Command Palette
Search for a command to run...
MiniCPM-V 4.0 Surpasse GPT-4.1-mini En Termes De Performances, Atteignant De Nouveaux Sommets Dans La Modélisation d'images Sur Appareil ; HelpSteer3 Rapproche Les Réponses De l'IA De La Pensée humaine.

L'évolution technologique des grands modèles linguistiques multimodaux (MLLM) stimule le développement de l'écosystème de l'IA. La demande des utilisateurs pour une interaction en temps réel sur les appareils mobiles, tels que les téléphones et les tablettes, connaît une croissance significative. Cependant, si les grands modèles traditionnels offrent d'excellentes performances, ils sont soumis à un grand nombre de paramètres, ce qui les rend difficiles à déployer et à exploiter sur les appareils, que ce soit en mobilité ou hors ligne.Les grands modèles en périphérie nécessitent toujours une prise en charge et une optimisation côté cloud lorsqu'ils sont impliqués dans certaines tâches complexes, et il existe encore une marge d'amélioration des performances en périphérie et des capacités multimodales.
Dans ce contexte,Le laboratoire de traitement du langage naturel de l'université Tsinghua et Mianbi Intelligence ont lancé conjointement le modèle de bout en bout à grande échelle et efficace MiniCPM-V 4.0.Ce modèle hérite non seulement des puissantes performances de compréhension d'images uniques, multi-images et vidéo de son prédécesseur, le MiniCPM-V 2.6, mais surpasse également les modèles grand public tels que GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct et InternVL2.5-8B en termes de compréhension d'images lors de l'évaluation OpenCompass. Il bénéficie également d'une réduction de paramètres de moitié, à 4,1 B, abaissant ainsi considérablement le seuil de déploiement.L'équipe de recherche a également ouvert simultanément des applications iOS pour iPhone et iPad, permettant aux utilisateurs de bénéficier de « capacités de niveau cloud et d'une efficacité de niveau périphérique » sur leurs téléphones.
En tant qu'exploration importante du MLLM côté terminal, MiniCPM-V 4.0 favorise le déploiement léger de terminaux pour ouvrir un espace de développement plus large et fournit un bon exemple pour l'expansion d'autres modalités telles que la voix et la vidéo vers les appareils périphériques.
Le site officiel d'HyperAI vient de lancer « MiniCPM-V4.0 : Modèle embarqué à grande échelle extrêmement efficace ». Venez l'essayer !
Utilisation en ligne:https://go.hyper.ai/pZ5aZ
Du 11 au 15 août, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 6
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en août : 2
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de problèmes mathématiques NuminaMath-LEAN
NuminaMath-LEAN est un ensemble de données de problèmes mathématiques publié conjointement par Numina et l'équipe Kimi. Il vise à fournir des énoncés formels et des preuves annotés manuellement pour l'entraînement et l'évaluation de modèles de démonstration automatisée de théorèmes. Cet ensemble de données contient 100 000 problèmes de compétitions mathématiques, dont ceux issus de compétitions prestigieuses telles que l'Olympiade internationale de mathématiques (IMO) et l'Olympiade américaine de mathématiques (USAMO).
Utilisation directe :https://go.hyper.ai/YSJM2
2. Ensemble de données de réglage des instructions de sécurité Trendyol
Trendyol est un ensemble de données de réglage d'instructions de sécurité conçu pour former des assistants IA avancés en cybersécurité défensive. Cet ensemble de données contient 53 202 exemples de réglage d'instructions couvrant plus de 200 domaines de cybersécurité, dont les menaces cloud natives, la sécurité IA/ML et d'autres défis de sécurité modernes. Il fournit un corpus de haute qualité pour la formation de modèles IA de sécurité défensive.
Utilisation directe :https://go.hyper.ai/hfxLQ
3. Ensemble de données de scènes intérieures 3D InteriorGS
InteriorGS est un jeu de données de scènes intérieures 3D conçu pour surmonter les limites des jeux de données de scènes intérieures existants en termes d'exhaustivité géométrique, d'annotation sémantique et de capacités d'interaction spatiale. Ce jeu de données fournit des représentations de diffusion gaussienne 3D de haute qualité, ainsi que des cadres de délimitation sémantiques et des cartes d'occupation au niveau de l'instance indiquant les zones accessibles aux agents.
Utilisation directe :https://go.hyper.ai/8pxTq
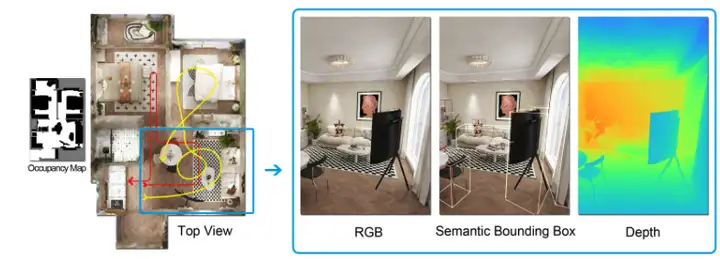
4. Ensemble de données de référence pour la génération de texte CognitiveKernel-Pro-Query
CognitiveKernel-Pro-Query est un jeu de données de référence de génération de texte publié par Tencent, conçu pour évaluer les performances des modèles lors du traitement de textes longs. Ce jeu de données contient plus de 10 000 textes longs, couvrant des scénarios d'application tels que des articles de presse, des documents techniques et des livres.
Utilisation directe :https://go.hyper.ai/onijU
5. Ensemble de données d'observation de la Terre intégrant des satellites
Satellite Embedding est un jeu de données d'observation de la Terre publié par Google. Il vise à fournir une représentation géospatiale très polyvalente, intégrant le contexte spatial, temporel et de mesure provenant de sources multiples pour générer avec précision et efficacité des cartes et des systèmes de surveillance, de l'échelle locale à l'échelle mondiale.
Utilisation directe :https://go.hyper.ai/Yfw8K

6. Ensemble de données de référence pour la compréhension de texte LongText-Bench
LongText-Bench est un jeu de données de référence pour la compréhension de textes, conçu pour évaluer la capacité des modèles à comprendre avec précision de longs passages de textes chinois et anglais. Ce jeu de données contient 160 invites pour évaluer des tâches de rendu de textes longs, couvrant huit scénarios différents (panneaux de signalisation, objets étiquetés, documents imprimés, pages web, diapositives, affiches, titres et dialogues).
Utilisation directe :https://go.hyper.ai/k6Kj8
7. Ensemble de données de conduite autonome nuPlan
nuPlan est un ensemble de données de conduite autonome publié par Motional. Il vise à fournir un cadre de développement et de formation de planificateurs basé sur l'apprentissage automatique, un simulateur léger en boucle fermée, des indicateurs de planification de mouvement dédiés et des outils interactifs de visualisation des résultats. Cet ensemble de données contient 1 200 heures de données de conduite humaine provenant de quatre villes des États-Unis et d'Asie : Boston, Pittsburgh, Las Vegas et Singapour.
Utilisation directe :https://go.hyper.ai/BcEC8

8. Ensemble de données sur les préférences humaines HelpSteer3
HelpSteer3 est un ensemble de données de préférences humaines publié par NVIDIA. Il vise à améliorer la réactivité des modèles aux sollicitations des utilisateurs grâce au retour d'information humain et aux techniques d'apprentissage par renforcement. Cet ensemble de données contient 40 476 exemples de préférences, chacun incluant un domaine, une langue, un contexte, deux réponses, une note de préférence globale entre les deux réponses et des notes de préférence individuelles provenant de trois annotateurs maximum.
Utilisation directe :https://go.hyper.ai/hByqe
9. Ensemble de données d'édition d'images NHR-Edit
NHR-Edit est un jeu de données d'édition d'images conçu pour soutenir l'entraînement de modèles d'édition d'images génériques capables de suivre diverses instructions d'édition naturelles. Ce jeu de données contient 286 608 images sources uniques et 358 463 triplets d'édition d'images. Chaque exemple contient également des métadonnées supplémentaires, telles que le type d'édition, le style et la résolution de l'image, ce qui le rend idéal pour l'entraînement de modèles d'édition d'images précis et contrôlables.
Utilisation directe :https://go.hyper.ai/LZtkd

10. Ensemble de données de conduite par temps violent A-WetDri
A-WetDri est un ensemble de données de conduite par temps violent, conçu pour améliorer la robustesse et la généralisation des modèles de perception de la conduite autonome dans des conditions météorologiques défavorables. Cet ensemble de données contient 42 390 échantillons répartis sur quatre scénarios environnementaux (pluie, brouillard, nuit, neige et temps clair) et diverses catégories d'objets (voitures, camions, vélos, motos, piétons, panneaux et feux de circulation).
Utilisation directe :https://go.hyper.ai/W2XE7

Tutoriels publics sélectionnés
1. MiniCPM-V4.0 : modèle de bout en bout à grande échelle extrêmement efficace
MiniCPM-V 4.0 est un modèle embarqué à grande échelle extrêmement efficace, développé en open source par le Laboratoire de traitement du langage naturel de l'Université Tsinghua et Mianbi Intelligence. Lors du test OpenCompass, MiniCPM-V 4.0 a surpassé GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct et InternVL2.5-8B en termes de compréhension d'images.
Exécutez en ligne :https://go.hyper.ai/pZ5aZ

2. Analyse exploratoire des données | Explication des valeurs SHAP de XGBoost
Ce tutoriel s'articule autour du problème de multi-classification de « prédiction de l'engrais optimal » et présente en détail le processus de bout en bout, de l'exploration des données à la formation du modèle jusqu'à l'analyse interprétable.
Exécutez en ligne :https://go.hyper.ai/41z6K
3. dots.ocr : modèle d'analyse de documents multilingues
dots.ocr est un modèle d'analyse de mise en page de documents multilingues développé par le laboratoire hi de Xiaohongshu. Basé sur un modèle de langage visuel (MLV) de 1,7 milliard de paramètres, il intègre la détection de mise en page et la reconnaissance de contenu, garantissant ainsi un ordre de lecture optimal. Ce modèle offre une architecture simple et efficace, ne nécessitant qu'une modification de l'invite de saisie pour changer de tâche. Sa vitesse d'inférence rapide le rend adapté à une variété de scénarios d'analyse de documents.
Exécutez en ligne :https://go.hyper.ai/JewLR

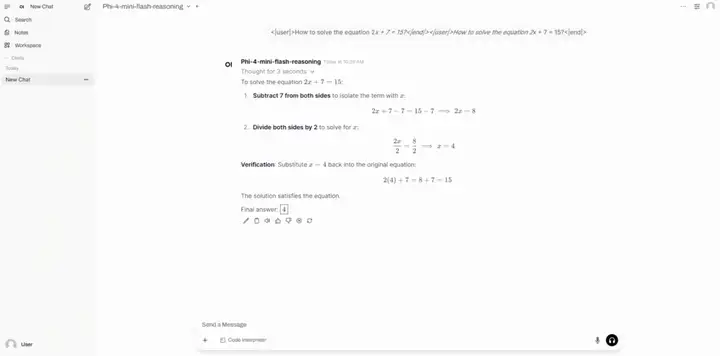
4. Déployer le raisonnement Phi-4-mini-flash à l'aide de vLLM+Open-WebUI
Phi-4-mini-flash-reasoning est un modèle open source léger publié par l'équipe Microsoft. Construit à partir de données synthétiques, il se concentre sur des données d'inférence denses et de haute qualité, et est affiné pour offrir des capacités de raisonnement mathématique plus avancées. Ce modèle, qui fait partie de la famille Phi-4, prend en charge des longueurs de contexte de jetons de 64 000 et utilise une architecture décodeur-décodeur hybride, combinée à un mécanisme d'attention et à un modèle d'espace d'état (SSM), pour une excellente efficacité d'inférence.
Exécutez en ligne :https://go.hyper.ai/ENYcL
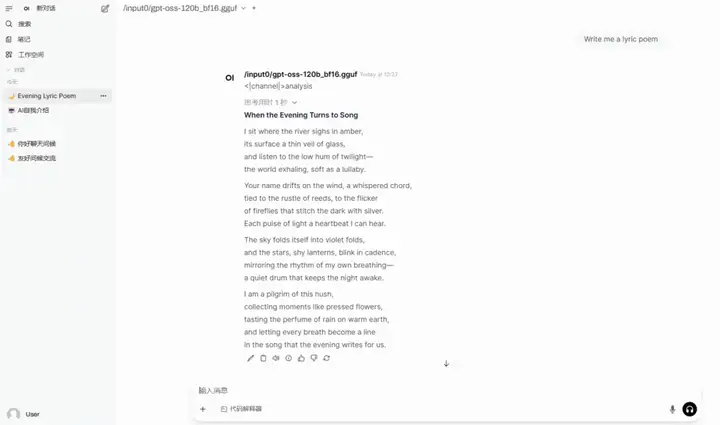
5. lama.cpp+Open-WebUI déploient gpt-oss-120b
gpt-oss-120b est un modèle de raisonnement open source publié par OpenAI, conçu pour le raisonnement fort, les tâches basées sur des agents et divers scénarios de développement. Basé sur l'architecture MoE, ce modèle prend en charge une longueur de contexte de 128 k et excelle dans l'invocation d'outils, les appels de fonctions à plusieurs coups, le raisonnement en chaîne et la réponse aux questions de santé.
Exécutez en ligne :https://go.hyper.ai/3BnDy
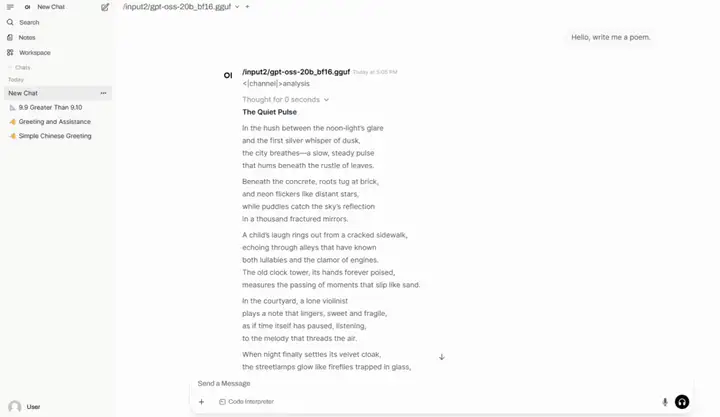
6. lama.cpp+Open-WebUI déploient gpt-oss-20b
gpt-oss-20b est un modèle d'inférence open source publié par OpenAI. Il convient aux applications verticales à faible latence, locales ou spécialisées. Il fonctionne parfaitement sur du matériel grand public (comme les ordinateurs portables et les périphériques), avec des performances comparables à celles de l'o3-mini.
Exécutez en ligne :https://go.hyper.ai/28FXJ
Recommandation de papier de cette semaine
1. ReasonRank : Optimiser le classement des passages grâce à une forte capacité de raisonnement
En raison de la rareté des données d'entraînement à forte intensité d'inférence, les rerankers existants sont peu performants dans de nombreux scénarios de classement complexes, et leurs capacités de classement en sont encore à leurs débuts. Cet article propose pour la première fois un cadre automatisé de synthèse de données d'entraînement à forte intensité d'inférence. Ce cadre extrait les requêtes et les paragraphes d'entraînement de plusieurs domaines et utilise le modèle DeepSeek-R1 pour générer des étiquettes d'entraînement de haute qualité. De plus, un mécanisme de filtrage des données auto-cohérent est conçu pour garantir la qualité des données.
Lien vers l'article :https://go.hyper.ai/nmaou
2. WideSearch : analyse comparative de la recherche d'informations à grande échelle par les agents
Cet article présente un nouveau benchmark, WideSearch, conçu pour évaluer la fiabilité des agents lors de tâches de collecte à grande échelle. Il comprend 200 questions soigneusement sélectionnées, issues de plus de 15 domaines différents et basées sur des requêtes réelles d'utilisateurs. Chaque tâche exige de l'agent qu'il collecte de grandes quantités d'informations atomiques et les organise en un résultat clairement structuré.
Lien vers l'article :https://go.hyper.ai/87pbh
3. WebWatcher : repousser les limites de l'agent de recherche approfondie vision-langage
Cet article présente WebWatcher, un agent multimodal de recherche approfondie doté de capacités de raisonnement vision-langage améliorées. Cet agent permet un apprentissage à froid efficace grâce à des trajectoires multimodales synthétiques de haute qualité, combine plusieurs outils de raisonnement profond et améliore encore la généralisation grâce à l'apprentissage par renforcement.
Lien vers l'article :https://go.hyper.ai/n9IKZ
4. Matrix-3D : Génération de mondes 3D explorables omnidirectionnels
Cet article propose le cadre Matrix-3D, qui utilise une représentation panoramique pour générer des mondes 3D à grande échelle et entièrement explorables. Il combine la génération vidéo conditionnelle avec des techniques de reconstruction 3D panoramique. Les chercheurs ont d'abord entraîné un modèle de diffusion vidéo panoramique guidé par trajectoire, conditionné par un rendu de maillage de scène, afin d'obtenir une génération vidéo de scène de haute qualité et géométriquement cohérente.
Lien vers l'article :https://go.hyper.ai/ojvKE
5. Voost : un transformateur de diffusion unifié et évolutif pour l'essai virtuel bidirectionnel
L'essayage virtuel vise à générer des images réalistes d'une personne portant un vêtement cible. Cependant, modéliser avec précision la correspondance entre le vêtement et le corps humain reste un défi persistant, notamment en présence de variations de pose et d'apparence. Dans cet article, nous proposons un framework unifié et évolutif, nommé Voost, qui apprend conjointement les tâches d'essayage et de désessayage virtuels via un seul transformateur de diffusion.
Lien vers l'article :https://go.hyper.ai/qCCaH
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Google DeepMind et Google Research ont conjointement lancé Perch 2.0, propulsant la recherche en bioacoustique vers de nouveaux sommets. Comparé à son prédécesseur, Perch 2.0 se concentre sur la classification des espèces comme tâche principale d'entraînement. Il intègre non seulement davantage de données d'entraînement provenant de groupes non aviaires, mais utilise également de nouvelles stratégies d'augmentation des données et de nouveaux objectifs d'entraînement. Cela a permis d'obtenir des résultats de pointe pour les benchmarks bioacoustiques BirdSET et BEANS.
Voir le rapport complet :https://go.hyper.ai/B7ZUk
Une équipe de recherche de l'Université de Pékin a proposé MediCLIP, une solution efficace de détection d'anomalies d'images médicales en quelques clichés. Ne nécessitant qu'un nombre minimal d'images médicales normales, cette méthode atteint des performances de pointe dans la détection et la localisation d'anomalies. Elle détecte efficacement différentes maladies sur un large éventail de types d'images médicales, démontrant ainsi d'impressionnantes capacités de généralisation en un seul cliché.
Voir le rapport complet :https://go.hyper.ai/VAhFb
Paper With Code a officiellement cessé ses activités, et des utilisateurs expérimentés du monde entier se sont exprimés. D'une part, ils ont salué l'intérêt du site web pour la recherche en apprentissage automatique et, d'autre part, ont exprimé de réels besoins : outre la correspondance entre les articles et les codes open source, des fonctionnalités telles que SOTA et les classements sont tout aussi importantes.
Voir le rapport complet :https://go.hyper.ai/poRWa
Pour résoudre le problème de la coloration histochimique dans l'imagerie par spectrométrie de masse, l'équipe de recherche de l'UCLA a proposé une méthode de coloration histologique virtuelle basée sur un modèle de diffusion, qui peut améliorer la résolution spatiale et introduire numériquement un contraste de morphologie cellulaire dans les images de spectrométrie de masse de tissus humains sans marquage, réalisant ainsi la prédiction de la structure pathologique des tissus cellulaires à haute résolution basée sur des données IMS à basse résolution.
Voir le rapport complet :https://go.hyper.ai/gcZ5U
Ainnova Tech, entreprise de technologies de la santé, a développé sa plateforme Vision AI, exploitant une technologie de diagnostic intelligent basée sur l'imagerie du fond d'œil. Cette plateforme permet de détecter la rétinopathie diabétique (avec une précision supérieure à 90,1 % TP3T), le risque cardiovasculaire et d'autres maladies multisystémiques en quelques secondes. Présente dans plus de 20 pays, Ainnova Tech a finalisé avec succès sa réunion de pré-soumission auprès de la FDA en juillet 2025 et a désormais lancé un modèle de dépistage gratuit en Amérique latine, stimulant ainsi l'innovation dans le diagnostic précoce des maladies chroniques.
Voir le rapport complet :https://go.hyper.ai/Ete2g
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
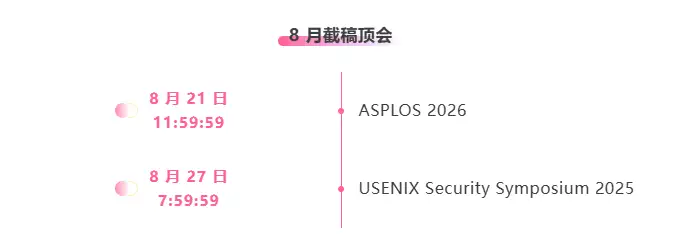
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








