Command Palette
Search for a command to run...
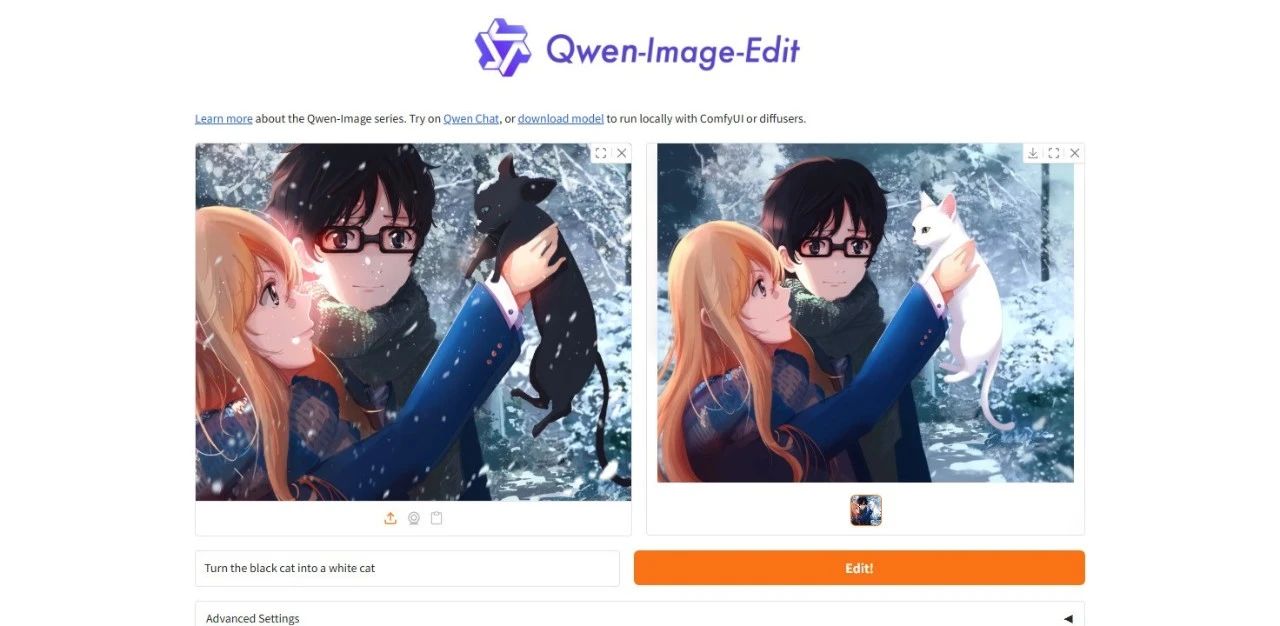
La Nouvelle Référence En Matière De Retouche d'images ! Qwen-Image-Edit Combine Des Fonctionnalités d'édition Sémantique Et d'apparence ; Granary Résout Le Problème De Pénurie De Données Pour Les Modèles Multilingues En 25 langues européennes.

À mesure que les modèles d'images continuent de se développer et de mûrir, la demande des utilisateurs pour l'utilisation de grands modèles ne se limite plus à la génération d'une seule image, et ils espèrent également apporter des modifications plus détaillées et contrôlables aux images existantes. « L’édition » est une exigence d’utilisation plus détaillée et microscopique que « la génération ».Les logiciels d'édition d'images traditionnels (tels que Photoshop) ont un certain seuil d'utilisation et nécessitent souvent que les utilisateurs effectuent un apprentissage systématique ; et les applications d'IA d'édition d'images existantes peuvent être améliorées à la fois en termes de fonctions et d'effets, en particulier en termes de rendu de texte et de capacités d'édition.
Sur cette base,L'équipe d'Alitong Yiqianwen a publié le modèle d'édition d'image complet Qwen-Image-Edit, qui possède une double capacité d'édition de sémantique et d'apparence.Il peut non seulement comprendre avec précision l'intention d'instruction de l'édition d'apparence, mais également effectuer une édition sémantique visuelle avancée tout en maintenant la cohérence du style visuel de l'image.Ce modèle étend également les excellentes capacités de rendu de texte chinois de Qwen-Image au domaine de l'édition d'images, permettant une édition précise du texte dans les images.
En tant que nouvelle version de Qwen-Image, Qwen-Image-Edit améliore la boucle fermée depuis la génération d'images, l'édition en chaîne jusqu'à la présentation de l'effet final, améliorant considérablement la convivialité des images.Les évaluations sur plusieurs benchmarks publics démontrent des performances de pointe dans les tâches d'édition d'images.
Le site officiel d'HyperAI a lancé « Qwen-Image-Edit : Démo du modèle d'édition d'images tout-en-un ». Venez l'essayer !
Utilisation en ligne:https://go.hyper.ai/nmjYo
Du 18 au 22 août, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 4
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en août : 2
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de reconnaissance vocale et de traduction Granary European
Granary est un vaste ensemble de données vocales multilingues publié par NVIDIA, conçu pour fournir du matériel d'entraînement et d'évaluation de haute qualité pour les modèles ASR/AST multilingues. Cet ensemble de données contient environ un million d'heures de données vocales ASR pseudo-étiquetées de haute qualité, couvrant 25 langues européennes.
Utilisation directe :https://go.hyper.ai/D3926
2. Ensemble de données de référence M3-Bench pour les questions-réponses vidéo longues
M3-Bench, un jeu de données de référence de questions-réponses vidéo longue durée publié par l'équipe ByteDance Seed, est conçu pour évaluer la mémoire à long terme et les capacités de raisonnement des agents multimodaux. Ce jeu de données contient 1 020 échantillons vidéo, chacun incluant des sous-titres, des résultats intermédiaires et des graphiques de mémoire.
Utilisation directe :https://go.hyper.ai/LIHsO
3. Ensemble de données vocales à large bande passante à grande échelle HiFiTTS-2
HiFiTTS-2 est un ensemble de données vocales à large bande passante, à grande échelle, conçu pour soutenir l'apprentissage et l'évaluation de modèles de synthèse vocale (TTS) de haute qualité. Cet ensemble de données contient des métadonnées audio de 5 000 locuteurs, soit environ 36 700 heures d'enregistrements vocaux en anglais à 22,05 kHz et 31 700 heures à 44,1 kHz, organisées en strates selon la qualité de la bande passante et la fréquence d'échantillonnage.
Utilisation directe :https://go.hyper.ai/XZwDD
4. Ensemble de données de questions-réponses visuelles culturelles multilingues CulturalGround
CulturalGround est un jeu de données visuelles multilingues et multimodales de questions-réponses pour l'alignement des connaissances culturelles, publié par NeuLab de l'Université Carnegie Mellon. Il vise à améliorer les capacités de compréhension et de raisonnement des grands modèles linguistiques multimodaux pour les entités culturelles de niche et les langues à faibles ressources.
Utilisation directe :https://go.hyper.ai/wayAA
5. Ensemble de données sur les préférences humaines HPDv3
HPDv3 est le premier ensemble de données à large spectre sur les préférences humaines publié par MizzenAI et MMLab de l'Université chinoise de Hong Kong. L'article associé a été sélectionné pour l'ICCV 2025. Cet ensemble de données est conçu pour l'alignement, la permutation et l'évaluation de modèles de génération de texte en image, afin de favoriser l'alignement des modèles avec l'esthétique humaine et d'améliorer la cohérence sémantique.
Utilisation directe :https://go.hyper.ai/xV8fK
6. Ensemble de données de référence COREVQA pour les questions visuelles
COREVQA, un jeu de données de référence de questions-réponses visuelles publié par l'Algoverse AI Research Center, est conçu pour évaluer les capacités de raisonnement des modèles de langage visuel (MLV) dans des scènes de foule. Ce jeu de données présente principalement des scènes réelles de foule, mettant l'accent sur des problèmes tels que l'occlusion, les changements de perspective et les interférences d'arrière-plan. Il vise à améliorer la perception fine et les capacités de raisonnement des MLL dans des scénarios sociaux complexes.
Utilisation directe :https://go.hyper.ai/tOFNw
7. Ensemble de données de segmentation de profondeur et d'obstacles DDOS pour drones
DDOS est un jeu de données d'imagerie aérienne synthétique conçu pour faire progresser le développement d'algorithmes pour l'autonomie des drones. Ce jeu de données est soigneusement classé par type d'environnement. L'ensemble d'entraînement comprend 300 vols, totalisant 30 000 images ; l'ensemble de validation comprend 20 vols, totalisant 2 000 images ; et l'ensemble de test comprend 20 vols, totalisant 2 000 images.
Utilisation directe :https://go.hyper.ai/XRE6R

8. Ensemble de données de raisonnement multi-domaines Nemotron
Nemotron est un jeu de données de raisonnement multi-domaines publié par NVIDIA, conçu pour améliorer l'efficacité et la précision du raisonnement du modèle Llama. Ce jeu de données contient 25,66 millions d'échantillons couvrant cinq catégories : conversation, code, mathématiques, STEM et appels d'outils.
Utilisation directe :https://go.hyper.ai/WP2Ym
9. Ensemble de données de référence de documents multimodaux Document Haystack
Document Haystack est un jeu de données de référence documentaire multimodal publié par Amazon AGI. Il contient 400 variantes de documents et 8 250 questions de recherche. Il vise à évaluer les capacités de recherche et de compréhension d'informations des modèles de langage visuel (MLV) dans des documents contextuels longs et complexes.
Utilisation directe :https://go.hyper.ai/Q08Xt
10. Ensemble de données audio émotionnelles CSEMOTIONS
CSEMOTIONS est un ensemble de données audio émotionnelles conçu pour soutenir la recherche sur la contrôlabilité et la génération de parole en langage naturel. Cet ensemble contient environ 10 heures de données audio de haute qualité, couvrant sept catégories émotionnelles, dont le calme, la joie et la colère, enregistrées par 10 comédiens voix off professionnels.
Utilisation directe :https://go.hyper.ai/4fe7A
Tutoriels publics sélectionnés
1. Déploiement vLLM + Open-WebUI janvier-v1-4B
Jan-v1-4B est un modèle de langage open source de 4 milliards de paramètres publié par l'équipe Jan. Destiné au raisonnement intelligent basé sur le corps et à l'invocation d'outils, il s'agit de la première version de la famille Jan, optimisée pour les scénarios de workflow réels des applications Jan. Basé sur Qwen3-4B-Thinking-2507, ce modèle a été peaufiné et étendu, atteignant une précision de 91,1% sur le benchmark SimpleQA, démontrant ainsi des améliorations significatives de performances grâce à l'extension et au réglage du modèle.
Exécutez en ligne :https://go.hyper.ai/CZf3s
2. Tutoriel sur la classification et la prédiction des données de diagnostic du cancer du sein par apprentissage automatique
Ce tutoriel, basé sur l'ensemble de données de diagnostic du cancer du sein du Wisconsin (WDBC), illustre l'intégralité du processus d'apprentissage automatique pour un problème de classification binaire. Il vous aide à comprendre la logique fondamentale de la sélection des caractéristiques, du réglage du modèle et de la visualisation des résultats, fournissant ainsi une référence pour la modélisation du diagnostic d'autres maladies.
Exécutez en ligne :https://go.hyper.ai/zFjil
3. Qwen-Image-Edit : Démonstration d'un modèle d'édition d'images polyvalent
Qwen-Image-Edit est un modèle complet d'édition d'images développé par l'équipe Alibaba Tongyi Qianwen. Il combine des fonctionnalités d'édition sémantique et visuelle, prend en charge l'édition précise de texte en chinois et en anglais, et permet de modifier le texte des images tout en préservant la police, la taille et le style d'origine.
Exécutez en ligne :https://go.hyper.ai/nmjYo
4. Déploiement en un clic de Qwen3-4B-2507
Qwen3-4B-Thinking-2507 et Qwen3-4B-Instruct-2507 sont des modèles de langage de grande taille développés par l'équipe Alibaba Tongyi Qianwen. En termes de performances, Qwen3-4B-Thinking-2507 surpasse nettement le modèle Qwen3 de taille similaire, plus petit, en termes de raisonnement sur des problèmes complexes, de capacités mathématiques, de codage et d'appels de fonctions multi-tours. Dans les domaines non liés au raisonnement, Qwen3-4B-Instruct-2507 surpasse largement le modèle GPT-4.1-nano à petite échelle et à code source fermé en termes de connaissances, de raisonnement, de programmation, d'alignement et de capacités d'agent, et se rapproche des performances du modèle Qwen3-30B-A3B de taille moyenne (non lié à la pensée).
Exécutez en ligne :https://go.hyper.ai/HiqSR
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. DINOv3
Ce rapport technique présente DINOv3, qui génère des caractéristiques denses de haute qualité et offre des performances exceptionnelles pour un large éventail de tâches de vision, surpassant largement les modèles de référence auto-supervisés et faiblement supervisés précédents. Les chercheurs ont également publié la famille de modèles de vision DINOv3, visant à faire progresser l'état de l'art pour un large éventail de tâches et d'ensembles de données en fournissant des solutions évolutives permettant de répondre à diverses contraintes de ressources et scénarios de déploiement.
Lien vers l'article :https://go.hyper.ai/tBuYx
2. Rapport technique Ovis2.5
Cet article présente Ovis2.5, successeur d'Ovis2, conçu pour la perception visuelle en résolution native et un puissant raisonnement multimodal. Ovis2.5 intègre un transformateur visuel en résolution native qui traite les images directement à leur résolution native variable, évitant ainsi la dégradation de qualité associée à la segmentation à résolution fixe, tout en préservant pleinement les détails fins et la présentation globale.
Lien vers l'article :https://go.hyper.ai/jlEXl
3. SSRL : Apprentissage par renforcement de la recherche personnelle
Des chercheurs étudient le potentiel des grands modèles de langage (LLM) comme simulateurs efficaces pour les tâches de recherche d'agents en apprentissage par renforcement (RL), réduisant ainsi la dépendance aux interactions coûteuses avec des moteurs de recherche externes. Des évaluations empiriques démontrent que les modèles de politiques entraînés avec SSRL offrent un environnement économique et stable pour l'apprentissage par renforcement basé sur la recherche, réduisant considérablement la dépendance aux moteurs de recherche externes et facilitant un transfert robuste de la simulation à la réalité.
Lien vers l'article :https://go.hyper.ai/4TFRe
4. Thym : Pensez au-delà des images
Étant donné qu'aucun travail open source n'offre actuellement un ensemble de fonctionnalités comparable à celui des modèles propriétaires, cet article mène une exploration préliminaire dans cette direction et propose Thyme (Think Beyond Images), qui permet aux modèles multimodaux de grand langage (MLLM) d'aller au-delà des méthodes existantes de « réflexion par les images » et de générer et d'exécuter de manière autonome diverses opérations de traitement d'images et de calcul via du code exécutable.
Lien vers l'article :https://go.hyper.ai/ZhLMI
5. Chaîne d'agents : modèles de fondation d'agents de bout en bout via la distillation multi-agents et l'apprentissage par renforcement agentique
La plupart des systèmes multi-agents existants reposent sur des invites personnalisées ou une ingénierie des flux de travail et reposent sur des structures d'agents complexes, ce qui entraîne une inefficacité informatique, des capacités limitées et l'impossibilité de tirer parti de l'apprentissage centré sur les données. Cette recherche propose la chaîne d'agents (CoA), un nouveau paradigme de raisonnement LLM qui permet nativement la résolution de problèmes complexes de bout en bout au sein d'un modèle unique, en utilisant les mêmes mécanismes que les systèmes multi-agents.
Lien vers l'article :https://go.hyper.ai/5m3gV
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Une équipe conjointe de l'Université d'Oxford et d'autres universités a proposé une méthode RAG basée sur des graphes spécifiquement destinée au domaine médical : Medical GraphRAG. Cette méthode améliore efficacement les performances des masters en droit (LLM) en médecine en générant des réponses fondées sur des données probantes et des explications terminologiques médicales officielles.
Voir le rapport complet :https://go.hyper.ai/3458z
L'équipe Tongyi Qianwen continue d'enrichir sa matrice de modèles open source, en se concentrant sur l'innovation architecturale, l'amélioration de l'efficacité et les avancées dans les scénarios d'analyse approfondie, obtenant des performances comparables à celles des leaders du secteur. La section « Tutoriels » du site officiel d'HyperAI a publié plusieurs tutoriels sur les modèles open source Tongyi.
Voir le rapport complet :https://go.hyper.ai/JKJTY
Une équipe de l'Université Cornell a proposé un circuit intégré appelé réseau neuronal micro-ondes (MNN), capable de traiter simultanément des données à très haut débit et des signaux de communication sans fil. Grâce à sa faible consommation d'énergie et à sa petite taille, il offre une nouvelle solution pour les applications à large bande passante.
Voir le rapport complet :https://go.hyper.ai/Cki2I
Lors de l'École d'été 2025 sur l'IA pour la bio-ingénierie de l'Université Jiao Tong de Shanghai, la professeure Zhuang Yingping de l'Université des sciences et technologies de Chine orientale a partagé son point de vue sur « L'IA au service des processus de biofabrication efficaces ». Elle a présenté le système technique et les réalisations de l'équipe sous trois angles : la relation entre la biofabrication et la biologie synthétique, les domaines d'application des produits issus de la biologie synthétique, et les technologies et pratiques de biofabrication intelligente.
Voir le rapport complet :https://go.hyper.ai/LgKcG
Afin de promouvoir l'application généralisée de l'intelligence artificielle dans le domaine de l'ingénierie des protéines, le groupe de recherche du professeur Hong Liang à l'Université Jiao Tong de Shanghai a développé un banc d'essai d'ingénierie des protéines open source à guichet unique, VenusFactory, pour intégrer la récupération de données biologiques, l'analyse comparative des tâches standardisées et les modèles de langage protéique pré-entraînés.
Voir le rapport complet :https://go.hyper.ai/p3llU
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :https://go.hyper.ai/wiki

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








