Command Palette
Search for a command to run...
De « l'assistant » À « l'utilisateur », Microsoft UserLM-8B Simule De Véritables Conversations Humaines, Ouvrant La Voie À Une Nouvelle Vague d'optimisation LLM. Conçu Pour Des Performances Légères, Extract-0 Permet Aux Modèles À Petits Paramètres d'extraire Des Informations Avec précision.

Avec le développement rapide des grands modèles de langage (LLM), nous avons assisté à l’émergence de modèles puissants qui agissent comme des « assistants », dédiés à fournir des réponses détaillées et structurées pour répondre aux besoins explicites de l’utilisateur.existerDans les situations de conversation réelles, les utilisateurs n'expriment souvent pas leurs intentions d'un seul coup, mais révèlent progressivement les informations au fil de plusieurs échanges. Leur style de langage se caractérise généralement par la fragmentation, la personnalisation et l'adaptation instantanée.En revanche, les modèles d'« assistants » traditionnels ne sont pas très performants pour simuler les utilisateurs. De plus, plus l'assistant du LLM est performant, plus son imitation d'« utilisateur » est faussée. Cette limitation met également en lumière un point sensible du système actuel d'évaluation des LLM : faute de profils d'« utilisateurs » de qualité capables de simuler fidèlement les conversations humaines, les environnements d'évaluation existants sont souvent trop idéalisés et largement dépassés par les contextes complexes des applications réelles.
C'est dans ce contexte queMicrosoft a lancé le dernier modèle de langage utilisateur UserLM-8B,Contrairement aux LLM classiques, qui servent généralement d'assistants, ce modèle, entraîné sur le corpus de conversations WildChat, permet de simuler le rôle de l'utilisateur dans les conversations, en participant à plusieurs tours de dialogue et en servant d'outil précieux pour évaluer les capacités des modèles à grande échelle. Lors de l'utilisation d'UserLM pour simuler des conversations de programmation et de mathématiques, le score de GPT-4o est passé de 74,61 TP3T à 57,41 TP3T, confirmant que des environnements de simulation plus réalistes peuvent entraîner une dégradation des performances de l'assistant, en raison de sa difficulté à répondre aux nuances de l'expression de l'utilisateur.
Le lancement d'UserLM-8B offre un environnement de test plus réaliste et plus robuste pour l'évaluation de modèles de grande taille. En simulant les conversations des utilisateurs, même les modèles d'assistants les plus performants peuvent voir leurs performances baisser considérablement, permettant ainsi aux chercheurs et aux développeurs d'identifier plus précisément les faiblesses des modèles dans les interactions réelles.Cela favorise en outre l’évaluation des compétences LLM pour aller au-delà d’un simple test de référence statique et d’une comparaison des scores, et met progressivement l’accent sur les « exercices de combat réels » qui sont plus proches de la réalité.Laissez LLM mieux comprendre les véritables intentions de l’utilisateur et optimiser en permanence l’expérience utilisateur humaine.
Le modèle de simulation de conversation utilisateur « UserLM-8b » est désormais disponible sur le site officiel d'HyperAI. Venez le tester !
Utilisation en ligne :https://go.hyper.ai/EHcdQ
Du 20 au 24 octobre, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 8
* Sélection de tutoriels de qualité : 7
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Conférence de premier plan avec date limite en octobre : 1
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence de performance CP2K_Benchmark
Le jeu de données de référence CP2K est un ensemble de données de test et de validation de performances spécialement conçu pour les environnements de calcul haute performance (HPC). Ce jeu de données, issu du logiciel open source de simulation de principes fondamentaux CP2K, permet d'évaluer les performances des calculs de chimie quantique et de dynamique moléculaire sous différentes plateformes matérielles, stratégies de parallélisation (MPI/OpenMP) et paramètres d'optimisation de la compilation.
Utilisation directe :https://go.hyper.ai/BGnLb
2. Ensemble de données de référence pour la simulation de la dynamique du plasma Smilei_Benchmark
Smilei, abréviation de Simulation of Matter Irradiated by Light at Extreme Intensities, est un code de particules électromagnétiques dans la cellule (PIC) open source et facile à utiliser, conçu pour fournir une plate-forme de simulation de dynamique de plasma de haute précision, de haute performance et évolutive pour des domaines tels que l'interaction laser-plasma, l'accélération des particules, la QED en champ fort et la physique spatiale.
Utilisation directe :https://go.hyper.ai/6VCxB
3. Exemple de jeu de données d'analyse du génome Gatk_benchmark
GATK (Genome Analysis Toolkit) est une boîte à outils bioinformatique open source développée par le Broad Institute, une coentreprise entre le MIT et l'Université Harvard. Le projet vise à fournir un pipeline d'analyse standardisé pour les données de séquençage à haut débit (NGS).
Utilisation directe :https://go.hyper.ai/0VAuf
4. Ensemble de données de référence de dynamique moléculaire LAMMPS-Bench
Les jeux de données de laboratoire LAMMPS permettent de tester et de comparer les performances de LAMMPS (logiciel de simulation de dynamique moléculaire) sur différents matériels et configurations. Ces jeux de données ne sont pas des données expérimentales scientifiques, mais servent plutôt à évaluer les performances de calcul (vitesse, mise à l'échelle et efficacité). Ils contiennent des architectures spécifiques, des fichiers de champs de force, des scripts d'entrée, des coordonnées atomiques initiales, etc. LAMMPS fournit ces jeux de données dans le dossier « bench/ ».
Utilisation directe :https://go.hyper.ai/L4gye
5. Ensemble de données SFT d'invite de réglage fin supervisé PromptCoT-2.0-SFT-4.8M
PromptCoT-2.0-SFT-4.8M est un jeu de données synthétiques à grande échelle conçu pour fournir des signaux de raisonnement de haute qualité pour les grands modèles de langage, que ce soit pour le perfectionnement ou l'auto-apprentissage. Ce jeu de données contient environ 4,8 millions de signaux entièrement synthétiques avec traces de raisonnement, couvrant deux domaines majeurs du raisonnement : les mathématiques et la programmation.
Utilisation directe :https://go.hyper.ai/f188j
6. Extraction des données d'informations du document Extract-0
Extract-0 est un jeu de données d'entraînement et d'évaluation de haute qualité, spécialement conçu pour l'extraction d'informations documentaires. Il vise à soutenir la recherche d'optimisation des performances des modèles paramétriques à petite échelle dans les tâches d'extraction complexes.
Utilisation directe :https://go.hyper.ai/z9BQO
7. Ensemble de données de référence sur la perception des émotions EmoBench-M
EmoBench-M est un jeu de données de référence proposé par l'Université de Shenzhen, le Laboratoire de Guangming, l'Université de Macao et d'autres institutions pour évaluer les capacités de compréhension des émotions des grands modèles linguistiques multimodaux (MLLM). Il vise à combler les lacunes des jeux de données émotionnels unimodaux ou statiques existants dans des scénarios d'interaction dynamiques et multimodaux, et à se rapprocher de la complexité de l'expression et de la perception émotionnelles humaines en environnement réel.
Utilisation directe :https://go.hyper.ai/WafXo
8. GeoReasoning-10K Ensemble de données de raisonnement multimodal géométrique
GeoReasoning-10K est un jeu de données de raisonnement multimodal pour la géométrie, conçu pour combler le fossé entre les modalités visuelles et linguistiques en géométrie. Ce jeu de données contient 10 000 paires géométriques image-texte accompagnées d'annotations détaillées de raisonnement géométrique. Chaque paire maintient une cohérence dans la structure géométrique, l'expression sémantique et la présentation visuelle, ce qui permet un alignement sémantique intermodal très précis.
Utilisation directe :https://go.hyper.ai/7qisY

Tutoriels publics sélectionnés
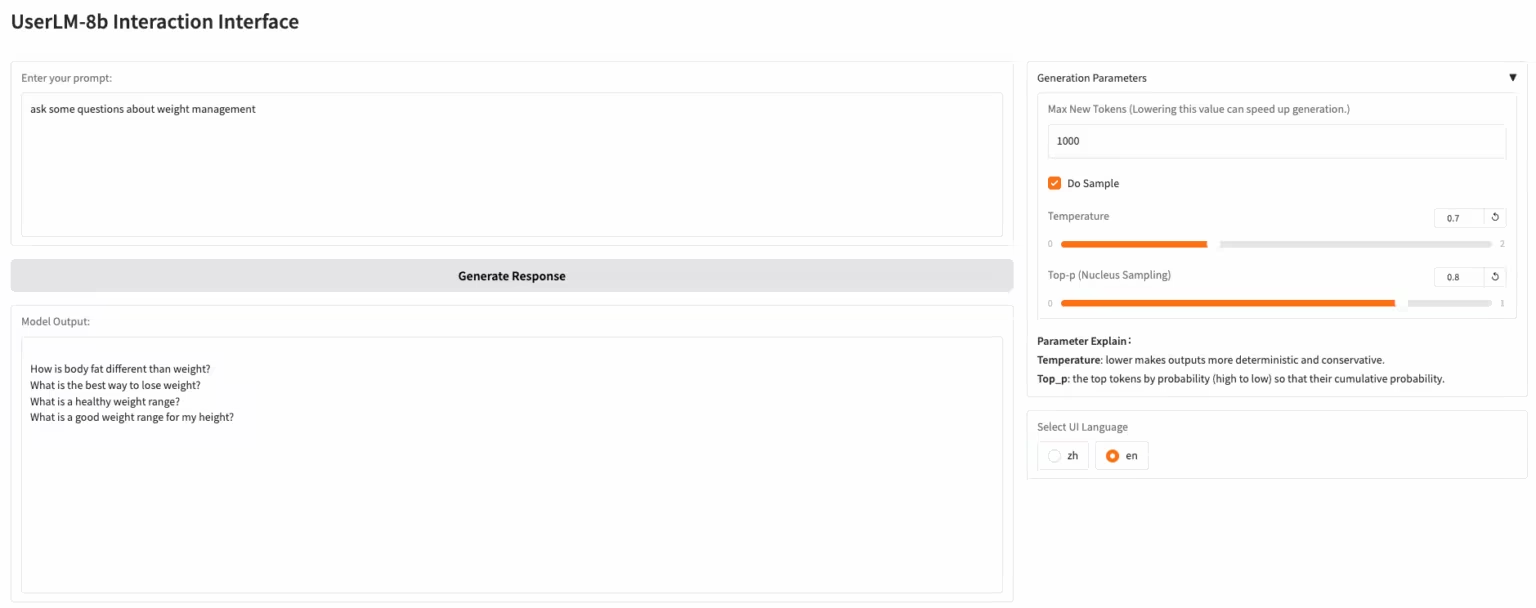
1. UserLM-8b : Modèle de simulation de dialogue utilisateur
UserLM-8b est un modèle de simulation du comportement utilisateur publié par Microsoft. Contrairement aux LLM classiques, qui jouent le rôle d'« assistant » dans les conversations, UserLM-8b simule le rôle d'« utilisateur » dans les conversations (entraîné sur le corpus de conversations WildChat) et permet d'évaluer les capacités des assistants à grande échelle. Ce modèle n'est pas un assistant à grande échelle classique et ne peut pas simuler des conversations plus réalistes ni résoudre des problèmes, mais il peut contribuer au développement d'assistants plus performants.
Exécutez en ligne :https://go.hyper.ai/EHcdQ
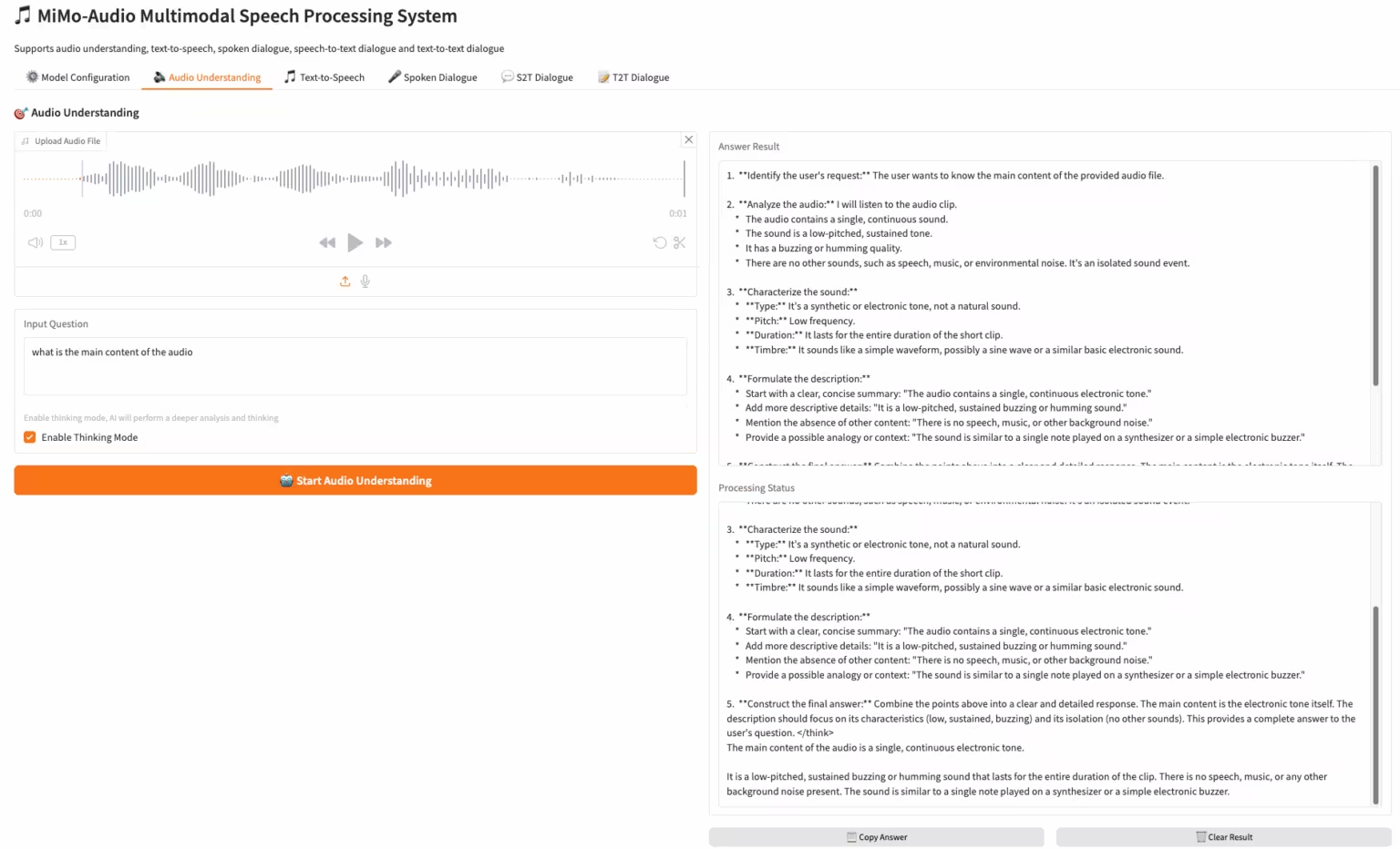
2. MiMo-Audio-7B-Instruct : le modèle vocal open source de bout en bout de Xiaomi
MiMo-Audio est un modèle vocal de bout en bout publié par Xiaomi. Les données de pré-entraînement ont été étendues à plus de 100 millions d'heures, et les chercheurs ont observé des capacités d'apprentissage en quelques secondes pour diverses tâches audio. L'équipe a évalué systématiquement ces capacités et a constaté que MiMo-Audio-7B-Base a atteint des performances de pointe (SOTA) lors des tests d'intelligence vocale et de compréhension audio des modèles open source.
Exécutez en ligne :https://go.hyper.ai/3DWbb
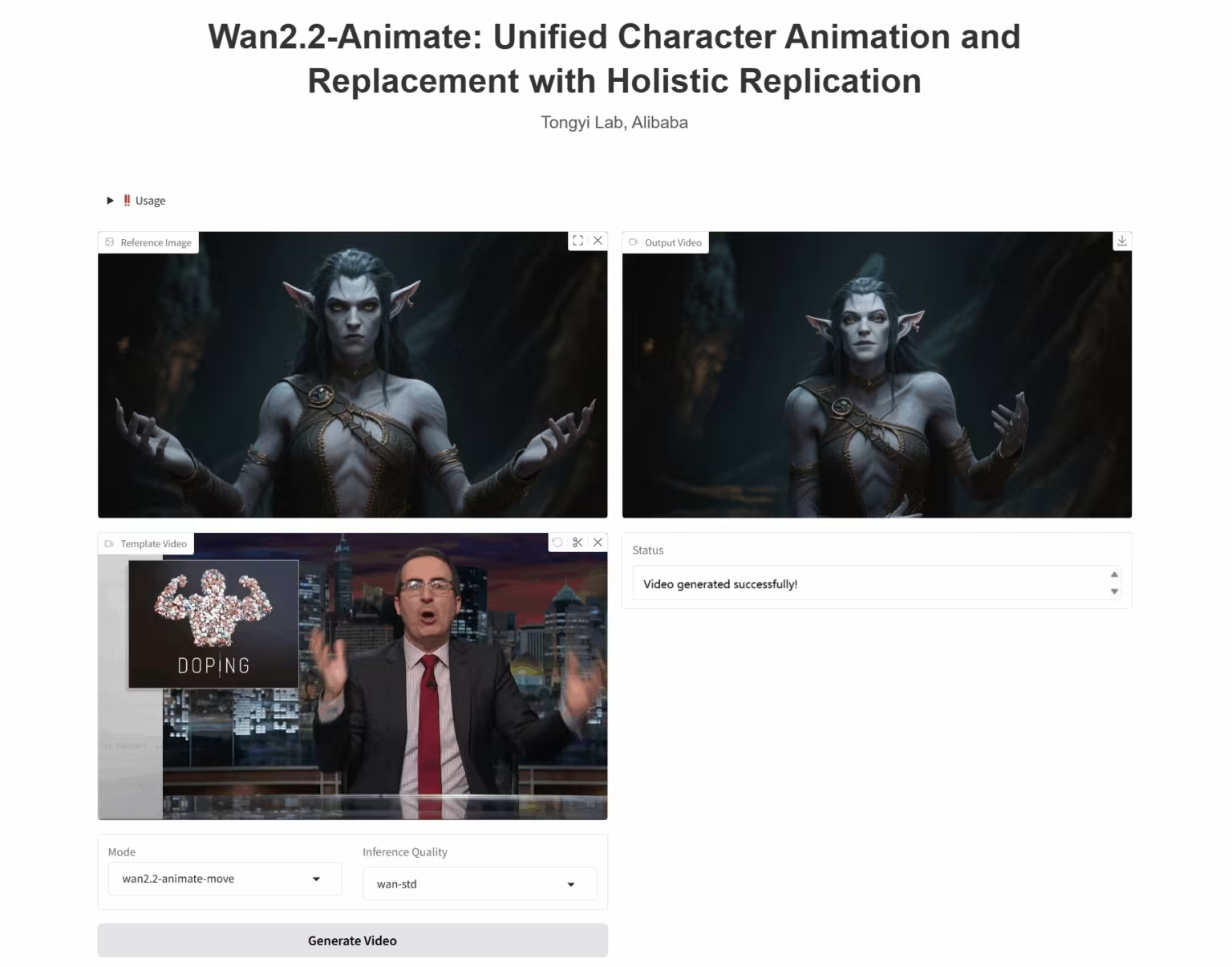
3. Wan2.2-Animate-14B : Modèle ouvert avancé de génération de vidéos à grande échelle
Wan2.2-Animate-14B est un modèle de génération de mouvement open source développé par l'équipe Alibaba Tongyi Wanxiang. Ce modèle prend en charge les modes imitation de mouvement et jeu de rôle. À partir de vidéos d'artistes, il reproduit fidèlement les expressions faciales et les mouvements pour générer des animations de personnages très réalistes.
Exécutez en ligne : https://go.hyper.ai/UbtSO
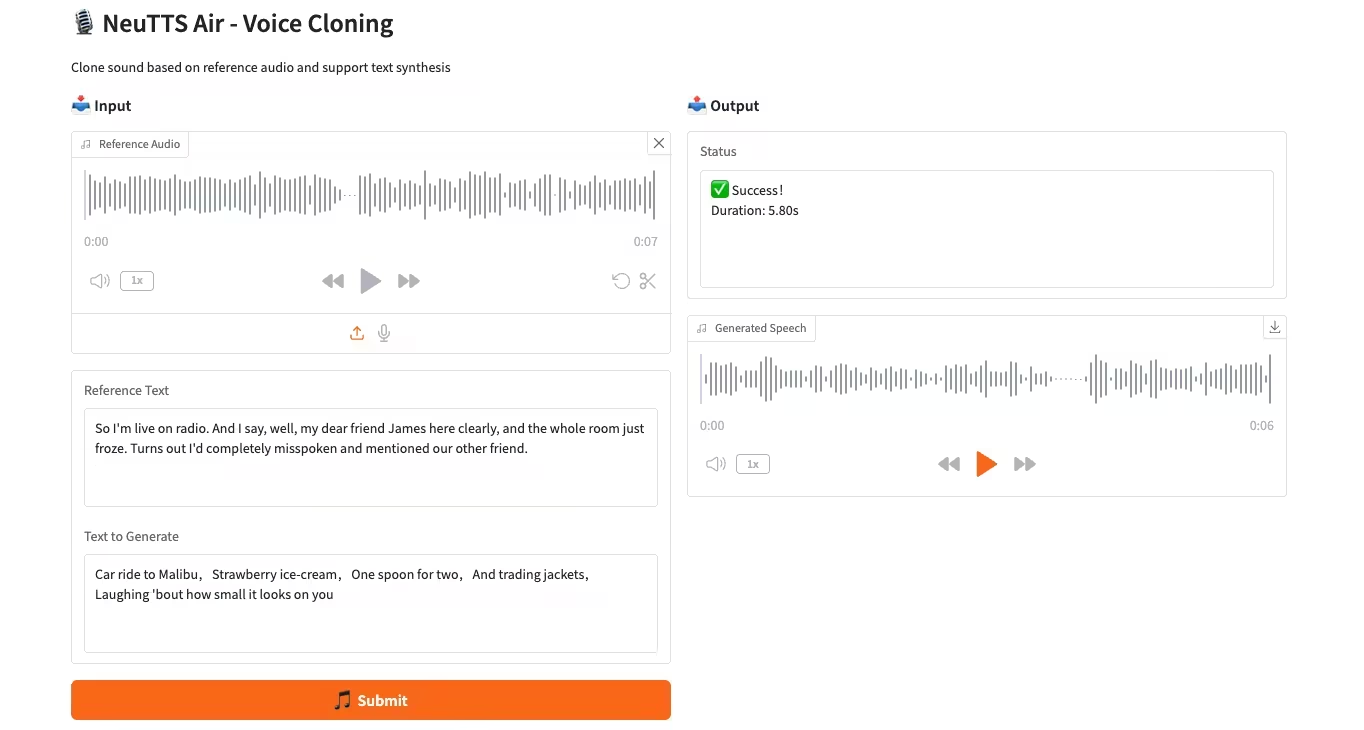
4. Déploiement du processeur du modèle de clonage vocal NeuTTS-Air
NeuTTS-Air est un modèle de synthèse vocale (TTS) de bout en bout publié par Neuphonic. Basé sur le backbone Qwen LLM de 0,5 milliard de dollars et le codec audio NeuCodec, ce modèle démontre des capacités d'apprentissage en quelques coups pour le déploiement sur appareil et le clonage vocal instantané. Les évaluations système montrent que NeuTTS Air atteint des performances de pointe parmi les modèles open source, notamment en synthèse hyperréaliste et lors des benchmarks d'inférence en temps réel.
Exécutez en ligne :https://go.hyper.ai/KMMG1
5. HuMo-1.7B : Cadre de génération vidéo multimodale
HuMo est un framework de génération vidéo multimodal développé par l'Université Tsinghua et le laboratoire de création intelligente de ByteDance, axé sur la génération vidéo centrée sur l'humain. Il génère des vidéos réalistes, de haute qualité, détaillées et contrôlables, à partir d'entrées multimodales, incluant du texte, des images et de l'audio. Le modèle prend en charge un suivi précis des signaux textuels, une préservation constante du sujet et une synchronisation des mouvements pilotée par l'audio.
Exécutez en ligne :https://go.hyper.ai/tnyQU
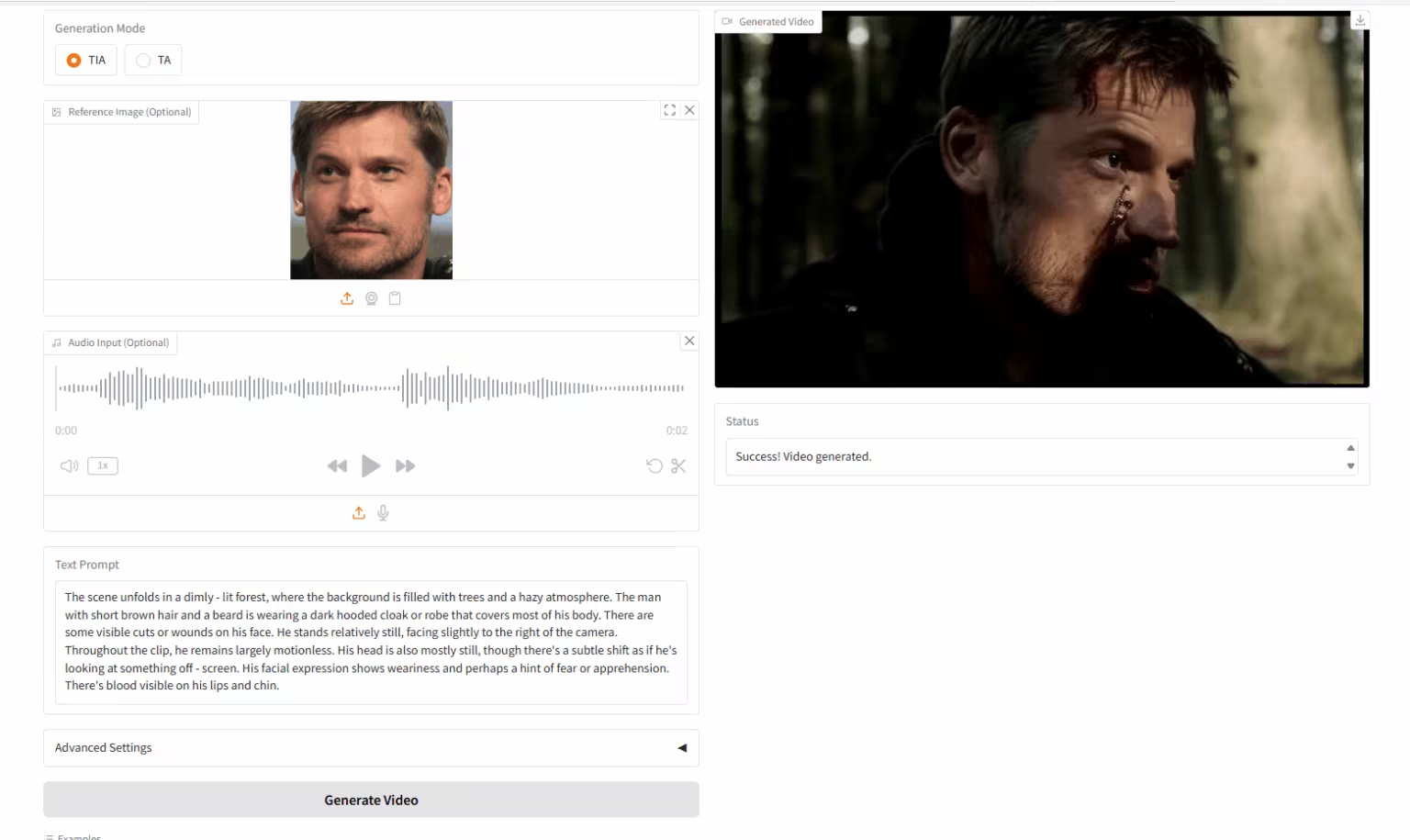
6. HuMo-17B : Création collaborative trimodale
HuMo est un framework de génération vidéo multimodale publié par l'Université Tsinghua et le ByteDance Intelligent Creation Lab. Il prend en charge la génération de vidéos à partir de fichiers texte-image (VideoGen à partir de texte-image), texte-audio (VideoGen à partir de texte-audio) et texte-image-audio (VideoGen à partir de texte-image-audio).
Exécutez en ligne :https://go.hyper.ai/liAti
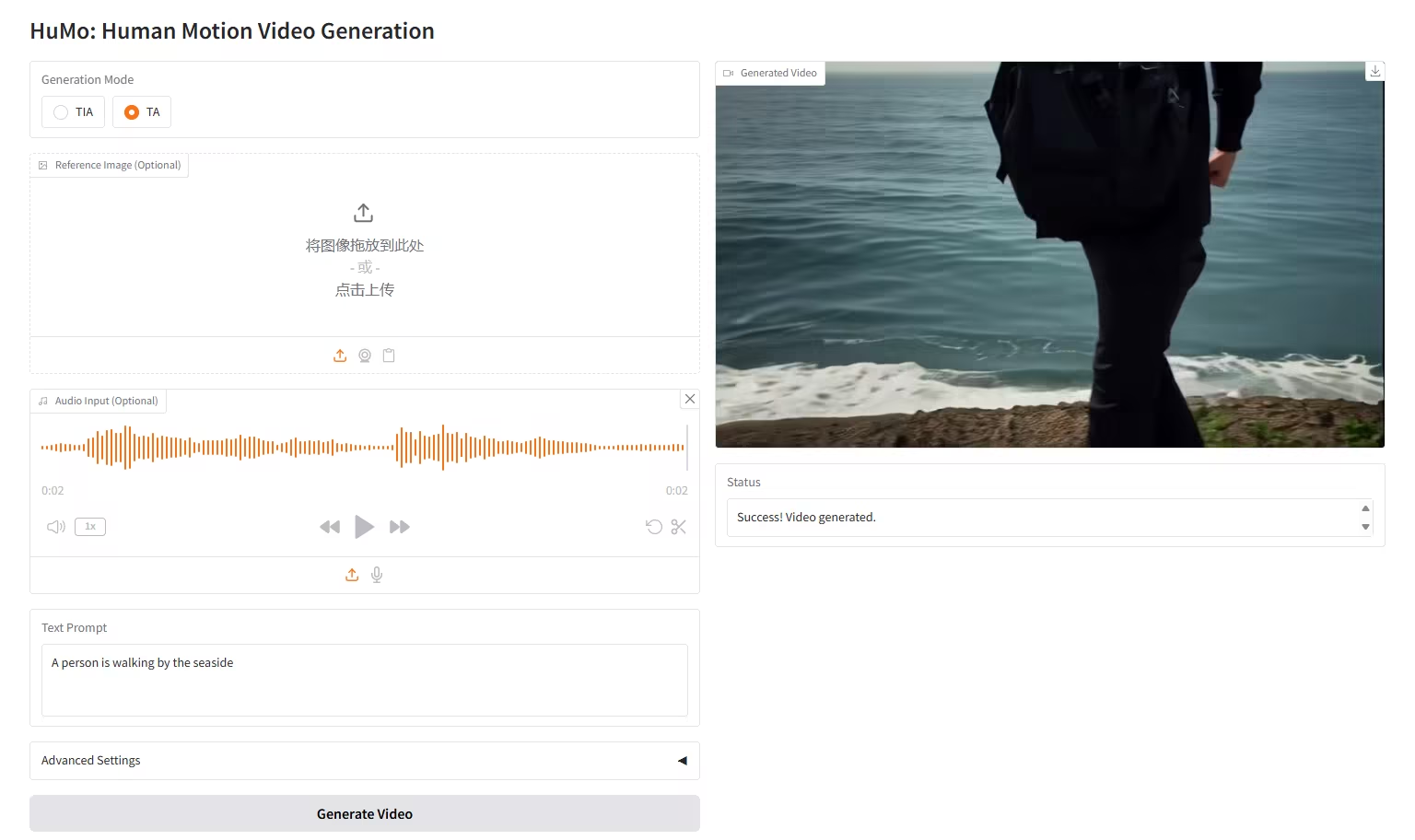
7. HunyuanImage-2.1 : Modèle de diffusion pour images Wensheng haute résolution (2K)
HunyuanImage-2.1 est un modèle d'image textuel open source développé par l'équipe Tencent Hunyuan. Il prend en charge la résolution native 2K et possède de puissantes capacités de compréhension sémantique complexe, permettant une génération précise des détails de la scène, des expressions des personnages et des actions. Ce modèle prend en charge la saisie en chinois et en anglais et peut générer des images dans divers styles, tels que des bandes dessinées et des figurines, tout en conservant un contrôle rigoureux du texte et des détails des images.
Exécutez en ligne :https://go.hyper.ai/hpWNA
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. Étude théorique sur la corrélation entre probabilité interne et auto-cohérence pour le raisonnement LLM
Cet article propose l'approche RPC (Perplexity-Consistency and Reasoning Pruning), une approche hybride intégrant des connaissances théoriques et composée de deux éléments clés : la cohérence de la perplexité et l'élagage du raisonnement. L'analyse théorique et les résultats empiriques obtenus sur sept jeux de données de référence démontrent le potentiel significatif de la RPC pour réduire les erreurs de raisonnement. Notamment, la RPC atteint des performances de raisonnement comparables à l'auto-cohérence, tout en améliorant significativement la fiabilité et en réduisant le coût d'échantillonnage de 50%.
Lien vers l'article :https://go.hyper.ai/V3reH
2. Chaque attention compte : une architecture hybride efficace pour le raisonnement à long contexte
Ce rapport technique propose une série de modèles linéaires en anneau, dont les modèles Ring-mini-linéaire-2.0 et Ring-flash-linéaire-2.0. Ces deux modèles adoptent une architecture hybride qui intègre efficacement l'attention linéaire et l'attention softmax, réduisant ainsi considérablement la charge d'E/S et la charge de calcul dans les scénarios de raisonnement à contexte long.
Lien vers l'article :https://go.hyper.ai/xLhP3
3. BAPO : Stabilisation de l'apprentissage par renforcement hors politique pour les LLM via une optimisation équilibrée des politiques avec découpage adaptatif
Cet article propose une méthode simple et efficace, l'optimisation de politique équilibrée avec découpage adaptatif (BAPO), qui ajuste dynamiquement les limites de découpage, rééquilibre de manière adaptative les contributions positives et négatives, maintient efficacement l'entropie de la politique et améliore considérablement la stabilité de l'optimisation RL.
Lien vers l'article :https://go.hyper.ai/EGQ4A
4. DeepAnalyze : Modèles de langage agentiques volumineux pour la science des données autonome
Cet article présente DeepAnalyze-8B, le premier modèle de langage à grande échelle conçu spécifiquement pour la science des données autonome. Il automatise le processus de bout en bout, de la source des données jusqu'aux rapports de recherche approfondis de qualité analytique. Les résultats expérimentaux démontrent qu'avec seulement 8 milliards de paramètres, ce modèle surpasse les agents de workflow précédents, basés sur la plupart des modèles de langage propriétaires à grande échelle de pointe.
Lien vers l'article :https://go.hyper.ai/UTdwP
5. OmniVinci : Améliorer l'architecture et les données pour une compréhension omnimodale LLM
Cet article présente le projet OmniVinci, qui vise à construire un modèle de langage étendu (LLM) omnimodal, puissant et open source. Les chercheurs ont mené des recherches approfondies sur la conception de l'architecture du modèle et les stratégies de construction de données, conçu et mis en œuvre un processus de construction et de synthèse de données, et généré un ensemble de données de 24 millions de conversations unimodales et omnimodales.
Lien vers l'article :https://go.hyper.ai/c3yQW
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. Sélectionné pour NeurIPS 2025, NVIDIA a proposé le modèle ERDM pour résoudre les problèmes de prévision à long terme, et ses prévisions à moyen et long terme continuent de dominer le benchmark EDM.
Sur la base du cadre du modèle de diffusion élucidée (EDM), une équipe de recherche de NVIDIA et de l'Université de Californie à San Diego a systématiquement amélioré la planification du bruit, la paramétrisation du réseau de débruitage, les procédures de prétraitement, les stratégies de pondération des pertes et les algorithmes d'échantillonnage pour répondre aux besoins de la modélisation de séquence, et a construit un modèle de diffusion de séquence amélioré (ERDM).
Voir le rapport complet :https://go.hyper.ai/QZBBl
2. Tutoriel inclus | Le MIT et al. lancent BindCraft, qui appelle directement AF2 pour réaliser une conception intelligente de complexes protéiques
Une équipe de l'École polytechnique fédérale de Lausanne (EPFL) et du Massachusetts Institute of Technology (MIT) a proposé un processus automatisé open source, BindCraft, permettant de concevoir des liants protéiques de A à Z. L'idée principale est de rétropropager la séquence de liant hallucinée à travers les poids AlphaFold2 et de calculer le gradient d'erreur.
Voir le rapport complet :https://go.hyper.ai/LqNeb
3. Trois prix Nobel en deux ans : l'accumulation de recherches scientifiques à long terme d'Alphabet, l'IA et l'informatique quantique à la pointe de la puissance et de l'ambition technologiques
Avec l'annonce des prix Nobel 2025, les scientifiques d'Alphabet, la maison mère de Google, ont une fois de plus été récompensés. Pour ce géant technologique, lauréat deux années consécutives de prix Nobel, le fait d'avoir remporté « trois prix et cinq lauréats en deux ans » n'est pas un hasard. De ses prix de chimie et de physique pour l'IA en 2024 à sa percée en recherche quantique, qui lui a valu le prix de physique cette fois-ci, plus d'une décennie de planification et de stratégies de recherche ambitieuses a permis de consolider ses solides capacités de recherche scientifique.
Voir le rapport complet :https://go.hyper.ai/mY9Z3
Le MIT construit un modèle d'IA génératif basé sur des priors physiques, ne nécessitant qu'une seule entrée de modalité spectrale pour réaliser une génération spectrale intermodale avec des corrélations expérimentales jusqu'à 99%.
Une équipe de recherche du MIT a proposé SpectroGen, un modèle d'IA génératif basé sur des priors physiques. Utilisant une seule modalité spectrale en entrée, il peut générer des spectres intermodaux avec une corrélation de 99% avec les résultats expérimentaux. Ce modèle introduit deux innovations clés : premièrement, la représentation des données spectrales sous forme de courbes de distribution mathématiques ; deuxièmement, la construction d'un algorithme génératif d'autoencodeur variationnel basé sur des priors physiques.
Voir le rapport complet :https://go.hyper.ai/OsYY2
5. Les équipes de Google collaborent sur Earth AI, en se concentrant sur trois points de données principaux et en améliorant les capacités de raisonnement géospatial d'ici 64%.
Plusieurs équipes de Google ont développé conjointement « Earth AI », un modèle d'intelligence artificielle géospatiale et un système de raisonnement intelligent. Ce système construit une famille interopérable de modèles GeoAI et permet l'analyse collaborative de données multimodales grâce à des agents d'inférence personnalisés. Axé sur trois types de données clés : l'imagerie, la population et l'environnement, le système relie ces trois modèles grâce à des agents Gemini. Ce système transcende les limites des modèles monopoints, permettant même aux utilisateurs non experts d'effectuer des analyses inter-domaines en temps réel et de faire progresser la recherche sur le système terrestre vers des connaissances globales et exploitables.
Voir le rapport complet :https://go.hyper.ai/djq48
Articles populaires de l'encyclopédie
1. DALL-E
2. Hyperréseaux
3. Front de Pareto
4. Mémoire bidirectionnelle à long terme (Bi-LSTM)
5. Fusion de rang réciproque
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite d'octobre pour la conférence

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








