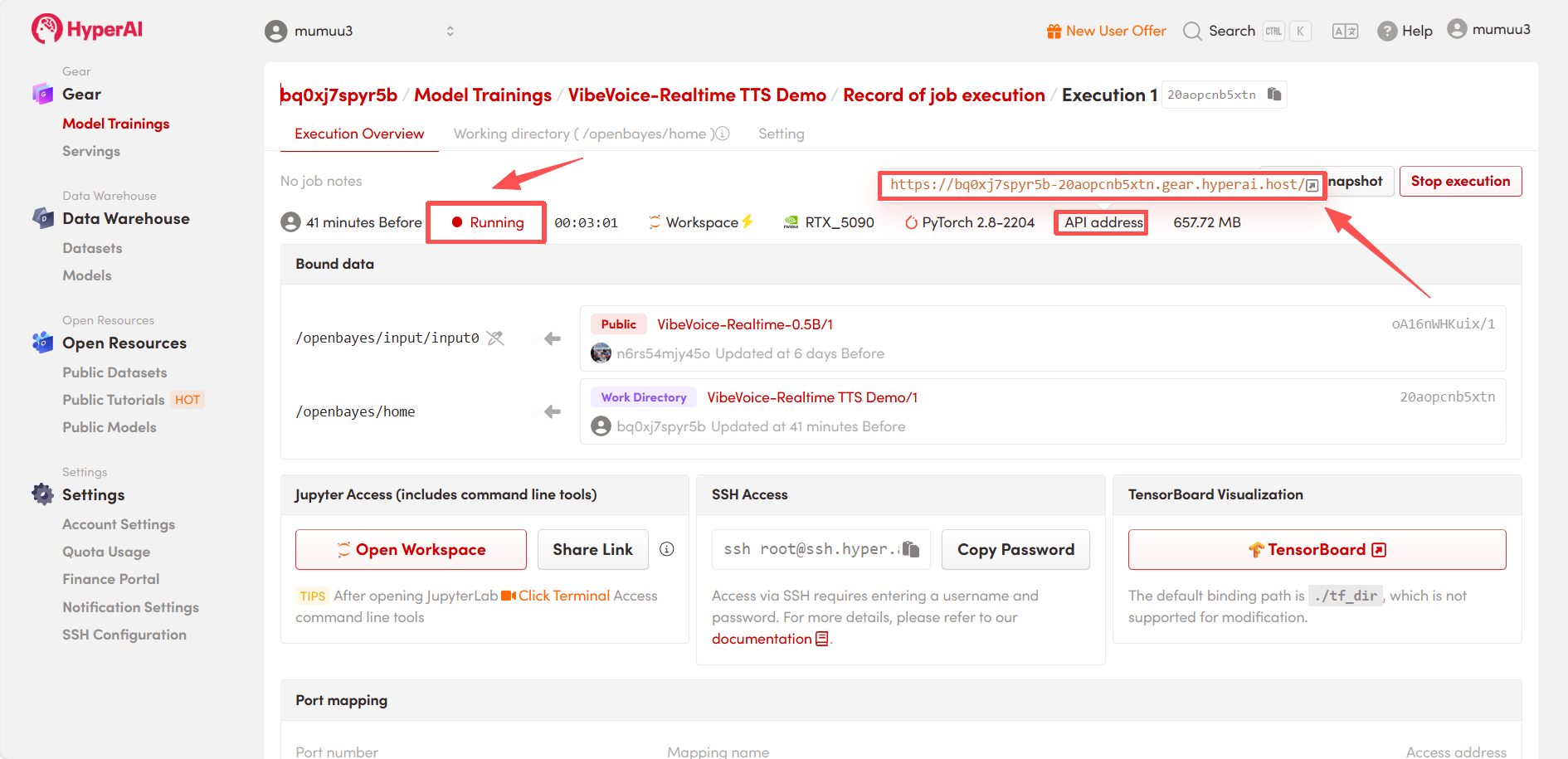
Démonstration d'effet
Une fois sur la page de démonstration, téléchargez votre vidéo de test, saisissez le texte dans le champ « Texte à convertir » et choisissez parmi 7 timbres de voix disponibles dans l'option « Voix du locuteur ». L'intensité du style de parole est contrôlée par le paramètre « Échelle CFG » ; une valeur plus élevée indique une émotion plus forte. Enfin, cliquez sur « Générer la parole » et patientez quelques instants pendant la génération de l'audio.
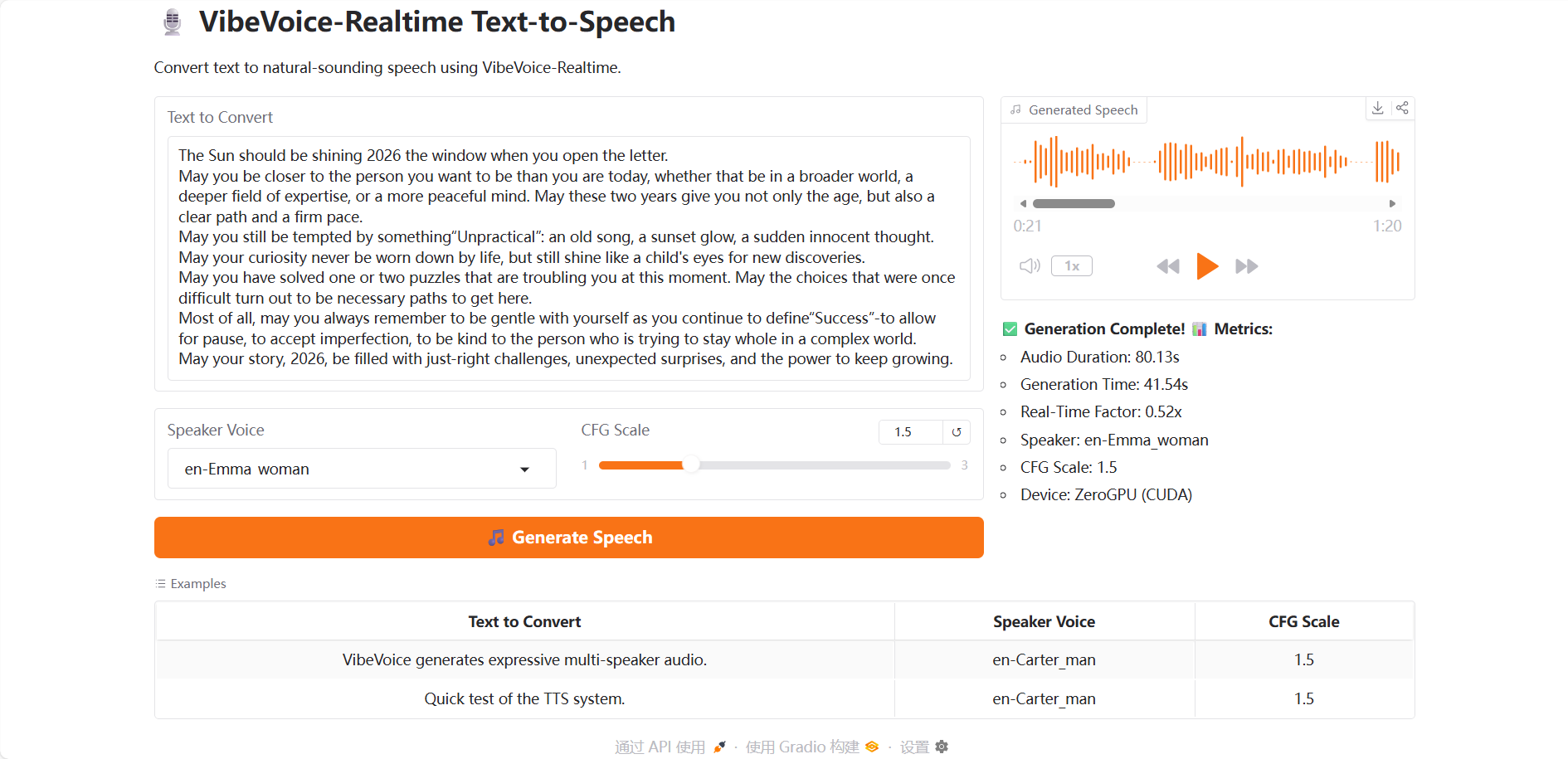
Alors que l'année touche à sa fin, cliquez pour écouter les vœux de Nouvel An de VibeVoice !
Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
Lien du tutoriel :








