Command Palette
Search for a command to run...
Modèle De Diffusion × Génération De Musique, DiffRhythm Termine La Création De Chansons En Quelques Minutes ! L'ensemble De Données MiniMind Est Open Source Pour Permettre Des Modèles Linguistiques De Grande Taille Avec De Faibles Barrières De Déploiement

Le domaine de la génération musicale a fait des progrès significatifs ces dernières années, mais les modèles existants présentent encore de nombreuses limites dans leurs applications pratiques. La plupart des modèles ne peuvent générer que des pistes vocales ou d'accompagnement de manière indépendante, ce qui entraîne une expérience musicale incohérente. Pour relever ces défis, le laboratoire de traitement audio de la parole et du langage de l’Université polytechnique du Nord-Ouest et l’Université chinoise de Hong Kong ont développé conjointement un modèle appelé DiffRhythm.
En tant que premier modèle complet de génération de chansons open source basé sur la technologie de diffusionDiffRhythm maintient non seulement un niveau élevé de génération et de compréhension musicale, mais assure également son évolutivité grâce à un modèle, une architecture et un pipeline de traitement de données concis et efficaces. En termes d'expérience utilisateur, sa structure non autorégressive assure une vitesse de génération rapide.Générez une musique complète en seulement 1 minute.
Actuellement, HyperAI a lancé le tutoriel « DiffRhythm : Générer une démo musicale complète en 1 minute ». Venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/sHdPu
Du 17 au 21 mars, le site officiel hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels sélectionnés de haute qualité : 2
* Sélection d'articles communautaires : 6 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en mars : 1
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de synthèse de codage KodCode-V1
Cet ensemble de données est actuellement le plus grand ensemble de données open source entièrement synthétique, fournissant des solutions et des tests vérifiables pour les tâches de codage. Il contient 12 sous-ensembles différents, couvrant divers domaines (des algorithmes aux connaissances spécifiques aux progiciels) et niveaux de difficulté (des exercices de codage de base aux entretiens et aux défis de programmation compétitifs), et est conçu pour le réglage fin supervisé (SFT) et le réglage RL.
Utilisation directe :https://go.hyper.ai/CfZCm
2. Ensemble de données sur les dangers routiers
Cet ensemble de données contient 2,7 000 images et est principalement utilisé pour détecter les nids-de-poule, les fissures et les regards ouverts sur la route.
Utilisation directe :https://go.hyper.ai/XPJNQ

3. Ensemble de données de préhension de robot DexGraspVLA
Il s'agit d'un petit ensemble de données contenant 51 échantillons de données de démonstration humaine, ce qui est utile pour comprendre les données et le format, et pour exécuter le code pour expérimenter le processus de formation. Le contexte de la recherche découle de la nécessité d'un taux de réussite élevé en matière de préhension adroite dans des scènes encombrées, en particulier en atteignant un taux de réussite de plus de 90% dans des combinaisons sans précédent d'objets, d'éclairage et d'arrière-plans.
Utilisation directe :https://go.hyper.ai/pJ44Y

4. Ensemble de données VQA sur les illusions visuelles IllusionAnimals
L'ensemble de données IllusionAnimals est un ensemble de données FiftyOne contenant 2 000 échantillons. L'ensemble de données contient 10 catégories d'animaux et une catégorie sans illusion, avec une résolution d'image de 512 × 512 pixels. Il est utilisé pour évaluer la capacité des modèles multimodaux à identifier et à expliquer les illusions visuelles basées sur les animaux.
Utilisation directe :https://go.hyper.ai/Ebl40

5. Ensemble de données d'évaluation de grands modèles multilingues et multimodaux m-WildVision
L'ensemble de données contient 500 exemples de requêtes utilisateur complexes dans 23 langues, chacune dérivée de la plate-forme WildVision-Arena. La structure de l'ensemble de données comprend l'ID de la question, le type de langue, le texte d'instruction et les données d'image, visant à évaluer la généralisation et la robustesse du modèle dans différentes langues.
Utilisation directe :https://go.hyper.ai/Im6mN

6. Ensemble de données de formation et de réglage fin de grands modèles MiniMind
MiniMind est un projet open source de modèle de langage léger et volumineux qui vise à abaisser le seuil d'utilisation des modèles de langage volumineux (LLM) et à permettre aux utilisateurs individuels de s'entraîner et de déduire rapidement sur des appareils ordinaires.
Utilisation directe :https://go.hyper.ai/gCz2y
7. Ensemble de données de détection et de segmentation des débris marins Seaclear
L'ensemble de données contient 8 610 images de débris marins annotées pour les tâches de détection d'objets et de segmentation d'instances, couvrant 40 catégories d'objets comprenant non seulement des débris mais également des animaux, des plantes et des pièces de robot observés. Les annotations sont fournies sous forme de fichiers au format COCO (.json) et les images sont organisées dans des dossiers, chaque dossier étant dédié à une paire site-caméra unique. Toutes les images sont en résolution 1920×1080.
Utilisation directe :https://go.hyper.ai/JFofd
8. Ensemble de données de captchas texte et audio
L'ensemble de données contient 100 000 échantillons CAPTCHA, chacun étiqueté avec sa chaîne alphanumérique correspondante, ce qui le rend idéal pour la formation de modèles OCR, de reconnaissance vocale et de solveurs CAPTCHA basés sur l'IA.
Utilisation directe :https://go.hyper.ai/vFmTJ
9. Ensemble de données sur la classification des déchets
L'ensemble de données contient des images et des annotations au format YOLO pour la classification et la détection de différents types de déchets : plastique, papier et carton, verre/métal, déchets organiques, textiles et électroniques (déchets électroniques).
Utilisation directe :https://go.hyper.ai/NwEF7
10. Image de la surface de Mars (rover Curiosity) Ensemble de données d'images de la surface de Mars
L'ensemble de données comprend 6 691 images collectées par trois instruments du Mars Science Laboratory (MSL) : Mastcam œil droit, Mastcam œil gauche et MAHLI, couvrant 24 catégories. Ces images sont des versions « navigation » de chaque produit de données brutes et ne sont pas en pleine résolution, environ 256 × 256 pixels par image.
Utilisation directe :https://go.hyper.ai/B1T0l
Tutoriels publics sélectionnés
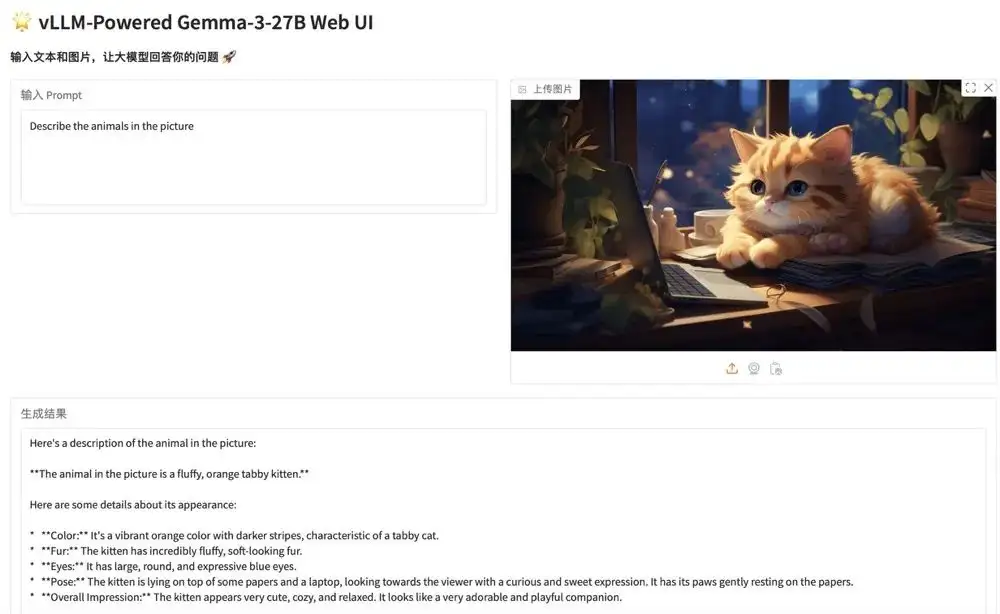
1. Déployer Gemma-3-27B-IT à l'aide de vLLM
La série Gemma est une série de grands modèles open source par Google, construits sur la même recherche et la même technologie que le modèle Gemini. Gemma 3 est un grand modèle multimodal capable de traiter des entrées de texte et d'image et de générer des sorties de texte. Le modèle convient à une variété de tâches de génération de texte et de compréhension d'images, notamment la réponse aux questions, le résumé et le raisonnement. Leur taille relativement petite leur permet d’être déployés dans des environnements aux ressources limitées, tels que les ordinateurs portables, les ordinateurs de bureau ou les infrastructures cloud.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/JxVbA
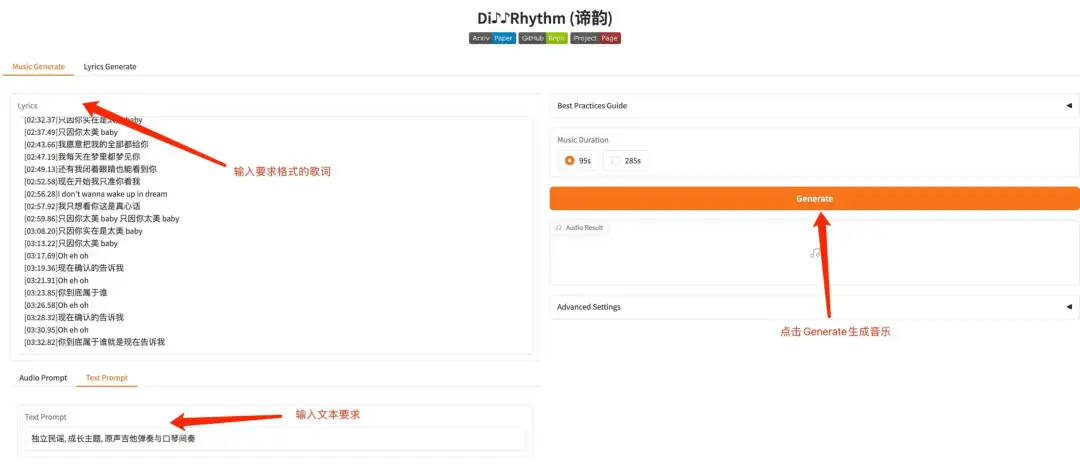
2. DiffRhythm : Générez une démo musicale complète en 1 minute
DiffRhythm est le premier modèle de génération de chansons basé sur la diffusion capable de composer des chansons entières. Il peut générer une chanson complète d'une durée maximale de 4 minutes et 45 secondes, y compris les voix et l'accompagnement, en peu de temps. Les utilisateurs n'ont qu'à fournir des paroles et des conseils de style, et DiffRhythm peut générer automatiquement des mélodies et des accompagnements qui correspondent aux paroles, prenant en charge la saisie multilingue.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/sHdPu
Articles de la communauté
L'équipe de l'académicien Wu Lixin a profondément intégré l'océanographie physique à l'IA, utilisé la théorie de la dynamique océanique pour piloter l'architecture du réseau neuronal et construit un grand modèle de prévision intelligent de l'environnement océanique à haute résolution à l'échelle mondiale « Wenhai » pour mieux refléter l'état de l'océan réel et économiser considérablement le temps de calcul et la consommation d'énergie. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/s7YMj
Une équipe de recherche de l'Université de Cambridge a proposé un modèle de tissu virtuel appelé Celcomen, qui peut non seulement estimer l'impact de l'environnement sur les cellules individuelles, mais également déduire l'impact des cellules individuelles sur leur environnement environnant et sur le tissu global. Les chercheurs ont vérifié l'identifiabilité du modèle Celcomen dans l'apprentissage de la structure causale et le démêlage des relations causales à travers des données synthétiques auto-cohérentes et des expériences de données du monde réel, ainsi que sa capacité à démêler et à récupérer les interactions gène-gène dans des données transcriptomiques spatiales réelles et auto-simulées. Les résultats connexes ont été sélectionnés pour l'ICLR 2025. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/ylKOr
Lors de la septième diffusion en direct de Meet AI4S, HyperAI a invité le professeur associé Huang Hong de l'Université des sciences et technologies de Huazhong, le Dr Zhou Dongzhan du Shanghai AI Lab et le Dr Zhou Bingxin de l'Institut de recherche de l'Université Jiao Tong de Shanghai à discuter du développement de pointe de l'IA dans les sciences sociales, la chimie physique, les sciences de la vie et d'autres domaines avec trois chercheurs. Ils ont également partagé leurs points de vue sur le choix des orientations de recherche et leur expérience dans la soumission d’articles aux principales conférences sur l’IA. Cet article est un résumé du partage des trois enseignants.
Voir le rapport complet :https://go.hyper.ai/klU6m
Jensen Huang, PDG de NVIDIA, a prononcé un discours d'ouverture lors de la conférence GTC 2025, l'événement mondial annuel consacré à l'IA, en mettant l'accent sur les derniers développements dans le domaine de pointe de l'IA. Non seulement il a présenté la nouvelle génération de puces d'IA de qualité nucléaire de Blackwell, mais il a également lancé une série de nouvelles réalisations, notamment l'ensemble de données d'IA physique, le modèle GR00T N1, le moteur physique Newton et le modèle mondial Cosmos. Cet article est un résumé du contenu du discours de Huang Renxun et de ses nouvelles réalisations.
Voir le rapport complet :https://go.hyper.ai/Q6wdO
NVIDIA, en collaboration avec le MIT et d'autres, a développé un nouveau type de générateur de protéines à flux à grande échelle, Proteina. Proteina possède 5 fois plus de paramètres que le modèle RFdiffusion et a étendu ses données de formation à 21 millions de structures protéiques synthétiques. Il a atteint des performances SOTA dans la conception de squelettes protéiques de novo et a généré des protéines diverses et concevables avec une longueur sans précédent allant jusqu'à 800 résidus. Ses résultats ont été sélectionnés pour l'ICLR 2025 Oral. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/w7jlU
L'Université Jiao Tong de Shanghai s'est associée à un certain nombre d'institutions de premier plan pour créer un système d'évaluation faisant autorité et mener des tests systématiques de 10 LLM traditionnels au pays et à l'étranger, notamment ChatGPT et DeepSeek. Il s’agit de la première preuve concrète d’une formation de médecins de soins primaires assistée par l’IA et fournit un soutien essentiel aux soins de santé primaires basés sur l’IA. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/DH8hf
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 700 ensembles de données publiques
* Comprend plus de 500 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








