Command Palette
Search for a command to run...
NeurIPS 2025 | Le MIT Propose AutoSciDACT, Un Outil De Découverte Scientifique Automatisé Très Sensible Aux Données Anormales En Astronomie, En Physique Et En biomédecine.

Tout au long de l'histoire, les découvertes scientifiques ont souvent comporté une part de hasard. Par exemple, la pénicilline a été découverte accidentellement dans une boîte de Petri moisie, et le rayonnement de fond cosmique provient d'un « bruit anormal » capté par une antenne. Ces observations fortuites sont finalement devenues des moteurs essentiels du progrès de la civilisation humaine. Aujourd'hui, dans le contexte de la recherche axée sur les données, d'immenses quantités de données interdisciplinaires recèlent des observations encore plus singulières et inexplicables, multipliant théoriquement les chances de découvertes scientifiques accidentelles. Pourtant, paradoxalement, extraire avec précision de « nouvelles découvertes » de ces volumes considérables et complexes de données de recherche est bien plus difficile que de chercher une aiguille dans une botte de foin.
Les méthodes traditionnelles de découverte scientifique reposent largement sur l'intuition et l'expertise des scientifiques, nécessitant un processus complexe d'observation, de recherche, d'hypothèse, d'expérimentation et de vérification pour déterminer la véritable valeur scientifique d'une « nouvelle découverte ». Cependant, face à la croissance exponentielle et à la complexité croissante des données scientifiques, identifier de « nouvelles découvertes » par la seule observation attentive est devenu quasiment impossible. Si les méthodes d'investigation scientifique automatisées, basées sur l'intelligence artificielle et les grands modèles de langage, se sont récemment révélées prometteuses,Cependant, en raison de l'absence d'un cadre intégré capable de tester et de vérifier rigoureusement et automatiquement les hypothèses,Même avec de telles méthodes, il reste inévitable que « la volonté soit là, mais les capacités insuffisantes ».
Pour relever les défis de la découverte scientifique, une équipe du MIT, de l'UW-Madison et de l'Institut pour l'intelligence artificielle et les interactions fondamentales (IAIFI) de la National Science Foundation a proposé une méthode appelée AutoSciDACT (Découverte scientifique automatisée avec test contrastif anormal).Il peut être utilisé pour automatiser la détection de « nouvelles découvertes » dans les données scientifiques, simplifiant ainsi la recherche scientifique.Les chercheurs ont validé la méthode sur des ensembles de données réels en astronomie, physique, biomédecine et imagerie, ainsi que sur un ensemble de données synthétiques, démontrant que la méthode est très sensible à de petites quantités de données anormales injectées dans tous les domaines.
Les résultats de recherche associés, intitulés « AutoSciDACT : Découverte scientifique automatisée grâce à l'intégration contrastive et aux tests d'hypothèses », ont été publiés dans NeurIPS 2025.
Points saillants de la recherche :
* AutoSciDACT est un cadre général de bout en bout pour détecter la nouveauté des données scientifiques, avec une transférabilité interdomaines ;
* Un processus systématique a été conçu en intégrant des données de simulation scientifique, des données étiquetées manuellement et des connaissances d'experts dans un flux de travail de réduction de dimensionnalité comparative ;
* Un cadre statistique rigoureux a été élaboré pour quantifier la signification des anomalies observées et pour déterminer, d'un point de vue statistique, si ces anomalies ont une signification scientifique.
* Les résultats ont été validés par des données réelles dans quatre domaines scientifiques très différents, démontrant une efficacité, une force de persuasion et une valeur promotionnelle significatives.

Adresse du document :
https://openreview.net/forum?id=vKyiv67VWa
Suivez le compte public et répondez à « AutoSciDACT Obtenez le PDF complet
Autres articles sur les frontières de l'IA :
https://hyper.ai/papers
Jeux de données : Des jeux de données diversifiés et interdisciplinaires valident les performances supérieures d’AutoSciDACT
Afin de vérifier rigoureusement les performances supérieures d'AutoSciDACT,Les chercheurs l'ont testé sur cinq ensembles de données provenant de domaines complètement différents.Ces ensembles de données comprennent des données provenant de quatre domaines distincts : l’astronomie, la physique, la biomédecine et l’imagerie, ainsi qu’un ensemble de données construit synthétiquement.
Concernant les ensembles de données astronomiques,L'équipe a sélectionné les données d'ondes gravitationnelles enregistrées par l'Observatoire d'ondes gravitationnelles par interférométrie laser (LIGO) à Hanford (Washington) et Livingston (Louisiane) comme référence astronomique. Ces données couvrent la troisième campagne d'observation, d'avril 2019 à mars 2020. Elles consistent en des signaux temporels de 50 millisecondes provenant de deux canaux (un canal par interféromètre), échantillonnés à une fréquence de 4 096 Hz (200 mesures par canal). Différentes catégories de données ont été incluses : le bruit pur, les interférences instrumentales, les signaux astrophysiques connus et un type de signal caché appelé « sursaut de bruit blanc (WNB) » (considéré comme une anomalie). Les signaux WNB ont été exclus lors du pré-entraînement, puis injectés dans les données afin de tester la capacité du modèle à identifier ce signal invisible parmi les signaux d'ondes gravitationnelles.
ensembles de données de physiqueL'équipe a choisi le jeu de données JETCLASS comme référence en physique des particules. Ce vaste ensemble contient des jets simulés issus de collisions proton-proton au Grand collisionneur de hadrons (LHC). L'étude a utilisé un sous-ensemble de ces données, incluant les jets provenant de processus de chromodynamique quantique (QCD) (quark/gluon), de la désintégration du quark top (t → bqq′) et de la désintégration des bosons vecteurs W/Z (V → qq′). Les jets de signal issus de la désintégration du boson de Higgs en quark bottom (H → bb¯) ont également été conservés. L'équipe a utilisé le Particle Transformer (ParT) comme encodeur contrastif, une variante de l'architecture Transformer adaptée à la physique des particules.
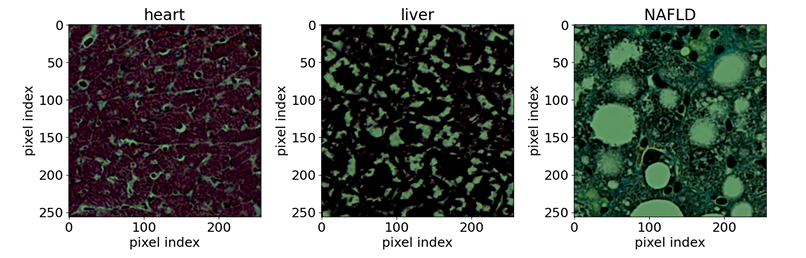
Dans le domaine de la biomédecine,L'équipe a utilisé des images de microscopie optique, accessibles au public, d'échantillons de tissus colorés. Les échantillons de référence comprenaient sept types de tissus de souris (cerveau, cœur, rein, foie, poumon, pancréas et rate) et un type de tissu hépatique normal de rat. L'objectif de la recherche était de détecter les anomalies du tissu hépatique de souris dues à la stéatose hépatique non alcoolique (NAFLD). Les échantillons d'entrée étaient des coupes de tissus d'une résolution de 256 x 256 pixels, extraites d'images de coupes complètes et colorées au trichrome de Masson. Le réseau de neurones utilisé était EfficientNet-B0.
En matière de science de l'image,L'équipe a utilisé le jeu de données d'images CIFAR-10 (50 000 images au total), en sélectionnant aléatoirement la première classe comme classe d'anomalies et en effectuant un pré-entraînement sur les neuf autres classes. Lors de la phase de découverte, l'équipe a enrichi l'ensemble de test CIFAR-10 avec 100 000 images issues de CIFAR-5m, augmentant ainsi le nombre de points de données disponibles pour les tests d'hypothèses. L'architecture de l'encodeur utilisait un réseau ResNet-50 avec des poids pré-entraînés, remplaçant uniquement la dernière couche entièrement connectée par un MLP légèrement plus grand, puis affinant ce réseau sur la tâche d'intégration contrastive de CIFAR.
Concernant les ensembles de données synthétiques,Son objectif principal est de démontrer les capacités fondamentales d'AutoSciDACT et de vérifier son insensibilité aux spécificités des jeux de données scientifiques réels. Le jeu de données synthétiques est constitué de X⊂R^D+M, comprenant D dimensions significatives et M dimensions bruitées. Ces dernières sont générées uniformément entre 0 et 1, tandis que les dimensions significatives sont composées de N clusters gaussiens de moyenne uniforme comprise entre 0 et 1 et de covariances générées aléatoirement (distribuées uniformément entre 0 et 0,5). Toutes les dimensions sont ensuite soumises à une rotation aléatoire afin de masquer les variables discriminantes initiales. L'apprentissage est réalisé par une méthode d'intégration contrastive, utilisant uniquement N-1 clusters comme données d'apprentissage et réservant un cluster comme « signal » à détecter. Le modèle de base utilisé pour l'apprentissage est un perceptron multicouche (MLP) simple.
De plus, une validation complémentaire a été réalisée à l'aide d'autres jeux de données, tels que le jeu de données génomiques pour l'identification des hybrides de papillons et des données réelles sur la désintégration des tétraleptons dans le boson de Higgs du LHC, afin de vérifier plus avant la capacité de généralisation interdomaines du modèle. En résumé, ces différents jeux de données ont tous été construits à partir de « données de fond » et de « données de signaux anormaux », et ont servi respectivement au pré-entraînement du modèle et à la vérification de sa capacité à détecter des nouveautés. Les résultats de validation démontrent l'efficacité d'AutoSciDACT en tant que processus général de détection de nouveautés dans les données scientifiques, ainsi que sa capacité de généralisation interdomaines.
Architecture du modèle : un processus en deux étapes de « pré-entraînement » et de « découverte » crée de nouvelles méthodes pour la découverte scientifique
Le cœur d'AutoSciDACT repose sur deux étapes : « pré-entraînement - découverte ».En combinant l'intégration de caractéristiques de faible dimension avec des tests statistiques, nous pouvons extraire des « signaux nouveaux » statistiquement significatifs à partir de données scientifiques de haute dimension.
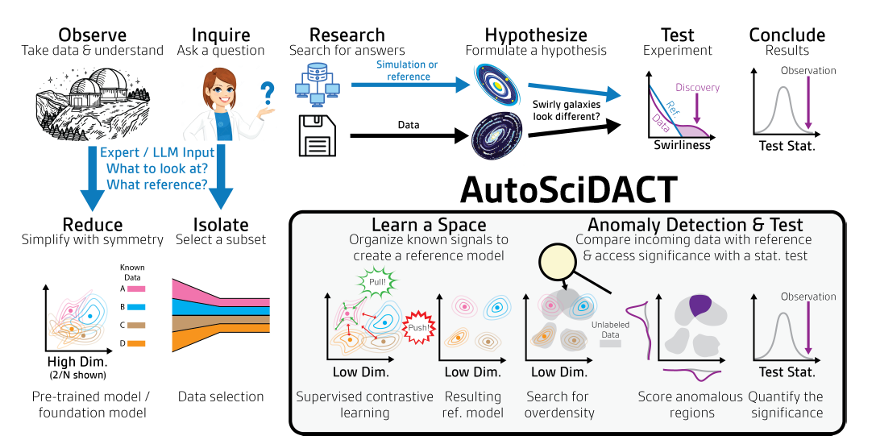
Plus précisément, la phase de pré-entraînement s'attaque au problème de la redondance des données de grande dimension. Elle consiste principalement à compresser les centaines, voire les milliers, de dimensions des caractéristiques d'entrée que peuvent contenir les données scientifiques originales en vecteurs de faible dimension, tout en conservant les caractéristiques sémantiques clés des données – c'est-à-dire l'information essentielle au sens scientifique du terme – jetant ainsi les bases de l'analyse ultérieure.
En termes d'implémentation, l'élément central du pipeline pré-entraîné est un encodeur fθ : X → Rᵈ entraîné par apprentissage contrastif. Cet encodeur transforme les données brutes de l'espace d'entrée de haute dimension X en une représentation de basse dimension dans Rᵈ. L'objectif de l'apprentissage contrastif est de maximiser l'alignement entre les entrées similaires (paires positives) tout en séparant les entrées dissemblables (paires négatives) dans l'espace d'apprentissage. Le framework sous-jacent utilise SimCLR, qui entraîne l'encodeur fθ et la tête de projection gϕ.Après l'entraînement, seul l'encodeur fθ est conservé pour produire l'embedding final de faible dimension.En pratique, l'apprentissage contrastif supervisé (SupCon) est utilisé. Il exploite des données d'entraînement étiquetées pour créer des paires positives issues de la même classe et des paires négatives issues de classes différentes, la fonction de perte étant la perte SupCon. Des stratégies d'augmentation des données peuvent être conçues en intégrant des connaissances du domaine afin de compléter la construction des paires positives. De plus, une perte d'entropie croisée supervisée (LCE) peut être ajoutée, ce qui donne une perte totale de L = LSupCon + λCELCE (où λCE varie de 0,1 à 0,5 pour éviter que l'objectif de classification ne devienne prépondérant).
La phase de découverte utilise les représentations de faible dimension obtenues à l'étape précédente dans le cadre NPLM (New Physics Learning Machine) pour la détection d'anomalies et la vérification d'hypothèses.Rechercher d'éventuels « signaux nouveaux » dans les données de recherche et quantifier leur importance par des tests statistiques.
Dans cette phase, les chercheurs utilisent des vecteurs d'intégration fθ pour traiter des jeux de données inédits et rechercher des regroupements anormaux, des distorsions de densité ou des valeurs aberrantes s'écartant de la distribution de fond dans un espace de faible dimension. Le processus de recherche emploie une approche classique de test d'hypothèse scientifique : il compare un jeu de données de référence R, composé d'un fond connu, à un jeu de données observé D, de composition inconnue, afin d'accepter ou de rejeter l'hypothèse nulle selon laquelle R et D ont la même distribution. Cette hypothèse est testée à l'aide de l'algorithme NPLM (basé sur le test du rapport de vraisemblance classique proposé par Neyman et al.).Combiné à des vecteurs d'intégration appris expressifs, ce modèle devient extrêmement sensible aux nouveaux signaux.
Il est important de noter que la réduction de dimensionnalité lors du pré-entraînement est cruciale, car l'efficacité de toute méthode de test statistique, y compris NPLM, diminue considérablement avec l'augmentation de la dimensionnalité des données. Autrement dit, une dimensionnalité plus élevée exige un échantillon plus grand pour détecter des signaux faibles statistiquement significatifs, or, en pratique, la taille des échantillons est souvent insuffisante pour répondre à ces exigences. Par conséquent, seule la compression des données de grande dimension permet à des outils comme NPLM de fonctionner efficacement, de détecter des anomalies statistiquement significatives et, ainsi, d'accroître leur valeur scientifique.
Résultats expérimentaux : Des comparaisons multidimensionnelles et à large spectre mettent en évidence la transférabilité et les capacités interdomaines d’AutoSciDACT
Les chercheurs ont entraîné et évalué AutoSciDACT sur chaque ensemble de données en utilisant la même méthode, n'effectuant que des ajustements mineurs lors de la phase de pré-entraînement pour répondre aux besoins spécifiques de chaque ensemble de données.
Tous les encodeurs ont une dimension d'intégration de d=4. Les résultats d'intégration sont visualisés comme indiqué dans la figure ci-dessous.De plus, l'expérience a établi trois types de points de comparaison, notamment un point de comparaison supervisé, un point de comparaison supervisé idéal et la ligne de base de Mahalanobis.
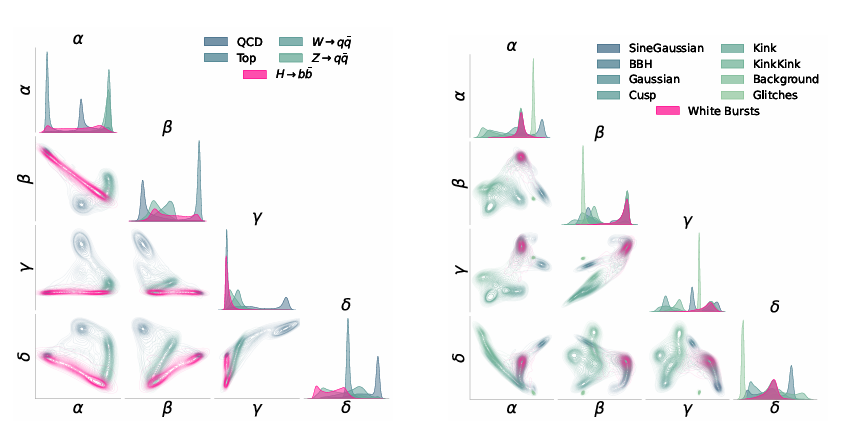
Comme le montre la figure ci-dessous, les résultats démontrent que NPLM peut détecter des biais hautement significatifs (Z ≳ 3 ou p ≲ 10⁻³) avec des proportions de signal aussi faibles que 11TP³T. Deux modèles de référence supervisés, avec une compréhension complète de la distribution du signal dans l'espace d'intégration, fournissent une limite supérieure raisonnable pour la sensibilité du signal, et dans certains cas, les performances de NPLM approchent cette limite. Au-delà d'environ 5σ, certaines tendances deviennent invalides, mais à ce niveau de signification (p ∼ 10⁻⁷), les résultats sont déterminés par l'algorithme.
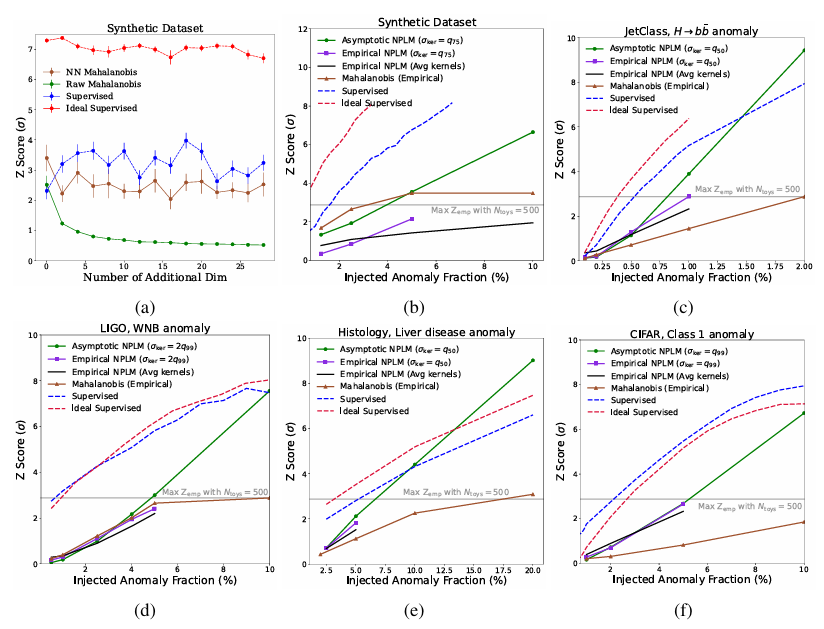
En plus des données synthétiquesDans tous les autres ensembles de données, NPLM surpasse significativement la distance de Mahalanobis de référence.Cela s'explique par sa capacité à modéliser diverses distorsions dans l'espace d'entrée.
Pour les jeux de données LIGO et JETClass, la méthode proposée atteint la limite supérieure supervisée avec un score Z de 3, comparable voire supérieur à celui de tous les algorithmes de détection d'anomalies dans leurs domaines respectifs. Si l'astronomie et la physique des particules utilisent depuis longtemps des techniques de détection d'anomalies issues de l'évolution statistique, leur application à l'histologie démontre la transférabilité méthodologique entre les disciplines scientifiques.
En termes d'histologie,Les expériences montrent que l'espace d'intégration construit à partir des informations d'étiquetage est supérieur à l'espace d'intégration construit uniquement sur la base de l'augmentation des données.Grâce à AutoSciDACT, des chercheurs ont mis au point une nouvelle méthode permettant de détecter des anomalies localisées, parfois présentes uniquement dans de petites portions de tissus. Cette capacité est essentielle pour le dépistage précoce des maladies et pour guider les pathologistes dans l'identification des composés toxiques.
À l'ère de la croissance explosive des données, les « scientifiques de l'IA » sont devenus une réalité.
La vague de l'IA déferle, menaçant de tout bouleverser. L'exploration scientifique, fer de lance de la recherche, subit des transformations sans précédent grâce à l'IA, devenant un domaine central profondément remodelé par cette révolution.
En plus d'AutoSciDACT mentionné dans l'article susmentionnéDans le même domaine, des équipes de Google, de l'université de Stanford et d'autres institutions ont également proposé des co-chercheurs IA capables d'imiter les scientifiques humains.Il peut générer des idées, discuter, questionner, optimiser et améliorer, tout comme un humain. Plus précisément, il s'agit d'un système multi-agents basé sur Gemini 2.0 qui aide les scientifiques à découvrir des connaissances nouvelles et originales et, en s'appuyant sur les données existantes et en tenant compte des objectifs de recherche et des orientations fournies par Science Journal, à proposer des hypothèses et des solutions de recherche innovantes et vérifiables.
Titre de l'article :Vers un co-chercheur en IA
Adresse du document :https://arxiv.org/abs/2502.18864
De plus, la capacité de l'IA à mener des recherches scientifiques ne cesse de s'étendre, passant même de la « réflexion automatique sur la recherche sur les électrons » à la « rédaction d'articles scientifiques complets ». Une équipe des universités d'Oxford et de Columbia a proposé un tel scientifique doté d'IA.Il s'agit du premier cadre global pour la découverte scientifique entièrement automatisée.Cela permet à des modèles de langage complexes de mener des recherches de manière autonome et de diffuser leurs résultats. En d'autres termes, cet expert en intelligence artificielle peut générer des idées de recherche novatrices, écrire du code, réaliser des expériences, visualiser les résultats, décrire ses conclusions dans des articles scientifiques complets, puis simuler un processus d'évaluation par les pairs.
Titre de l'article :Le scientifique IA : vers une découverte scientifique ouverte et entièrement automatisée
Adresse du document :https://arxiv.org/abs/2408.06292
Au cours du premier semestre de cette année, AI Scientist a bénéficié d'une mise à jour majeure, devenant AI Scientist-v2. Par rapport à sa version précédente,AI Scientist-v2 ne dépend plus de modèles de code portables par l'humain ; il peut généraliser efficacement à différents domaines d'apprentissage automatique.Ce système utilise une méthode novatrice de recherche arborescente par agents progressifs, gérée par un agent dédié à la gestion des essais cliniques. Il intègre une boucle de rétroaction basée sur un modèle visuel et linguistique (VLM) afin d'améliorer le composant d'évaluation par IA, optimisant ainsi itérativement le contenu et l'esthétique des graphiques. Les chercheurs ont évalué AI Scientist-v2 en soumettant trois manuscrits entièrement rédigés par eux-mêmes à un atelier ICLR avec évaluation par les pairs, obtenant des résultats très positifs. L'un de ces manuscrits a obtenu un score suffisamment élevé pour dépasser le seuil moyen des évaluations humaines, une première pour un article entièrement généré par IA lors d'une évaluation par les pairs.
Titre de l'article :L'IA scientifique v2 : Découverte scientifique automatisée au niveau de l'atelier via la recherche arborescente agentique
Adresse du document :https://arxiv.org/abs/2504.08066
Il est clair que l'IA et l'exploration scientifique s'intègrent et évoluent profondément, passant de l'aide à la formulation d'hypothèses à la recherche scientifique entièrement autonome, et de la vérification dans un domaine spécifique à une vaste application interdisciplinaire. Ces systèmes permettent non seulement de surmonter les obstacles à l'efficacité de la recherche scientifique traditionnelle, mais aussi de transformer cette dernière, d'une approche « axée sur l'expérience » à une approche « axée sur les données ». À l'avenir, grâce à la mise en œuvre du modèle de collaboration homme-machine, l'IA ouvrira un nouveau chapitre de découvertes efficaces pour la communauté scientifique, tout en insufflant un nouvel élan au progrès de la civilisation mondiale.








