Command Palette
Search for a command to run...
Avec 2,6 000 Étoiles, MonkeyOCR-3B Surpasse Le Modèle 72B Dans La Tâche d'analyse De Documents Anglais Et Atteint Les Performances SOTA

Aujourd'hui, la technologie OCR (reconnaissance optique de caractères) ne se limite plus à la reconnaissance de texte, mais évolue progressivement vers un système d'analyse de documents plus complexe. De la simple extraction initiale de caractères au grand modèle multimodal apparu ces dernières années,L'OCR a été intégré dans des tâches telles que la compréhension de la mise en page, la reconnaissance sémantique et la restauration de la structure, et a été largement utilisé dans la reconnaissance de documents, la reconnaissance de sous-titres, le tri logistique, la recherche de littérature et d'autres domaines.Les scénarios d’application riches imposent également des exigences plus strictes au modèle.
Par exemple, la plupart des modèles OCR traditionnels adoptent une conception modulaire, ce qui nécessite de décomposer l'analyse des documents en plusieurs sous-tâches fines, ce qui est inefficace et difficile à optimiser uniformément. Bien que ce modèle complet soit puissant, il nécessite des ressources extrêmement importantes et est difficile à mettre en œuvre de manière universelle. Les documents complexes composés de multiples éléments tels que du texte, des tableaux, des expressions mathématiques et des graphiques intégrés constituent toujours un « grave préjudice » à la précision.
Compte tenu de cela,L'Université des sciences et technologies de Huazhong et Kingsoft Office ont lancé conjointement un modèle d'analyse de documents appelé MonkeyOCR.Il permet de convertir efficacement le contenu non structuré d'un document en informations structurées. Dans le cadre du paradigme SRR, l'analyse des documents se résume à trois questions fondamentales : où (structure), quoi (reconnaissance) et comment organiser (relation), qui correspondent respectivement à l'analyse de la mise en page, à la reconnaissance du contenu et au tri logique. Cette décomposition claire des tâches permet d'atteindre un équilibre entre précision et rapidité.Prend en charge un traitement efficace et évolutif sans compromettre la précision.
Afin de fournir un support de données suffisant pour le modèle, l’équipe de recherche a construit un ensemble de données appelé MonkeyDoc.Il s'agit de l'ensemble de données d'analyse de documents le plus complet à ce jour, contenant 3,9 millions d'instances et couvrant une variété de types de documents (tels que des notes, des PPT, des magazines, des documents d'examen, etc.).Parallèlement, différents blocs structurels (tableaux, images, textes, formules, etc.) sont également marqués en détail.
Selon les résultats expérimentaux de l’équipe de recherche, MonkeyOCR fonctionne bien lors du traitement de documents complexes, tels que ceux contenant des formules et des tableaux.Les performances des tâches d'analyse de formules et de tableaux ont été améliorées respectivement de 15,0% et 8,6%.Il dépasse également de loin les autres modèles en termes de vitesse de traitement de documents multipages, atteignant 0,84 page par seconde.
Il convient de noter que dans la tâche d'analyse de documents anglais, son modèle à 3 B paramètres surpasse le modèle standard à 72 B, et les performances moyennes atteignent le niveau SOTA. Aujourd'hui, MonkeyOCR a moins d'un mois et ses étoiles GitHub ont atteint 2 600.
« MonkeyOCR : analyse de documents basée sur le triple paradigme structure-reconnaissance-relation » a été lancé dans la section « Tutoriel » du site officiel HyperAI Super Neural (hyper.ai), venez le découvrir⬇️
Lien du tutoriel :
Essai de démonstration
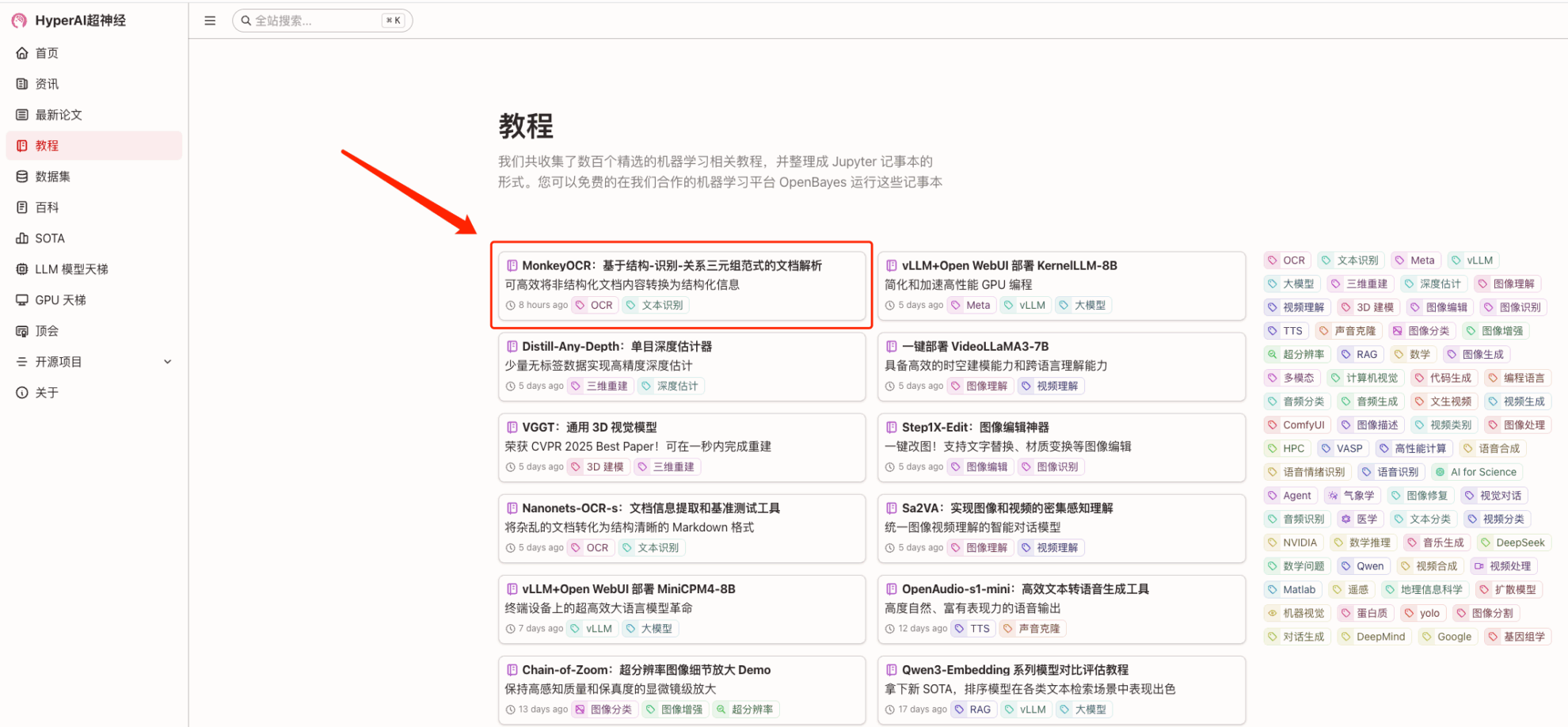
1. Après avoir accédé à la page d'accueil de hyper.ai, sélectionnez la page « Tutoriel », sélectionnez « MonkeyOCR : Analyse de documents basée sur le triple paradigme structure-reconnaissance-relation » et cliquez sur « Exécuter ce tutoriel en ligne ».
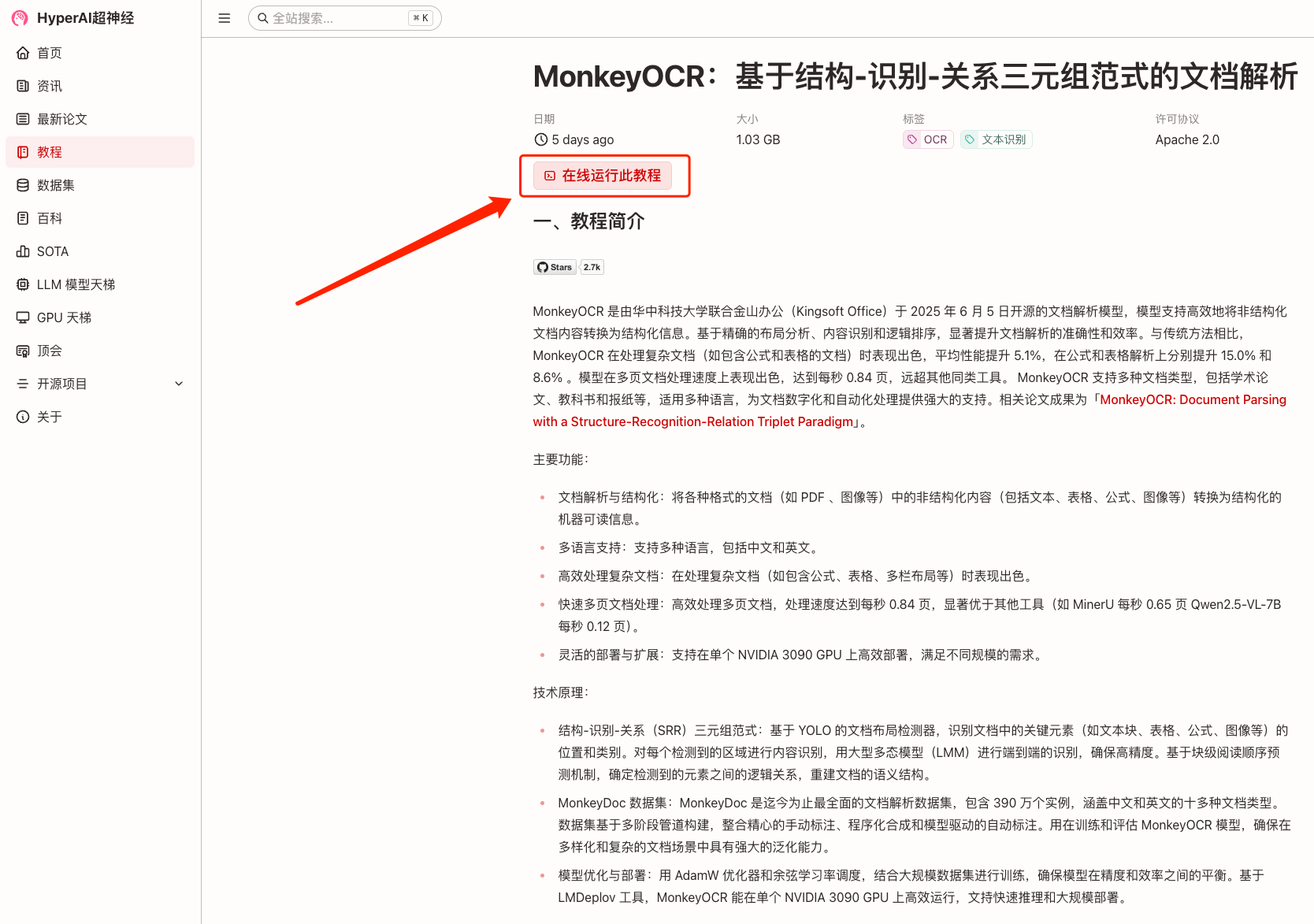
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
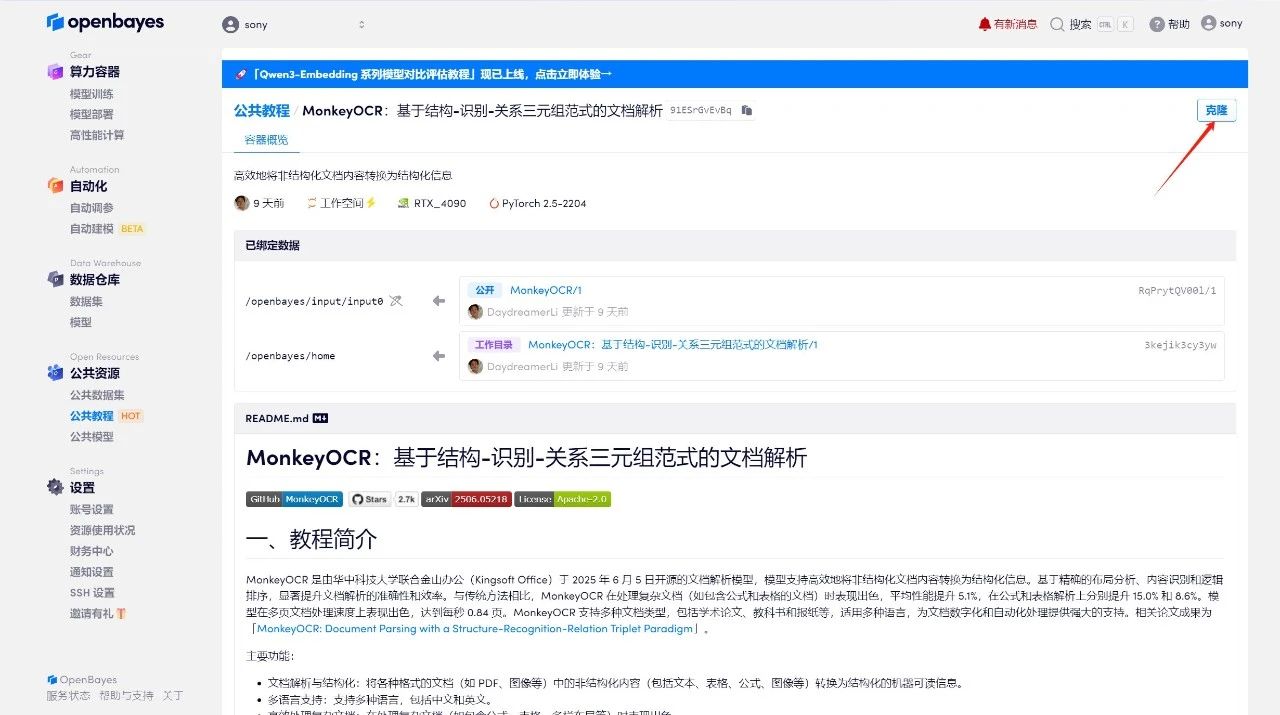
3. Sélectionnez les images « NVIDIA GeForce RTX 4090 » et « PyTorch ». La plateforme OpenBayes propose quatre méthodes de facturation. Vous pouvez choisir « Payer au fur et à mesure » ou « Quotidien/Hebdomadaire/Mensuel » selon vos besoins. Cliquez sur « Continuer ». Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
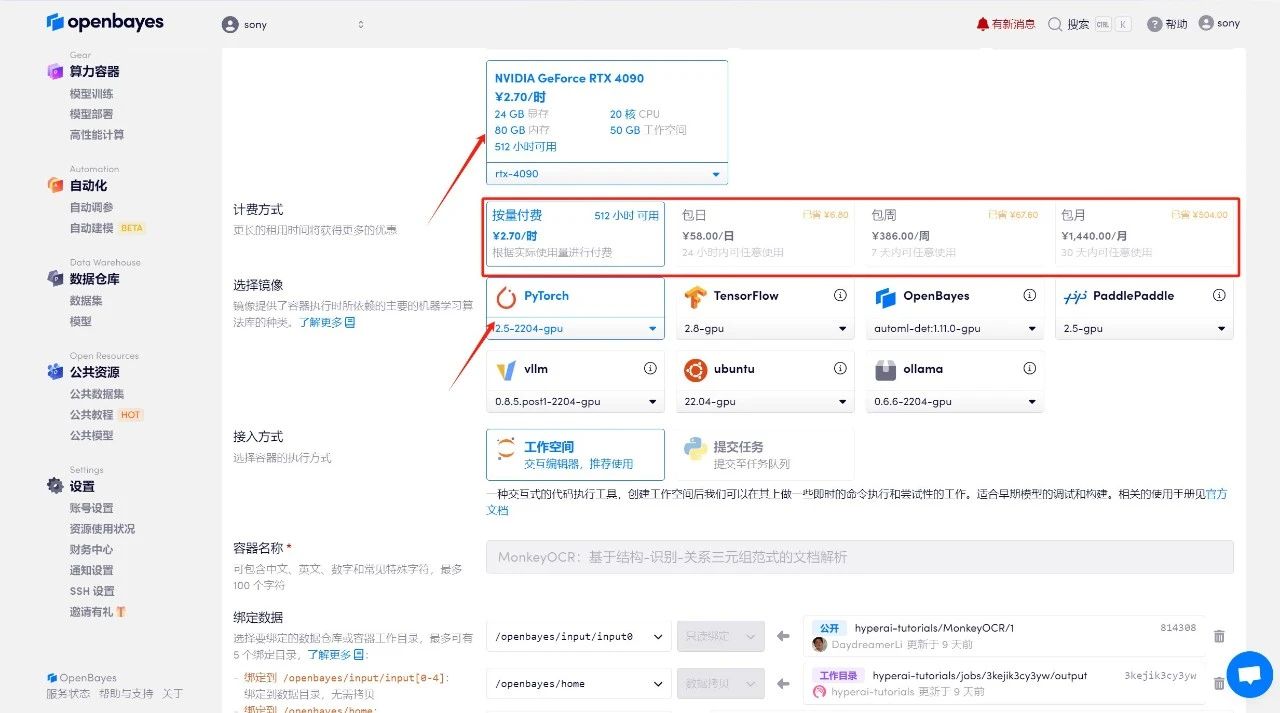
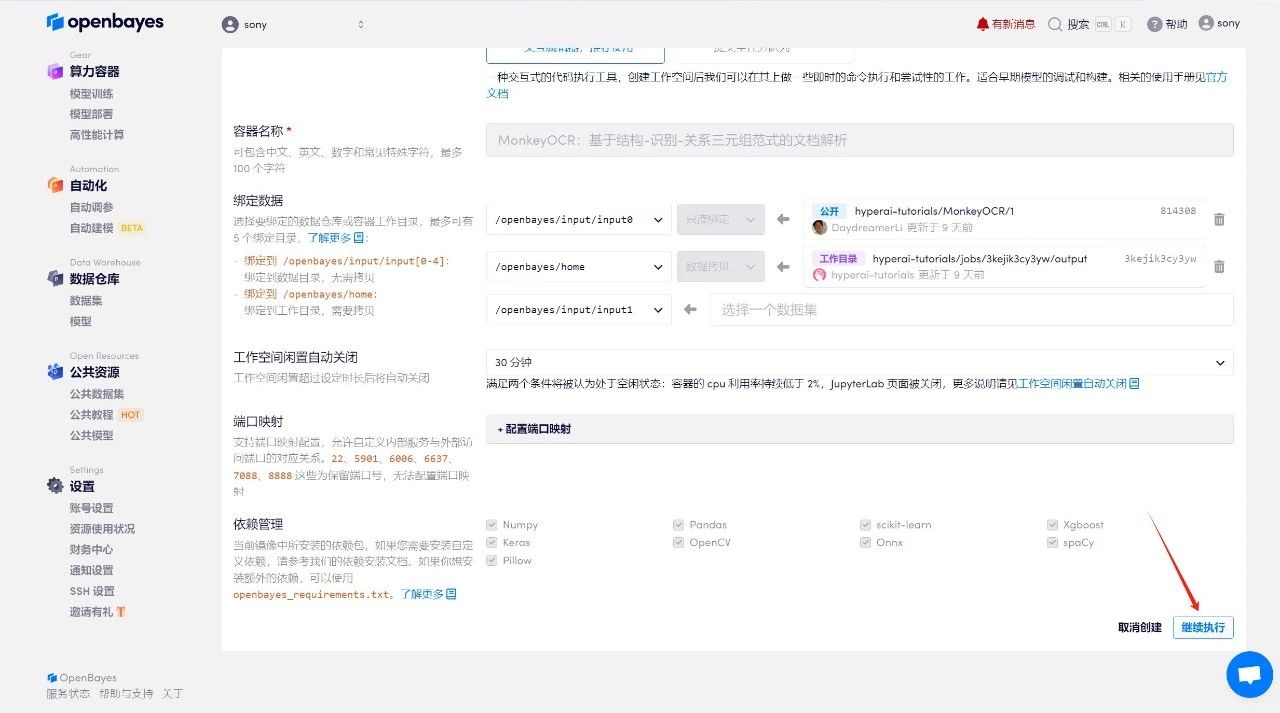
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
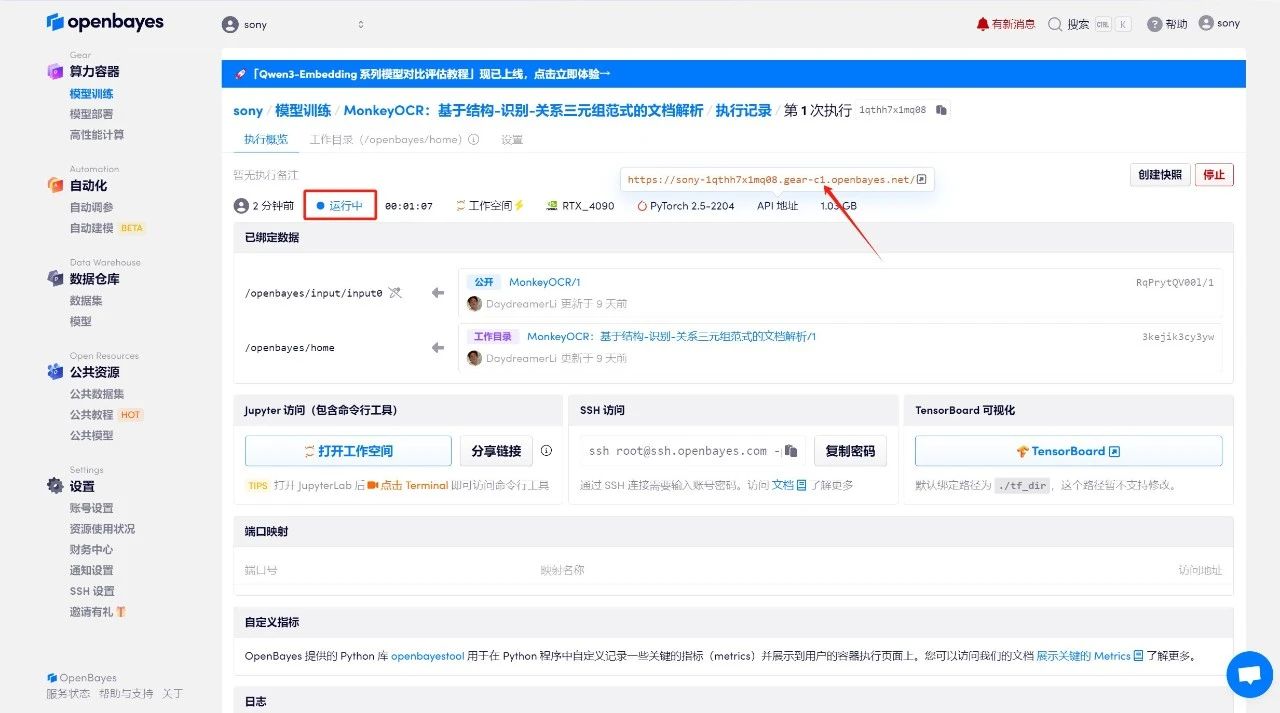
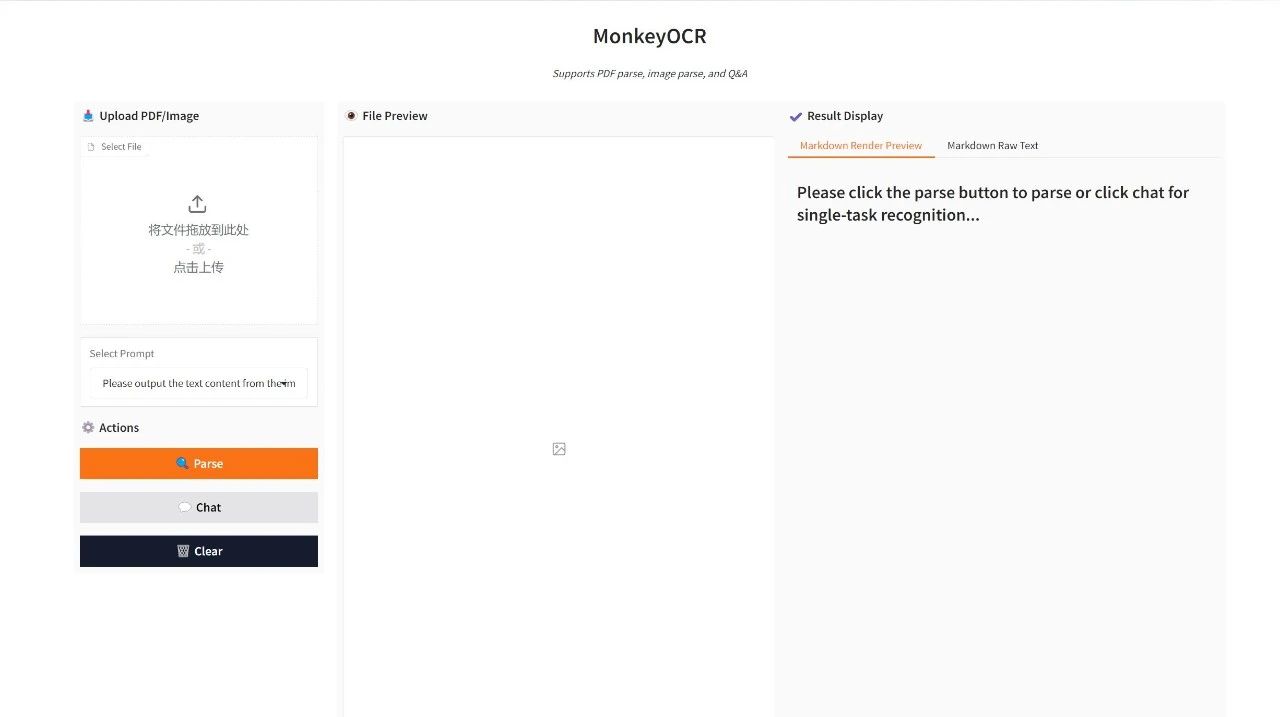
Démonstration d'effet
Téléchargez un PDF ou une image et cliquez sur « Analyser » pour l'analyser. Si vous choisissez le mode « Chat », vous devez sélectionner « Invite » dans « Sélectionner une invite ».
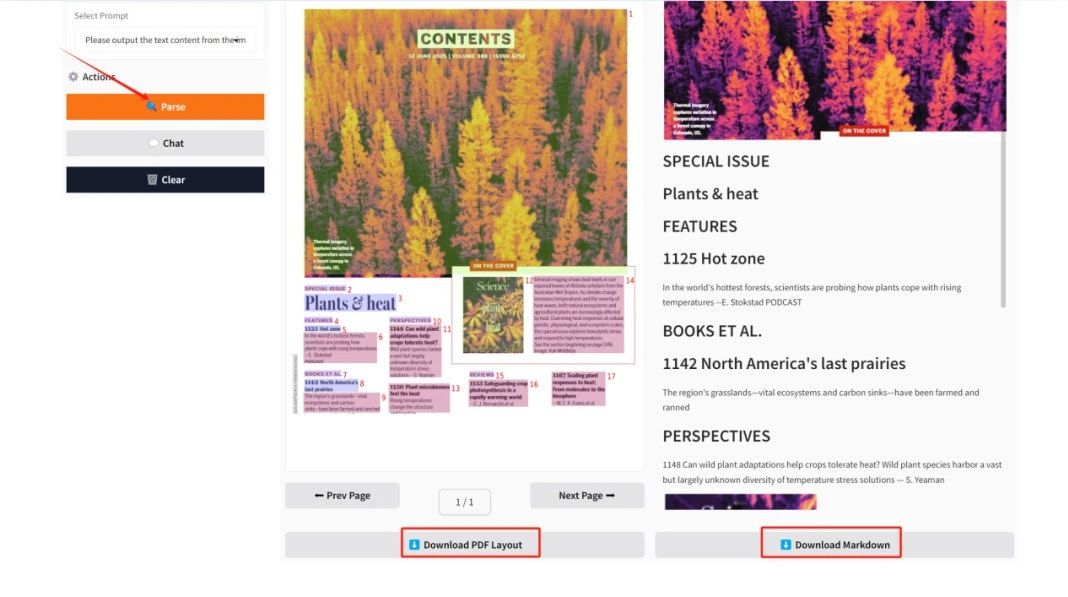
Les résultats s'afficheront dans « Affichage des résultats ». Cliquez sur « Télécharger la mise en page PDF/Télécharger Markdown » pour télécharger le document au format PDF/Markdown sur votre ordinateur.

Le tutoriel ci-dessus est recommandé pour ce problème. Bienvenue à tous ! ⬇️
Lien du tutoriel :








