Command Palette
Search for a command to run...
2,5 000 Questions ! HLE a Réalisé Une Avancée Majeure En Créant Un Système d'évaluation Précis Pour Les Grands Modèles linguistiques. Jan-Nano, Un Modèle Linguistique Léger Et Volumineux Avec 4 milliards De Paramètres, Est Conçu Pour Les Recherches approfondies.

Ces dernières années, les grands modèles linguistiques (LLM) ont réalisé des progrès considérables et sont désormais capables de gérer diverses tâches, telles que répondre à des questions et créer du contenu, démontrant ainsi leurs solides capacités. Les benchmarks sont des outils importants pour évaluer les capacités de développement des LLM et constituent une référence pour leur amélioration. Cependant, les benchmarks actuels, très répandus, manquent de difficulté, car les LLM de pointe ont obtenu des scores similaires et élevés lors de nombreuses évaluations existantes, ce qui limite la précision de la mesure des capacités des LLM et brouille les pistes d'amélioration des capacités des grands modèles.
Sur cette base, le Center for AI Safety et Scale AI ont publié conjointement l'ensemble de données de référence sur les problèmes humains multimodaux Humanity's Last Exam (HLE).Vise à construire le sceau ultime couvrant les frontières de la connaissance humaineFerméÉvaluersystème.Cet ensemble de données comprend 2 500 questions portant sur des dizaines de domaines et vise à fournir une norme de mesure des capacités LLM précise et efficace, à clarifier l'écart entre les capacités LLM actuelles et les universitaires professionnels, et à mieux parvenir à une amélioration rapide des capacités LLM dans les domaines de pointe de la connaissance.
Actuellement, le site officiel du HyperAI Super Neural Network a lancé le « HLE Human Problem Reasoning Benchmark Dataset », venez l'essayer~
Téléchargement du jeu de données :
Du 14 au 18 juillet, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 5
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juillet : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de raisonnement mathématique GSM8K
GSM8K est un ensemble de données de raisonnement mathématique publié par OpenAI en 2022. Il vise à améliorer les performances des modèles d'apprentissage automatique dans la compréhension et la résolution de problèmes mathématiques complexes. Cet ensemble de données contient 8 500 problèmes mathématiques élémentaires de haute qualité, rédigés dans différentes langues, couvrant l'algèbre, l'arithmétique, la géométrie et d'autres domaines. La résolution des questions comporte entre 2 et 8 étapes. La solution consiste principalement en une série de calculs simples utilisant des opérations arithmétiques de base (addition, soustraction, multiplication et division) pour obtenir la réponse finale.
Utilisation directe :https://go.hyper.ai/ZqNLt
2. Ensemble de données sur les maladies des cultures
Crops Disease est un ensemble de données d'images de maladies des cultures agricoles conçu pour faciliter le développement de modèles de vision par ordinateur permettant de détecter et de classer automatiquement les maladies de différentes cultures. Cet ensemble de données contient environ 1 300 images de maladies des cultures, couvrant des maladies courantes touchant diverses cultures (comme le maïs, les tomates, les pommes de terre, etc.), et chaque image est annotée avec une catégorie de maladie spécifique.
Utilisation directe :https://go.hyper.ai/GEDTA

3. Ensembles de données synthétiques multi-domaines OpenScience
OpenScience est un jeu de données synthétiques multi-domaines publié par NVIDIA en 2023. Il vise à améliorer la précision des benchmarks avancés tels que GPQA-Diamond et MMLU-Pro grâce à l'optimisation supervisée ou à l'apprentissage par renforcement. Ce jeu de données contient 6 millions de paires de questions-réponses à choix multiples avec des traces de raisonnement détaillées, couvrant de nombreux domaines scientifiques tels que les sciences, la technologie, l'ingénierie et les mathématiques (STEM), le droit, l'économie et les sciences humaines.
Utilisation directe :https://go.hyper.ai/YvAo7
4. Ensemble de données de raisonnement sur les problèmes de programmation mathématique Skywork-OR1-RL
Skywork-OR1-RL est un ensemble de données de raisonnement mathématique conçu pour entraîner le modèle de raisonnement mathématique Skywork-OR1 (Open Reasoner 1). Cet ensemble de données contient 105 000 problèmes mathématiques et 14 000 problèmes de programmation vérifiables, complexes et variés.
Utilisation directe :https://go.hyper.ai/mxoAv
5. Ensemble de données d'images de classification des espèces d'oiseaux
Bird Species est un jeu de données de classification d'images d'oiseaux adapté à l'entraînement de modèles de vision par ordinateur pour l'identification et la classification des espèces d'oiseaux. Ce jeu de données contient sept espèces différentes, chacune comportant 1 200 images. Les images de chaque espèce contiennent le motif du plumage, la couleur et la structure corporelle de l'oiseau concerné. Certaines images sont volontairement floues, inclinées ou contiennent deux oiseaux d'espèces différentes, ce qui accroît la complexité du monde réel et renforce la fiabilité du modèle pour une classification précise en milieu naturel.
Utilisation directe :https://go.hyper.ai/X2X2M

6. Ensemble de données d'édition de code NextCoder
NextCoder est un jeu de données d'édition de code de dialogue synthétique publié par Microsoft en 2025. Il permet d'affiner les modèles de langage volumineux afin d'améliorer leurs performances en matière de réparation, de refactorisation et d'optimisation de code. Il est particulièrement adapté à l'entraînement des assistants de programmation IA et à l'amélioration des capacités de lecture de code et d'interaction multi-tours. Ce jeu de données contient environ 381 000 échantillons d'instructions à tour unique (NextCoderDataset) et 57 000 échantillons de dialogues multi-tours (version conversationnelle), couvrant huit langages tels que Python et Java.
Utilisation directe :https://go.hyper.ai/e4MIs
7. Ensemble de données de questions-réponses sur les connaissances en psychologie Psych-101
Psych-101 est un ensemble de données de questions-réponses sur les connaissances psychologiques, conçu pour contribuer au développement de modèles de traitement du langage naturel pour ces tâches et promouvoir la recherche en IA liée à la psychologie, notamment dans l'enseignement de la psychologie, l'analyse des sentiments et les applications en santé mentale. Cet ensemble de données contient des données essai par essai issues de 160 expériences psychologiques et de 60 092 participants, totalisant 10 681 650 choix.
Utilisation directe :https://go.hyper.ai/NUshw
8. Ensemble de données d'images de leucémie
Leucémie est un ensemble de données d'images de cellules leucémiques conçu pour entraîner des modèles de vision par ordinateur à détecter et classer automatiquement les cellules leucémiques. Cet ensemble de données contient 6 778 images cellulaires, dont 3 389 de cellules normales et 3 389 de cellules leucémiques.
Utilisation directe :https://go.hyper.ai/Lwxwj
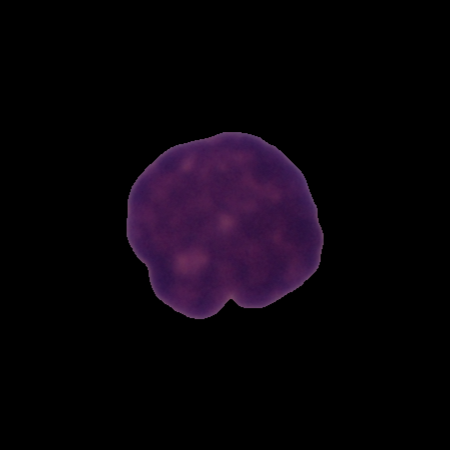
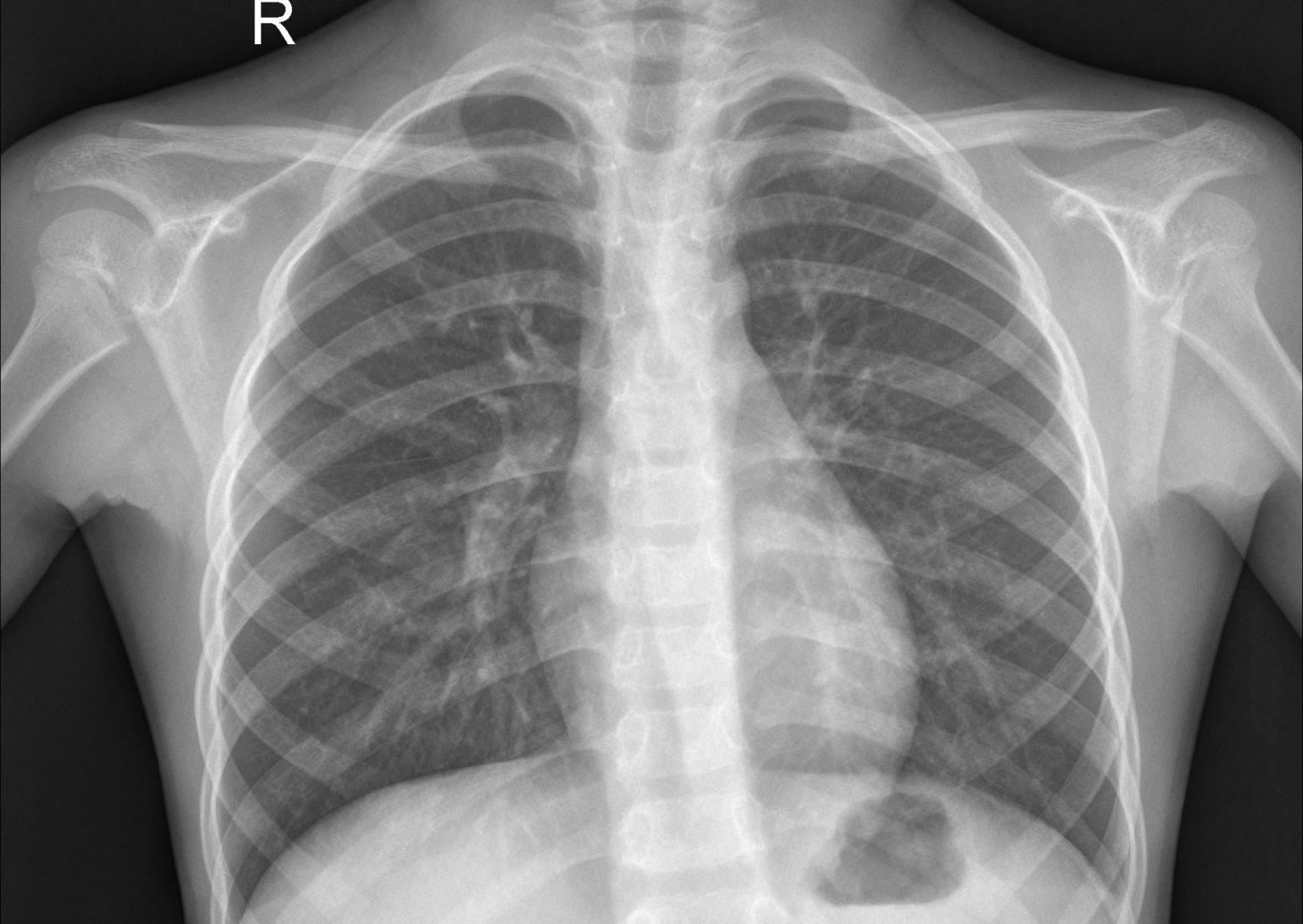
9. Ensemble de données d'images radiographiques sur la pneumonie thoracique
Les images radiographiques pour la pneumonie thoracique sont un ensemble de données conçu pour entraîner et évaluer des modèles de vision par ordinateur afin d'aider les systèmes de diagnostic automatisé à détecter des maladies respiratoires telles que la pneumonie. Cet ensemble de données contient environ 5 800 images radiographiques thoraciques réparties en deux catégories : normales et pneumonies (bactériennes et virales).
Utilisation directe :https://go.hyper.ai/Pgra4
10. Humidité du sol Ensemble de données d'images sur l'humidité du sol
Soil Moisture est un ensemble de données d'humidité du sol basé sur des mesures. Il vise à étudier son impact sur la croissance des cultures, à optimiser les systèmes d'irrigation et à améliorer l'efficacité de la production agricole. Il présente également d'importantes applications dans des domaines tels que le changement climatique et la gestion des ressources en eau. Cet ensemble de données contient 200 images de surface du sol provenant de la zone agricole pluviale de Bondowoso, en Indonésie.
Utilisation directe :https://go.hyper.ai/TtpgP

Tutoriels publics sélectionnés
Cette semaine, nous avons résumé 4 catégories de tutoriels publics de haute qualité :
*Tutoriels d'IA pour la science : 2
*Tutoriel de reconnaissance de texte : 1
*Tutoriel multimodal : 1
*Tutoriel grand modèle : 1
Tutoriel sur l'IA pour la science
1. RFdiffusion : un modèle de conception de protéines par diffusion
RFdiffusion est un framework de génération de structures protéiques : il utilise RoseTTAFold comme réseau principal et introduit le modèle de probabilité de diffusion débruité (DDPM) pour concevoir de nouvelles structures protéiques de A à Z. Ce framework permet de concevoir des protéines aux formes complexes (comme des hélices α et des replis β) et de prédire avec précision l'échafaudage du site catalytique des enzymes.
Exécutez en ligne :https://go.hyper.ai/q7Ajs
2. Biomni : Le premier agent biomédical général
Biomni est un agent d'IA biomédicale à usage général qui peut réaliser de manière autonome des tâches de recherche complexes dans plusieurs branches biomédicales telles que la génétique, la génomique, la microbiologie, la pharmacologie et la médecine clinique, marquant une nouvelle étape dans le développement de la découverte scientifique basée sur l'IA.
Exécutez en ligne :https://go.hyper.ai/aameS
Tutoriel sur la reconnaissance de texte
1. OCRFlux-3B : boîte à outils de reconnaissance de texte intelligente
OCRFlux-3B est une boîte à outils basée sur un modèle de langage multimodal étendu permettant de convertir des PDF et des images en texte Markdown clair, lisible et simple. Cet outil offre non seulement des fonctionnalités de conversion de texte au niveau de la page, mais prend également en charge la fusion de tableaux et de paragraphes entre pages, offrant ainsi une prise en charge performante pour le traitement de structures de documents complexes.
Exécutez en ligne :https://go.hyper.ai/BGqmR
Tutoriel multimodal
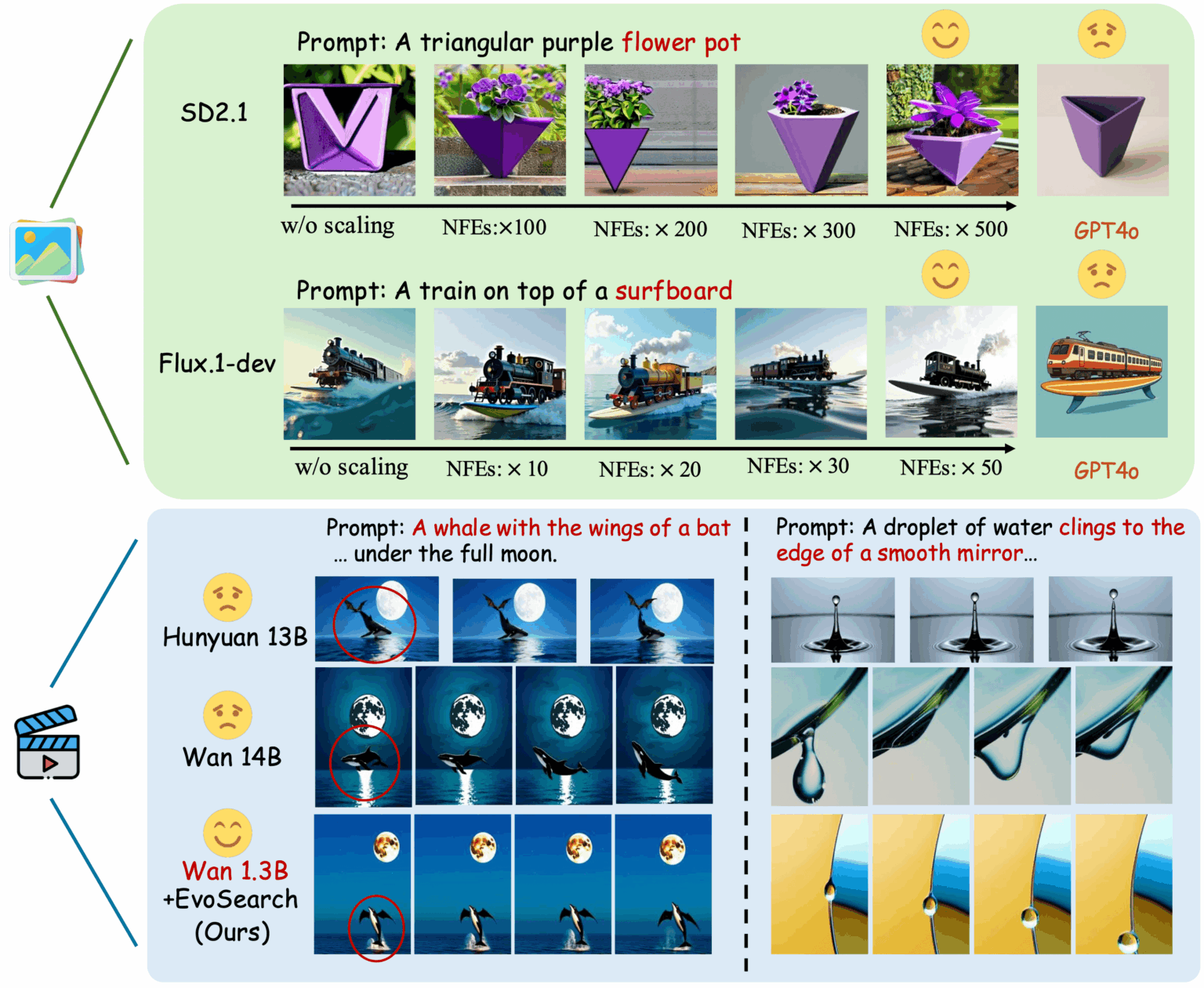
1. EvoSearch-codes : cadre d'algorithme évolutif
EvoSearch-codes est une méthode de recherche évolutive lancée par l'Université des sciences et technologies de Hong Kong et l'équipe Kuaishou Keling. Elle améliore considérablement la qualité de génération du modèle en augmentant la quantité de calculs lors de l'inférence, prend en charge la génération d'images et de vidéos, et s'adapte aux modèles de diffusion et de flux les plus avancés. Ce modèle peut obtenir des résultats optimaux significatifs sur une série de tâches sans entraînement ni mise à jour de gradient, et présente de bonnes capacités de mise à l'échelle, de robustesse et de généralisation.
Exécutez en ligne :https://go.hyper.ai/zjzrE
Tutoriel sur les grands modèles
1. Jan-Nano : un modèle de langage compact spécifique à la recherche
Jan-Nano est un modèle de langage léger de 4 milliards de paramètres publié par l'équipe de recherche Menlo le 1er juillet 2025. Il est conçu pour les tâches de recherche approfondie et optimisé pour le serveur Model Context Protocol (MCP) afin de faciliter une intégration efficace avec une variété d'outils de recherche et de sources de données.
Exécutez en ligne :https://go.hyper.ai/mC8gx
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. Mise à l'échelle du temps de test avec un modèle génératif réflexif
Cet article présente MetaStone-S1, le premier modèle génératif réflexif, qui atteint le niveau de performance d'OpenAI o3 grâce à un modèle de récompense de processus auto-supervisé (SPRM). En partageant le réseau fédérateur et en utilisant des têtes spécifiques à chaque tâche pour la prédiction du prochain jeton et la notation du processus, SPRM intègre avec succès le modèle de politique et le modèle de récompense de processus (PRM) dans une interface unifiée sans nécessiter d'annotations de processus supplémentaires, réduisant ainsi les paramètres du PRM de plus de 991 TP3T, permettant ainsi une inférence efficace.
Lien vers l'article :https://go.hyper.ai/zFLhf
2. Open Vision Reasoner : transfert du comportement cognitif linguistique au raisonnement visuel
Cet article propose un paradigme en deux étapes basé sur Qwen2.5-VL-7B : un premier réglage fin à grande échelle du langage par démarrage à froid, suivi de près de 1 000 étapes d'apprentissage par renforcement multimodal (RL), ce qui dépasse toutes les tentatives open source précédentes. Le modèle final, Open-Vision-Reasoner (OVR), atteint des performances de pointe sur une série de tests de raisonnement, notamment 95,31 TP3T sur MATH500, 51,81 TP3T sur MathVision et 54,61 TP3T sur MathVerse.
Lien vers l'article :https://go.hyper.ai/WucU8
3. Raisonnement ou mémorisation ? Résultats peu fiables de l'apprentissage par renforcement en raison de la contamination des données.
Les chercheurs ont constaté que, bien que Qwen2.5 soit performant en raisonnement mathématique, son pré-entraînement sur un corpus web à grande échelle le rend vulnérable à la contamination des données des benchmarks populaires, ce qui affecte la fiabilité des résultats obtenus. Pour résoudre ce problème, les chercheurs ont introduit un générateur capable de générer des problèmes arithmétiques entièrement synthétiques de longueur et de difficulté arbitraires, produisant ainsi un ensemble de données propre appelé RandomCalculation. Grâce à ces ensembles de données exempts de fuites, il est prouvé que seuls des signaux de récompense précis peuvent améliorer continuellement les performances, contrairement aux signaux bruités ou erronés.
Lien vers l'article :https://go.hyper.ai/WZp4V
4. NeuralOS : vers la simulation de systèmes d'exploitation via des modèles neuronaux génératifs
Cet article présente NeuralOS, un framework neuronal qui simule l'interface utilisateur graphique (GUI) d'un système d'exploitation en prédisant directement les images d'écran en réponse aux saisies utilisateur telles que les mouvements de souris, les clics et les actions clavier. NeuralOS combine un réseau neuronal récurrent (RNN) pour suivre l'état de l'ordinateur et un moteur de rendu neuronal par diffusion pour générer des images d'écran. Il ouvre la voie à la création d'interfaces neuronales entièrement adaptatives et génératives pour les futurs systèmes d'interaction homme-machine.
Lien vers l'article :https://go.hyper.ai/hceCb
5. CLiFT : jetons de champ lumineux compressifs pour un rendu neuronal adaptatif et efficace en termes de calcul
Dans cet article, nous proposons une méthode de rendu neuronal qui représente les scènes sous forme de « Jetons de Champ Lumineux Compressés » (CLiFT), préservant ainsi la richesse de l'apparence et de la géométrie de la scène. CLiFT permet un rendu performant grâce à l'utilisation de jetons compressés, tout en permettant de modifier le nombre de jetons dans un même réseau entraîné pour représenter la scène ou restituer de nouvelles perspectives.
Lien vers l'article :https://go.hyper.ai/aqzHX
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Une équipe de recherche conjointe de Meta FAIR, de l'Université de Cambridge et du MIT a proposé le Transformer ADiT à diffusion tout-atomique, qui a brisé les barrières de modélisation entre les systèmes périodiques et non périodiques. Grâce à deux innovations majeures, la représentation latente unifiée tout-atomique et la diffusion latente Transformer, cette équipe a réalisé une avancée majeure dans la génération de molécules et de cristaux à partir d'un modèle unique.
Voir le rapport complet :https://go.hyper.ai/Dnw5r
L'équipe de l'Université Stanford et l'Arc Institute de Palo Alto, en Californie, ont proposé conjointement une nouvelle méthode de conception de séquences protéiques, la FAMPNN (Full-Atom MPNN), capable de modéliser explicitement l'identité de séquence et la structure de la chaîne latérale de chaque résidu d'acide aminé. Ce modèle utilise une architecture de transmission de messages basée sur des réseaux neuronaux graphes, combinée à des modules MPNN et GVP améliorés pour le codage de l'atome complet, capables de traiter simultanément les informations de la chaîne principale et de la chaîne latérale des protéines.
Voir le rapport complet :https://go.hyper.ai/x04Am
L'Université de Stanford, en collaboration avec Genentech, l'Arc Institute, l'UCSF et d'autres institutions, a développé Biomni, le premier agent d'IA biomédicale généraliste. Ce dernier peut effectuer de manière autonome un large éventail de tâches de recherche dans différents sous-domaines biomédicaux et créer le premier agent environnemental unifié, exploitant les outils, bases de données et solutions nécessaires à partir de dizaines de milliers de publications dans 25 domaines biomédicaux. Les tests de performance du système montrent que Biomni atteint une forte généralisation dans des tâches biomédicales hétérogènes sans aucun réglage spécifique à la tâche.
Voir le rapport complet :https://go.hyper.ai/VHpMD
Le 5 juillet, le 7e salon Meet AI Compiler Technology, organisé par HyperAI, s'est conclu avec succès. Dong Zhaohua, directeur principal de Muxi Integrated Circuit, a expliqué en détail comment appliquer la TVM sur les GPU Muxi, présenté les caractéristiques techniques de ses produits GPU, les solutions d'adaptation des compilateurs TVM, des cas d'application concrets et une vision de construction écologique, et démontré les avancées technologiques et le potentiel d'application des GPU nationaux dans les domaines du calcul haute performance et de l'IA.
Voir le rapport complet :https://go.hyper.ai/rxxX3
L'équipe de recherche de NVIDIA, en collaboration avec Mila de l'Institut québécois d'intelligence artificielle (IQA), a proposé La-Proteina, une méthode de conception de protéines au niveau atomique basée sur l'appariement de flux latent partiel. Cette méthode s'attaque au défi majeur de la variabilité dimensionnelle des représentations explicites des chaînes latérales lors de la génération des protéines, apportant ainsi de nouvelles avancées dans le domaine de la conception des protéines.
Voir le rapport complet :https://go.hyper.ai/0Sw8R
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de juillet pour le sommet
11 juillet 7:59:59 POPL 2026
15 juillet 7:59:59 SODA 2026
18 juillet 7:59:59 SIGMOD 2026
19 juillet 7:59:59 ICSE 2026
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








