Command Palette
Search for a command to run...
Réalisez Un Mixage Et Un Clonage Multitimbraux En 3 Secondes ! Le Didacticiel F5/E2 TTS Est En Ligne ; l'ensemble De Données De Dialogue Psychologique PsyDTCorpus 5k Est Publié, Simulant Avec Précision Le Style De Langage Des Conseillers psychologiques.

Grâce au développement rapide du clonage vocal, l’IA a pu simuler des effets vocaux de plus en plus réalistes, mais il reste encore de nombreux défis à relever dans l’apprentissage à échantillon zéro et le contrôle multi-émotions.
Plus tôt cette année, E2 TTS a mis en œuvre une méthode simplifiée de génération de texte en parole qui remplit simplement l'entrée de texte à la même longueur que la parole d'entrée avec des marqueurs de remplissage, puis effectue une débruitage pour générer la parole. Récemment, F5 TTS a fait référence à cette méthode et a encore amélioré les performances du modèle basé sur la méthode de génération non autorégressive de correspondance de flux, de sorte qu'il prend non seulement en charge la synthèse multilingue, mais peut également ajuster les émotions et la vitesse de parole en fonction du contenu du texte, rendant la synthèse vocale de texte long plus délicate et plus fluide.
Afin de permettre à chacun de découvrir les effets de génération sonore du F5 TTS et du E2 TTS,Le site officiel hyper.ai a lancé le tutoriel d'intégration F5/E2 TTS, qui peut être cloné en un clic~
Exécutez en ligne :https://go.hyper.ai/SZxqv
Du 4 au 8 novembre, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en novembre : 6
Visitez le site officiel : hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données sur les types de cheveux Ensemble de données sur les types de cheveux
L'ensemble de données sur les types de cheveux est un ensemble de données d'images permettant de classer diverses coiffures. Il contient des images de haute qualité de 4 types de coiffures : droites, ondulées, bouclées et dreadlocks, avec un total de 1 992 images. Cet ensemble de données permet de former des modèles d’apprentissage automatique pour identifier et classer les types de cheveux.
Utilisation directe :https://go.hyper.ai/aXYcj

2. Ensemble de données de suppression du cloud public AllClear
L'ensemble de données AllClear est actuellement le plus grand ensemble de données publiques sur la suppression des nuages, contenant 23 742 régions d'intérêt (ROI) réparties à l'échelle mondiale couvrant divers modèles d'utilisation des terres et un total de 4 millions d'images. Il répond au manque de repères et de données de formation diverses dans la recherche sur la suppression des nuages.
Utilisation directe :https://go.hyper.ai/e2BYC

3. Ensemble de données arabes manuscrites de Muharaf
L'ensemble de données Muharaf est un ensemble de données d'apprentissage automatique axé sur la reconnaissance des caractères arabes manuscrits. Cet ensemble de données contient plus de 1,6 000 images de pages manuscrites historiques transcrites par des experts arabes. Chaque image de document est accompagnée des coordonnées spatiales du polygone de ses lignes de texte et d'informations sur les éléments de base de la page.
Utilisation directe :https://go.hyper.ai/NN2UR
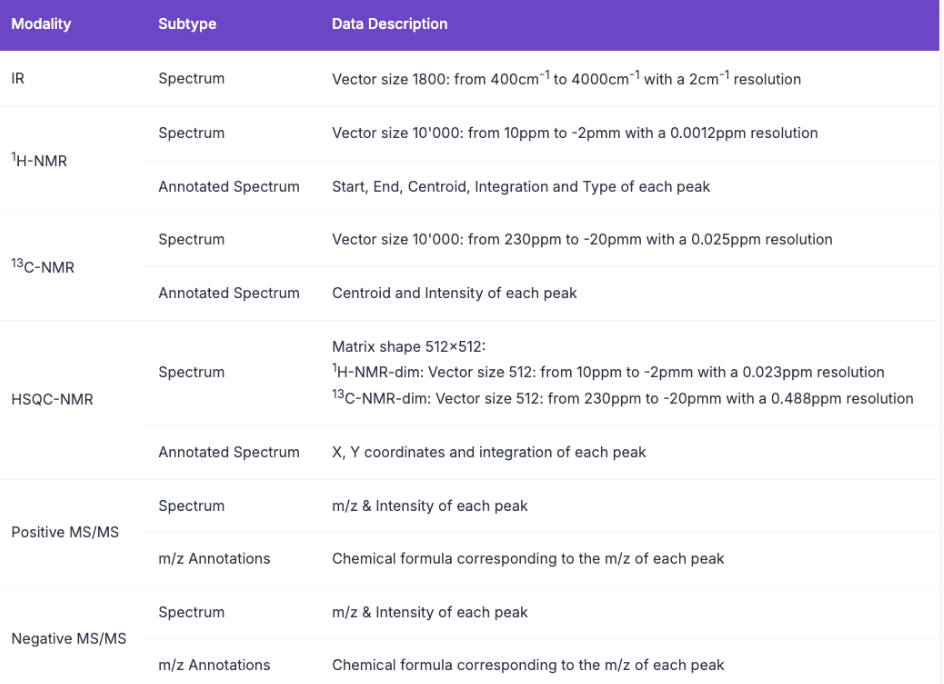
4. Ensemble de données spectroscopiques chimiques multimodales
L'ensemble de données contient des données spectrales simulées de 1H-RMN, 13C-RMN, HSQC-RMN, infrarouge et de spectrométrie de masse (modes ions positifs et négatifs) de 790 000 molécules extraites de réactions chimiques dans les données de brevets. Il peut intégrer des informations provenant de multiples modalités spectrales et simuler les méthodes utilisées par les experts humains pour analyser les structures moléculaires, ayant ainsi le potentiel d'automatiser l'analyse structurelle et de simplifier le processus de découverte moléculaire de la synthèse à la détermination de la structure.
Utilisation directe :https://go.hyper.ai/Z7zlr
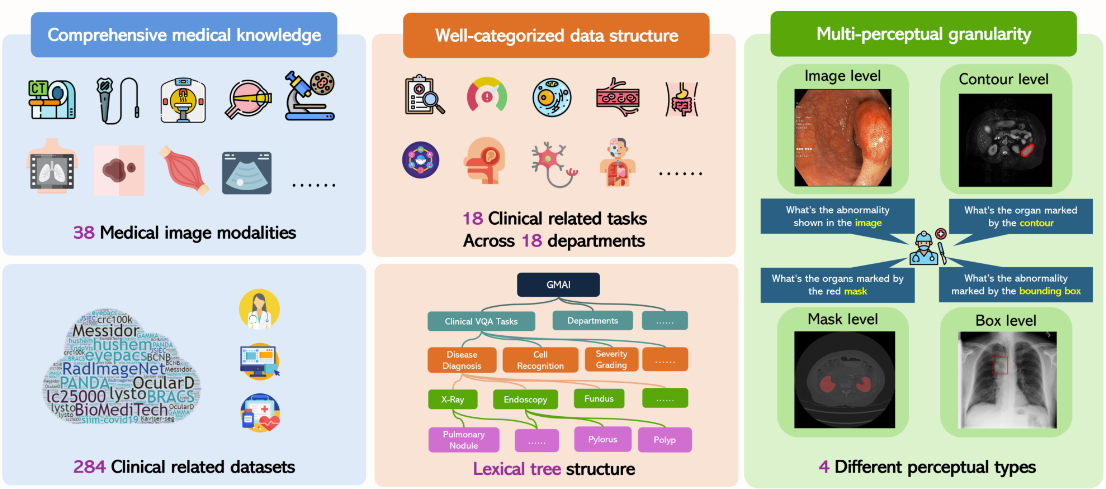
5. Ensemble de données de référence pour l'évaluation multimodale médicale GMAI-MMBench
GMAI-MMBench est un benchmark d'évaluation multimodal conçu pour faire progresser le domaine de l'intelligence artificielle médicale générale. Il contient 284 ensembles de données provenant de différentes sources, impliquant 38 modalités d'imagerie médicale et 18 tâches cliniquement pertinentes, couvrant 18 services médicaux différents, et est évalué à 4 granularités perceptuelles différentes, considérant ainsi les performances des LVLM à partir de plusieurs dimensions.
Utilisation directe :https://go.hyper.ai/FL799
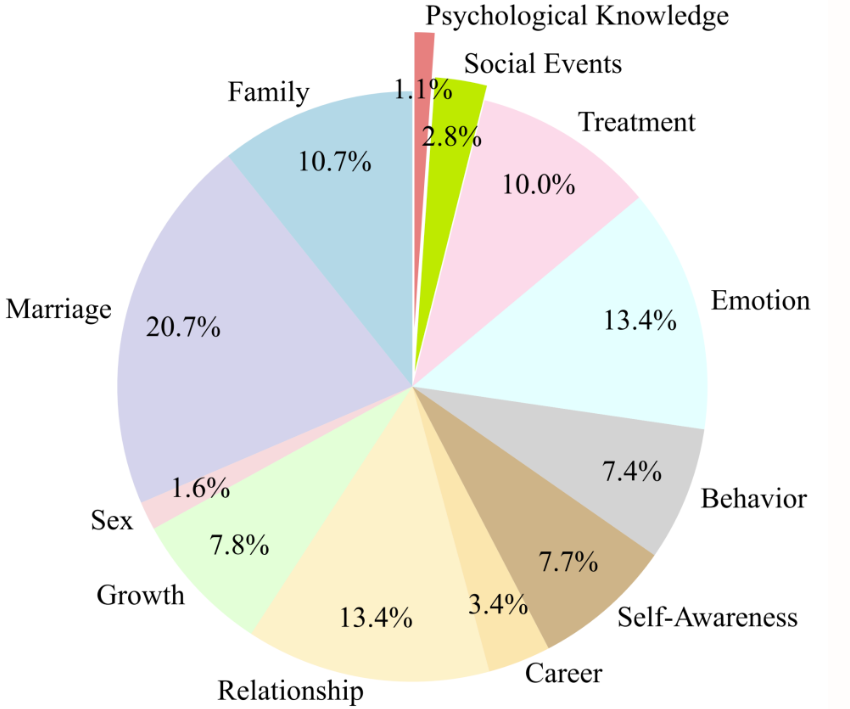
6. Ensemble de données de jumeaux numériques de conseillers psychologiques PsyDTCorpus
L'objectif principal de l'ensemble de données PsyDTCorpus est de simuler le style de langage et les techniques de conseil de conseillers psychologiques spécifiques pour soutenir le développement et la formation du modèle jumeau numérique du conseiller psychologique SoulChat2.0. Cet ensemble de données contient 5 000 données de conversation de haute qualité sur la santé mentale avec le style de langage du conseiller et les méthodes d'application de la technique thérapeutique.
Utilisation directe :https://go.hyper.ai/hGi4O
7. Ensemble de données audio de chant GTSinger
Cet ensemble de données est un grand ensemble de données de chant open source et de haute qualité qui contient 80,59 heures de chant enregistrées dans des studios professionnels. Ces chansons sont interprétées par 20 chanteurs professionnels dans 9 langues différentes, dont le chinois, l'anglais, le japonais, le coréen, etc., offrant aux chercheurs une bibliothèque de ressources avec des timbres et des styles extrêmement riches.
Utilisation directe :https://go.hyper.ai/wBcBz
8. Ensemble de données de simulation du catalyseur OC22
Cet ensemble de données est un ensemble de données de simulation de catalyseur, à savoir l'ensemble de données Open Catalyst 2022 (OC22). Cet ensemble de données étend et complète l'ensemble de données OC20, contient des structures de catalyseurs plus complexes et de nouveaux types de réactions, et fournit des données plus riches pour la formation et le test des modèles d'IA.
Utilisation directe :https://go.hyper.ai/M8Cpn
9. Ensemble de données open source sur les matériaux quantiques OQMD
L'ensemble de données OQMD contient les propriétés thermodynamiques et structurelles de plus de 1,22 million de matériaux calculées à l'aide de la théorie de la fonctionnelle de la densité (DFT). Les données de l'ensemble de données proviennent de la base de données sur la structure cristalline inorganique (ICSD), y compris les calculs d'énergie totale DFT de près de 300 000 composés et les modifications de structures cristallines courantes.
Utilisation directe :https://go.hyper.ai/dGOKs
10. Base de données en ligne sur les matériaux du projet Matériaux
Les données de la base de données du projet Matériaux comprennent la structure cristalline et les caractéristiques énergétiques, ainsi que des informations détaillées telles que la structure électronique et les propriétés thermodynamiques. Cet ensemble de données vise à utiliser des calculs de premiers principes à haut débit pour fournir des données de performance complètes, des informations structurelles et des résultats de simulation informatique pour plus d'un million de matériaux inorganiques, accélérant ainsi le processus de découverte et d'innovation de nouveaux matériaux.
Utilisation directe :https://go.hyper.ai/tGIVs
Pour plus d'ensembles de données publics, veuillez visiter:
Tutoriels publics sélectionnés
1. AnyText génération et édition de texte visuel multilingue
AnyText est un modèle de génération et d'édition de texte visuel multilingue. Il peut prendre en charge la génération de texte dans plusieurs langues telles que le chinois, l'anglais, le japonais, le coréen, etc., et prend également en charge l'édition du contenu du texte dans les images d'entrée. La technologie de génération de texte impliquée dans ce modèle offre des possibilités pour de nouvelles applications AIGC telles que les affiches de commerce électronique, la conception de logos, les graffitis créatifs et les émoticônes.
Cliquez sur le lien ci-dessous, suivez les étapes du didacticiel pour cloner et démarrer le conteneur, puis vous pourrez utiliser votre créativité pour concevoir des images.
Exécutez en ligne :https://go.hyper.ai/uMcNa
2. F5/E2 TTS clone n'importe quel son en seulement 3 secondes
Ce tutoriel comprend une utilisation de démonstration des modèles F5 TTS et E2 TTS. F5 TTS peut générer rapidement un discours naturel, fluide et fidèle au texte original grâce à un apprentissage sans interruption sans supervision supplémentaire. E2 TTS peut générer la séquence vocale entière à la fois, améliorant considérablement la vitesse de génération tout en maintenant une sortie vocale de haute qualité.
Ce projet peut générer une interface interactive front-end via l'interface Gradio. Les modèles et dépendances pertinents ont été déployés. Vous pouvez expérimenter le clonage sonore en le démarrant en un clic.
Exécutez en ligne :https://go.hyper.ai/SZxqv
3. Démo de génération d'images de grande taille avec Stable-Diffusion-3.5
Le modèle Stable Diffusion 3.5 Large est un modèle texte-image de générateur de diffusion multimodale (MMDiT) présentant des améliorations significatives de la qualité de l'image, de la typographie, de la compréhension des invites complexes et de l'efficacité des ressources. Sa taille massive de 8 milliards de paramètres offre des capacités de génération d'images de niveau professionnel, particulièrement adaptées aux besoins de génération d'images haute résolution.
Ce tutoriel a déployé l'environnement et vous pouvez générer directement des images haute résolution selon les instructions du tutoriel.
Exécutez en ligne :https://go.hyper.ai/w5k5V

💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Articles de la communauté
Récemment, Meta a publié l'ensemble de données open source à grande échelle Open Materials 2024 et un ensemble de modèles pré-entraînés de support. Parmi eux, l'ensemble de données OMat24 contient plus de 110 millions de résultats de calcul de théorie fonctionnelle de la densité axés sur la diversité structurelle et compositionnelle. L'ensemble de données est désormais disponible sur le site officiel d'HyperAI. Cet article est une interprétation détaillée et un partage du document de recherche.
Voir le rapport complet :https://go.hyper.ai/3wP7R
Lors du COSCon'24, HyperAI, en tant que communauté coproductrice, a organisé un forum d'IA open source en direction de l'IA pour la science. Des experts et des universitaires de l'Université Jiao Tong de Shanghai, de l'Université du Zhejiang, de l'Université Tsinghua et d'OpenBayes Bayesian Computing ont partagé leurs points de vue sur de multiples aspects, notamment l'intelligence artificielle médicale, l'intelligence artificielle de l'information géographique, la plate-forme cloud de calcul intelligent de recherche scientifique et les systèmes complexes urbains pilotés par l'IA. Cet article est une revue des points forts du forum. Cliquez ici pour une couverture détaillée.
Voir le récapitulatif de l'événement :https://go.hyper.ai/s2RQU
La société pharmaceutique d'IA Terray Therapeutics a finalisé un tour de financement de série B de 120 millions de dollars mené par NVentures, la branche de capital-risque de Nvidia, et le nouvel investisseur Bedford Ridge Capital. Il s’agit également du deuxième investissement de Nvidia dans Terray. L'entreprise a également construit le plus grand ensemble de données chimiques au monde et a combiné l'IA avec des expériences humides pour former une boucle fermée du côté des données. Cliquez ici pour une explication détaillée.
Voir le rapport complet :https://go.hyper.ai/AWojF
Dans le quatrième épisode de la série en direct « Meet AI4S », Lan Kunyao, titulaire d'un doctorat, du Cross-Media Language Intelligence Laboratory de l'Université Jiao Tong de Shanghai, a prononcé un discours intitulé « Plateforme de diagnostic et de consultation en santé mentale basée sur de grands agents modèles ». Il a présenté en détail les étapes d’utilisation, les points forts techniques et les projets futurs de la clinique psychologique. Cet article est une transcription des points saillants du discours, y compris une démonstration de la clinique psychologique intelligente. Cliquez pour le regarder rapidement.
Voir le rapport complet :https://go.hyper.ai/CHhKC
Articles populaires de l'encyclopédie
1. Modèle de transformateur
2. Auto-encodeur variationnel VAE
3. Réseaux de neurones artificiels
4. Front de Pareto
5. Compréhension linguistique multitâche à grande échelle (MMLU)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
* Comprend plus de 400 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :
Enfin, je recommande un « Programme d’incitation aux créateurs ». Les amis intéressés peuvent scanner le code QR pour participer !









