Command Palette
Search for a command to run...
Caractérisation Fine Des Séquences TCR ! Le Framework d'apprentissage Profond DeepTCR Élargit Les Méthodes De Recherche En Immunologie, Étayé Par Les Données De 50 000 Patients Atteints De Cancer Du Poumon ! Risque De Cancer Du Poumon : Détaille Les Facteurs De risque.

Le séquençage des récepteurs des lymphocytes T (TCR-Seq) est une application importante de la technologie de séquençage de nouvelle génération (NGS), permettant aux chercheurs de caractériser systématiquement la diversité des réponses immunitaires adaptatives. Lors de l'analyse des données de séquençage des récepteurs des lymphocytes T, les méthodes traditionnelles (telles que la recherche de motifs ou l'alignement de séquences) ont donné de bons résultats, mais ont aussi progressivement révélé leurs limites.Lors de l'identification des réponses des lymphocytes T spécifiques à un antigène à basse fréquence dans le corps, leurs signaux sont souvent submergés par un grand nombre de signaux de lymphocytes T non spécifiques.Cela reflète les défis auxquels sont confrontées les méthodes traditionnelles pour identifier les signaux du bruit.
Alors que la demande de caractérisation plus précise des séquences TCR continue de croître, les chercheurs se sont tournés vers les technologies d’apprentissage en profondeur représentées par les réseaux de neurones convolutifs (CNN).DeepTCR est apparu comme un cadre d’analyse de séquençage des récepteurs immunitaires basé sur l’apprentissage en profondeur.Le cadre peut apprendre les séquences CDR3, l'utilisation des gènes V/D/J et les caractéristiques du type de molécule MHC à partir des données du répertoire immunitaire de séquençage TCR et construire une représentation conjointe pour modéliser des données de séquençage TCR hautement complexes.
DeepTCR applique systématiquement le cadre d'apprentissage en profondeur à l'analyse de séquence TCR, ce qui non seulement élargit les méthodes d'analyse de la recherche immunologique, mais démontre également davantage la large application de la technologie d'apprentissage en profondeur dans différents domaines.
Le site officiel d'HyperAI a lancé « DeepTCR : Prédire l'affinité TCR-peptide grâce au deep learning ». Venez l'essayer !
Utilisation en ligne:https://go.hyper.ai/gKmgi
Du 8 au 12 septembre, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels sélectionnés de haute qualité : 2
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en septembre : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Nouvelles maladies des plantes Ensemble de données d'images sur les maladies des plantes
New Plant Diseases est un jeu de données d'images destiné à l'identification des maladies des plantes et à la recherche sur la classification foliaire. Il couvre les feuilles saines et divers types de maladies. Il est parfaitement adapté au développement et à l'évaluation de modèles d'apprentissage automatique et d'apprentissage profond, notamment pour la surveillance de la santé des cultures, l'identification des maladies, les modèles d'agriculture de précision et la recherche universitaire. Il constitue une référence importante.
Utilisation directe : https://go.hyper.ai/RKYtW

2. Ensemble de données de classification d'images de scènes naturelles Intel Image Classification
Intel Image Classification est un ensemble de données de classification d'images publié par Intel. Il vise à classer les images de scènes naturelles et artificielles. Cet ensemble de données contient environ 25 000 images couleur réparties en six catégories, dont les bâtiments et les forêts.
Utilisation directe : https://go.hyper.ai/qgbeX

3. Ensemble de données de raisonnement romanesque LongPage
LongPage est le premier ensemble de données complet permettant d'entraîner des modèles d'intelligence artificielle à écrire des romans complets dotés de capacités de raisonnement complexes. Il prend en charge le réglage fin supervisé à froid des processus d'apprentissage par renforcement et convient à l'entraînement de modèles linguistiques à grande échelle dotés de capacités de raisonnement hiérarchique, ainsi qu'à l'amélioration de la cohérence et de la planification des écrits longs.
Utilisation directe : https://go.hyper.ai/odoKA
4. Ensemble de données sur le risque de cancer du poumon
Lung Cancer Risk est un ensemble de données tabulaires destiné à la prédiction du risque de cancer du poumon et à l'analyse des facteurs de santé. Il vise à explorer l'association entre tabagisme, mode de vie et risque de cancer du poumon à travers des caractéristiques multidimensionnelles. Il est adapté à la modélisation du risque de cancer du poumon, à la recherche en apprentissage automatique médical, au développement de systèmes de prédiction de santé et aux expériences pédagogiques. Il est particulièrement utile pour la modélisation de la classification et les scénarios d'évaluation des risques.
Utilisation directe:https://go.hyper.ai/YGFzG
5. Ensemble de données d'évaluation d'instructions inversées IFEval-Inverse
IFEval-Inverse est un jeu de données d'évaluation d'instructions contradictoires pour les grands modèles linguistiques, publié par ByteDance Seed en collaboration avec l'Université de Nanjing, l'Université Tsinghua et d'autres institutions. Il vise à tester la capacité du modèle à briser l'inertie d'apprentissage et à assurer une véritable conformité aux instructions face à des instructions inversées ou anormales.
Utilisation directe : https://go.hyper.ai/IcTqj
6. Ensemble de données graphiques de connaissances financières FinReflectKG
FinReflectKG est un jeu de données de graphes de connaissances à grande échelle destiné au secteur financier. Il vise à extraire des relations sémantiques structurées à partir de documents réglementaires d'entreprise et à promouvoir le développement de la recherche sur les graphes de connaissances dans le domaine financier. Il est adapté à la reconnaissance d'entités, à l'extraction de relations, à la construction de graphes de connaissances, à l'analyse de séries chronologiques, à l'évaluation de l'extraction d'informations à grande échelle basée sur des modèles de langage et au développement d'applications financières intelligentes en aval dans le secteur financier.
Utilisation directe : https://go.hyper.ai/EB5em
7. Ensemble de données du corpus cantonais WenetSpeech Yue
WenetSpeech Yue est un vaste corpus vocal annoté multidimensionnellement pour la reconnaissance vocale cantonaise (RAP) et la synthèse vocale (TTS). Il vise à combler le manque de ressources dans le domaine cantonais et à promouvoir la formation et l'évaluation de modèles cantonais de haute qualité.
Accès direct : https://go.hyper.ai/cICOv
8. Ensemble de données de réglage d'instructions continues UCIT
UCIT est un ensemble de données de référence pour le réglage continu des instructions de grands modèles de langage multimodaux. Chaque échantillon de cet ensemble de données comprend une description de tâche (invite/instruction) et l'attente d'exécution correcte correspondante (réponse terrain), qui permet de mesurer les performances du modèle en conditions de zéro-shot.
Utilisation directe : https://go.hyper.ai/TZPwY
9. Ensemble de données de référence de raisonnement multidomaine LoongBench
LoongBench est un ensemble de données d'évaluation du raisonnement multi-domaines conçu pour fournir aux étudiants de LLM une ressource de formation et d'évaluation multi-domaines et vérifiable. Cet ensemble de données contient 8 729 questions en langage naturel, couvrant 12 domaines exigeant un raisonnement intensif, dont les mathématiques et la physique avancées.
Utilisation directe : https://go.hyper.ai/AcFOZ
10. Ensemble de données d'alignement des préférences humaines CA‑1
CA-1 se concentre sur les jugements de valeur et les préférences des humains concernant les comportements par défaut des modèles d'IA. Il s'agit d'un ensemble de données comportementales de rétroaction humaine combinant contenu généré par le modèle et évaluations d'annotateurs. Il est adapté à l'étude des différences d'alignement des groupes, à l'orientation des normes comportementales des modèles et au développement de mécanismes de récompense sensibles aux valeurs.
Utilisation directe : https://go.hyper.ai/mXznO
Tutoriels publics sélectionnés
1. Wan2.2-S2V-14B : Génération vidéo audio de qualité cinématographique
Wan2.2-S2V-14B est un modèle open source de génération vidéo piloté par l'audio, développé par l'équipe Alibaba Tongyi Wanxiang. À partir d'une seule image fixe et d'un son, il permet de générer des vidéos numériques de qualité cinématographique, d'une durée maximale de quelques minutes, prenant en charge divers types et tailles d'images. Le modèle intègre plusieurs technologies innovantes pour permettre la génération vidéo pilotée par l'audio pour des scènes complexes, prenant en charge la génération de vidéos longues et l'apprentissage et l'inférence multirésolution.
Exécutez en ligne : https://go.hyper.ai/TlSai
2. DeepTCR : apprentissage profond pour prédire l'affinité TCR-peptide
DeepTCR est un outil d'analyse de séquençage de récepteurs immunitaires basé sur l'apprentissage profond. Il permet de prédire l'affinité à partir des données du répertoire immunitaire de séquençage des TCR, d'extraire et d'apprendre les séquences CDR3 des TCR, l'utilisation des gènes V/D/J ou les caractéristiques des types de molécules du CMH, et de représenter conjointement les TCR pour modéliser des données de séquençage de TCR très complexes. Il permet d'extraire des TCR spécifiques d'antigènes à partir de l'ARN-Seq unicellulaire avec bruit de fond et de tests basés sur la culture de lymphocytes T.
Exécutez en ligne : https://go.hyper.ai/gKmgi
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. Partager, c'est prendre soin : LM post-formation efficace avec partage d'expériences RL collectives
Cet article propose SAPO (Swarm Sampling Policy Optimization), un algorithme d'apprentissage par renforcement post-apprentissage entièrement décentralisé et asynchrone. SAPO est conçu pour les réseaux décentralisés de nœuds de calcul hétérogènes. Chaque nœud gère de manière autonome son propre modèle de politique tout en « partageant » sa trajectoire avec les autres nœuds. L'algorithme ne repose pas sur des hypothèses explicites concernant la latence, l'homogénéité du modèle ou la configuration matérielle, et les nœuds peuvent fonctionner indépendamment à la demande.
Lien vers l'article : https://go.hyper.ai/MWeWF
2. Pourquoi les modèles de langage hallucinent
Cet article propose que la raison fondamentale pour laquelle les modèles de langage connaissent des hallucinations réside dans le fait que leurs mécanismes d'entraînement et d'évaluation tendent à privilégier les suppositions plutôt que de reconnaître l'incertitude. Il analyse plus en détail les racines statistiques des hallucinations dans les processus d'entraînement modernes. La pénalité systématique imposée par les grands modèles aux réponses incertaines suggère que les méthodes de notation actuelles, courantes mais biaisées, devraient être révisées, plutôt que d'introduire des mesures supplémentaires pour évaluer les hallucinations.
Lien vers l'article : https://go.hyper.ai/eXoOR
3. Raisonnement par rétro-ingénierie pour une génération ouverte
Cet article propose un nouveau paradigme, le raisonnement par ingénierie inverse (REER), qui transforme fondamentalement la façon dont le raisonnement est construit. Contrairement aux méthodes traditionnelles qui construisent les processus de raisonnement de bas en haut, par essais et erreurs ou par imitation, le REER adopte une stratégie « inverse ». À partir de solutions connues de haute qualité, il découvre par calcul, étape par étape, les voies de raisonnement profondes potentielles permettant de générer ces solutions.
Lien vers l'article : https://go.hyper.ai/xFygJ
4. Parallel-R1 : Vers une pensée parallèle via l'apprentissage par renforcement
Cet article présente Parallel-R1, le premier cadre d'apprentissage par renforcement (RL) pour les tâches complexes de raisonnement réel, qui favorise les comportements de pensée parallèle. Ce cadre utilise un programme d'études progressif pour répondre explicitement au problème de démarrage à froid de l'apprentissage de la pensée parallèle dans l'apprentissage par renforcement.
Lien vers l'article : https://go.hyper.ai/s2OlH
5. WebExplorer : explorer et évoluer pour former des agents Web à long terme
S'appuyant sur un ensemble de données de haute qualité et soigneusement construit, cet article a permis d'entraîner avec succès un modèle proxy web de pointe, WebExplorer-8B, grâce à un réglage fin supervisé combiné à un apprentissage par renforcement. Ce modèle prend en charge des longueurs de contexte allant jusqu'à 128 Ko et peut exécuter jusqu'à 100 appels d'outils, permettant ainsi de résoudre des problèmes à long terme. Lors de plusieurs tests de recherche d'informations, WebExplorer-8B a atteint des performances de pointe parmi des modèles de taille similaire.
Lien vers l'article : https://go.hyper.ai/NusbG
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Des chercheurs de l'Université chinoise de Hong Kong, de l'Université Mohamed bin Zayed d'intelligence artificielle et d'autres institutions ont proposé un modèle de diffusion évolutif guidé par le transcriptome, MorphDiff, spécialement conçu pour simuler avec une grande fidélité la réponse de la morphologie cellulaire aux perturbations. Ce modèle, basé sur l'architecture du modèle de diffusion latente (LDM), utilise les profils d'expression génétique L1000 comme données d'entrée conditionnelles pour l'apprentissage du débruitage.
Voir le rapport complet : https://go.hyper.ai/f7WeP
Une équipe de recherche conjointe de l'Université chinoise du pétrole et de l'Université Yonsei a intégré plusieurs technologies avancées pour développer un nouveau cadre, baptisé AlphaPPIMI. Combinant un modèle pré-entraîné à grande échelle et un mécanisme d'apprentissage adaptatif, cet outil vise à relever le défi principal de la découverte de modulateurs ciblant spécifiquement l'interface IPP, apportant ainsi un soutien solide au développement futur de médicaments ciblant les IPP.
Voir le rapport complet : https://go.hyper.ai/4tp0M
Le 10 septembre à 1h00, heure de Pékin, la conférence d'automne 2025 d'Apple était entièrement consacrée à l'IA, annonçant des mises à niveau pour trois produits phares : l'iPhone 17, l'Apple Watch Series 11 et les AirPods Pro 3. L'intelligence artificielle d'Apple est passée d'une présentation conceptuelle l'année dernière à une mise en œuvre à grande échelle, couvrant des scénarios tels que la traduction en temps réel, la surveillance de la santé et l'intelligence visuelle. Les puces A19 et M19 Pro de nouvelle génération constituent la pierre angulaire de sa puissance de calcul.
Voir le rapport complet : https://go.hyper.ai/IimjS
Des équipes de recherche de l'Université de Wuhan et de l'Université technologique de Nanyang ont conjointement développé un agent de santé composé de trois éléments : le dialogue, la mémoire et le traitement. Cet agent est capable d'identifier les besoins médicaux des patients et de détecter automatiquement les problèmes d'éthique et de sécurité médicale.
Voir le rapport complet : https://go.hyper.ai/AdG2j
Début septembre, Apple aurait manifesté son intérêt pour l'acquisition de la startup française Mistral AI. Le géant des semi-conducteurs ASML a suivi le mouvement, menant son tour de table de série C avec 1,3 milliard d'euros. La valorisation de l'entreprise a désormais atteint 14 milliards de dollars, ce qui en fait un acteur majeur du secteur européen de l'IA.
Voir le rapport complet : https://go.hyper.ai/zsQBu
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
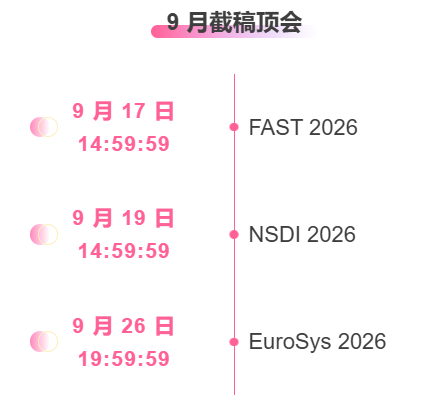
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








