Command Palette
Search for a command to run...
Compte À Rebours 3 Jours ! Prenez rendez-vous Dès Maintenant Pour La Diffusion En Direct De l'Apple WWDC24 ; L'ensemble De Données De Préférences Multimodales À Grande Échelle RLAIF-V Est En Ligne, Réduisant Efficacement Le Phénomène d'hallucination De Différents MLLM

Du 3 au 7 juin, le site officiel hyper.ai est mis à jour :
Ensembles de données publiques de haute qualité : 10
Sélection de tutoriels de qualité : 2
Sélection d'articles communautaires : 3 articles
Entrées d'encyclopédie populaires : 5
Principales conférences avec dates limites en juin et juillet : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence des questions graphiques ChartQA
L'ensemble de données couvre 9,6 000 questions rédigées par des humains et 23,1 000 questions générées à partir de résumés de diagrammes rédigés par des humains, et est conçu pour résoudre des problèmes complexes impliquant un raisonnement visuel et logique.
Utilisation directe :https://go.hyper.ai/5tJE9
2. Ensemble de données de télédétection RS5M à grande échelle par appariement image-texte
L'ensemble de données RS5M contient 5 millions d'images de télédétection avec des descriptions en anglais. Cet ensemble de données est obtenu en examinant des ensembles de données d'appariement image-texte accessibles au public et des ensembles de données de télédétection (RS) étiquetés à l'aide d'un modèle de langage visuel pré-entraîné (VLM).
Utilisation directe :https://go.hyper.ai/jbwsV
3. Ensemble de données d'images et de textes multimodaux CapsFusion-120M
Cet ensemble de données contient des informations d'image et de texte provenant des ensembles de données LAION-2B et LAION-COCO, qui peuvent être utilisées pour une pré-formation multimodale à grande échelle ou pour étudier plus en détail la qualité des données d'image et de texte.
Utilisation directe :https://go.hyper.ai/pEE7u
4. ShareGPT4V Ensemble de données d'images et de textes de haute qualité à grande échelle
L'ensemble de données contient 1,2 million de paires image-texte qui alignent efficacement les caractéristiques visuelles et linguistiques, améliorent la capacité du modèle à suivre les instructions et intègrent davantage de tâches académiques telles que ScienceQA, TextVQA, SBU, etc.
Utilisation directe :https://go.hyper.ai/9CVao
5. RLAIF-V-Dataset Ensemble de données de préférences multimodales à grande échelle
L'ensemble de données RLAIF-V est un ensemble de données de préférences multimodales généré par l'IA qui couvre une variété de tâches et de domaines. L'ensemble de données contient plus de 44 757 paires de haute qualité pour la formation et l'évaluation de modèles linguistiques multimodaux de grande taille.
Utilisation directe :https://go.hyper.ai/cG6fp
6. FoodLogoDet-1500 Ensemble de données de détection de logos alimentaires de haute qualité
L'ensemble de données comprend 1 500 catégories, 99 768 images et 145 400 objets. Il s’agit du premier et du plus grand ensemble de données de détection d’étiquettes alimentaires accessible au public.
Utilisation directe :https://go.hyper.ai/eco23
7. Ensemble de données d'images alimentaires ZSFooD
L'ensemble de données contient 20 603 images d'aliments collectées à partir de 10 scènes de restaurant, chacune comportant plusieurs objets alimentaires annotés avec des cadres de délimitation, constitués de 95 322 cadres de délimitation et de 291 classes.
Utilisation directe :https://go.hyper.ai/6xrrC
8. Ensemble de données d'images d'aliments Food-1K
L'ensemble de données contient plus de 1 000 catégories d'aliments à granularité fine et plus de 500 000 images, et a été utilisé par l'ICCV 2021 pour le concours d'analyse alimentaire à grande échelle Workshop LargeFineFoodAI.
Utilisation directe :https://go.hyper.ai/sjZJi
9. Ensemble de données d'images alimentaires ISIA Ingredient-201
Cet ensemble de données comprend 201 sous-catégories, couvrant les types courants de catégories alimentaires existantes. Les images d’aliments ont été collectées dans 5 scènes liées à l’alimentation, et au moins 150 catégories d’aliments ont été collectées dans chaque scène.
Utilisation directe :https://go.hyper.ai/bGe45
10. Ensemble de données sur les plats alimentaires ISIA Food-500
L'ensemble de données contient 399 726 aliments, avec plus de 500 plats. Chaque élément contient le nom et l'image de l'aliment.
Utilisation directe :https://go.hyper.ai/yqco5
Pour plus d'ensembles de données publics, veuillez visiter :
Tutoriels publics sélectionnés
Le modèle DynamiCrafter lancé par l'Université chinoise de Hong Kong, Tencent AI Lab et d'autres utilise la technologie de diffusion vidéo pour simuler des modèles de mouvement du monde réel et, combiné à des instructions textuelles, peut convertir des images en vidéos dynamiques. Ce tutoriel a créé pour vous un environnement de flux de travail ComfyUI. Vous n’avez pas à vous soucier des erreurs de connexion aux nœuds. Téléchargez simplement des images et saisissez du texte pour fonctionner !
Exécutez en ligne :https://go.hyper.ai/PWzJR
2. N’attendez pas ! Venez découvrir la démo GLM-4-9B-Chat
Cette semaine, Zhipu AI a publié la dernière réalisation open source du grand modèle de base GLM-4 - GLM-4-9B, qui possède pour la première fois des capacités multimodales. Afin de permettre à chacun de découvrir au plus vite ce modèle open source qui prétend « surpasser Llama3-8B », Chao Neuro a lancé le tutoriel « GLM-4-9B-Chat Demo ». Pas besoin de saisir de commandes, cliquez simplement sur Cloner et commencez immédiatement à découvrir les excellentes performances de GLM-4-9B-Chat.
Exécutez en ligne :https://go.hyper.ai/hc5OK
Articles de la communauté
Le groupe de recherche de Hong Liang à l'Université Jiao Tong de Shanghai a proposé le réseau neuronal graphique sensible au microenvironnement PROTLGN, qui peut apprendre et prédire les sites de mutation d'acides aminés bénéfiques à partir de la structure tridimensionnelle des protéines, et guider la conception de mutations à site unique et de mutations multi-sites de protéines avec différentes fonctions. Les protéines mutantes à point unique conçues par PROTLGN dépassant 40% sont supérieures à leurs homologues de type sauvage. Les résultats pertinents ont été publiés dans « JCM ».
Voir le rapport complet :https://go.hyper.ai/6FkFu
L'équipe de Kang Jianqiang de l'Université de technologie de Wuhan a proposé un modèle électrochimique simplifié d'apprentissage d'ensemble (ELM) + FIE. ELM prédit avec précision la concentration en ions lithium de l'électrode solide, permettant une prédiction de tension plus précise qu'un modèle unique, et sa complexité de calcul est bien inférieure à celle du modèle P2D. FIE prédit avec précision la concentration en ions lithium dans l'électrolyte à proximité des collecteurs de courant positif et négatif.
Voir le rapport complet :https://go.hyper.ai/CWvce
Le groupe de recherche du professeur Mei Yongfeng du département des sciences des matériaux de l'université de Fudan a proposé une méthode d'analyse par éléments finis quasi-statique à plusieurs niveaux et a conçu et construit six types de microstructures tridimensionnelles assemblées de nanofilms de silicium/chrome et les détecteurs optiques tridimensionnels correspondants, vérifiant la bonne polyvalence et la praticabilité industrielle de la technologie. Les résultats pertinents ont été publiés dans « Nature ».
Voir le rapport complet :https://go.hyper.ai/2s73Q
Articles populaires de l'encyclopédie
1. Norme nucléaire
2. Modélisation du langage masqué (MLM)
3. Mémoire à long et à court terme Mémoire à long terme
4. Détection d'objets de bout en bout en temps réel YOLOv10
5. Réseaux de Kolmogorov-Arnold
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Aperçu de la diffusion en direct de la station B
Apple organisera la WWDC24 le 11 juin (mardi prochain), heure de Pékin. Le compte HyperAI Super Neural Video et Bilibili le diffuseront en temps réel. Bienvenue pour scanner le code QR pour prendre rendez-vous pour la diffusion en direct↓

Afin de vous aider à mieux comprendre les informations pertinentes d'Apple,La salle de diffusion en direct de la station Super Neuro B continuera de diffuser la vidéo « Apple Special ».Comprend : les conférences WWDC passées, les entretiens avec les dirigeants, les documentaires connexes et d'autres contenus riches.
Le tableau suivant est un aperçu du contenu sélectionné par l'éditeur↓↓↓
| date | temps | contenu |
| Lundi 10 juin | 18:00 | Steve Jobs |
| Mardi 11 juin | 1:00 | Apple WWDC24 |
| Mercredi 12 juin | 18:00 | Qu'est-ce qui fait d'Apple |
| Jeudi 13 juin | 18:00 | Première sortie de l'iPhone |
| Vendredi 14 juin | 18:00 | Histoire de Steve Jobs |
| Samedi 15 juin | 18:00 | Comment Apple a survécu à la quasi-faillite |
| Dimanche 16 juin | 18:00 | L'histoire de Tim Cook |
Super Neuro TV diffuse en direct 24h/24 et 7j/7. Cliquez pour obtenir les « cornichons électroniques » dans le domaine de l'IA :
http://live.bilibili.com/26483094
La date limite pour la conférence est juin-juillet
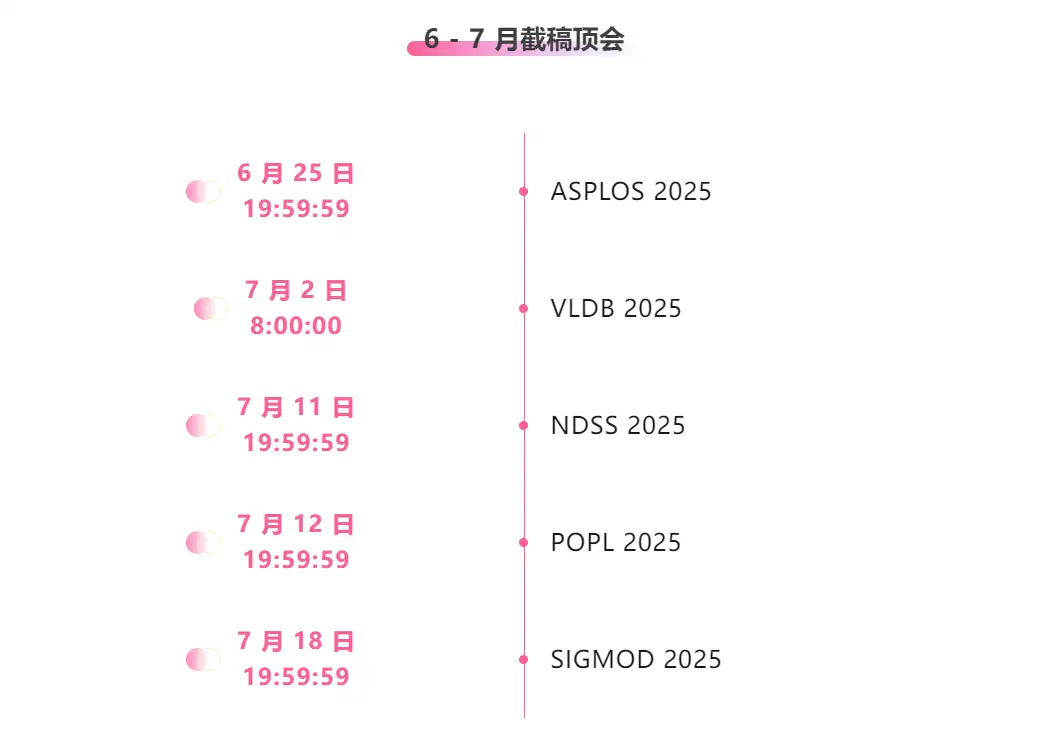
Suivi unique des principales conférences universitaires sur l'IA :https://hyper.ai/events
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 200 ensembles de données publiques
* Comprend plus de 300 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








