Command Palette
Search for a command to run...
L'équipe De David Baker a Annoncé Une Mise À Jour Majeure : RFantibody Permet Le Développement d'anticorps Personnalisés Pour Des Cibles Spécifiques ; VisualOverload Repousse Les Limites De La Compréhension Visuelle, Conduisant À De Nouvelles Avancées Dans Le Raisonnement De Scènes complexes.

Les anticorps constituent le pilier des thérapies protéiques actuelles. À l'échelle mondiale, plus de 160 médicaments à base d'anticorps ont été approuvés pour la commercialisation, et le marché devrait atteindre 445 milliards de dollars américains au cours des cinq prochaines années.Cependant, le développement d’anticorps thérapeutiques repose encore principalement sur l’immunisation animale ou sur le criblage de molécules candidates à partir de grandes bibliothèques d’anticorps.Ces méthodes sont non seulement longues et exigeantes en main-d’œuvre, mais elles rendent également souvent difficile la conception précise de nouveaux anticorps correspondant aux épitopes spécifiques de la cible.
Sur cette base,L'équipe de David Baker a lancé une nouvelle génération d'outils de conception d'anticorps et de nanoanticorps RFantibody, finement optimisés sur la base de la diffusion RF.Conçu pour fournir aux chercheurs et aux ingénieurs biotechnologiques une méthode de conception de novo efficace, l'outil utilise l'apprentissage en profondeur pour générer des structures d'anticorps (en particulier les régions CDR), puis utilise ProteinMPNN pour concevoir des séquences, puis utilise RF2 (RoseTTAFold2) pour vérifier qu'elles se replient dans la structure attendue.
En tant qu'outil efficace de conception de protéines, l'anticorps RF est largement utilisé dans la recherche biomédicale, le développement de médicaments, la conception de vaccins et d'autres domaines, offrant un nouvel outil pour la recherche biomédicale.
Le site officiel d'HyperAI a lancé « RFantibody : outil de conception d'anticorps et de nanocorps ». Venez l'essayer !
Utilisation en ligne:https://go.hyper.ai/sO07A
Du 15 au 19 septembre, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de qualité : 7
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en septembre : 1
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données d'images de chantier de construction
ConstructionSite est un jeu de données de référence multimodal pour les scénarios de chantier. Il est conçu pour évaluer et améliorer la compréhension d'images et les capacités de raisonnement des modèles de langage visuel dans les environnements de sécurité de la construction. Ce jeu de données présente des scènes complexes, des annotations variées et est proche des inspections de sécurité réelles. Il est adapté à des tâches telles que le sous-titrage d'images, les questions-réponses visuelles, la détection d'objets, la localisation visuelle et le raisonnement multimodal.
Utilisation directe : https://go.hyper.ai/ZRy12
2. Ensemble de données de référence HTSC-2025 pour les supraconducteurs à haute température et à pression atmosphérique
HTSC-2025 est un jeu de données de référence pour la prédiction de la température critique des supraconducteurs haute température à pression ambiante. Il vise à fournir des échantillons d'essai standardisés et comparables pour les modèles, favorisant ainsi le progrès et la validation des prédictions relatives aux supraconducteurs. Ce jeu de données contient environ 140 matériaux et est stocké au format JSON/Parquet pour un traitement aisé.
Utilisation directe : https://go.hyper.ai/G2bJB
3. Ensemble de données de compréhension d'images de scène VisualOverload
VisualOverload est un jeu de données permettant d'évaluer la compréhension d'images de scènes. Il est conçu pour tester la capacité d'un modèle à comprendre visuellement et à analyser les détails de scènes complexes sans recourir à des connaissances externes. Ce jeu de données contient 2 720 paires de questions-réponses composées de peintures haute résolution, appartenant au domaine public, présentant souvent de multiples personnages, actions, intrigues secondaires et arrière-plans complexes.
Utilisation directe : https://go.hyper.ai/Acce1

4. Ensemble de données de réponses aux questions de recherche d'informations WebExplorer-QA
WebExplorer-QA est un jeu de données pour la recherche d'informations et la navigation web. Il vise à améliorer les performances des modèles pour le raisonnement complexe en plusieurs étapes et la navigation web longue portée en générant systématiquement des paires requête-réponse complexes. Il est adapté à l'entraînement et à l'évaluation d'agents réseau ou de modèles de langage volumineux pour la recherche d'informations, le raisonnement contextuel complexe/multi-sauts, le traitement d'invites contextuelles longues, l'invocation d'outils et la navigation web.
Utilisation directe:https://go.hyper.ai/I58Ry
5. Ensemble de données de questions-réponses sur les romans classiques AnonyRAG
AnonyRAG est un jeu de données de type questions-réponses pour l'anonymisation d'entités, publié par Tencent Youtu Lab, l'Université Monash et l'Université polytechnique de Hong Kong. Il vise à évaluer si le système de génération augmentée de récupération (RAG) s'appuie sur la récupération pour obtenir des preuves lorsque l'entité est anonymisée.
Utilisation directe : https://go.hyper.ai/jzqD9
6. Ensemble de données de réponses aux questions de chimie organique RxnBench
RxnBench est un jeu de données de questions-réponses visuelles pour la compréhension d'images de réactions chimiques multimodales. Il vise à évaluer les capacités des modèles de langage visuel pour des tâches telles que la compréhension d'images de réactions chimiques, le raisonnement multimodal et la réponse à des questions scientifiques. Ce jeu de données contient 1 525 questions à choix multiples sur la compréhension des réactions chimiques organiques, disponibles en chinois et en anglais.
Utilisation directe : https://go.hyper.ai/Utkdo
7. Ensemble de données de rendu 3D de scènes intérieures SceneSplat-7K
SceneSplat-7 est le plus vaste et le plus qualitatif des jeux de données 3D Gaussian Splats (3DGS) de scènes d'intérieur. Il vise à améliorer la compréhension et le raisonnement sémantique des modèles pré-entraînés en langage visuel sur des scènes 3D d'intérieur réelles.
Accès direct : https://go.hyper.ai/HISAa
8. Ensemble de données de questions-réponses tabulaires semi-structurées SSTQA
SSTQA est un jeu de données de référence pour les tâches de questions-réponses sous forme de tableaux semi-structurés, publié par l'Université Jiao Tong de Shanghai en collaboration avec l'Université Simon Fraser, l'Université Tsinghua et d'autres institutions. Il vise à tester les capacités de compréhension et de réponse de grands modèles de langage et de systèmes de questions-réponses sous forme de tableaux face à des mises en page complexes dans des tableaux réels (cellules fusionnées, en-têtes hiérarchiques, imbrication multi-niveaux, etc.).
Utilisation directe : https://go.hyper.ai/JoZyB
9. Ensemble de données de référence de raisonnement spatial panoramique OmniSpatial
OmniSpatial est un jeu de données de référence standardisé, complet et exigeant, pour le raisonnement spatial panoramique. Il vise à combler une lacune dans l'évaluation de la compréhension spatiale des modèles vision-langage. Il est adapté à l'entraînement et à l'évaluation des capacités de raisonnement spatial de grands modèles multimodaux, notamment dans des applications telles que la navigation intelligente, la réalité augmentée/virtuelle et la compréhension de scènes complexes.
Utilisation directe : https://go.hyper.ai/a6ep8
10. Ensemble de données d'images sur les problèmes urbains
Urban Issues est un jeu de données public de classification d'images conçu pour aider les systèmes automatisés et de vision artificielle à identifier les problèmes d'infrastructures publiques et environnementaux en milieu urbain. Les images de ce jeu de données sont organisées par catégorie, chacune étant étiquetée selon une classe unique et présentée dans des conditions d'arrière-plan, d'éclairage et d'angle de vue variées.
Utilisation directe : https://go.hyper.ai/2id2J

Tutoriels publics sélectionnés
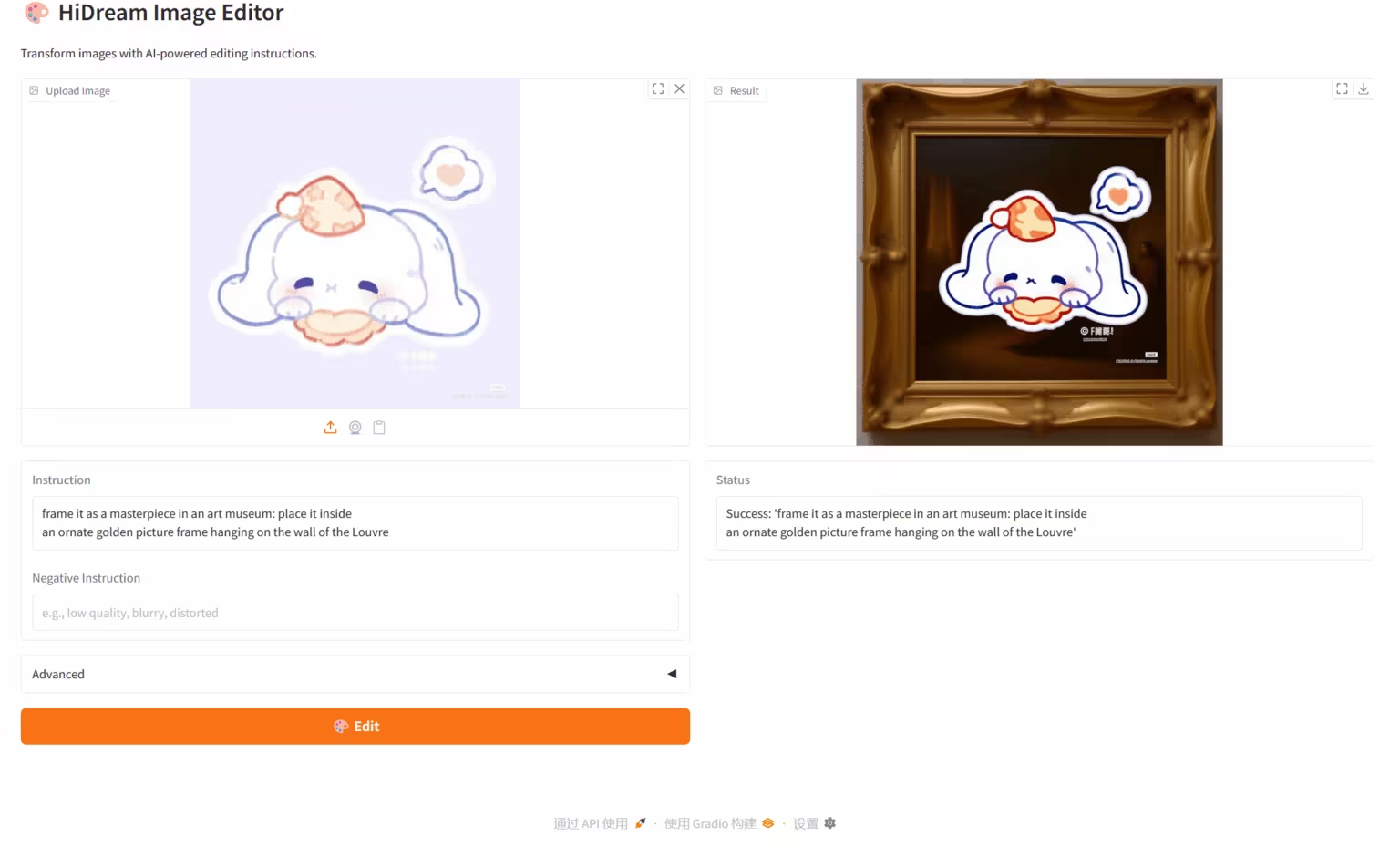
1. HiDream-E1.1 : éditeur d'images basé sur les commandes
Le modèle HiDream-E1.1 est un modèle d'édition d'images open source publié par Zhixiang Future. Basé sur son architecture propriétaire Sparse Diffusion Transformer, il prend en charge une résolution de plusieurs mégapixels et est sous licence open source du MIT. Ce modèle implémente des fonctionnalités d'édition d'images en langage naturel (speak, change). Les utilisateurs peuvent effectuer des tâches complexes telles que l'ajustement des couleurs, le transfert de style, l'ajout et la soustraction d'éléments grâce à des commandes simples, sans compétences logicielles spécifiques.
Exécutez en ligne : https://go.hyper.ai/P9C3R
2. RFantibody : outil de conception d'anticorps et de nanocorps
RFdiffusion2 est un outil de conception d'anticorps et de nanocorps développé par l'équipe de David Baker. Il vise à fournir aux chercheurs et aux ingénieurs en biotechnologie une approche de conception de novo efficace. Fondamentalement, l'outil s'appuie sur des techniques d'apprentissage profond pour prédire et concevoir la structure tridimensionnelle et la séquence d'acides aminés des anticorps à partir d'informations structurales, permettant ainsi le développement d'anticorps personnalisés ciblant des cibles spécifiques.
Exécutez en ligne : https://go.hyper.ai/sO07A
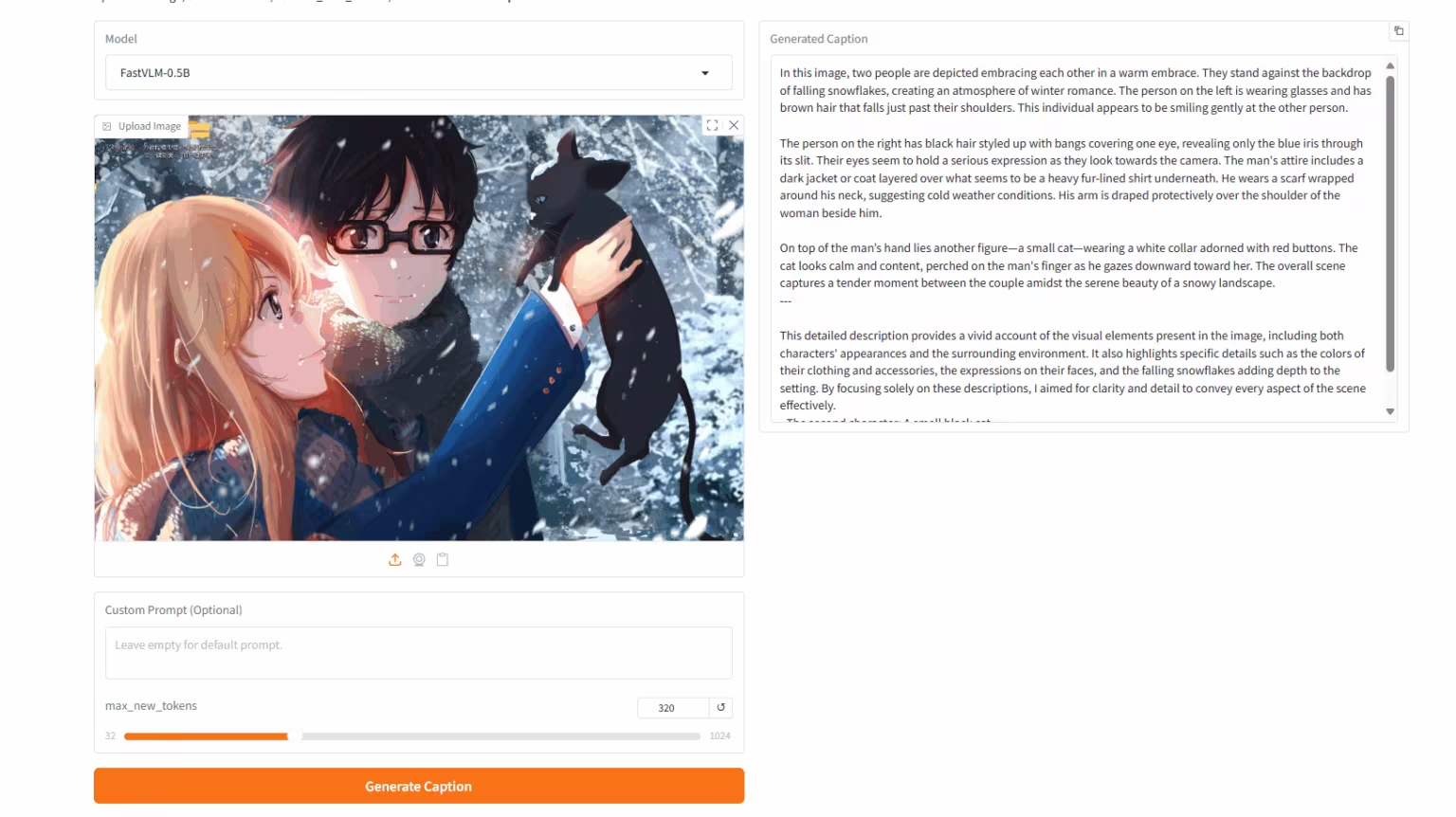
3. FastVLM : modèle de langage visuel extrêmement rapide
FastVLM est un modèle de langage visuel (MLV) hautement performant développé par l'équipe Apple. Il améliore l'efficacité et les performances du traitement d'images haute résolution. Ce modèle intègre le nouvel encodeur de vision hybride FastViTHD, réduisant ainsi efficacement le nombre de jetons visuels et considérablement le temps d'encodage.
Exécutez en ligne : https://go.hyper.ai/xg8wa
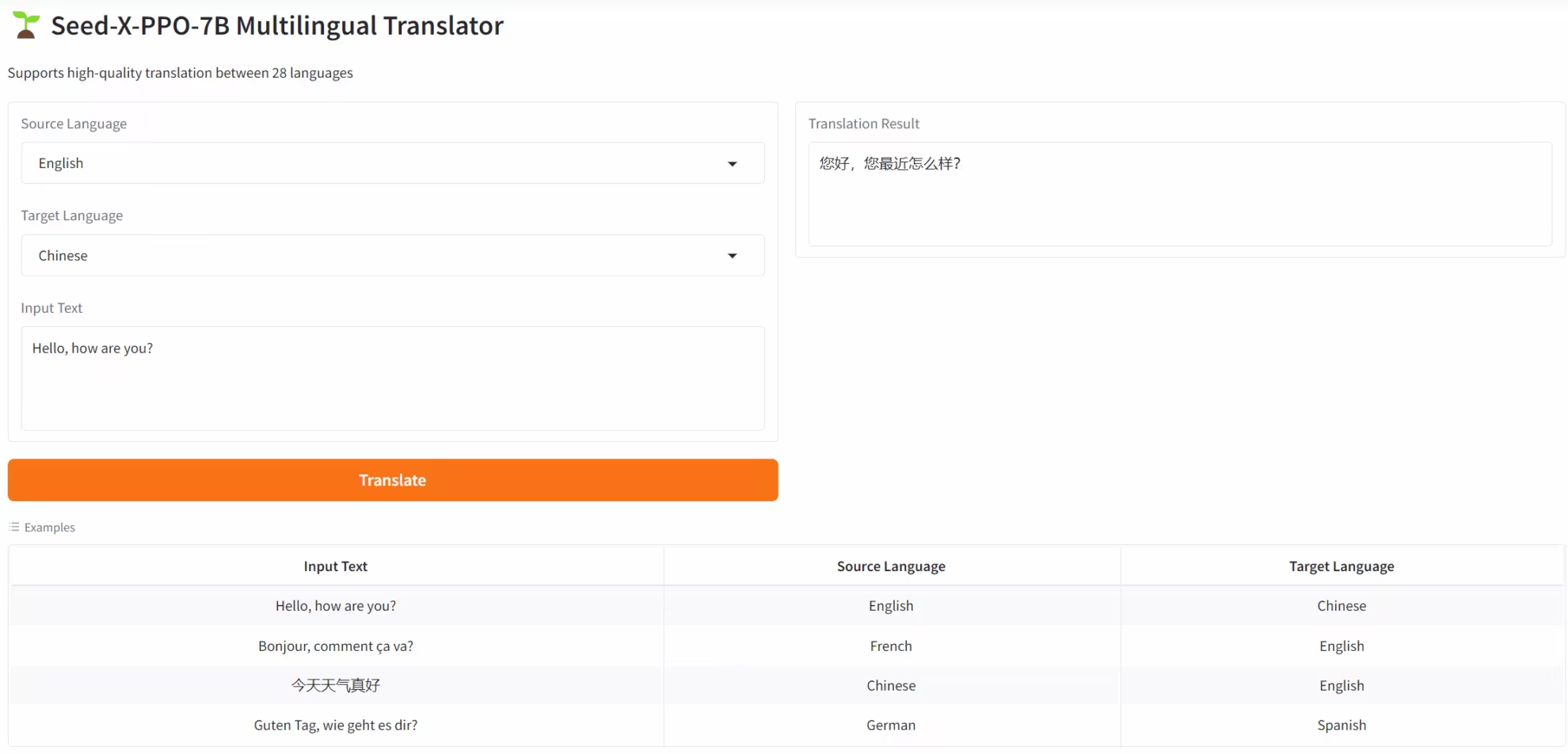
4. SEED-X-PPO-7B : Modèle de traduction multilingue optimisé par apprentissage par renforcement
SEED-X-PPO-7B est un modèle de traduction multilingue de nouvelle génération, développé par l'équipe Seed de ByteDance. Basé sur une optimisation itérative utilisant l'algorithme d'apprentissage par renforcement Proximal Policy Optimization (PPO), il vise principalement à répondre au besoin de transfert sémantique de haute précision dans les scénarios interlingues. Ce modèle surmonte les limites des modèles de traduction traditionnels : il s'adapte aux langues minoritaires, restaure le contexte culturel et garantit la cohérence des textes longs, prenant en charge la traduction entre 28 langues courantes, dont le chinois, l'anglais et l'allemand.
Exécutez en ligne : https://go.hyper.ai/aw5oS
5. SRPO : Dites adieu à la génération d’images de type IA !
SRPO est un modèle de conversion de texte en image développé conjointement par l'équipe Tencent Hunyuan, l'École des sciences de l'Université chinoise de Hong Kong (Shenzhen) et l'École doctorale internationale de Shenzhen de l'Université Tsinghua. En concevant le signal de récompense comme un signal conditionnel textuel, il permet un ajustement en ligne de la récompense et réduit la dépendance à un ajustement précis hors ligne.
Exécutez en ligne : https://go.hyper.ai/8OQxS

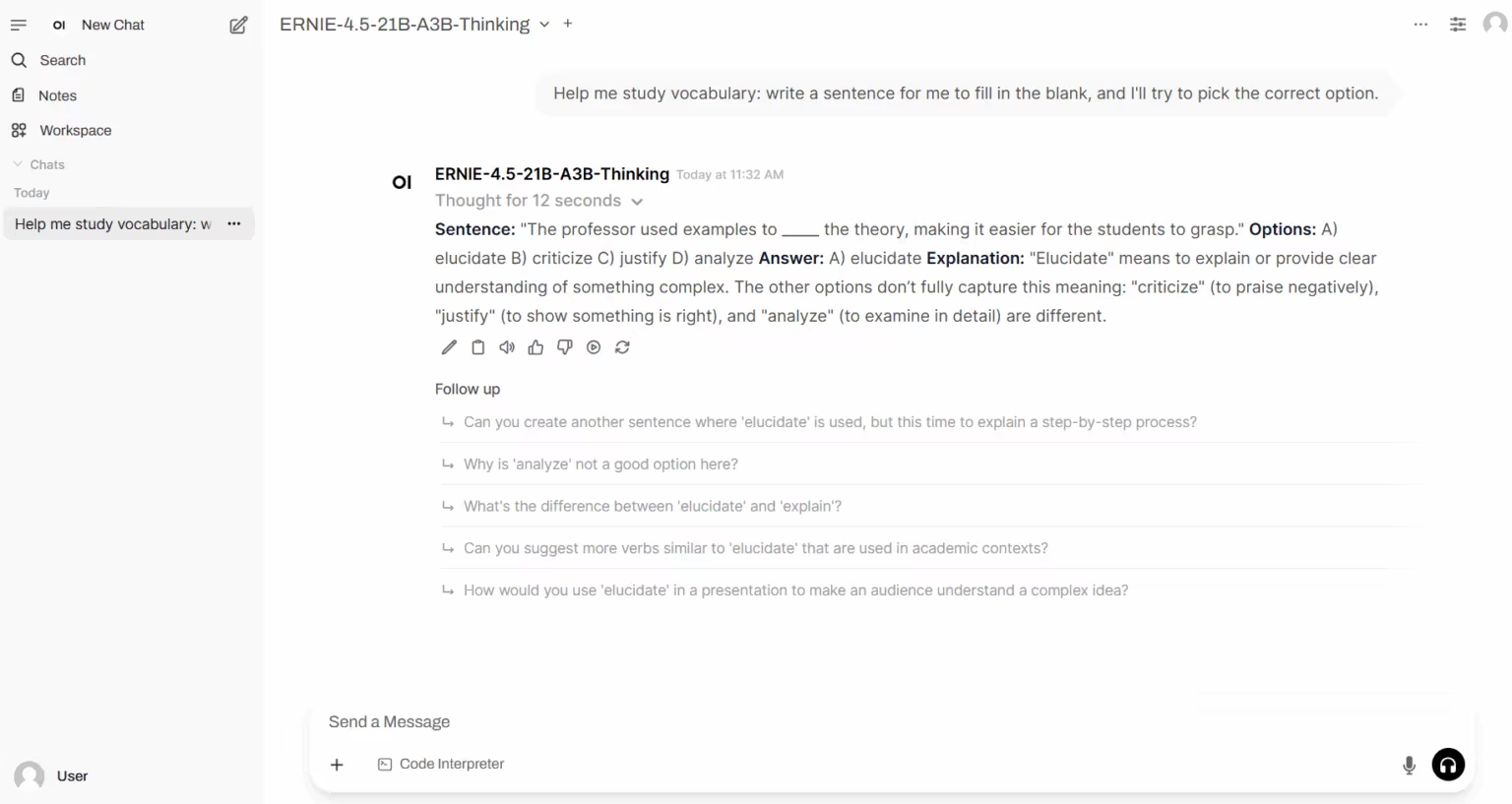
6. ERNIE-4.5-21B-A3B-Thinking : Amélioration des capacités de raisonnement sur modèle léger
ERNIE-4.5-21B-A3B-Thinking est une version allégée et réfléchie du modèle d'inférence publié par l'équipe Baidu Wenxin Yiyan. Ce modèle utilise une architecture mixte d'experts (MoE), possède une taille totale de paramètres de 21 B, et chaque jeton active 3 B paramètres. Son apprentissage repose sur le réglage fin des instructions et l'apprentissage par renforcement.
Exécutez en ligne : https://go.hyper.ai/bQmlo
7. RFdiffusion2 : outil de conception de protéines
RFdiffusion2 est un modèle de conception de protéines basé sur l'apprentissage profond, publié par l'Institute for Protein Design de l'Université de Washington. Ce modèle génère non seulement des structures enzymatiques avec des sites actifs personnalisés à partir de descriptions simples de réactions chimiques, mais surmonte également de manière significative les obstacles techniques rencontrés jusqu'à présent dans la conception de catalyseurs, offrant ainsi un support technique solide pour des applications importantes telles que la dégradation du plastique.
Exécutez en ligne : https://go.hyper.ai/9YInD
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. OmniWorld : un jeu de données multidomaine et multimodal pour la modélisation du monde 4D
Cet article présente OmniWorld, un jeu de données à grande échelle, multidomaine et multimodal conçu pour la modélisation de mondes quadridimensionnels. Ce jeu de données se compose du jeu OmniWorld-Game récemment collecté et de plusieurs jeux de données publics sélectionnés, couvrant divers scénarios d'application.
Lien vers l'article : https://go.hyper.ai/SbW2Y
2. WebWeaver : structurer les preuves à l'échelle du Web avec des schémas dynamiques pour une recherche approfondie et ouverte
Cet article propose un nouveau cadre d'agent double, WebWeaver, conçu pour imiter le processus de recherche humaine. L'agent de planification opère dans une boucle dynamique, entrelaçant de manière itérative l'acquisition de preuves et l'affinement du plan afin de produire un plan complet, structuré et basé sur les sources, relié à une mémoire de preuves. Ensuite, l'agent de rédaction exécute un processus hiérarchique de recherche et de rédaction, complétant la construction du rapport section par section.
Lien vers l'article : https://go.hyper.ai/lqMvM
3. Mise à l'échelle des agents via une pré-formation continue
Cet article propose, pour la première fois, l'intégration du pré-entraînement continu des agents (Agentic CPT) au processus d'apprentissage des agents d'apprentissage profond afin de construire un modèle basé sur les agents robuste. Sur la base de cette approche, les chercheurs ont développé un modèle d'agent d'apprentissage profond appelé AgentFounder.
Lien vers l'article : https://go.hyper.ai/6lyWG
4. WebSailor-V2 : combler le fossé avec les agents propriétaires grâce aux données synthétiques et à l'apprentissage par renforcement évolutif
Cet article propose une méthodologie complète de post-apprentissage, WebSailor, qui génère de nouvelles tâches à forte incertitude grâce à l'échantillonnage structuré et à la fuzzification de l'information. Elle utilise une stratégie de démarrage à froid RFT et la combine avec un algorithme d'apprentissage par renforcement basé sur des agents hautement performant, l'optimisation de la politique d'échantillonnage répété (DUPO). Grâce à ce processus intégré, WebSailor surpasse largement tous les agents open source existants dans les tâches complexes de recherche d'informations, approchant les performances des agents propriétaires et réduisant efficacement l'écart de capacité.
Lien vers l'article : https://go.hyper.ai/biWLb
5. Rapport technique Hala : Élaboration de modèles d'enseignement et de traduction centrés sur l'arabe à grande échelle
Cet article présente Hala, une famille de modèles d'instruction et de traduction centrés sur l'arabe. Basée sur un pipeline propriétaire de réglage fin de la traduction, Hala atteint des performances de pointe dans les catégories « nano » (≤ 2 milliards de paramètres) et « small » (7 à 9 milliards de paramètres) sur les principaux benchmarks arabes, surpassant largement son modèle de référence.
Lien vers l'article : https://go.hyper.ai/KI73S
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Des équipes de recherche de l'Académie chinoise des sciences, de l'Université agricole du Nord-Est, de l'Université de Macao et de l'Université de Jilin ont proposé conjointement un nouveau cadre de classification de jumeaux, scSiameseClu, pour l'interprétation des données d'ARN-seq unicellulaires. Ce cadre permet de pallier efficacement le problème d'effondrement de la représentation, d'obtenir une classification plus précise des populations cellulaires et de fournir un outil puissant pour l'analyse des données d'ARN-seq.
Voir le rapport complet : https://go.hyper.ai/hyDFA
En septembre 2025, l'équipe Tencent Hunyuan a lancé le modèle de traduction léger Hunyuan-MT-7B, capable de traduire 33 langues et cinq dialectes chinois. Avec seulement 7 milliards de paramètres, il assure une traduction efficace et précise. Lors du concours WMT2025 de l'Association for Computational Linguistics (ACL), ce modèle a remporté la première place dans 30 des 31 catégories linguistiques, réalisant des performances impressionnantes.
Voir le rapport complet : https://go.hyper.ai/y2X2L
Ces dernières années, la fréquence et l'intensité des précipitations extrêmes ont considérablement augmenté à Mumbai. Les systèmes de prévision mondiaux traditionnels, faute d'une résolution suffisante, peinent à saisir les conditions météorologiques locales. Pour y remédier, l'Institut indien de technologie (IIT) de Bombay, en collaboration avec l'Université du Maryland, a développé un modèle de prévision basé sur les réseaux de neurones convolutifs et l'apprentissage par transfert, permettant une prévision précoce des épisodes de précipitations extrêmes.
Voir le rapport complet : https://go.hyper.ai/wYsSk
Les résultats de la recherche DeepSeek-R1 ont fait la une de Nature, suscitant de vives discussions au sein de la communauté universitaire mondiale. L'importance de cette publication dans Nature réside dans son évaluation par les pairs de cette prestigieuse revue.
Voir le rapport complet : https://go.hyper.ai/B12hL
Google DeepMind, en collaboration avec des chercheurs de l'Université de New York, de l'Université de Stanford, de l'Université Brown et d'autres institutions, sur la base d'un cadre d'apprentissage automatique et d'un optimiseur Gauss-Newton de haute précision, a découvert systématiquement de nouvelles singularités instables dans trois équations de fluides différentes pour la première fois, et a révélé une formule asymptotique empirique simple qui relie le taux d'explosion à l'ordre d'instabilité.
Voir le rapport complet : https://go.hyper.ai/hq5og
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








