Command Palette
Search for a command to run...
Une Nouvelle Plateforme d'analyse Documentaire De Pointe ! La Nouvelle Version De MinerU Innove Avec Une Stratégie d'analyse En Deux Étapes, Du Plus Grossier Au Plus fin. Lancement Du Benchmarking De Domaine S2S ! Le Dernier Jeu De Données De Benchmarking De Tencent Évalue Les Capacités Des Modèles vocaux.

Dans la vague de numérisation, tous les domaines de la vie ont accumulé des quantités massives de données documentaires non structurées, en particulier des documents universitaires, des rapports, des formulaires, etc., principalement au format PDF.La conversion efficace et précise de ces documents en données structurées lisibles par machine est une condition préalable importante pour parvenir à une extraction automatisée des informations, à une gestion des documents et à une analyse intelligente, et constitue également une étape clé pour libérer la valeur des données.
Sur la base de la demande croissante en matière d'OCR,OpenDataLab et Shanghai AI Lab ont lancé conjointement le modèle de langage visuel MinerU2.5-2509-1.2B.Il se concentre sur la conversion de documents au format complexe tels que PDF en données structurées lisibles par machine (telles que Markdown, JSON, etc.) et est conçu pour les tâches d'analyse de documents de haute précision et de haute efficacité.La nouvelle version du modèle permet une analyse efficace grâce à une stratégie en deux étapes « du grossier au fin » :La première étape utilise une analyse de mise en page efficace pour identifier les éléments structurels et définir le cadre du document ; la deuxième étape effectue une reconnaissance fine dans la zone recadrée à la résolution d'origine pour garantir que les détails tels que le texte, les formules et les tableaux sont restaurés.
MinerU2.5-2509-1.2B dissocie l'analyse de la mise en page globale de la reconnaissance du contenu local, démontrant ainsi de puissantes capacités d'analyse de documents.Il surpasse les modèles de champ généraux et verticaux dans de multiples tâches de reconnaissance.Parallèlement, il présente des avantages significatifs en termes de temps de calcul. Il s'agit non seulement d'un modèle techniquement supérieur, mais aussi d'un outil améliorant efficacement l'efficacité technique, offrant un support solide pour les besoins des utilisateurs en aval, tels que l'analyse de données, la recherche d'informations et la construction de corpus.
Le site officiel d'HyperAI a publié « MinerU2.5-2509-1.2B : Démo d'analyse de documents ». Venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/emEKs
Du 13 au 17 octobre, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 11
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Conférence de premier plan avec date limite en octobre : 1
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence pour l'analyse de données hétérogènes FDAbench-Full
FDAbench-Full est le premier benchmark de tâches d'analyse de données hétérogènes pour les agents de données, publié par l'Université technologique de Nanyang, l'Université nationale de Singapour et Huawei Technologies Co., Ltd. Il vise à évaluer les capacités du modèle en matière de génération de requêtes de base de données, de compréhension SQL et d'analyse de données financières.
Utilisation directe :https://go.hyper.ai/AUjv5
2. Ensemble de données d'évaluation multimodale médicale PubMedVision
PubMedVision est un ensemble de données permettant d'évaluer les capacités multimodales médicales, couvrant diverses modalités d'imagerie médicale et régions anatomiques. Il vise à fournir des ressources de test standardisées pour les modèles multimodaux de langage à grande échelle (MLLM) utilisés dans les tâches de compréhension de texte et de vision médicale, afin de tester leurs performances en matière de fusion des connaissances visuelles et de raisonnement dans le domaine médical.
Utilisation directe :https://go.hyper.ai/qdvVe
3. Ensemble de données d'évaluation de la génération conjointe audiovisuelle Verse-Bench
Verse-Bench est un jeu de données de référence pour l'évaluation de la génération conjointe d'audio et de vidéo, publié par StepFun en collaboration avec l'Université des sciences et technologies de Hong Kong, l'Université des sciences et technologies de Hong Kong (Guangzhou) et d'autres institutions. Il vise à permettre aux modèles génératifs non seulement de générer des vidéos, mais aussi de maintenir un alignement temporel strict avec le contenu audio (y compris le son ambiant et la parole).
Utilisation directe :https://go.hyper.ai/mvau0

4. Ensemble de données de référence pour la génération de vidéos éducatives MMMC
MMMC est un ensemble de données de référence pour la génération de vidéos pédagogiques multidisciplinaires à grande échelle, publié par le Show Lab de l'Université nationale de Singapour. Il vise à fournir des ressources de formation et d'évaluation de haute qualité pour les modèles d'intelligence artificielle pédagogique et à soutenir la recherche sur la génération automatique de vidéos pédagogiques professionnelles à partir de code structuré et de contenu pédagogique.
Utilisation directe :https://go.hyper.ai/AELav
5. Ensemble de données de référence pour la génération d'images multimodales T2I-CoReBench
T2I-CoReBench est un benchmark d'évaluation complet pour les modèles de génération d'images textuelles, proposé par l'Université des sciences et technologies de Chine, l'équipe Kling de Kuaishou Technology et l'Université de Hong Kong. Il vise à mesurer simultanément les capacités de combinaison et de raisonnement des modèles de génération d'images.
Utilisation directe :https://go.hyper.ai/SLyED
6. Ensemble de données de référence WildSpeech-Bench pour la compréhension et la génération de la parole
WildSpeech-Bench est le premier benchmark publié par Tencent pour évaluer les capacités de synthèse vocale de SpeechLLM. Il vise à mesurer la capacité du modèle à comprendre et à générer une synthèse vocale complète (S2S) dans des scénarios d'interaction vocale réels.
Utilisation directe :https://go.hyper.ai/Cy63e
7. Ensemble de données de remappage des mouvements globaux des robots OmniRetarget
OmniRetarget est un jeu de données de trajectoires de haute qualité pour la reconfiguration des mouvements du corps entier des robots humanoïdes, publié par Amazon en collaboration avec le MIT, l'Université de Californie à Berkeley et d'autres institutions. Il contient les trajectoires de mouvement du robot humanoïde G1 lors de ses interactions avec des objets et des terrains complexes, couvrant trois scénarios : transport d'objets, déplacement sur terrain et interaction mixte objet-terrain.
Utilisation directe :https://go.hyper.ai/xfZY4

8. Données de référence sur les vidéos papier Paper2Video
Paper2Video est le premier ensemble de données de référence de paires article-vidéo publié par l'Université nationale de Singapour. Il vise à fournir une référence et une ressource d'évaluation standard pour la génération automatique de vidéos de présentation (diapositives, sous-titres, audio et portraits d'intervenants) à partir d'articles universitaires.
Utilisation directe :https://go.hyper.ai/NeRuV
9. Ensemble de données d'évaluation multimodale FoMER Bench
FoMER Bench est un benchmark de raisonnement incarné de modèle fondamental (FoMER) couvrant trois types de robots différents et plusieurs modes de robot, conçu pour évaluer la capacité de raisonnement des LMM dans des scénarios complexes de prise de décision incarnée.
Utilisation directe :https://go.hyper.ai/Tiy5w
10. Ensemble de données de référence pour la reconnaissance de texte OCRBench-v2
OCRBench-v2 est un benchmark de reconnaissance optique de caractères (OCR) multimodal à grande échelle publié par l'Université des sciences et technologies de Huazhong, en collaboration avec l'Université de technologie de Chine du Sud, ByteDance et d'autres institutions. Il vise à évaluer les capacités OCR des grands modèles multimodaux (LMM) dans différentes tâches textuelles.
Utilisation directe :https://go.hyper.ai/hhGFR
Tutoriels publics sélectionnés
Cette semaine, nous avons résumé 4 catégories de tutoriels publics de haute qualité :
* Tutoriels OCR : 2
* Tutoriels AI4S : 2
* Tutoriel grand modèle : 1
* Tutoriels multimodaux : 6
Tutoriel OCR
1. MinerU2.5-2509-1.2B : Démonstration d'analyse de documents
MinerU 2.5-2509-1.2B est un modèle de langage visuel développé par OpenDataLab et Shanghai AI Lab, spécialement conçu pour une analyse documentaire haute précision et efficace. Il s'agit de la dernière version de la série MinerU, dédiée à la conversion de formats de documents complexes comme le PDF en données structurées et lisibles par machine (par exemple, Markdown et JSON).
Exécutez en ligne :https://go.hyper.ai/emEKs
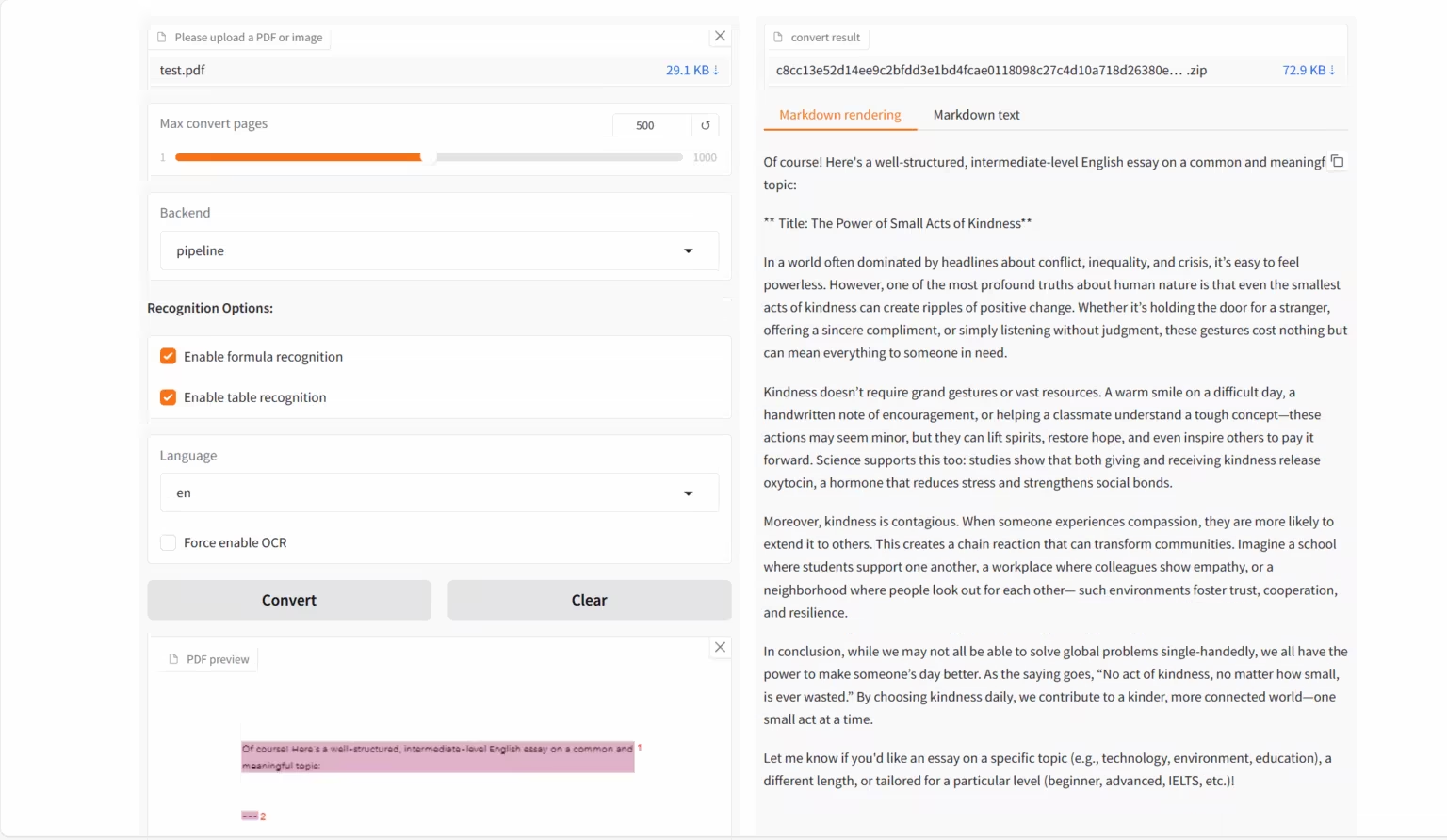
2. Analyse d'images de documents multimodaux Dolphin
Dolphin est un modèle d'analyse de documents multimodal développé par l'équipe ByteDance. Ce modèle utilise une approche en deux étapes : l'analyse de la structure, puis l'analyse du contenu. La première étape génère une séquence d'éléments de mise en page du document, et la seconde utilise ces éléments comme points d'ancrage pour analyser le contenu en parallèle. Dolphin a démontré des performances exceptionnelles dans diverses tâches d'analyse de documents, surpassant des modèles tels que GPT-4.1 et Mistral-OCR.
Exécutez en ligne : https://go.hyper.ai/lLT6X

Tutoriel AI4S
1. BindCraft : conception de liants protéiques
BindCraft, un pipeline open source de conception de liants protéiques en un clic développé par Martin Pacesa, affiche un taux de réussite expérimental de 10–100%. Il utilise directement les poids pré-entraînés d'AlphaFold2 pour générer in silico des liants de novo d'affinité nanomolaire, éliminant ainsi le recours au criblage à haut débit, aux itérations expérimentales, ni même à des sites de liaison connus.
Exécutez en ligne :https://go.hyper.ai/eSoHk
2. Ml-simplefold : un modèle d'IA léger de prédiction du repliement des protéines
Ml-simplefold est un modèle d'IA léger pour la prédiction du repliement des protéines, lancé par Apple. Basé sur la technologie de correspondance de flux, ce modèle contourne des modules complexes comme l'alignement de séquences multiples (MSA) et génère directement la structure tridimensionnelle des protéines à partir du bruit aléatoire, réduisant ainsi considérablement les coûts de calcul.
Exécutez en ligne : https://go.hyper.ai/Y0Us9
Tutoriel sur les grands modèles
1. SpikingBrain-1.0 : un modèle de pointes à grande échelle, semblable à celui du cerveau, basé sur la complexité intrinsèque
SpikingBrain-1.0 est un vaste modèle de stimulation cérébrale pilotable, développé localement et développé par l'Institut d'automatisation de l'Académie chinoise des sciences, en collaboration avec le Laboratoire national de cognition cérébrale et d'intelligence cérébrale, Muxi Integrated Circuit Co., Ltd., et d'autres institutions. Inspiré des mécanismes cérébraux, ce modèle intègre un mécanisme d'attention hybride à haute efficacité, un module MoE et un codage de stimulation dans son architecture, soutenu par un pipeline de conversion universel compatible avec l'écosystème de modèles open source.
Exécutez en ligne :https://go.hyper.ai/i3zHC
Tutoriel multimodal
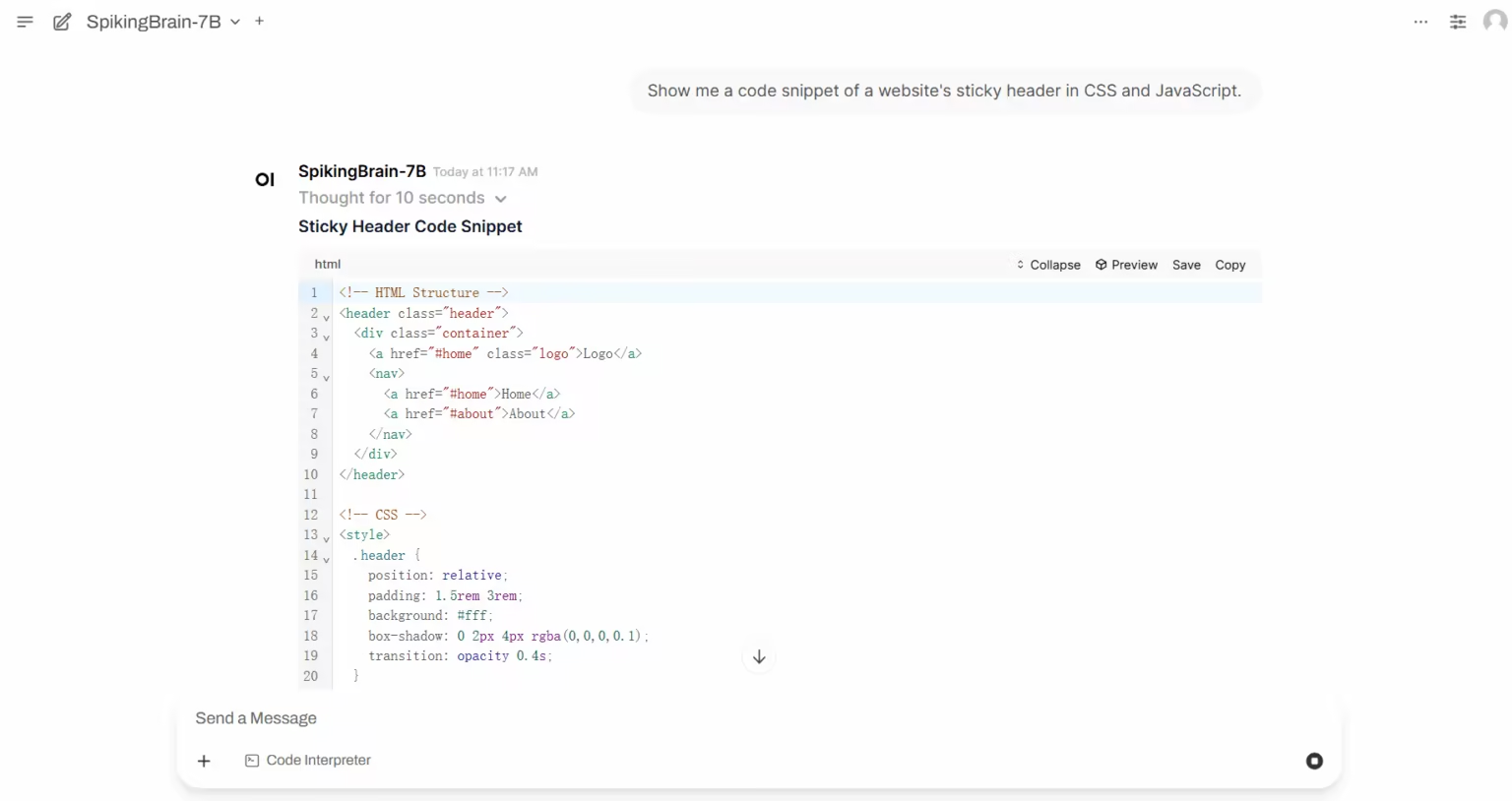
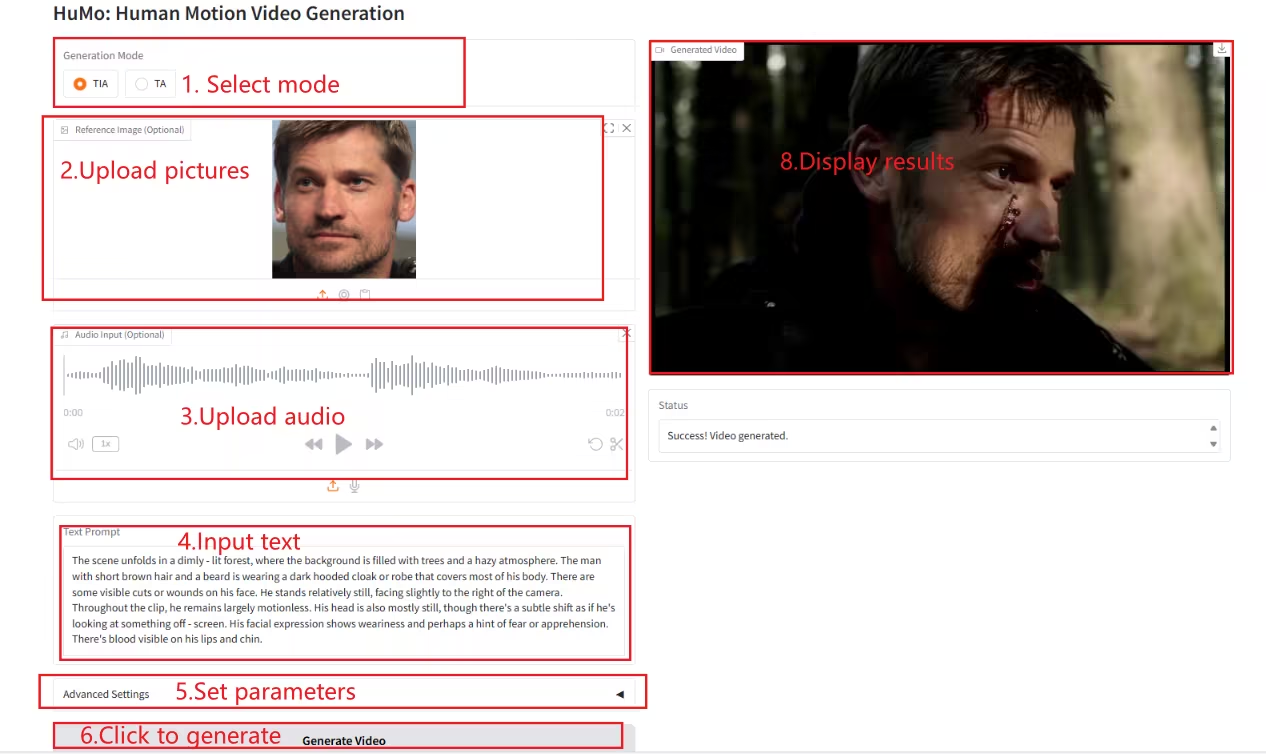
1. HuMo-1.7B : Cadre de génération vidéo multimodale
HuMo est un framework de génération vidéo multimodal développé par l'Université Tsinghua et le laboratoire de création intelligente de ByteDance. Il se concentre sur la génération vidéo centrée sur l'humain et permet de générer des vidéos réalistes de haute qualité, détaillées et contrôlables à partir de plusieurs entrées modales, dont du texte, des images et de l'audio.
Exécutez en ligne :https://go.hyper.ai/Xe4dM
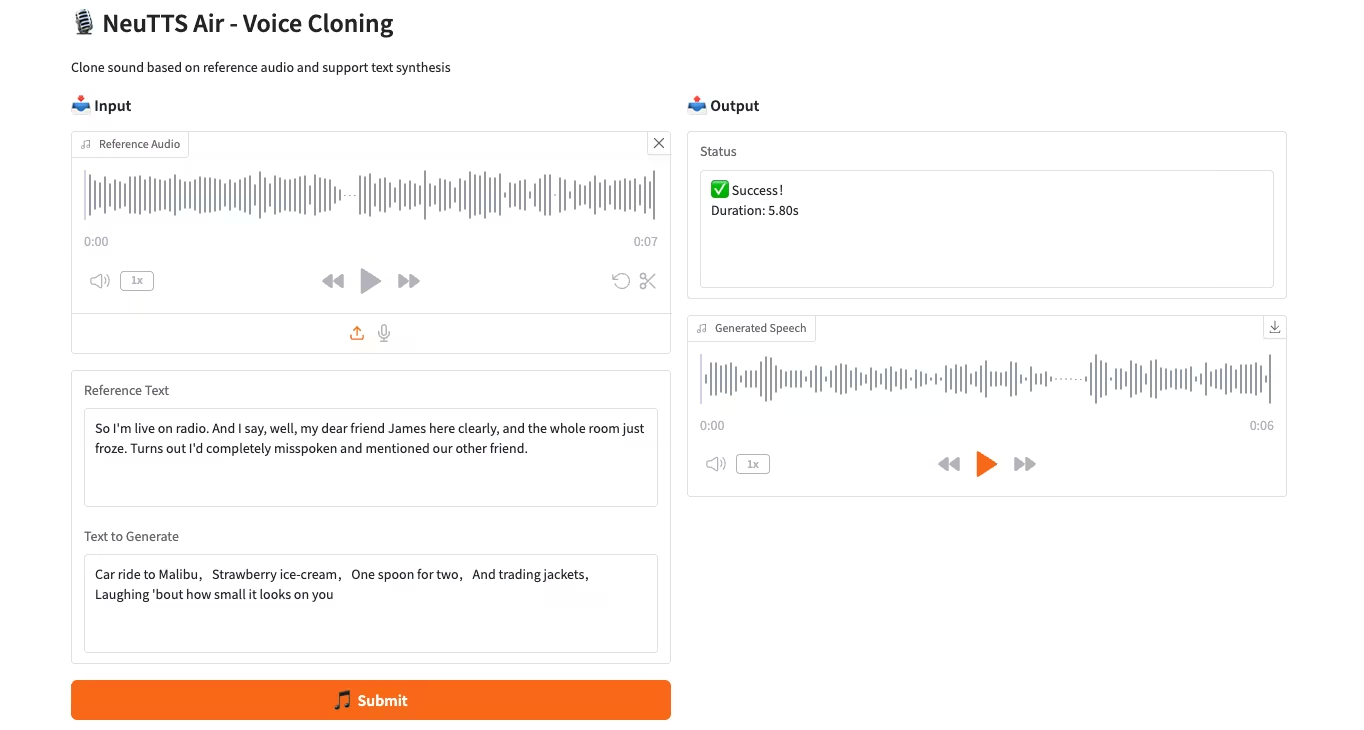
2. NeuTTS-Air : un modèle de clonage vocal léger et efficace
NeuTTS-Air est un modèle de synthèse vocale (TTS) de bout en bout publié par Neuphonic. Basé sur le backbone Qwen LLM de 0,5 milliard de dollars et le codec audio NeuCodec, il démontre des capacités d'apprentissage en quelques secondes pour le déploiement sur appareil et le clonage vocal instantané. Les évaluations système montrent que NeuTTS Air atteint des performances de pointe parmi les modèles open source, notamment en synthèse hyperréaliste et lors des benchmarks d'inférence en temps réel.
Exécutez en ligne :https://go.hyper.ai/7ONYq
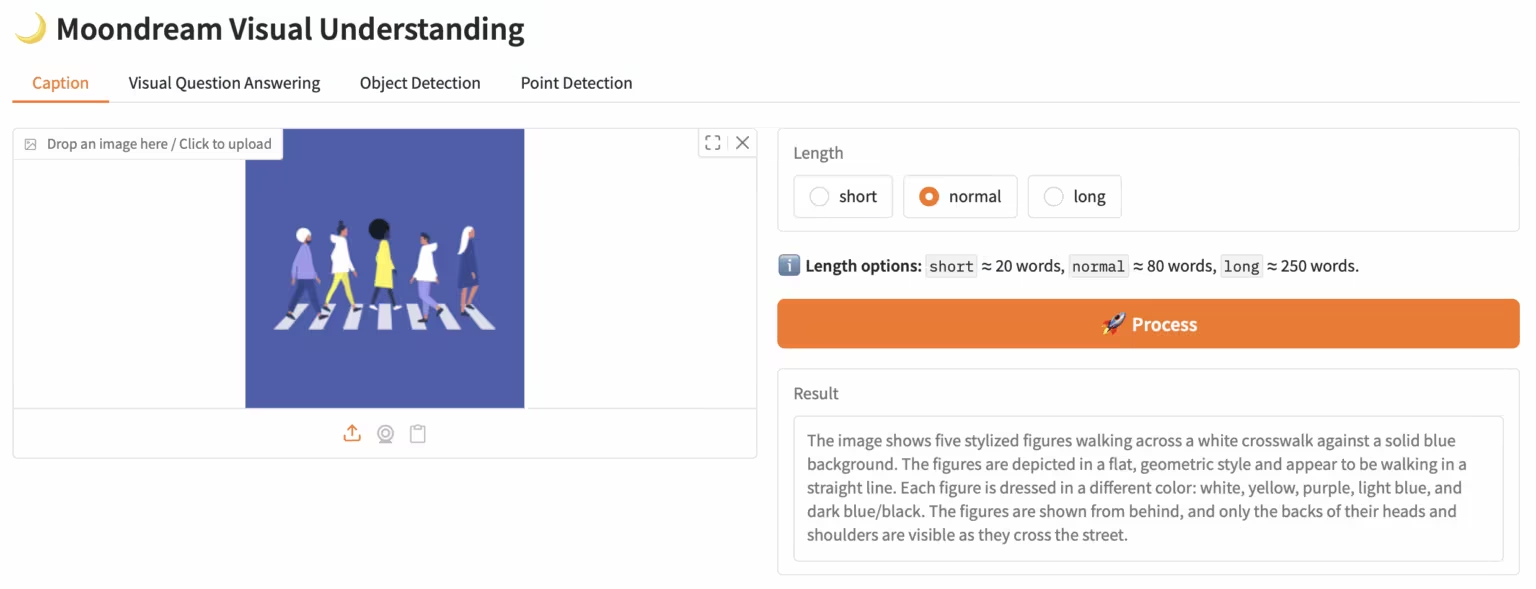
3. Moondream3-preview : Modèle modulaire de compréhension du langage visuel
Moondream3, un modèle de langage visuel basé sur une architecture experte hybride proposée par l'équipe Moondream, dispose de 9 milliards de paramètres (dont 2 milliards de paramètres d'activation). Ce modèle offre des capacités de raisonnement visuel de pointe, supporte une longueur de contexte maximale de 32 Ko et peut traiter efficacement des images haute résolution.
Exécutez en ligne :https://go.hyper.ai/eKGcP
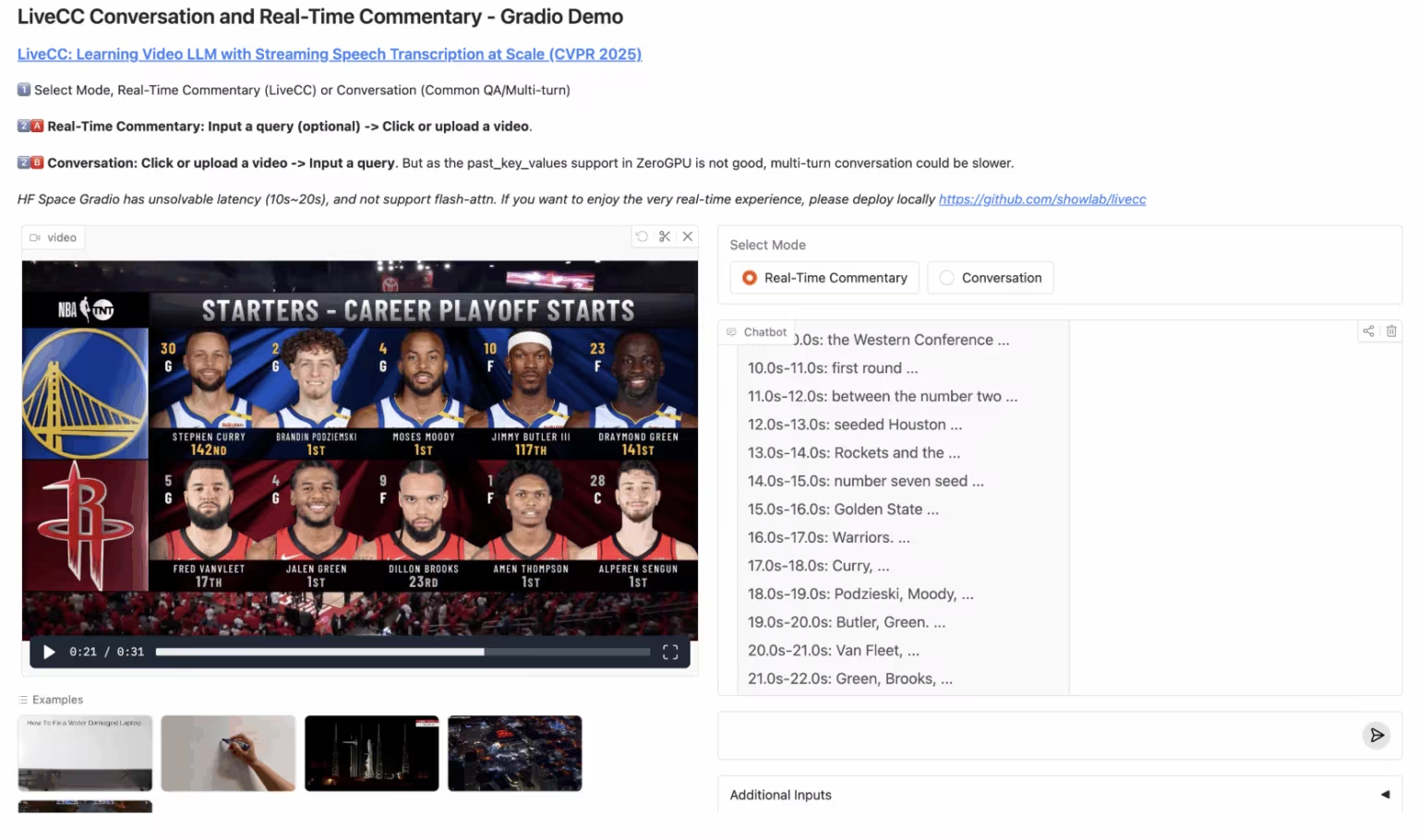
4. LiveCC : Commentaire vidéo en temps réel grand modèle
LiveCC est un projet de modèle de langage vidéo axé sur la transcription vocale en streaming à grande échelle. Ce projet vise à former le premier modèle de langage vidéo doté de fonctionnalités de commentaire en temps réel grâce à une méthode innovante de streaming vidéo par reconnaissance vocale automatique (RAP). Il a atteint les performances de pointe actuelles en matière de tests de performance, tant en streaming qu'hors ligne.
Exécutez en ligne :https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part : Modèle génératif 3D basé sur des composants
Hunyuan3D-Part, un modèle génératif 3D développé par l'équipe Tencent Hunyuan, est composé de P3-SAM et de X-Part. Pionnier de la génération de modèles 3D haute précision, contrôlables et basés sur des composants, il permet la génération automatique de plus de 50 composants. Ses applications sont nombreuses dans des domaines tels que la modélisation de jeux vidéo et l'impression 3D, comme la séparation d'un modèle de voiture en carrosserie et roues pour faciliter le défilement du jeu ou l'impression 3D étape par étape.
Exécutez en ligne :https://go.hyper.ai/1w1Jq

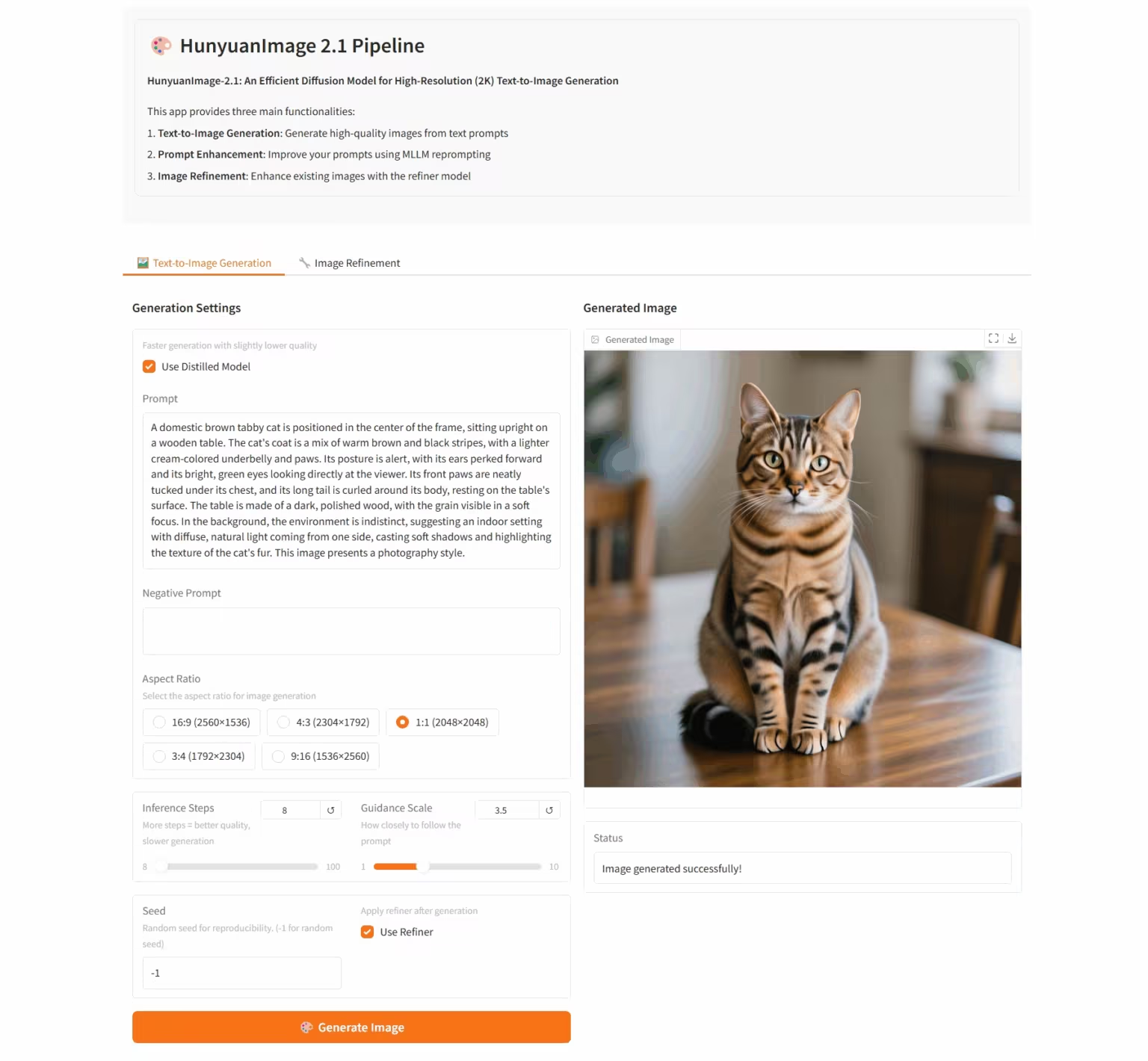
6. HunyuanImage-2.1 : Modèle de diffusion pour images Wensheng haute résolution (2K)
HunyuanImage-2.1 est un modèle d'image textuel open source développé par l'équipe Tencent Hunyuan. Il prend en charge la résolution native 2K et possède de puissantes capacités de compréhension sémantique complexe, permettant une génération précise des détails de la scène, des expressions des personnages et des actions. Ce modèle prend en charge la saisie en chinois et en anglais et peut générer des images dans divers styles, tels que des bandes dessinées et des figurines, tout en conservant un contrôle rigoureux du texte et des détails des images.
Exécutez en ligne :https://go.hyper.ai/i96yp
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. QeRL : Au-delà de l'efficacité — Apprentissage par renforcement amélioré par quantification pour les LLM
Cet article propose QeRL, un framework d'apprentissage par renforcement optimisé par quantification pour les grands modèles de langage. En combinant la quantification NVFP4 avec l'adaptation de bas rang (LoRA), ce modèle accélère la phase d'échantillonnage RL tout en réduisant significativement la charge mémoire. QeRL est le premier framework capable d'entraîner de grands modèles d'apprentissage par renforcement avec 32 milliards de paramètres (32 000) sur un seul GPU H100 de 80 Go, tout en améliorant la vitesse d'apprentissage globale.
Lien vers l'article : https://go.hyper.ai/catLh
2. Transformateurs de diffusion avec autoencodeurs de représentation
Cet article explore le remplacement des VAE par des encodeurs de représentation pré-entraînés (tels que DINO, SigLIP et MAE), combinés à des décodeurs pré-entraînés, afin de construire une nouvelle architecture appelée auto-encodeurs de représentation (RAE). Ces modèles permettent non seulement une reconstruction de haute qualité, mais possèdent également un espace latent sémantiquement riche et prennent en charge une conception d'architecture évolutive basée sur Transformer.
Lien vers l'article : https://go.hyper.ai/fqVs4
3. D2E : Mise à l'échelle de la préformation Vision-Action sur données de bureau pour le transfert vers l'IA intégrée
Cet article propose le cadre D2E (Desktop to Embodied AI), démontrant que l'interaction avec le bureau peut servir de base de pré-apprentissage efficace pour les tâches d'IA robotique intégrée. Contrairement aux approches précédentes, limitées à des domaines spécifiques ou aux données, D2E établit une chaîne technique complète, allant de la collecte évolutive de données de bureau à la vérification et à la migration du domaine intégré.
Lien vers l'article : https://go.hyper.ai/aNbE4
4. Penser avec la caméra : un modèle multimodal unifié pour une compréhension et une génération centrées sur la caméra
Cet article propose Puffin, un modèle multimodal unifié centré sur la caméra qui étend la perception spatiale le long de la dimension de la caméra, fusionne la régression du langage avec des techniques de génération basées sur la diffusion et peut analyser et générer des scènes à partir de points de vue arbitraires.
Lien vers l'article : https://go.hyper.ai/9JBvw
5. DITING : un cadre d'évaluation multi-agents pour l'analyse comparative de la traduction de romans Web
Cet article propose DITING, le premier cadre d'évaluation complet pour la traduction de romans en ligne. Il évalue systématiquement la cohérence narrative et la fidélité culturelle des traductions selon six dimensions : la traduction des idiomes, la gestion des ambiguïtés lexicales, la localisation terminologique, la cohérence des temps, la résolution des pronoms nuls et la sécurité culturelle. Il s'appuie sur plus de 18 000 paires de phrases chinois-anglais annotées par des experts.
Lien vers l'article :https://go.hyper.ai/KRUmn
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. L'Université des sciences et technologies de Hong Kong et d'autres ont proposé le modèle de prévision météorologique incrémental VA-MoE, qui comporte 751 paramètres simplifiés et atteint toujours des performances de pointe.
Des équipes de recherche de l'Université des sciences et technologies de Hong Kong et de l'Université du Zhejiang ont développé le modèle de mélange adaptatif variable d'experts (VA-MoE). Ce modèle utilise un apprentissage progressif et l'intégration d'indices variables pour guider les différents modules experts afin qu'ils se concentrent sur des variables météorologiques spécifiques. Lorsque de nouvelles variables ou stations sont ajoutées, le modèle peut être étendu sans réapprentissage complet, ce qui réduit considérablement la charge de calcul tout en préservant la précision.
Voir le rapport complet :https://go.hyper.ai/nPWPN
2. NeurIPS 2025 | L'Université des sciences et technologies de Huazhong et d'autres organisations ont publié OCRBench v2. Gemini a remporté le classement chinois, mais n'a obtenu qu'une note de passage.
L'équipe de Bai Xiang de l'Université des sciences et technologies de Huazhong, en collaboration avec l'Université de technologie de Chine du Sud, l'Université d'Adélaïde et ByteDance, a lancé le benchmark d'évaluation OCR de nouvelle génération OCRBench v2, qui a évalué 58 modèles multimodaux grand public dans le monde de 2023 à 2025 en chinois et en anglais.
Voir le rapport complet :https://go.hyper.ai/AL1ZJ
3. Sélectionné pour NeurIPS 2025, l'Université de Toronto et d'autres ont proposé le cadre Ctrl-DNA pour obtenir un « contrôle ciblé » de l'expression des gènes dans des cellules spécifiques.
Une équipe de l’Université de Toronto, en collaboration avec le laboratoire Changping, a développé un cadre d’apprentissage par renforcement contraint appelé Ctrl-DNA, qui peut maximiser l’activité régulatrice du CRE dans les cellules cibles tout en limitant strictement son activité dans les cellules non ciblées.
Voir le rapport complet :https://go.hyper.ai/eVORr
4. L'IA prédit l'emballement du plasma. Le MIT et d'autres utilisent l'apprentissage automatique pour réaliser des prédictions de haute précision de la dynamique du plasma avec des échantillons de petite taille.
Une équipe de recherche dirigée par le MIT a utilisé l'apprentissage automatique scientifique pour fusionner intelligemment les lois de la physique avec des données expérimentales. Elle a développé un modèle d'espace d'état neuronal capable de prédire la dynamique du plasma et les instabilités potentielles pendant le processus de décélération de la variable de configuration du tokamak (TCV) à partir d'un minimum de données.
Voir le rapport complet :https://go.hyper.ai/HQgZx
5. La structure MOF remporte le prix Nobel après 36 ans : lorsque l'IA comprend la chimie, les structures métallo-organiques évoluent vers l'ère de la recherche générative.
Le 8 octobre 2025, Susumu Kitagawa, Richard Robson et Omar Yaghi ont reçu le prix Nobel de chimie pour leurs contributions au domaine des structures organométalliques (MOF). Au cours des trois dernières décennies, le domaine des MOF a évolué de la conception structurale à l'industrialisation, posant les bases de la chimie computationnelle. Aujourd'hui, l'intelligence artificielle révolutionne la recherche sur les MOF grâce aux modèles génératifs et aux algorithmes de diffusion, inaugurant une nouvelle ère de la conception chimique.
Voir le rapport complet :https://go.hyper.ai/U5XgN
Articles populaires de l'encyclopédie
1. DALL-E
2. Hyperréseaux
3. Front de Pareto
4. Mémoire bidirectionnelle à long terme (Bi-LSTM)
5. Fusion de rang réciproque
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite d'octobre pour la conférence

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








