Command Palette
Search for a command to run...
EnergAIzer, Un Framework d'estimation De La Puissance GPU Développé Par Le MIT Et d'autres, Effectue Des Prédictions En Moyenne En 1,8 Seconde Avec Une Erreur d'environ 81 TP3T.

Selon les estimations du Laboratoire national Lawrence Berkeley, en raison de la croissance explosive de l'intelligence artificielle,D’ici 2028, les centres de données consommeront 121 TP3T de l’électricité totale utilisée aux États-Unis.En tant qu'accélérateur principal des charges de travail d'IA, les unités de traitement graphique (GPU) sont devenues une source majeure de consommation d'énergie, avec une enveloppe thermique (TDP) atteignant respectivement 700 W et 1 200 W pour les dernières cartes graphiques NVIDIA H100 et GB200. Face à des défis énergétiques de plus en plus préoccupants,L'estimation rapide de la puissance et de la consommation énergétique des GPU pour les charges de travail d'IA est devenue cruciale.
Les modèles de consommation d'énergie nécessitent généralement des informations sur l'utilisation du matériel afin de caractériser l'intensité d'utilisation des différents modules du GPU (tels que la DRAM et les cœurs Tensor), car la consommation d'énergie dynamique est directement proportionnelle à l'activité des modules. Les méthodes existantes obtiennent principalement ces informations par deux approches : la première consiste à utiliser des simulateurs au niveau des instructions pour déduire l'utilisation des modules en simulant l'exécution du GPU cycle par cycle.Cependant, même pour des charges de travail de taille moyenne, de telles simulations détaillées peuvent prendre plusieurs heures.La seconde est l'analyse des performances en temps réel (profilage).Cependant, cela entraîne non seulement une surcharge d'analyse plus importante, mais dépend également des ressources matérielles disponibles.
Dans ce contexteDes chercheurs du MIT et du laboratoire d'IA Watson du MIT-IBM ont développé EnergAIzer, un cadre d'estimation rapide de la consommation énergétique des GPU pour les charges de travail d'IA.Les informations relatives à l'utilisation du matériel peuvent être directement fournies aux modèles de consommation d'énergie sans nécessiter de simulations coûteuses ni d'analyses de performance.Ce nouveau cadre permet d'effectuer une estimation complète de la consommation d'énergie en seulement 1,8 seconde en moyenne.Sur les GPU NVIDIA Ampere, EnergAIzer a atteint une erreur de consommation d'énergie d'environ 81 TP3T, ce qui est compétitif avec les modèles traditionnels qui reposent sur des simulations cycliques complexes ou une analyse des performances matérielles.
Les chercheurs ont également démontré les capacités d'EnergAIzer en matière de mise à l'échelle de la fréquence et d'exploration de la configuration architecturale.En incluant la prédiction de la consommation électrique du NVIDIA H100, l'erreur n'est que de 7%.Globalement, EnergAIzer offre des capacités de prédiction de la consommation d'énergie rapides et précises pour les charges de travail d'IA. Les opérateurs de centres de données peuvent utiliser ces estimations pour répartir efficacement les ressources limitées entre plusieurs modèles et processeurs d'IA, améliorant ainsi l'efficacité énergétique.
Les résultats de recherche associés, intitulés « EnergAIzer : cadre d'estimation de la puissance GPU rapide et précis pour les charges de travail d'IA », ont été publiés en prépublication sur arXiv.
Points saillants de la recherche :
* Ce nouveau cadre permet de générer des estimations fiables de la consommation d'énergie en quelques secondes seulement, alors que les techniques de modélisation traditionnelles peuvent prendre des heures, voire des jours, pour produire des résultats.
* Ce nouvel outil de prévision peut être appliqué à une large gamme de configurations matérielles, y compris même aux conceptions émergentes qui n'ont pas encore été déployées.
Cet outil aide les développeurs d'algorithmes et les fournisseurs de modèles à évaluer la consommation énergétique potentielle des nouveaux modèles avant leur déploiement.

Adresse du document :
https://arxiv.org/abs/2604.20105
Suivez notre compte WeChat officiel et répondez « prévision de la consommation d'énergie » en arrière-plan pour obtenir le PDF complet.
Jeu de données : Couvrant divers types d’opérateurs courants et différentes formes de tenseurs.
Dans toutes les expériences,Des chercheurs ont construit des bases de données de noyaux hors ligne basées sur les GPU NVIDIA A100-40GB-PCIE et A10.Pour l'entraînement d'EnergAIzer, qui couvre différents types d'opérateurs courants et de formes de tenseurs, voir le tableau ci-dessous pour plus de détails :
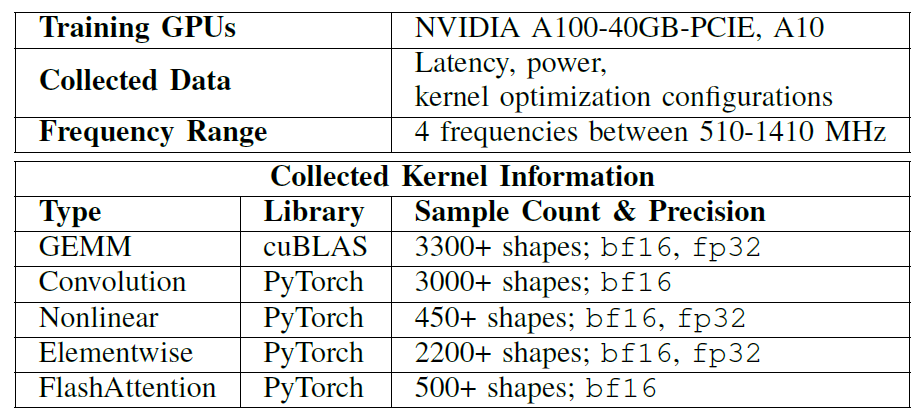
inclure:
* Calculs matriciels de type GEMM
* Convolution
* Non linéaire
* Elementwise
* Attention flash
Les chercheurs ont fourni des ressources expérimentales à EnergAIzer.Cela inclut le code source du cadre d'estimation, une base de données pré-collectée pour l'ajustement empirique et des données de mesure réelles pour valider les prédictions.Ses ressources comprennent des scripts pour reproduire des expériences, générer des estimations de consommation et de latence au niveau d'un seul noyau, et des estimations de bout en bout pour les charges de travail d'IA.
Trois étapes pour construire le modèle de prédiction au niveau du noyau EnergAIzer
Au cœur d'ENERGAIZER se trouve un modèle de prédiction au niveau du noyau, que les chercheurs construisent en trois étapes.d'abord,L'établissement de représentations de la charge de travail, telles que des stratégies d'optimisation logicielle comme le pavage, la planification des blocs de threads et le pipeline, formera des modèles d'exécution structurés qui constituent la base des modèles de performance.Deuxièmement,Construisez des modèles de performance et ajustez des données empiriques en utilisant ces modèles comme structures de base ;enfin,Le modèle de consommation d'énergie utilise le taux d'utilisation prévu pour estimer la consommation d'énergie dynamique.
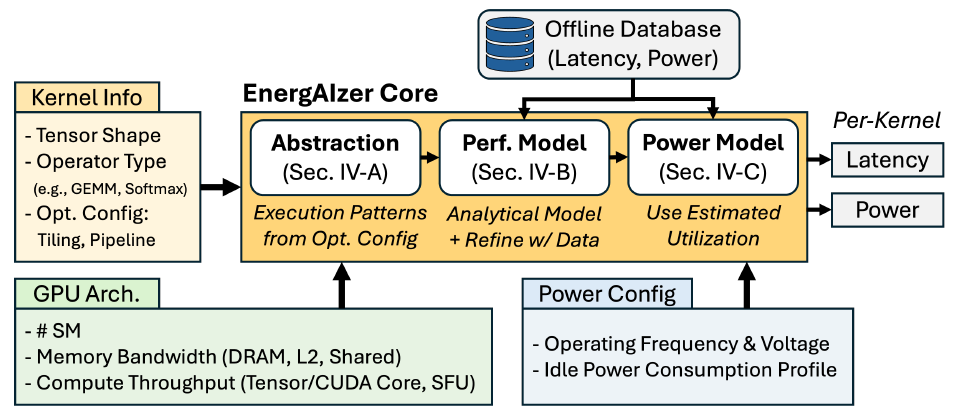
Couche de modélisation de la structure de la charge de travail
Stratégie d'optimisation
Les tenseurs sont divisés hiérarchiquement en blocs de données à différents niveaux d'exécution GPU. Le réarrangement des blocs de threads (ou « thread block swizzling ») répartit les blocs de threads accédant au même bloc d'entrée vers des tenseurs adjacents, optimisant ainsi la réutilisation du cache L2. Le pipeline logiciel superpose le transfert de données et le calcul lors des itérations temporelles. La structure du pipeline détermine la latence induite, un facteur clé dans la modélisation des performances.
Au-delà de GEMM
S’appuyant sur ce constat, les chercheurs ont systématiquement étendu l’analyse à tous les principaux types de noyaux en IA (y compris les noyaux non linéaires, par élément et de fusion) dans le but d’obtenir une utilisation au niveau du module pour la modélisation de la puissance des services.
vérifier
À l'aide de méthodes analytiques, les chercheurs ont calculé le trafic mémoire total pour la mémoire partagée, le cache L2 et la DRAM, et l'ont comparé aux données des compteurs matériels obtenues par l'analyse des performances NCU sur un GPU NVIDIA A100-40GB-PCIE. Des corrélations quasi parfaites ont été observées sur plus de 790 cœurs GEMM, 70 cœurs Softmax et plus de 380 cœurs FlashAttention, confirmant ainsi que les paramètres de bloc et le réarrangement optimal des blocs de threads déterminent le trafic mémoire.
Couche du modèle de performance
Construction de la chronologie
Le modèle de performance construit une chronologie d'exécution composée d'opérations à grande échelle. L'inclinaison détermine la granularité des opérations (par exemple, le chargement/stockage de données, le nombre d'instructions de calcul), tandis que le pipeline détermine la manière dont ces opérations se chevauchent en fonction des dépendances. Cette chronologie constitue la structure analytique et est utilisée pour révéler l'utilisation au niveau des modules, comme illustré dans la figure ci-dessous :
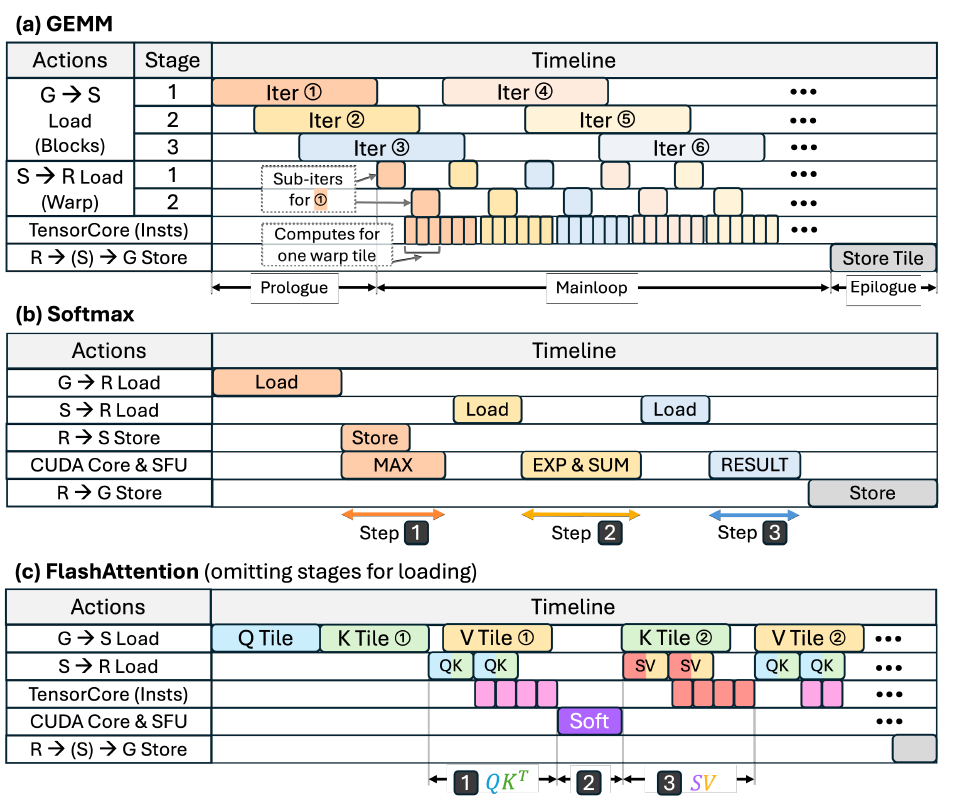
Prédiction retardée
Après avoir établi la structure chronologique, la méthode de calcul de la latence de chaque opération est décrite ; ensuite, la latence de ces opérations individuelles est combinée pour obtenir le temps d'exécution global, reflétant l'impact du pipeline.
Dérivation d'utilisation
À partir du calendrier de compilation, les taux d'utilisation de six modules clés ont été extraits : la mémoire DRAM, le cache L2, la mémoire partagée, les cœurs Tensor, les cœurs CUDA (pour les opérations en virgule flottante classiques) et les unités de fonctions spéciales (pour les fonctions exponentielles et autres fonctions non linéaires). Pour chaque module, son taux d'utilisation a été défini comme la proportion de son temps d'activité par rapport au temps d'exécution total du noyau.
couche du modèle de consommation d'énergie
À partir du taux d'utilisation au niveau du module obtenu grâce au modèle de performance, les chercheurs ont estimé la consommation d'énergie à l'aide d'une formule standard de consommation dynamique. Cette méthode est formellement cohérente avec la modélisation traditionnelle de la consommation d'énergie, mais la principale différence réside dans la manière dont le taux d'utilisation α est obtenu. La base de données hors ligne couvrant les mesures de consommation d'énergie à plusieurs fréquences de fonctionnement, le coefficient C est ajusté afin de minimiser l'erreur sur toute la plage de fréquences, permettant ainsi l'estimation de la consommation d'énergie à n'importe quelle fréquence sans mesures supplémentaires lors de la phase d'inférence.
En moyenne, il ne faut que 1,8 seconde par charge de travail pour effectuer l'estimation conjointe de la latence et de la consommation d'énergie.
Des chercheurs ont évalué expérimentalement le pouvoir prédictif d'EnergAIzer et son application à l'exploration de diverses options de conception :
Précision de l'estimation de la latence et de la consommation d'énergie pour les charges de travail d'IA
La figure ci-dessous présente les résultats d'estimation de la latence de bout en bout et de la consommation d'énergie pour différents modèles de langage (BERT-Large, GPT-2, OPT-1.3B, Qwen2-1.5B) et modèles visuels (ResNet101, ViT, MobileViT) :
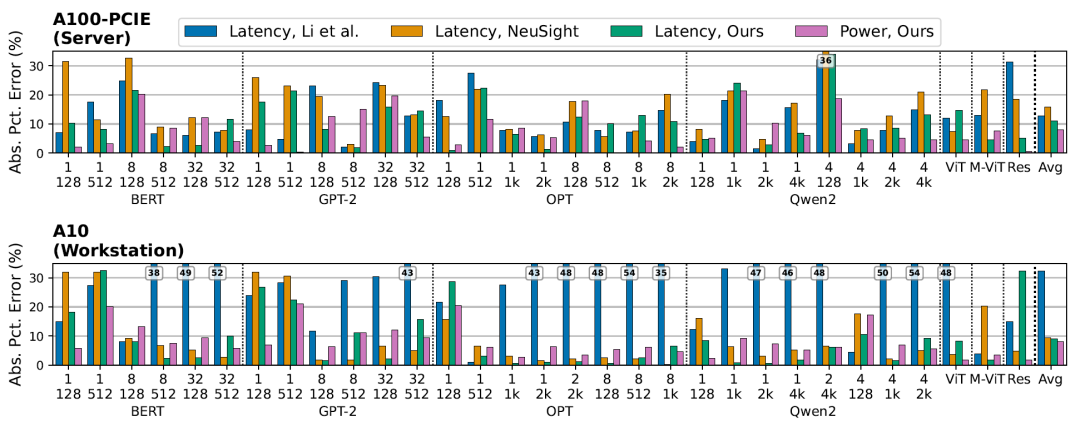
EnergAIzer a atteint une erreur de latence moyenne de 11,01 TP3T et une erreur de consommation d'énergie de 8,01 TP3T sur un GPU de qualité serveur (A100-40GB-PCIE).Sur un GPU de classe station de travail (A10), ils sont respectivement de 8,8% et 8,2%.Ces résultats sont moyennés sur l'ensemble des charges de travail. En matière de prédiction de latence, EnergAIzer rivalise avec les modèles de performance légers les plus performants (Li et al., NeuSight), tout en offrant des capacités d'estimation de la consommation énergétique que ces modèles ne proposent pas.
EnergAizer ne prend en moyenne que 1,8 seconde par charge de travail pour effectuer une estimation conjointe de la latence et de la consommation d'énergie.Pour les modèles de langage, une prédiction prend entre 1,1 et 2,8 secondes. En revanche, l'acquisition de compteurs matériels à l'aide de l'unité de contrôle réseau (NCU) prend entre 452 et 8 192 secondes, soit une accélération de 317 à 3 856 fois.
Explorez la régulation de la tension et de la fréquence
La régulation tension-fréquence est une technique de gestion de l'énergie couramment utilisée, qui peut tirer profit d'une prédiction précise de la consommation électrique à différents points de fonctionnement. Des chercheurs ont évalué la capacité d'EnergAIzer à estimer la consommation électrique à différentes fréquences (510–1410 MHz) sur une carte A100-40GB-PCIE. Lors des expériences, seuls les paramètres d'entrée de configuration de l'alimentation d'EnergAIzer ont été ajustés, notamment la fréquence cible, la tension et la consommation électrique en veille à cette fréquence. La figure suivante compare les valeurs mesurées et la consommation électrique prédite :
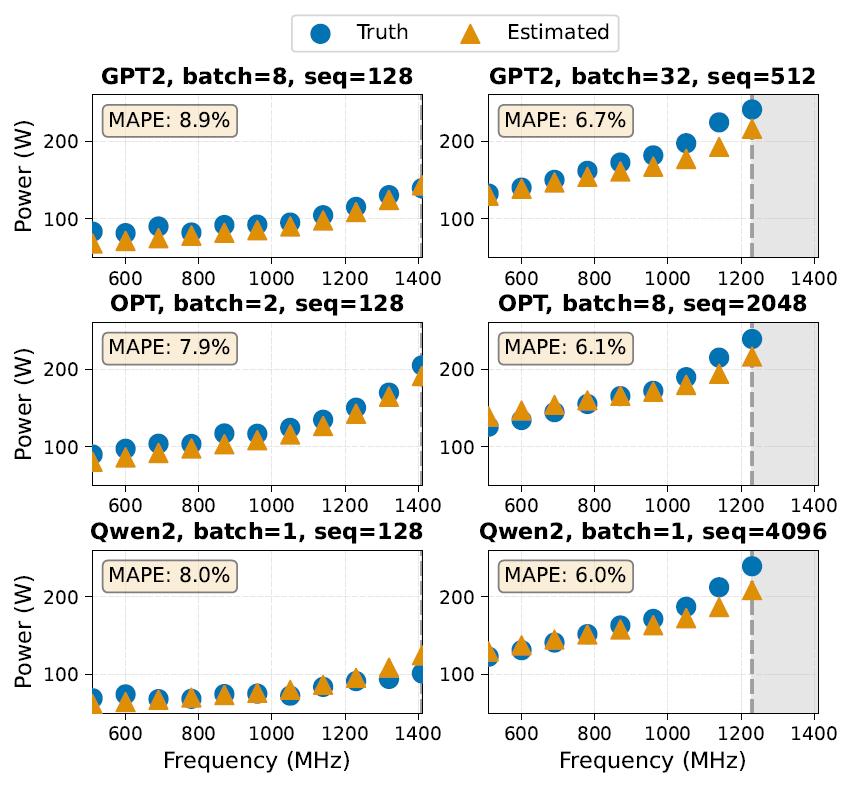
Le framework EnergAIzer peut capturer les comportements de mise à l'échelle typiques pour différents types de charges de travail : charges de travail à faible utilisation (petit lot/séquence, figure de gauche) et charges de travail à consommation d'énergie limitée (grand lot/séquence, figure de droite).L'erreur moyenne absolue en pourcentage (MAPE) à différentes fréquences est de 6%–9%.
Exploration de la configuration de l'architecture GPU
Ce cadre permet également d'explorer différentes configurations d'architecture GPU en ajustant les paramètres d'architecture GPU (tels que le nombre de SM, la bande passante mémoire et le débit de calcul) en entrée.Cela permet de prédire la consommation énergétique de la nouvelle architecture sans avoir à acquérir de données sur le matériel cible. Les chercheurs ont évalué deux scénarios : l’exploration au sein d’une même génération d’architecture GPU et l’exploration entre différentes générations d’architecture. Les configurations GPU cibles sont résumées dans le tableau ci-dessous :
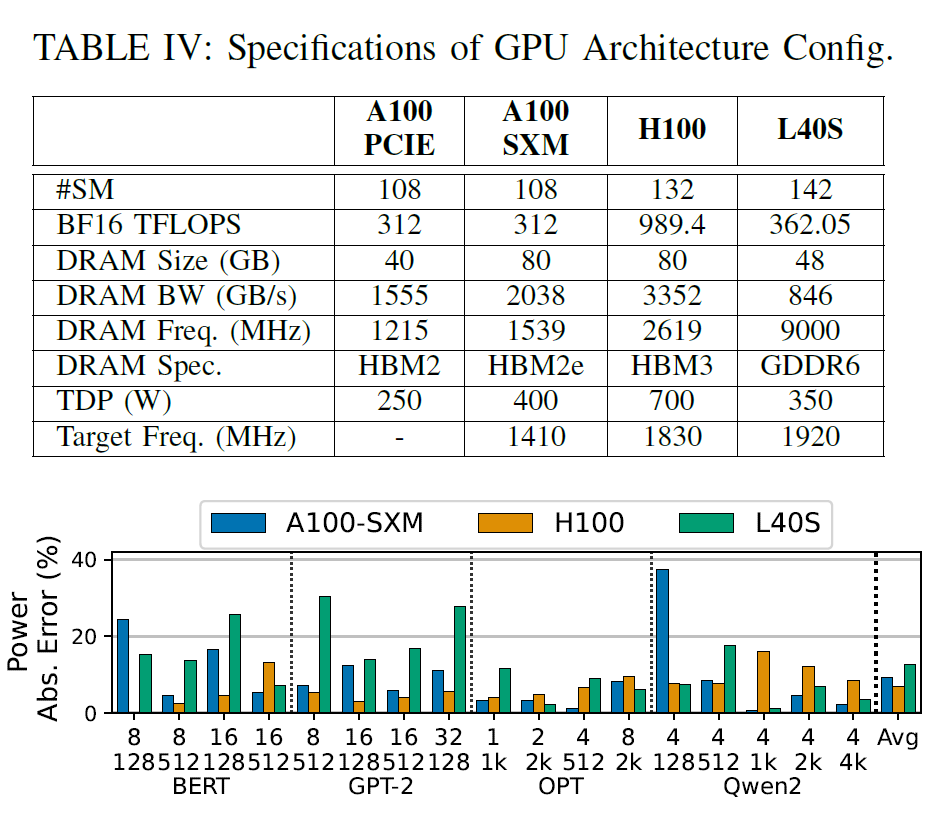
Premièrement, au sein de l'architecture Ampere, les chercheurs ont utilisé uniquement une base de données collectée auprès du contrôleur A100-40GB-PCIE pour prédire la consommation électrique du contrôleur A100-80GB-SXM, avec une erreur moyenne de 9,11 TP3T. Deuxièmement, dans des scénarios intergénérationnels, l'utilisation de la base de données de l'architecture Ampere pour prédire la consommation électrique des contrôleurs Hopper (H100) et Lovelace (L40S) a donné des erreurs respectives de 6,71 TP3T et 12,71 TP3T.
Globalement, EnergAIzer fournit une prédiction rapide et précise de la consommation d'énergie pour les charges de travail d'IA.
Conclusion
Pour les opérateurs de centres de données, EnergAIzer permet d'évaluer rapidement la consommation énergétique de différentes configurations GPU, stratégies de fréquence et schémas d'ordonnancement des ressources, facilitant ainsi une orchestration plus précise des ressources et une optimisation de l'efficacité énergétique. Pour les développeurs de modèles d'IA, ce framework offre un nouvel outil prenant en compte le matériel. Dès la conception du modèle, les compromis entre performances et consommation énergétique liés aux différentes précisions et implémentations peuvent être évalués, évitant ainsi de découvrir les problèmes de consommation énergétique uniquement lors du déploiement.
Bien sûr, le cadre actuel présente encore certaines limitations, notamment la nécessité d'améliorer ses capacités de modélisation pour le calcul collaboratif multi-GPU, la surcharge de communication et le calcul clairsemé irrégulier. Cependant, d'un point de vue méthodologique, EnergAIzer a démontré une tendance claire : la modélisation de la consommation énergétique des GPU évolue d'un outil d'analyse hors ligne « fortement dépendant des mesures » vers une capacité de prise de décision en ligne « légère et intégrable ». Face à l'expansion continue de la puissance de calcul de l'IA et aux contraintes énergétiques de plus en plus strictes, la valeur de ce type de technologie croît rapidement. À l'avenir, avec l'augmentation de la complexité des modèles et de l'hétérogénéité matérielle, les cadres comme EnergAIzer deviendront probablement bien plus que de simples outils de recherche ; ils pourraient devenir une composante indispensable de l'infrastructure de l'IA.
Références
https://news.mit.edu/2026/faster-way-to-estimate-ai-power-consumption-0427
https://arxiv.org/pdf/2604.20105