Command Palette
Search for a command to run...
Tutoriel En Ligne | Deepseek-OCR Atteint Des Performances De Pointe Dans Les Modèles De Bout En Bout Avec Un Nombre Minimal De Jetons Visuels

Comme on le sait, lorsque de grands modèles de langage traitent des textes de plusieurs milliers, dizaines de milliers, voire davantage, la charge de calcul augmente souvent considérablement, pouvant même engendrer un gaspillage de ressources informatiques. Ceci limite également l'efficacité des modèles de langage dans le traitement de données textuelles à haute densité.
Alors que l'industrie explore sans cesse des moyens d'optimiser l'efficacité des calculs, Deepseek-OCR propose une perspective inédite : peut-on « lire » efficacement un texte en utilisant les mêmes méthodes que celles employées pour le « voir » ? Partant de cette idée novatrice, des chercheurs ont découvert qu'une simple image contenant le texte d'un document peut représenter une multitude d'informations avec beaucoup moins de symboles que son équivalent numérique. Ainsi, lorsque l'on choisit de fournir des informations textuelles sous forme d'images à de grands modèles de compréhension et de mémorisation, l'efficacité globale peut être considérablement améliorée. Il ne s'agit plus simplement de traitement d'images.Il s'agit plutôt d'une « compression optique » ingénieuse, utilisant les modalités visuelles comme moyen de compression efficace pour les informations textuelles, permettant ainsi d'atteindre un taux de compression bien supérieur à celui de la représentation textuelle traditionnelle.
Plus précisément, DeepSeek-OCR se compose de deux éléments : DeepEncoder et DeepSeek3B-MoE-A570M. L’encodeur (DeepEncoder) est chargé d’extraire les caractéristiques de l’image, de segmenter les mots et de compresser les représentations visuelles, tandis que le décodeur (DeepSeek3B-MoE-A570M) sert à générer les résultats souhaités à partir des étiquettes et des invites de l’image.DeepEncoder, en tant que moteur principal, est conçu pour maintenir un faible niveau d'activation sous une entrée haute définition tout en atteignant un taux de compression élevé, afin de garantir que le nombre de jetons visuels soit à la fois optimisé et facile à gérer.Les expériences montrent que lorsque le nombre de jetons textuels est inférieur à 10 fois le nombre de jetons visuels (c'est-à-dire un taux de compression < 10×), le modèle atteint une précision de décodage (OCR) de 971 TP3T. Même avec un taux de compression de 20×, la précision de l'OCR reste aux alentours de 601 TP3T.
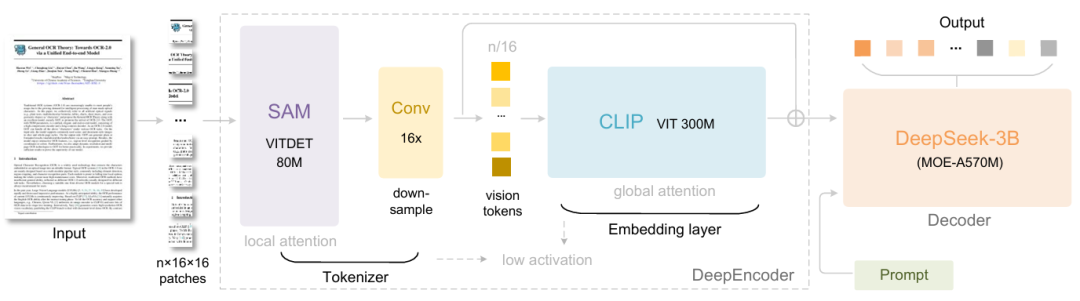
La sortie de DeepSeek-OCR représente non seulement une avancée dans les tâches d'OCR, mais démontre également un potentiel énorme dans des domaines de recherche de pointe tels que la compression de contextes longs et l'exploration des mécanismes d'oubli de la mémoire dans les LLM.
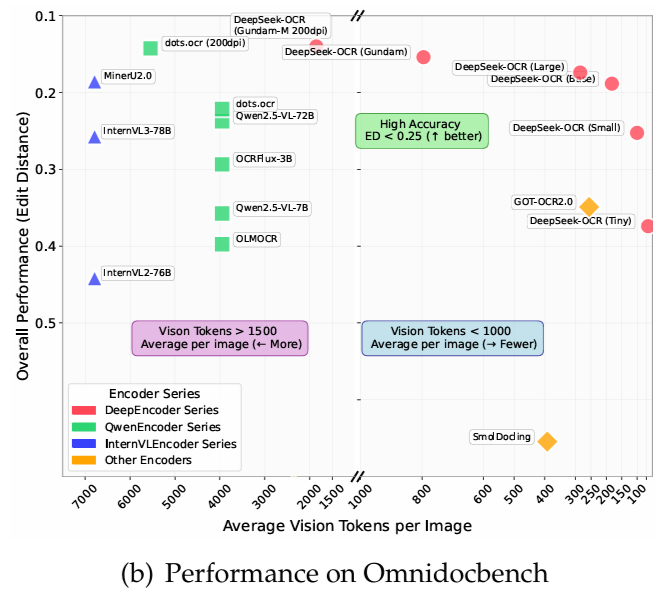
Sur OmniDocBench,Il surpasse GOT-OCR2.0 (256 jetons par page) en utilisant seulement 100 jetons visuels.De plus, il surpasse MinerU2.0 (plus de 6 000 jetons par page en moyenne) avec moins de 800 jetons visuels. En production, DeepSeek-OCR peut générer plus de 200 000 pages de données d'entraînement par jour pour les LLM/VLM (avec un seul A100-40G).
« DeepSeek-OCR : La compression visuelle remplace la reconnaissance de caractères traditionnelle » est désormais disponible dans la section « Tutoriels » du site web HyperAI (hyper.ai). Déployez-le et testez-le en un clic !
* Lien du tutoriel :
* Voir les articles connexes :
https://hyper.ai/papers/DeepSeek_OCR
Essai de démonstration
1. Après avoir accédé à la page d'accueil de hyper.ai, sélectionnez « DeepSeek-OCR : Compression visuelle au lieu de la reconnaissance de caractères traditionnelle », ou rendez-vous sur la page « Tutoriels » et sélectionnez « Exécuter ce tutoriel en ligne ».
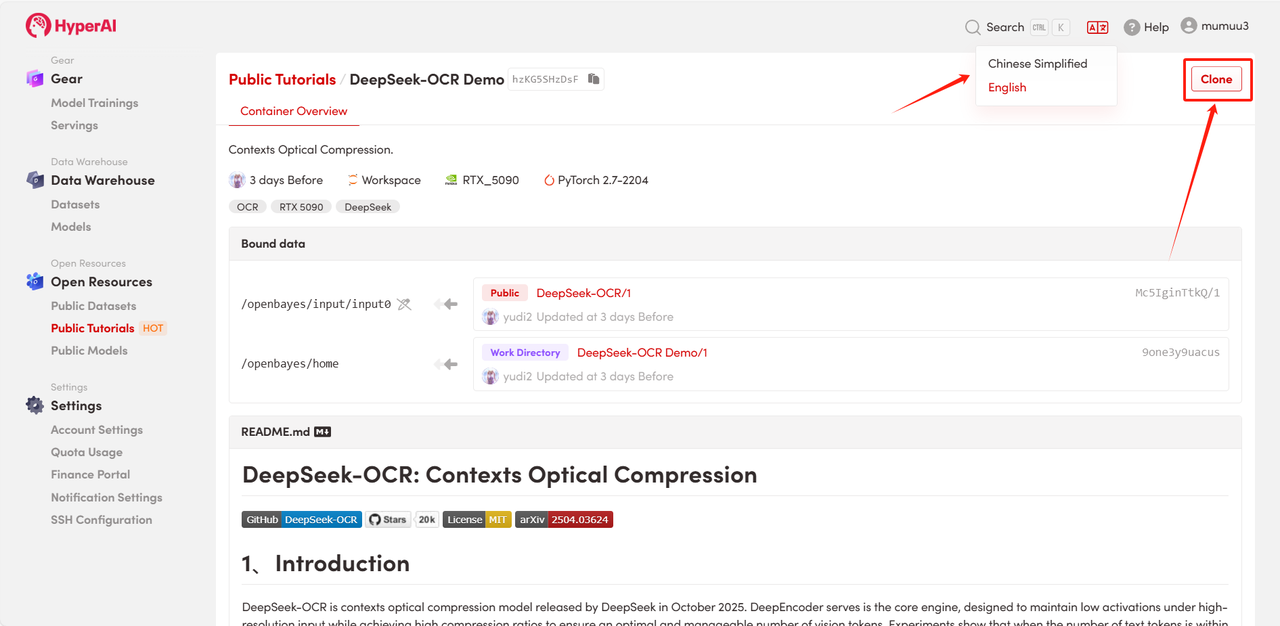
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
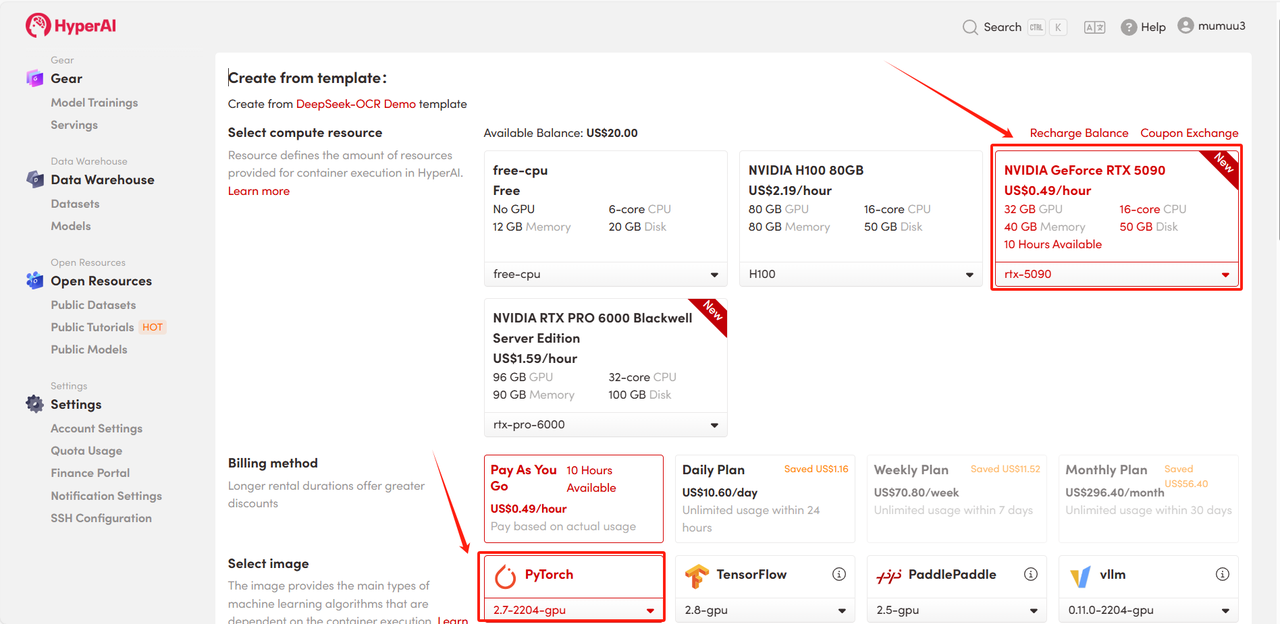
3. Sélectionnez les images « NVIDIA GeForce RTX 5090 » et « PyTorch », puis choisissez « Pay As You Go » ou « Daily Plan/Weekly Plan/Monthly Plan » selon vos besoins, puis cliquez sur « Continuer l’exécution de la tâche ».
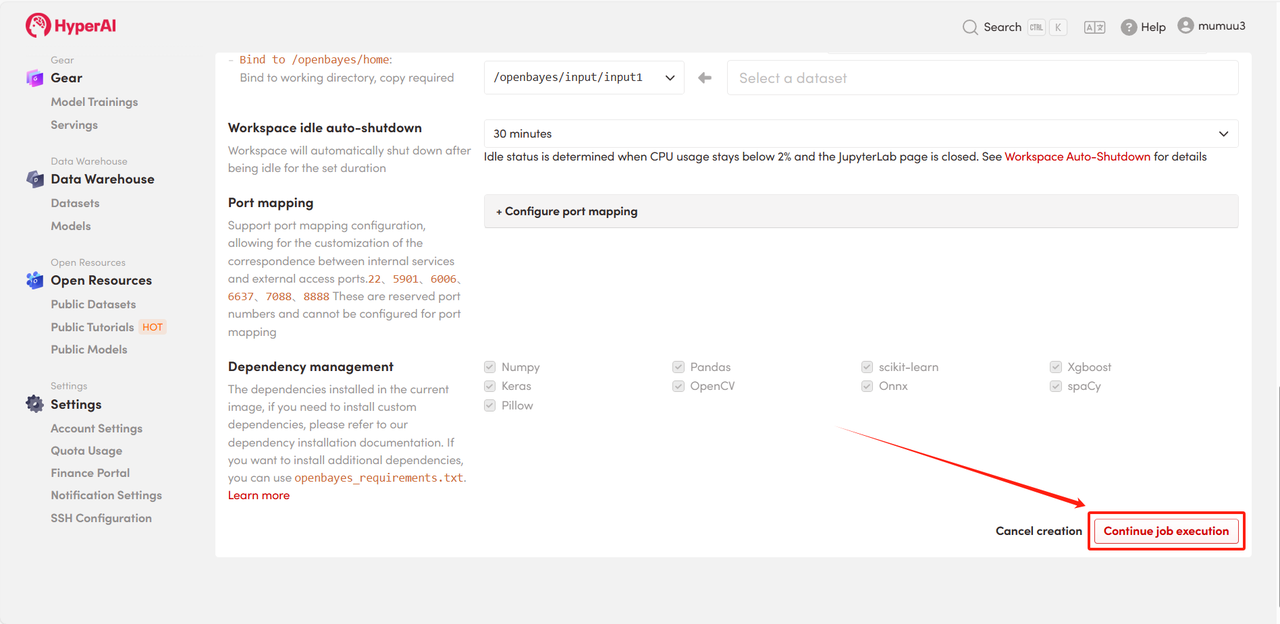
4. Patientez pendant l'allocation des ressources. Le premier clonage prendra environ 3 minutes. Une fois l'état passé à « En cours d'exécution », cliquez sur la flèche à côté de « Adresse API » pour accéder à la page de démonstration.
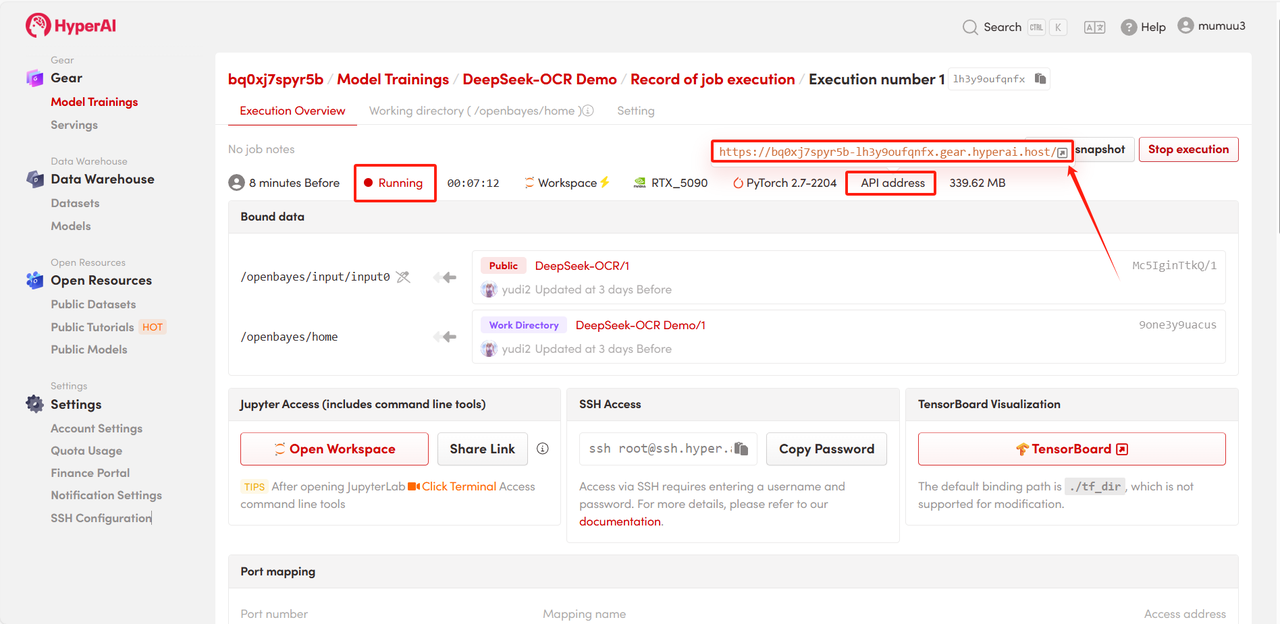
Démonstration d'effet
Après avoir accédé à la page de démonstration, téléchargez l'image du document à analyser, puis cliquez sur « Extraire le texte » pour lancer l'analyse.
Le modèle commence par diviser les modules de texte ou de graphique dans l'image, puis génère le texte au format Markdown.

Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
* Lien du tutoriel :








