Command Palette
Search for a command to run...
Tutoriel En Ligne : La Carte Unique A6000 Déploie Facilement Gemma 3 Et Identifie Avec Précision La Véritable Prise De Vue Du Discours De Huang Renxun

Le soir du 12 mars,Google a publié Gemma 3, le « diable à carte unique », qui serait le modèle le plus puissant pouvant fonctionner sur un seul GPU ou TPU.Les résultats réels ont également confirmé ce que le blog officiel disait : sa version 27B a battu le DeepSeek V3 avec 671B, ainsi que o3-mini et Llama-405B, juste derrière DeepSeek R1, mais ses besoins en puissance de calcul sont bien inférieurs à ceux des autres modèles. Comme le montre la figure suivante :
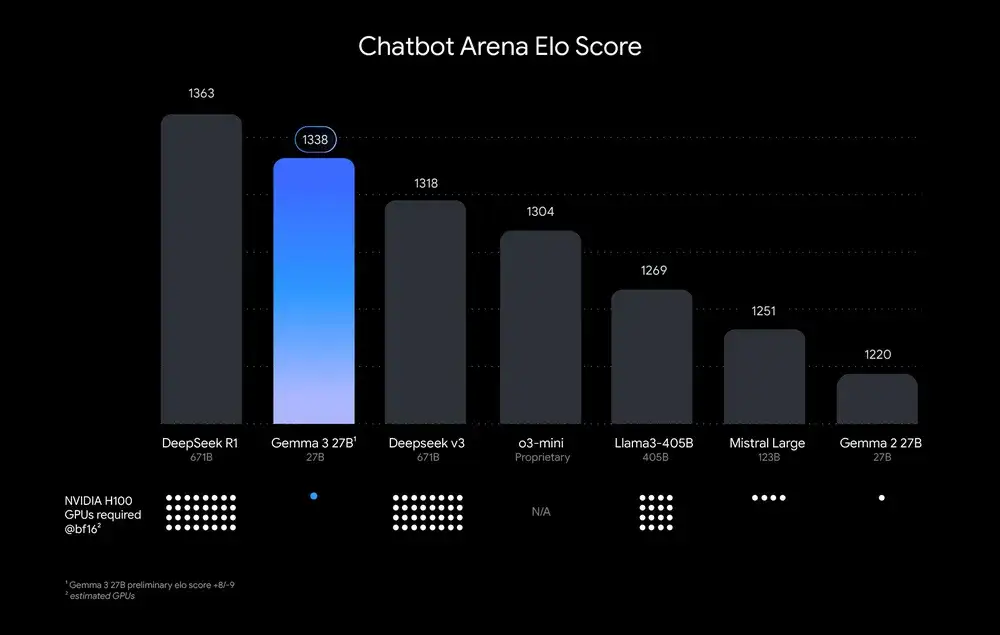
*Les modèles sont classés par score Elo de Chatbot Arena ; les points représentent les besoins estimés en puissance de calcul
Par la suite, Google a également généreusement levé l'interdiction du rapport technique de Gemma 3. Il est introduit que Gemma 3 combine des méthodes telles que la distillation, l'apprentissage par renforcement et la fusion de modèles, et les performances des versions pré-entraînées et de réglage fin des instructions sont meilleures que celles de Gemma 2. Dans le même temps, des capacités de compréhension visuelle et des capacités de compréhension linguistique plus étendues sont introduites, prenant en charge la compréhension de plus de 140 langues et de 128 000 contextes longs.
Dans les scénarios d'application, le grand modèle multimodal Gemma 3 peut traiter les entrées de texte et d'image et générer des sorties de texte, ce qui convient à diverses tâches de génération de texte et de compréhension d'images, notamment la réponse aux questions, le résumé et le raisonnement. Les quatre versions de paramètres 1B, 4B, 12B et 27B qui sont cette fois open source incluent à la fois des modèles pré-entraînés et des versions de réglage fin des instructions générales, qui peuvent être exécutées rapidement directement sur des appareils tels que des téléphones portables, des ordinateurs portables et des postes de travail.
Afin de permettre à chacun de mieux expérimenter ce « modèle multimodal le plus puissant à GPU unique »,La section tutoriel du site officiel d'HyperAI a lancé « Déploiement de Gemma-3-27B-IT à l'aide de vLLM », une version optimisée pour les instructions avec 27 milliards de paramètres.
Lien du tutoriel :
De plus, nous avons préparé un bonus surprise pour tout le monde - 4 heures Carte unique RTX A6000 Période d'utilisation gratuite (la période de validité des ressources est de 1 mois), les nouveaux utilisateurs utilisent un code d'invitation Gemma-3Inscrivez-vous pour l'obtenir, seulement 10 places disponibles, premier arrivé, premier servi !
Essai de démonstration
1. Connectez-vous à hyper.ai, sur la page Tutoriel, sélectionnez Déployer Gemma-3-27B-IT à l'aide de vLLM, puis cliquez sur Exécuter ce tutoriel en ligne.
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
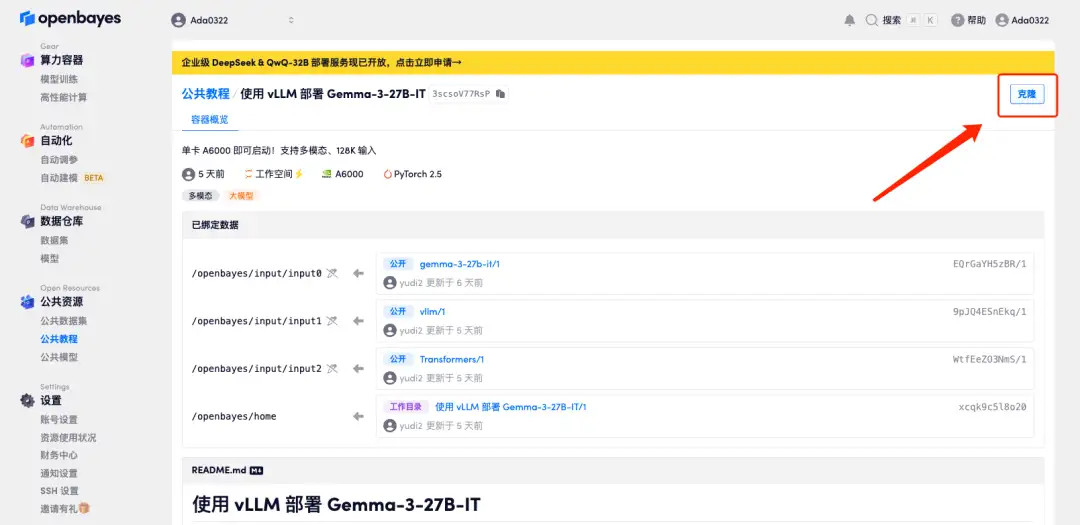
3. Sélectionnez les images NVIDIA A6000 et PyTorch, puis cliquez sur Continuer. Nous avons préchargé la dernière version de vLLM dans le conteneur.
La plateforme OpenBayes a lancé une nouvelle méthode de facturation. Vous pouvez choisir « payer à l'utilisation » ou « forfait journalier/hebdomadaire/mensuel » selon vos besoins. Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
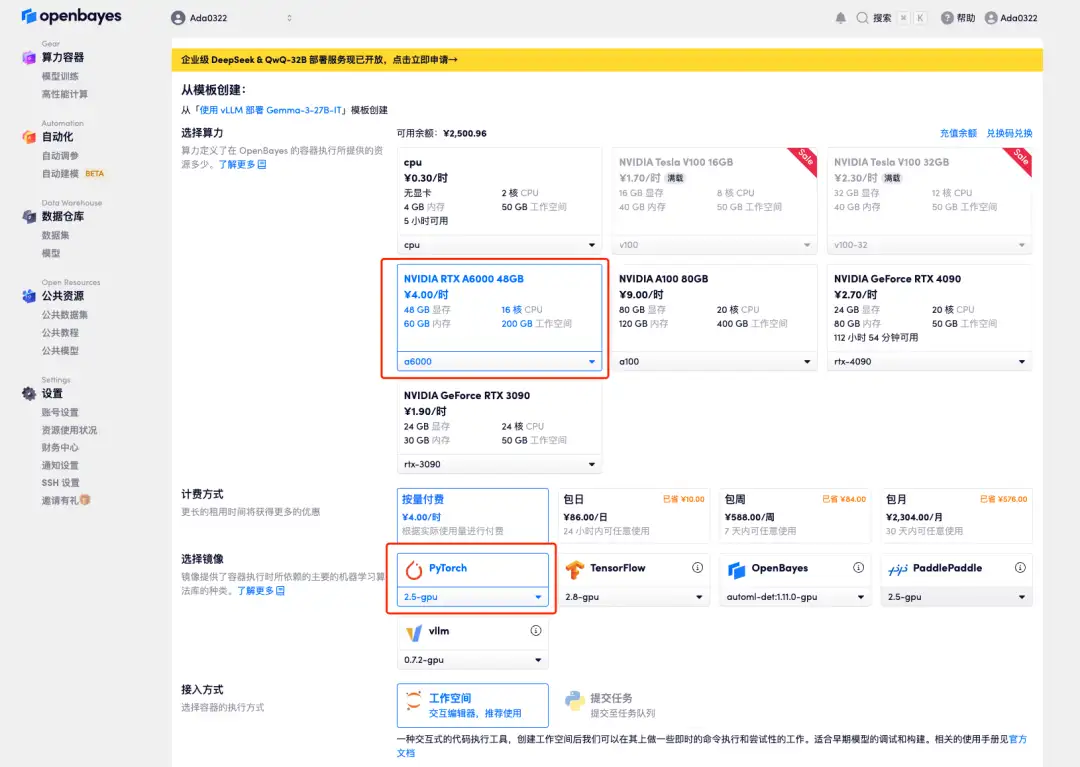
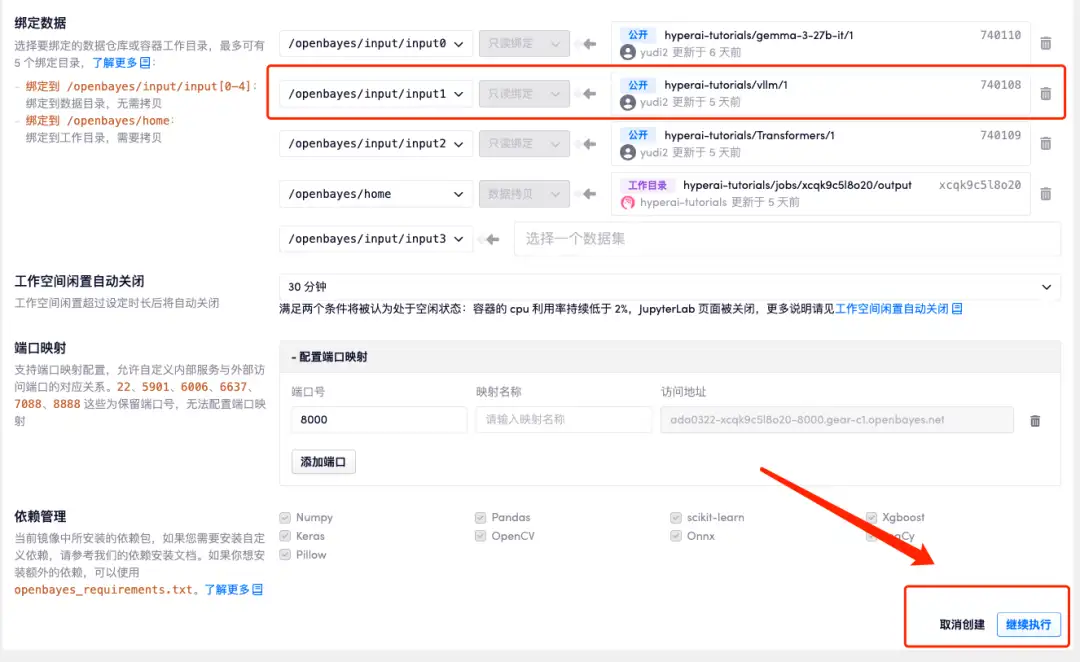
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Étant donné que le modèle est volumineux, il faut environ 3 minutes pour afficher l'interface WebUI, sinon « Bad Gateway » s'affichera. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
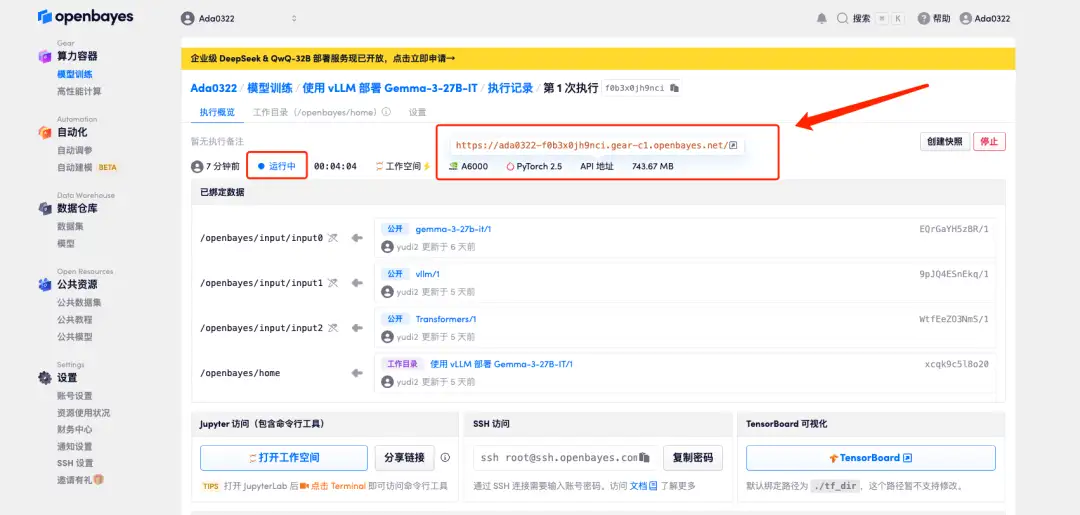
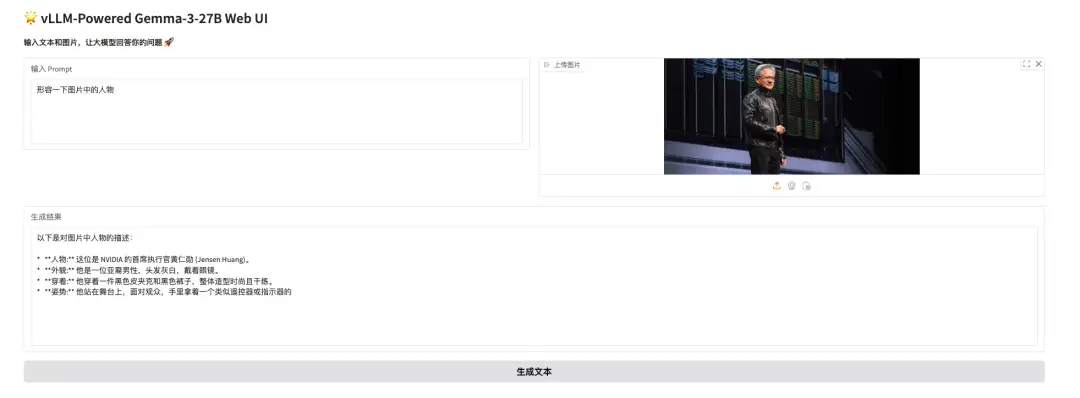
Affichage des effets
Hier (19 mars) au petit matin, Huang Renxun, le « Leather Swordsman », a prononcé un discours d'ouverture au NVIDIA GTC 2025. Je l'ai utilisé pour tester la compréhension de l'image par Gemma 3. Il a non seulement reconnu Huang d'un coup d'œil, mais a également reconnu qu'il tenait une télécommande et se tenait sur la scène, comme le montre la figure suivante :