Command Palette
Search for a command to run...
Pour Améliorer La Disponibilité Des Données Scientifiques, l'équipe De Zhang Zhengde À l'Académie Chinoise Des Sciences a Proposé Une Solution De Traitement Et De Fourniture De Données Compatible Avec l'IA Basée Sur Des Agents intelligents.

Dans la recherche actuelle en physique des hautes énergies, les installations scientifiques de pointe à grande échelle génèrent en permanence des quantités massives de données. Face à ce déluge de données sans précédent dépassant largement les limites de traitement des méthodes analytiques traditionnelles, les technologies d'intelligence artificielle (IA), notamment l'apprentissage automatique et les réseaux de neurones profonds, deviennent rapidement des outils essentiels dans le processus de recherche en physique des hautes énergies. Les algorithmes d'IA traitent efficacement de vastes quantités de données brutes et révèlent des schémas et des corrélations implicites, non linéaires et complexes, et présentent également des avantages applicatifs pour l'optimisation du fonctionnement des accélérateurs, la simulation des performances des détecteurs, la conception de systèmes de déclenchement expérimentaux et l'exploration de modèles théoriques. L'innovation continue et l'intégration poussée des méthodes d'IA sont devenues un moteur potentiel du développement futur de la physique des hautes énergies.
Lors de la Conférence académique nationale sur le calcul haute performance 2025 du CCF, Zhang Zhengde, chercheur et responsable de l'AI4S au Centre de calcul de l'Institut de physique des hautes énergies, s'est exprimé lors du forum « AI-Ready Scientific Data Technology » sur le thème « Avancées et pratiques du traitement des données des agents intelligents basés sur de grands modèles ».À partir de l'état actuel des données scientifiques provenant d'installations à grande échelle, cet article explique systématiquement le plan de construction efficace et de haute qualité pour les données, ainsi que l'application d'agents intelligents et de cadres multi-agents dans l'annotation et la fourniture de données.

HyperAI a compilé et résumé le discours du professeur Zhang Zhengde sans en compromettre l'intention initiale. Voici la transcription de son discours.
L'état des données prêtes pour l'IA et des données scientifiques
Dans le contexte des algorithmes AI4S open source, les données sont devenues le problème central le plus critique. L'IA pour le développement durable exige que les données soient conformes à des normes unifiées pour une analyse efficace. Bien que les données des grandes installations scientifiques bénéficient généralement d'un format et d'une architecture de stockage unifiés, en réalité, la plupart des données scientifiques ne sont pas compatibles avec l'IA.
L'énorme quantité de données générées par la physique des hautes énergies impose non seulement des exigences élevées aux technologies d'acquisition, de traitement et de fusion de données, mais constitue également une ressource essentielle pour le développement de méthodes d'IA. Les types de données mentionnés dans le rapport d'aujourd'hui comprennent non seulement des données expérimentales, mais aussi des données de simulation, des données de fonctionnement d'appareils et des données de corpus.
La définition générale d’un ensemble de données prêt pour l’IA est un ensemble de données qui peuvent être utilisées de manière efficace, sécurisée et reproductible pour la formation, l’évaluation et le déploiement de l’apprentissage automatique et de l’intelligence artificielle.Les données de haute qualité compatibles avec l'IA présentent 10 caractéristiques :
* Adaptation des tâches.Forte pertinence par rapport au scénario et à la tâche cibles, avec une couverture et une représentativité complètes ;
* Haute qualité et cohérence.Précis, complet, cohérent, dédupliqué et sans bruit ;
* Se conformer aux exigences de l'organisme et du marquage,Il dispose d'étiquettes, de hiérarchies et de mappages d'ontologies de haute qualité et est annoté avec des audits ;
* Ingénierie disponible.Lisible par machine, c'est-à-dire disposant d'un format standard, d'un sharding/bucketing raisonnable, d'une capacité de diffusion en continu et d'une parallélisation ;
* Évaluable et réutilisable.Divisez strictement les données de formation, de test et de validation, et l'ensemble de référence dispose d'indicateurs d'évaluation clairs et raisonnables ;
* Métadonnées et enrichissement.Couvre la méthode de collecte des métadonnées, l'heure, le système d'appareil, le contexte, la version et d'autres informations ;
* Contrôle des écarts de données.Tels que le biais d’échantillonnage, le biais d’étiquette et le biais historique ;
* Disponible.Interface d'accès stable, documentation et exemples ;
* Raisonnable et conforme.Autorisations et droits d'utilisation, protection de la vie privée et meilleures informations personnelles identifiables ;
* Sûr et fiable.Cryptage (en transit/au repos), moindre privilège, gestion des clés, etc.
En recherche pratique, les données ne servent pas seulement à entraîner les modèles, mais doivent également soutenir leur évaluation. Par conséquent, les ensembles de données nécessitent la définition de mesures d'évaluation correspondantes, telles que la précision, le rappel et le score F1. Cependant, si ces mesures sont généralement applicables à certaines tâches (comme la classification), elles sont moins efficaces pour des problèmes comme la régression. Cela impose des exigences plus élevées en matière de qualité des ensembles de données compatibles avec l'IA et présente des défis.
à l'heure actuelle,En plus de contenir des données ontologiques et annotées, un jeu de données qualifié et compatible avec l'IA doit également fournir des métadonnées, notamment une description de la tâche d'IA. Plus important encore, un jeu de données compatible avec l'IA doit être directement associé à des tâches d'IA pertinentes.En prenant les sources lumineuses comme exemple, leurs applications d’IA devraient être en mesure de prendre en charge efficacement des tâches scientifiques spécifiques telles que l’imagerie, la spectroscopie et la diffusion par diffraction.
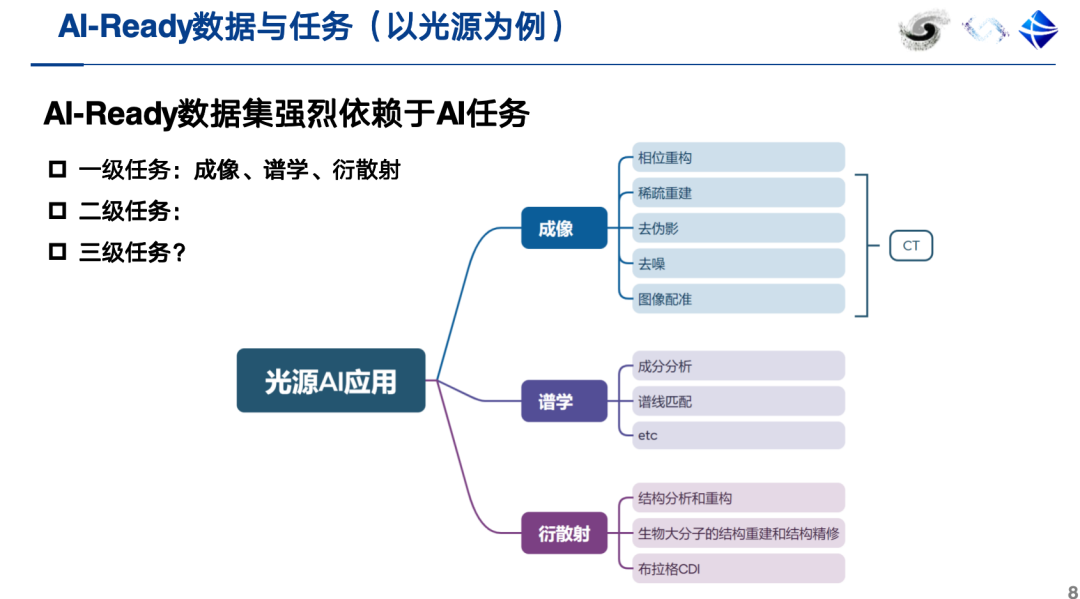
J'utiliserai ensuite deux exemples pour illustrer ce qui constitue un ensemble de données prêt pour l'IA. Par exemple, l'ensemble de données de prédiction de l'orientation des nanofibres a une tâche d'IA claire : prédire directement les paramètres d'orientation des nanofibres à partir de spectres de diffraction grand angle. La construction d'un tel ensemble de données nécessite la combinaison de données simulées et expérimentales.
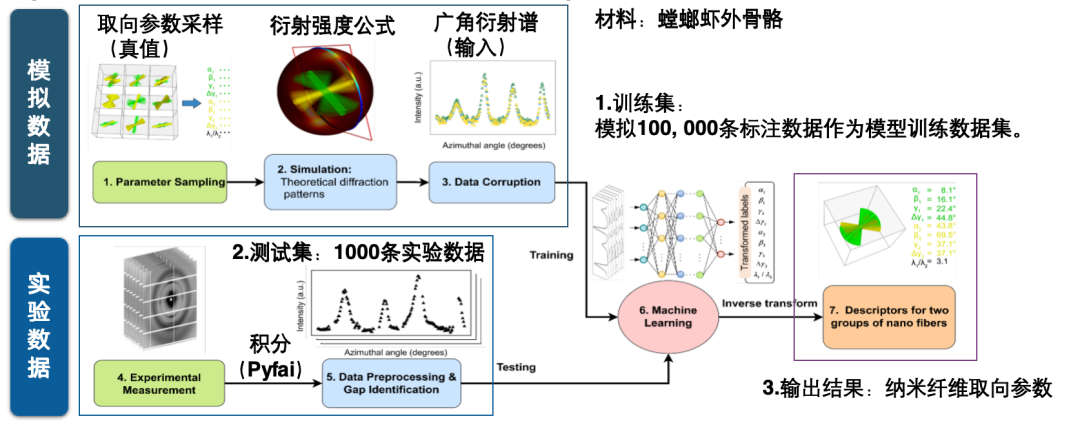
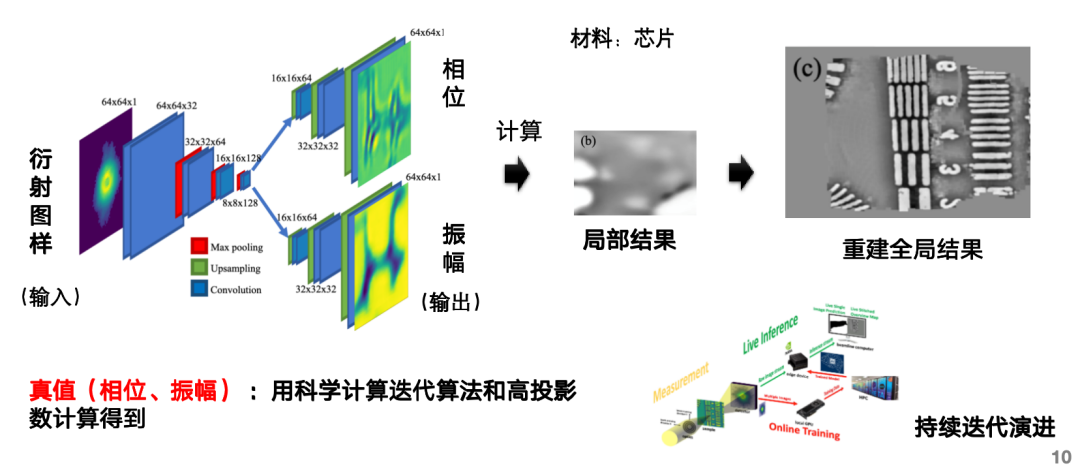
Par exemple, l'ensemble de données d'IA pour la reconstruction rapide d'images empilées peut compléter la tâche d'IA consistant à saisir un motif de diffraction, à prédire sa phase et son amplitude, et à calculer l'image reconstruite, complétant ainsi l'important travail de calcul nécessaire à la reconstruction d'images. Cette architecture comprend deux branches, l'une pour la prédiction de la phase et l'autre pour l'amplitude. Les valeurs réelles sont dérivées à l'aide d'un algorithme itératif de calcul scientifique et d'un grand nombre de projections.
Application de la technologie des agents au traitement des données
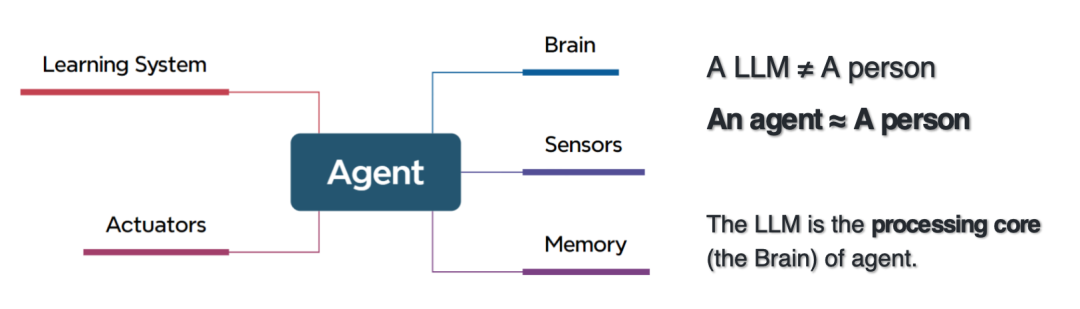
La définition d’un agent est très proche de la définition originale de l’intelligence artificielle, qui fait référence à des logiciels ou des systèmes capables de prendre des décisions ou d’effectuer des actions au nom des utilisateurs en fonction de leurs connaissances, de leurs programmes, de leur environnement et des informations saisies.
Bien que les agents intelligents présentent des similitudes avec les technologies d'automatisation, ces dernières reposent généralement sur des processus fixes pour fonctionner. Contrairement à l'automatisation traditionnelle, les agents intelligents sont particulièrement adaptés au traitement de flux de travail qui ne peuvent être efficacement couverts par des règles déterministes et peuvent gérer des tâches difficiles à gérer par les méthodes de calcul traditionnelles basées sur des règles.Les agents intelligents ne conviennent pas à tous les scénarios. Leur efficacité dépend fortement de l'environnement de la tâche et nécessite une prise en compte complète de la complexité de la prise de décision et du traitement des données. Par conséquent, la conception d'agents intelligents nécessite de repenser la manière dont le système doit gérer les processus décisionnels complexes.
Le cerveau de l’agent intelligent est un grand modèle, donc la relation entre l’agent intelligent et le grand modèle est en fait une relation d’inclusion.La différence entre un agent intelligent et un grand modèle est qu’il comprend une couche de perception, une couche d’exécution, une couche mémoire et un centre de traitement.Être capable d'acquérir une expertise du domaine, des outils d'analyse scientifique, de percevoir les données et les métadonnées, d'écrire du code et d'exécuter des programmes, de planifier des tâches, d'attribuer des rôles et de collaborer, etc.
Parallèlement, les scénarios d'application des systèmes mono-agent et multi-agent sont également différents. En général, un système mono-agent est équipé d'un seul outil. Plus le nombre d'outils embarqués augmente, plus la précision de la sélection diminue. Dans ce cas, les systèmes multi-agents peuvent être utilisés pour éviter toute confusion.
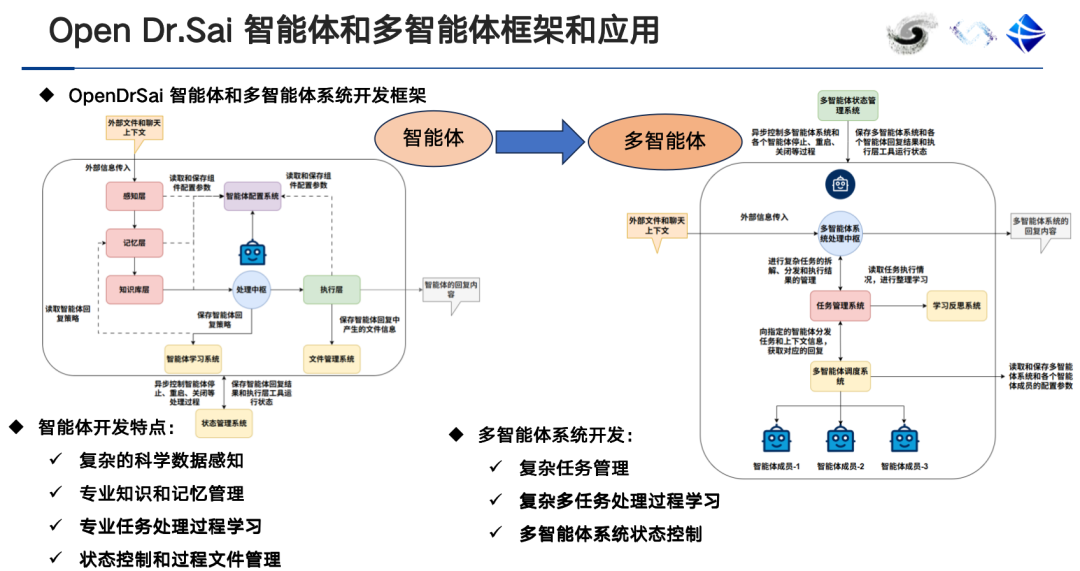
L'étiquetage des données par IA, basé sur des outils d'étiquetage, offre une grande précision, mais nécessite une intervention manuelle importante. L'étiquetage par IA, basé sur des agents intelligents, est hautement automatisé et efficace, et peut fournir une compréhension et une assistance des données. Il convient à la recherche interdisciplinaire, mais sa précision initiale peut être relativement faible, et la précision de l'étiquetage doit être continuellement améliorée grâce à des mécanismes d'apprentissage et de rétroaction continus.À l'heure actuelle, de nombreux outils d'annotation basés sur l'annotation sont progressivement passés au modèle « équipé d'un module d'agent intelligent + interaction homme-machine + assistance intelligente + système de révision + base de données ».
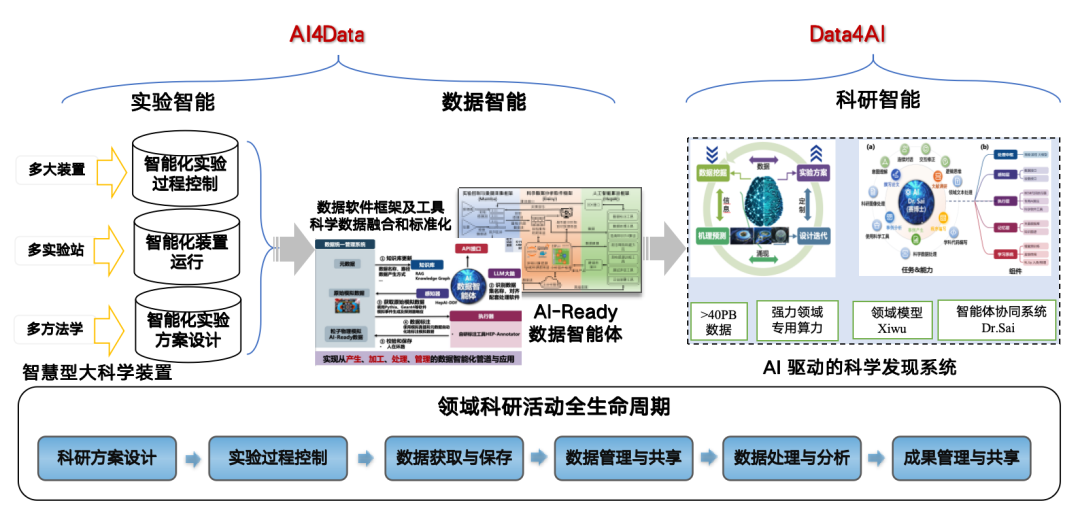
Agent de données appliqué aux scènes de sources lumineuses
L'agent de données de notre équipe est principalement utilisé dans les scénarios de sources lumineuses (HEPS) et de sources de neutrons (CSNS), pour le traitement et l'approvisionnement des données. L'agent est en amont du système de gestion des données Domas, lui-même connecté au système de collecte de données du dispositif Big Data, lui-même connecté au détecteur lui-même.
Pour plus d'informations sur les agents de données :
https://github.com/hepaihub/drsai
Lien vers la plateforme HepAI :
Le flux de travail de l'agent est divisé en 5 étapes :
* Connectez-vous à Domas pour obtenir des informations sur les données, y compris les données expérimentales et les métadonnées ;
* Mettre à jour la base de connaissances en fonction des données acquises ;
* L'agent perçoit en outre des données en fonction de tâches spécifiques et complète l'interaction avec les données en convertissant les formats de données et en exécutant des commandes ;
* Utiliser une variété d’outils de calcul scientifique pour traiter les données ;
* Saisissez les données dans l'exécuteur pour piloter l'exécution des tâches et saisissez les résultats de sortie dans Domas.
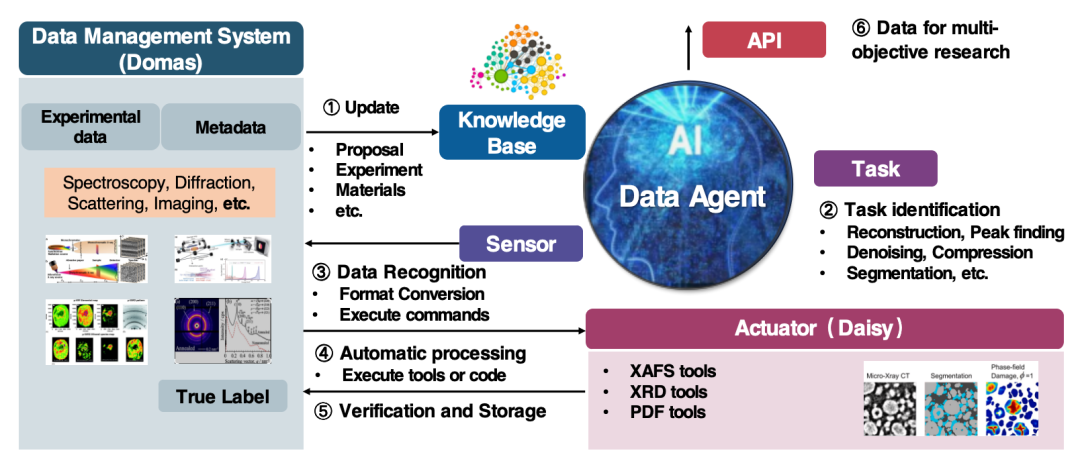
Actuellement, l'agent peut être utilisé pour construire des ensembles de données d'IA d'expériences et de simulations de diffraction des rayons X et de diffraction de poudre de neutrons entre appareils, et pour construire des ensembles de données de fusion expérimentale-simulation de fonctions de distribution de paires (PDF).
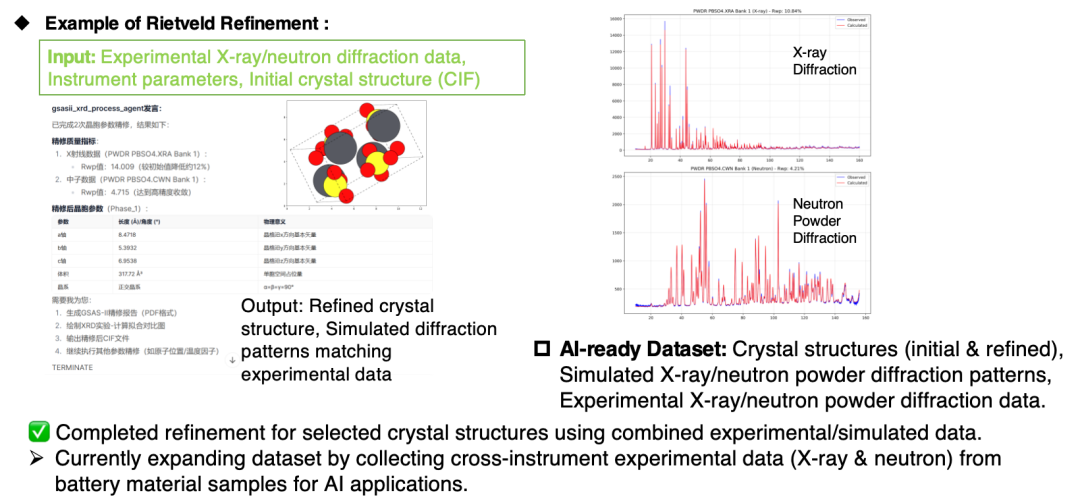
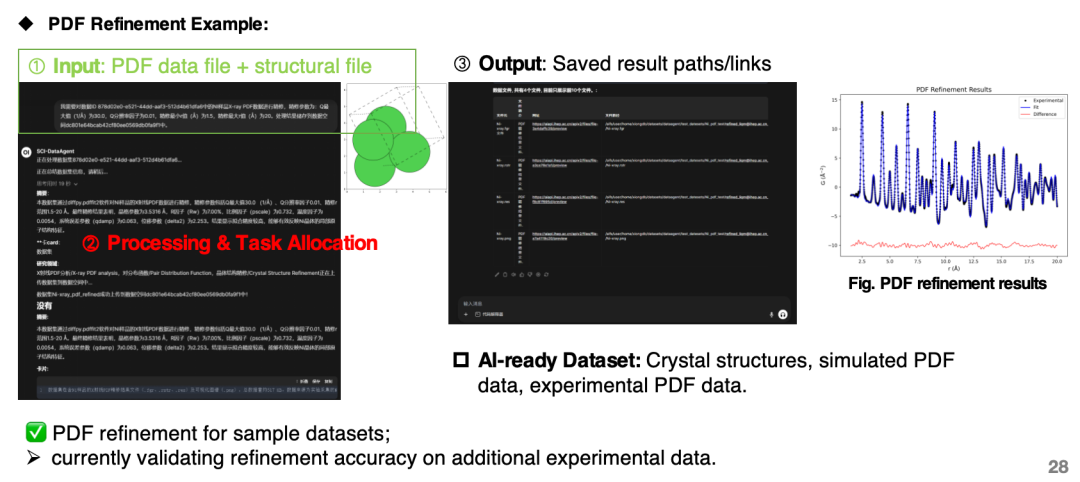
Système de découverte scientifique piloté par l'IA
La raison pour laquelle nous utilisons la technologie des agents intelligents dans le traitement des données est que l'IA pour les systèmes intelligents (IA4S) est devenue une tendance de développement. L'IA est utile à la recherche et à la découverte en physique des hautes énergies, mais elle exige des données de grande qualité.Par conséquent, nous avons adopté la stratégie « AI4Data » vers « Data4AI », en utilisant l'IA pour convertir les données brutes en un format prêt pour l'IA afin de promouvoir les résultats de la recherche et du développement et de construire un système de découverte scientifique piloté par l'IA.
À propos du chercheur Zhang Zhengde et de son équipe
Le Dr Zhang Zhengde est un jeune chercheur distingué à l'Institut de physique des hautes énergies de l'Académie chinoise des sciences. Il est titulaire d'un doctorat en physique des particules et en physique nucléaire de l'Institut de physique appliquée de Shanghai. Ses principaux domaines de recherche sont les algorithmes d'IA, les grands modèles et les agents intelligents pour la découverte scientifique, couvrant les algorithmes d'apprentissage profond, les grands modèles de données scientifiques, les plateformes d'intelligence artificielle et les systèmes logiciels. Son objectif principal est de promouvoir l'application de l'IA à la physique des particules, à l'astrophysique des particules, au rayonnement synchrotron, à la neutronologie et aux accélérateurs.

Actuellement, le chercheur Zhang Zhengde a publié six projets open source représentatifs sur GitHub, développé des réseaux neuronaux tels que CDNet, FINet et MWNet, développé le modèle de langage Xiwu à haute énergie et l'agent de recherche scientifique « Science Doctor », et planifié et construit la plateforme d'intelligence artificielle en physique des hautes énergies HepAI[4]. Parallèlement, il a présidé plusieurs projets de recherche scientifique importants, notamment « Projet De 0 à 1 – Recherche sur la découverte scientifique en physique des hautes énergies pilotée par de grands modèles d'IA » et « Recherche et démonstration de la technologie Big Data en physique des hautes énergies basée sur l'intelligence artificielle ».
Références :
[3] hepai-group. (nd). Open drsai [Logiciel informatique]. GitHub. https://github.com/hepaihub/drsai
[4] hepai-group. (nd). Plateforme HepAI. https://ai.ihep.ac.cn
Obtenez des articles de haute qualité et des articles d'interprétation approfondis dans le domaine de l'IA4S de 2023 à 2024 en un seul clic⬇️









