Command Palette
Search for a command to run...
Les Membres Initiaux De l'équipe CUDA Ont Vivement Critiqué cuTile Pour Avoir « Spécifiquement Ciblé » Triton ; Le Paradigme Tile peut-il Remodeler Le Paysage Concurrentiel De l'écosystème De Programmation GPU ?

En décembre 2025, près de vingt ans après la sortie de CUDA, NVIDIA a lancé la dernière version, CUDA 13.1. Le principal changement réside dans le nouveau modèle de programmation CUDA Tile (cuTile).La structure du noyau GPU a été réorganisée grâce à un modèle de programmation « basé sur les tuiles », permettant aux développeurs d'écrire des noyaux hautes performances sans manipuler directement le code CUDA C++ sous-jacent.Il s'agit sans aucun doute d'une étape importante pour l'écosystème de programmation GPU : il pourrait s'agir d'une nouvelle gamme de produits lancée par NVIDIA pour répondre à la demande croissante d'opérateurs personnalisés à l'ère de l'IA et renforcer encore la fidélisation de l'écosystème logiciel.
Après son apparition sur le marché, cuTile a rapidement suscité de nombreux débats au sein de la communauté des développeurs concernant le cycle de développement des opérateurs personnalisés, la concurrence directe avec Triton et son potentiel à devenir le point d'entrée par défaut de Python. Bien que cuTile soit encore à ses débuts, les retours des développeurs suggèrent qu'il pourrait déjà devenir un nouveau paradigme.
À mesure que l'écosystème concerné se structure, le positionnement et le potentiel de cuTile se précisent. Sur GitHub, dans les forums et au sein de projets internes, de nombreux ingénieurs ont confirmé les améliorations apportées par cuTile à l'organisation et à la lisibilité du code, tandis que certains utilisateurs de la communauté ont tenté de migrer du code CUDA existant vers cuTile. Grâce à sa compatibilité avec l'écosystème Python, cuTile deviendra-t-il le principal point d'entrée pour la programmation GPU, ou créera-t-il une nouvelle division technique des tâches entre CUDA et Triton ? L'émergence de charges de travail plus concrètes permettra sans doute de répondre à ces questions dans les années à venir.
cuTile : Vers une ère de programmation GPU axée sur le code
Depuis longtemps, CUDA fournit aux développeurs un modèle matériel et de programmation de multithreading à instruction unique (SIMT), leur permettant de décrire la logique de calcul parallèle du GPU à la granularité des « threads » : un noyau est divisé en milliers de threads, chaque thread effectue un petit segment de calcul, des groupes de threads forment des blocs, puis le matériel les mappe au multiprocesseur de flux (SM) pour exécution.
Cependant, avec la croissance exponentielle des besoins en calcul, notamment en matière d'entraînement de l'IA, au cours des 3 à 5 dernières années, cette programmation centrée sur les threads a rencontré de plus en plus de goulots d'étranglement.Les chercheurs et les ingénieurs doivent non seulement maîtriser la planification des threads, mais aussi prendre en compte en profondeur la fusion de la mémoire, la divergence des warps et même le format d'exécution des Tensor Cores. En d'autres termes, la conception d'un noyau CUDA haute performance exige une compréhension approfondie de tous les aspects de l'architecture de la carte graphique ; sans cela, il est difficile d'exploiter pleinement les capacités du matériel.
L'apparition de cuTile est la réponse de NVIDIA à cette tendance, permettant aux développeurs de revenir aux algorithmes, tout en laissant le gain de performance matérielle au framework.
Spécifiquement,cuTile est un modèle de programmation parallèle pour les GPU NVIDIA et un langage dédié (DSL) basé sur Python. Il peut exploiter automatiquement les capacités matérielles avancées.Par exemple, les cœurs Tensor et les accélérateurs de mémoire Tensor, et ils conservent une bonne portabilité sur différentes architectures GPU NVIDIA.

D'un point de vue technique,CUDA Tile repose sur CUDA Tile IR (Intermediate Representation), qui introduit un ensemble d'instructions virtuelles permettant de programmer nativement le matériel selon une architecture basée sur les tuiles. Les développeurs peuvent ainsi écrire du code de haut niveau exécutable efficacement sur plusieurs générations de GPU avec un minimum de modifications.
Bien que la technologie Parallel Thread Execution (PTX) de NVIDIA garantisse la portabilité des programmes SIMT,Cependant, CUDA Tile IR étend la plateforme CUDA pour prendre en charge nativement les applications basées sur des tuiles.Les développeurs peuvent se concentrer sur la division des programmes parallèles en tuiles et blocs de tuiles, CUDA Tile IR se chargeant de l'affectation de ces tuiles aux ressources matérielles, notamment les threads, les hiérarchies de mémoire et les cœurs tenseurs. Autrement dit, la programmation par tuiles permet aux développeurs d'écrire des algorithmes en spécifiant des tuiles et en définissant les opérations de calcul effectuées sur ces tuiles, sans avoir à configurer individuellement la méthode d'exécution de chaque élément de l'algorithme ; ces détails sont gérés par le compilateur.
Pourquoi NVIDIA a-t-elle choisi de mettre à jour son paradigme de programmation après 20 ans d'implémentation de CUDA ?
La sortie de cuTile intervient près de vingt ans après la sortie initiale de CUDA.Depuis son lancement en 2006, CUDA a progressivement évolué d'une interface de programmation GPU à un écosystème complet englobant frameworks, compilateurs, bibliothèques et chaînes d'outils, et continue de constituer une infrastructure essentielle du système logiciel NVIDIA. La décision de NVIDIA de lancer un nouveau paradigme de programmation pour faire évoluer CUDA en 2025 n'est pas seulement une évolution technologique, mais une réponse directe aux mutations du secteur.
D'une part, l'évolution des charges de travail en IA a engendré une demande extrêmement forte d'opérateurs personnalisés, et la vitesse de développement, les coûts de débogage et la pénurie de talents liés au CUDA C++ traditionnel sont devenus des contraintes. De nombreuses équipes parviennent à concevoir rapidement des algorithmes, mais peinent à écrire des noyaux CUDA performants et maintenables dans un délai restreint. Le lancement de cuTile vise précisément à résoudre cette contradiction : sans sacrifier les performances, il offre un point d'entrée convivial pour Python, permettant à un plus grand nombre de développeurs de créer des opérateurs personnalisés à un coût maîtrisé, abaissant ainsi le seuil global de la programmation GPU et raccourcissant le cycle d'itération.
Autrement dit,cuTile est la première initiative stratégique de NVIDIA pour reprendre le contrôle du paradigme de programmation avant le début des guerres DSL à grande échelle entre opérateurs.
Par ailleurs, dans le contexte de la « dé-Nvidiaisation », la concurrence au sein de l'écosystème logiciel des GPU s'intensifie : AMD a lancé ROCm, une plateforme de calcul accéléré open source, attirant ainsi davantage de bibliothèques et d'outils tiers grâce à son architecture ouverte et à l'élargissement de son écosystème ; Intel a lancé OneAPI, visant à construire un modèle de programmation unifié pour toutes les architectures et offrant la prise en charge de langages tels que DPC++ afin de simplifier le développement de systèmes hétérogènes. Tous ces éléments contribuent à fragiliser la position dominante de CUDA.
Par ailleurs, les entreprises spécialisées dans les modèles d'IA à grande échelle et les fabricants de puces se livrent une véritable course pour développer leurs propres DSL d'opérateurs. Dès octobre 2022, OpenAI a publié Triton. Ce compilateur open source de langage de programmation pour l'apprentissage profond sur GPU permet aux développeurs d'écrire des noyaux GPU haute performance à l'aide d'un code concis de type Python, sans avoir à se plonger dans les détails de bas niveau du CUDA C++. De ce fait, Triton a rapidement suscité l'intérêt de la communauté. De nombreux chercheurs et ingénieurs estiment que Triton facilite l'accès au développement d'opérateurs pour GPU. Parallèlement, les langages TC/tenseurs liés à Meta/FAIR, ainsi que les frameworks de compilation et d'optimisation d'opérateurs développés par la communauté autour de TVM/Relay/DeepSpeed, offrent également diverses options pour la compétition dans des domaines spécifiques de l'écosystème logiciel.
Cela a directement conduit à l'émergence de cuTile : afin de consolider son avantage concurrentiel, NVIDIA a dû améliorer davantage le packaging et l'expérience utilisateur de son système logiciel, afin que davantage de développeurs choisissent de rester dans l'écosystème CUDA. SemiAnalysis a publié un article affirmant que l'introduction de cuTile est une initiative importante de NVIDIA pour renforcer son avantage concurrentiel en matière de CUDA.Le compilateur PyTorch prend désormais en charge NVIDIA Python CuTeDSL en plus de Triton, ce qui rend FlexAttention deux fois plus rapide que l'implémentation Triton. NVIDIA a toujours été un fervent défenseur de son écosystème propriétaire Python CuTeDSL, cuTile et TileIR. Grâce à Python CuTeDSL/cuTile/TileIR, NVIDIA a retrouvé l'accès aux optimisations de son compilateur propriétaire.
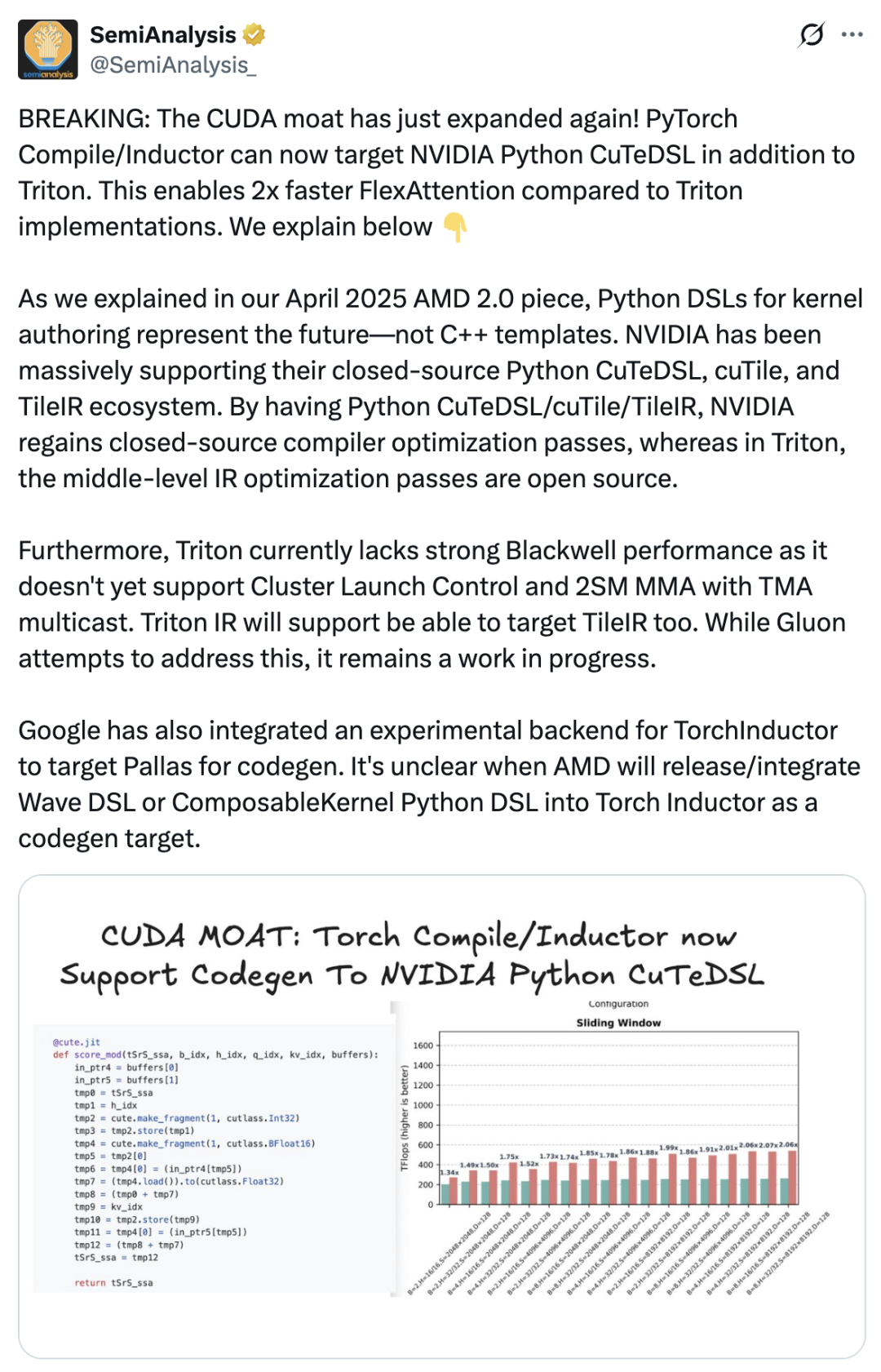
Copie de Triton ? « L’état d’esprit des tuiles » de cuTile : voici ce que disent les développeurs.
En fait,L'accueil réservé à cuTile par le marché a été mitigé et controversé.Certains développeurs ayant utilisé cuTile ont signalé que, malgré l'intérêt de l'optimisation Tile, le nombre excessif de DSL engendrait de nouvelles difficultés d'apprentissage. L'utilisateur Reddit Previous-Raisin1434 a indiqué s'être senti dépassé par ces nouveaux DSL lors de la transition.
« Pourquoi y a-t-il soudainement des milliers de choses différentes ? J'utilisais Triton auparavant, et maintenant NVIDIA a sorti plus d'une douzaine de nouveaux DSL », s'est-il plaint.
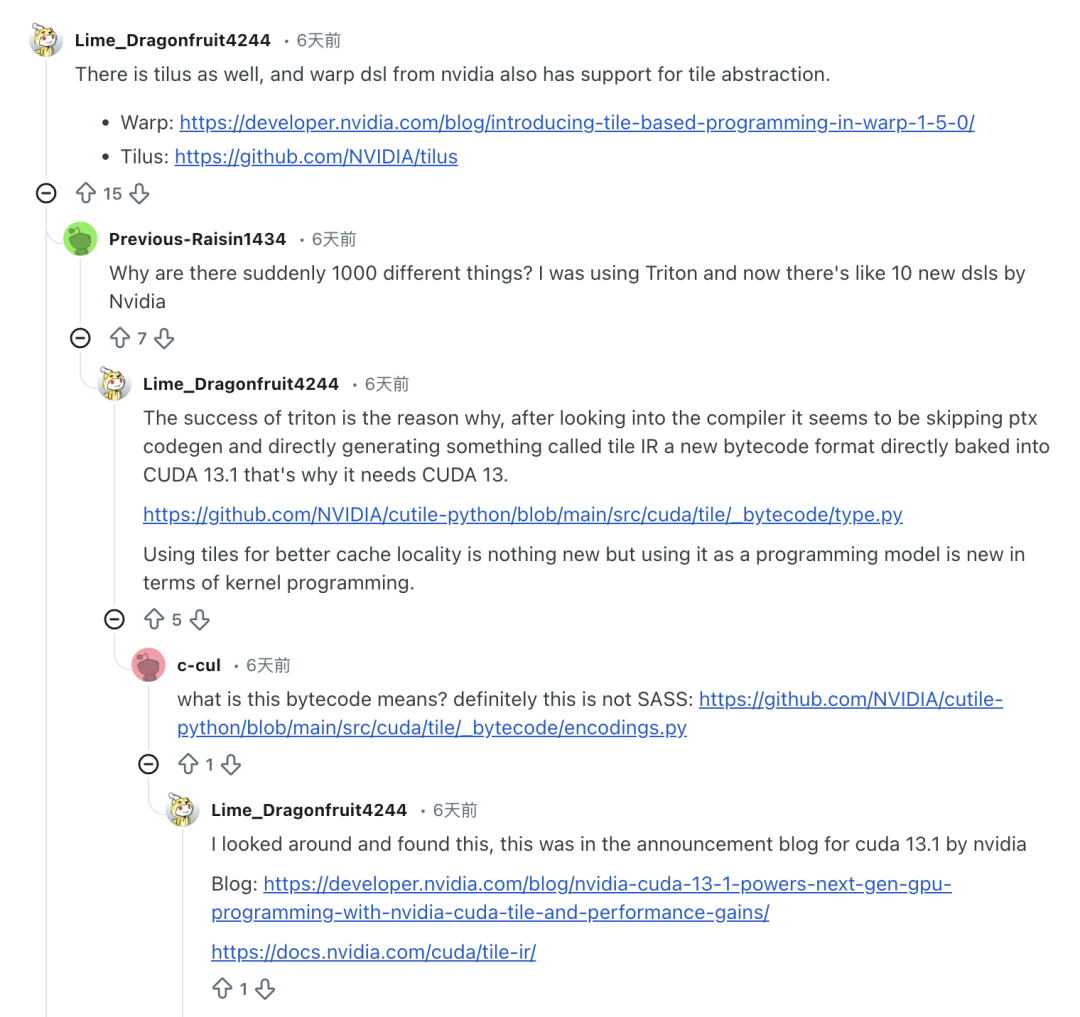
Parallèlement, certains professionnels du secteur ont remis en question le manque de différenciation et d'originalité de cuTile, déclarant : « cuTile donne l'impression d'être la réponse de NVIDIA à Triton, Mojo et ThunderKittens, comme s'ils avaient été intégrés ensemble. »

À cet égard,Nicholas Wilt, membre de l'équipe initiale de CUDA, a même publié un message indiquant que...« Il est difficile de ne pas soupçonner que cuTile a été développé directement pour contrer Triton. cuTile est un nouveau eDSL pour l'écriture de noyaux, tout comme Triton ou Helion. »
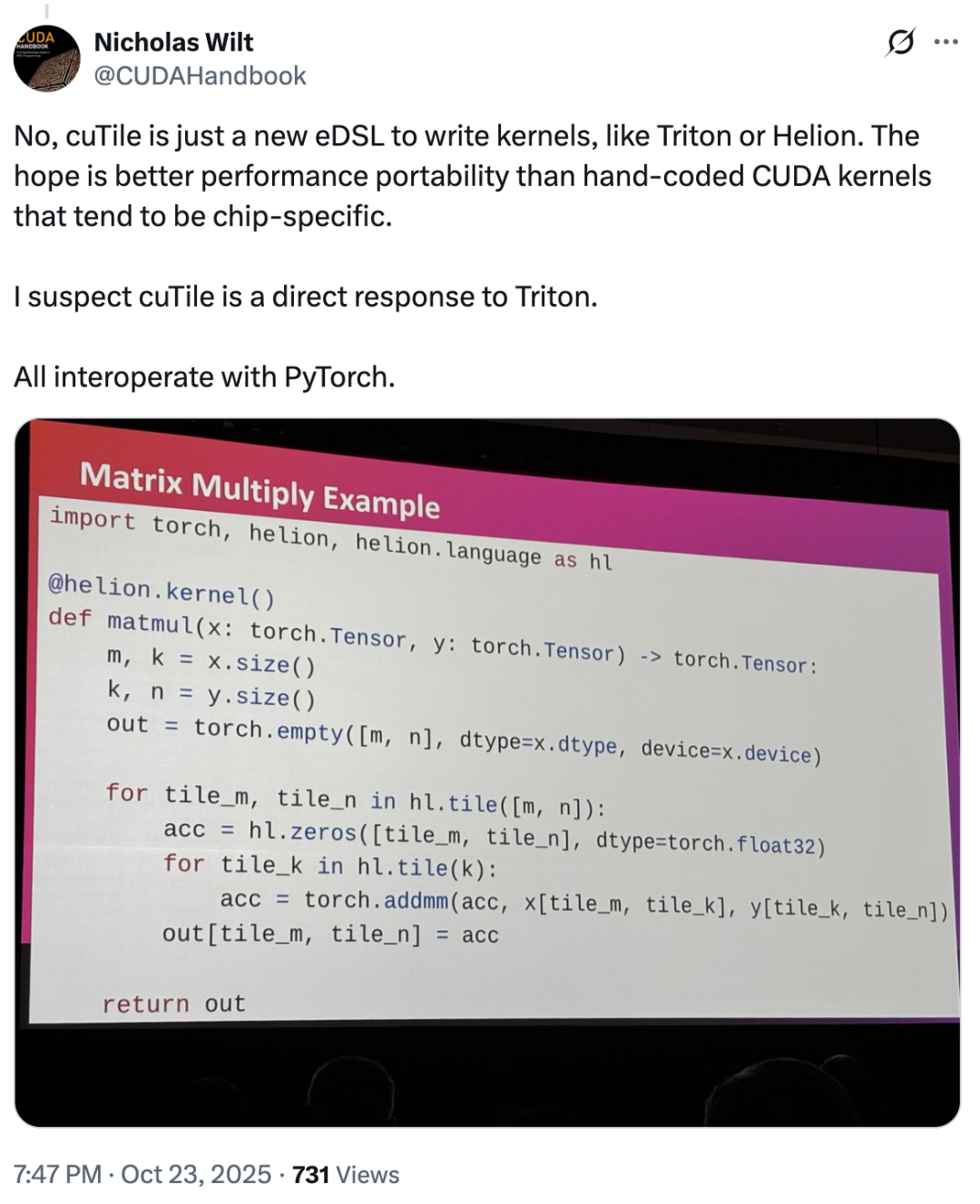
Alors, cuTile a-t-il copié Triton ? La plupart des utilisateurs ont répondu non – en fait, l’accueil du marché pour cuTile a été généralement optimiste, avec seulement quelques avis divergents.La plupart des utilisateurs n'ont pas exprimé de mécontentement face à cette mise à jour ; certains ont même qualifié cuTile de « produit révolutionnaire ».« cuTile élimine la nécessité pour les utilisateurs de se soucier de l'échange de mémoire, du warp spclz, de la fusion de mémoire et de plus d'une centaine d'autres problèmes. »
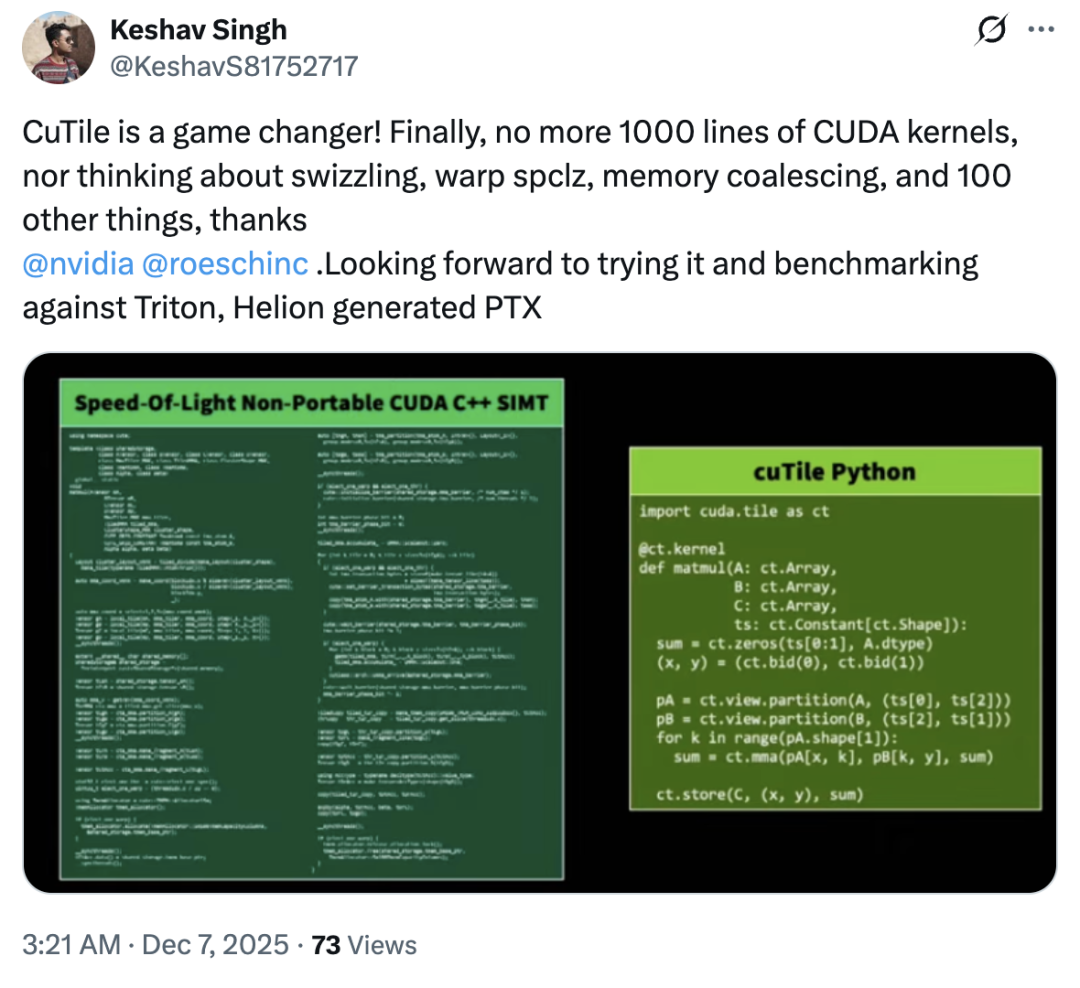
Selon un blog technologique, le principal atout de cuTile pour séduire les utilisateurs réside dans son concept de « tuile », qui introduit le calcul GPU à un niveau d'abstraction supérieur.
« Au départ, je pensais qu'il s'agissait simplement d'une autre interface Python ou d'un wrapper simplifié pour CUDA, mais après avoir étudié sa documentation et ses exemples, j'ai découvert qu'il avait des ambitions bien plus grandes. » L'idée centrale de cuTile est celle de la tuile, qui est pertinente pour le calcul parallèle et l'accélération matérielle.Le pavage est une technique d'optimisation classique qui consiste à diviser de grands ensembles de données en plus petits morceaux afin de mieux exploiter les caches ou la mémoire partagée. cuTile élève ce concept au rang de modèle de programmation. Le blog précise : « Il permet aux développeurs de concevoir et de décrire les calculs directement en termes de tuiles. Plus besoin de gérer explicitement la collaboration de chaque thread au sein d'un bloc, le chargement des données de la mémoire globale vers la mémoire partagée, ni la synchronisation. Il suffit de définir les tuiles de vos données et les opérations qui leur sont appliquées ; le compilateur cuTile génère alors automatiquement un code noyau efficace pour gérer ces détails techniques fastidieux. »
Bien que cuTile soit encore à ses débuts, certains acteurs du secteur ont déjà exploré de manière proactive les voies de migration.Certains spécialistes des algorithmes ont commencé à essayer de construire des outils de conversion automatisés de CUDA C++ vers cuTile.L'objectif est de créer un lien viable entre le code d'ingénierie existant et le nouveau paradigme. Dans ce contexte, des développeurs de la communauté Reddit ont lancé un projet open source capable de traduire certaines parties du noyau CUDA en un format modulaire afin de répondre aux besoins potentiels de migration de la communauté.
Cependant, il est difficile de prédire jusqu'où ira le paradigme « Tile » de NVIDIA : cuTile, produit récent, n'en est qu'à ses débuts en phase de validation. Si la chaîne d'outils de migration de CUDA vers cuTile continue de gagner en maturité et si la communauté s'engage dans de nouveaux échanges et expérimentations autour de cuTile, ce dernier pourrait occuper une place inédite dans l'écosystème logiciel des GPU de demain.Cependant, les conséquences de l'échec à franchir ces seuils sont assez claires : cuTile pourrait bien n'être qu'une brève expérience dans la longue histoire de CUDA.En conclusion, dans le contexte concurrentiel actuel, l'attrait continu de cuTile dépendra de sa capacité à optimiser en permanence l'expérience de développement, à réduire les coûts de migration et à offrir des avantages de performance irremplaçables aux opérateurs complexes.
Liens de référence :
1.https://byteiota.com/nvidia-cutile-python-gpu-kernel-programming-without-cuda-complexity/
2.https://veyvin.com/archives/github-trending-2025-12-08-nvidia-cutile-python
3.https://cloud.tencent.com/developer/article/2512674
4.https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware








