HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends
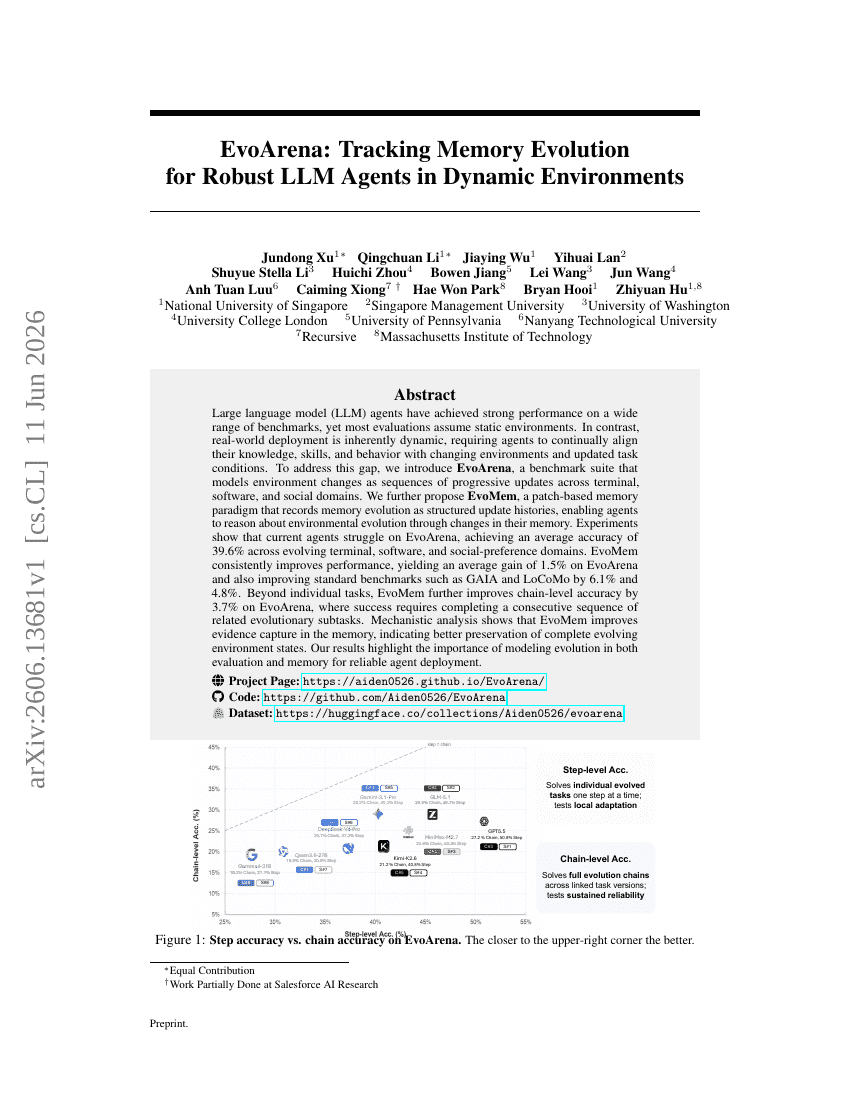
EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments

Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction

























EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
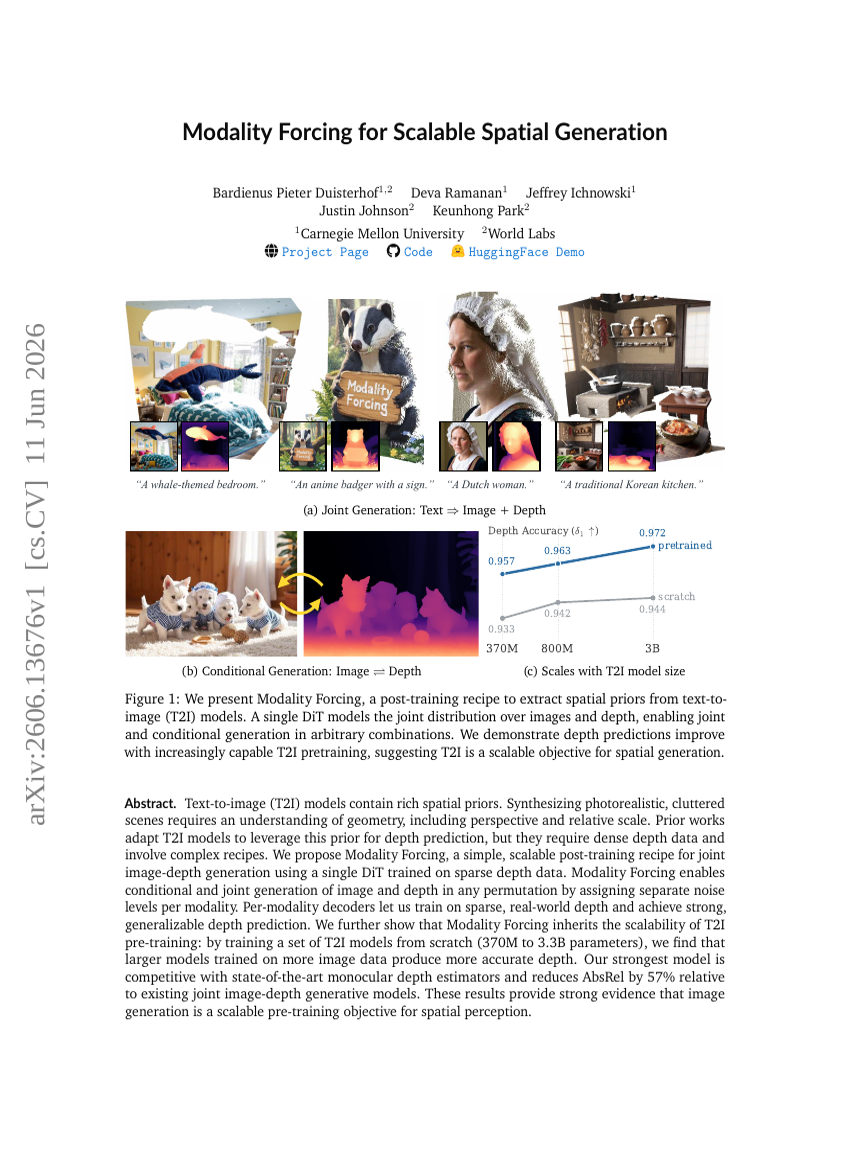
Modality Forcing for Scalable Spatial Generation
From AGI to ASI
World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Regularized f-Divergence Kernel Tests
Pretraining Recurrent Networks without Recurrence
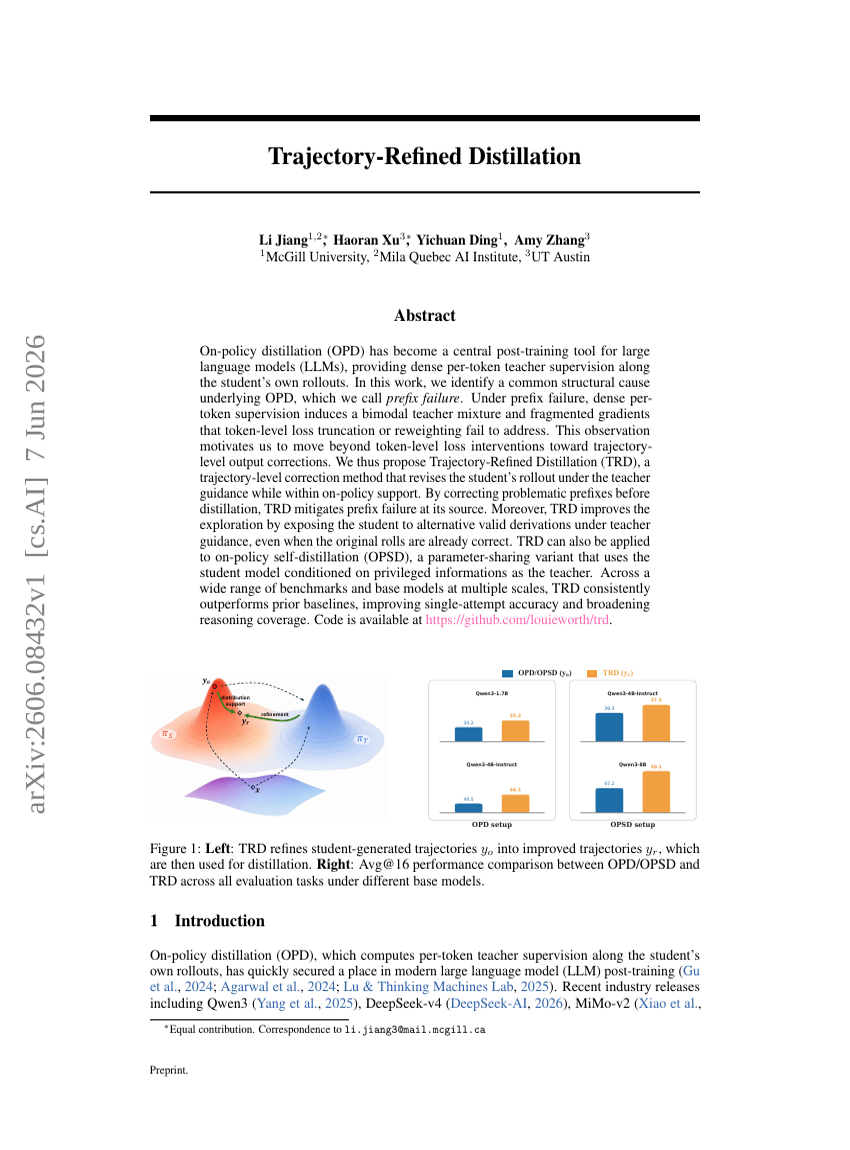
Trajectory-Refined Distillation
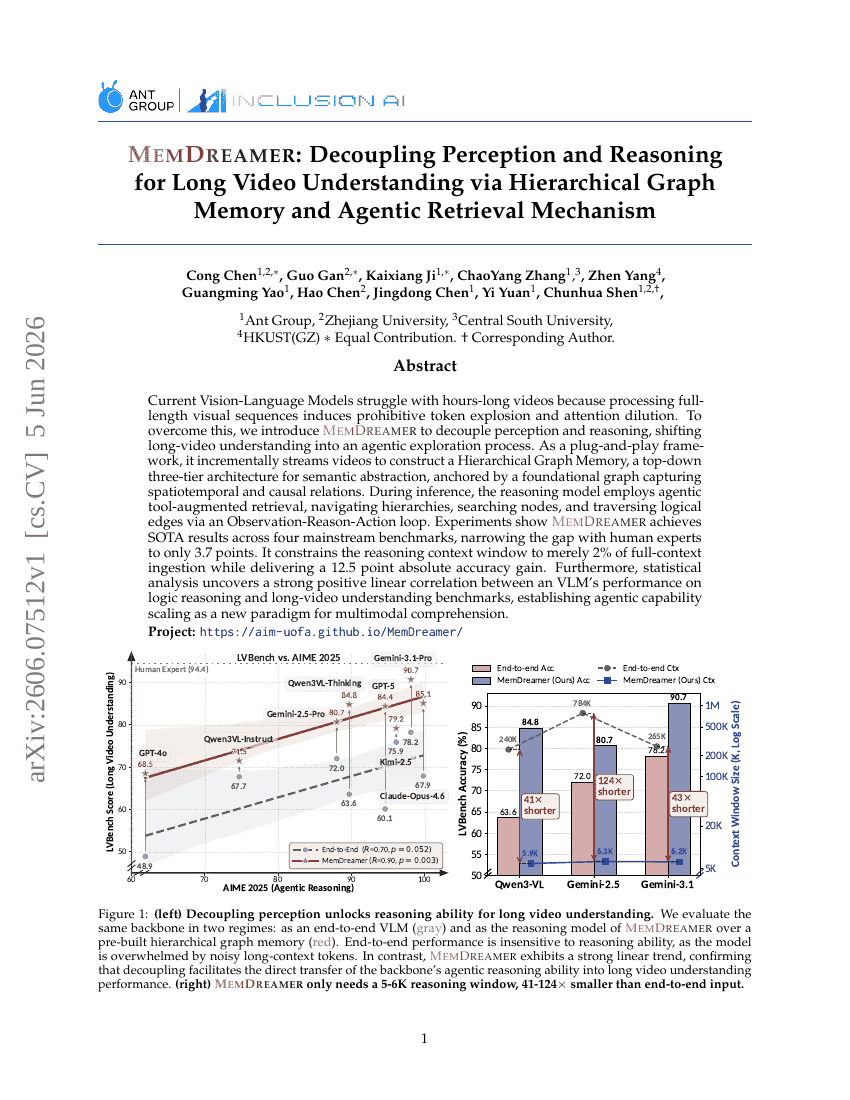
MemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism
SearchSwarm: Towards Delegation Intelligence in Agentic LLMs for Long-Horizon Deep Research
Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
ABot-Earth 0.5: Generative 3D Earth Model
Kwai Keye-VL-2.0 Technical Report
TESSERA: Temporal Embeddings of Surface Spectra for Earth Representation and Analysis
If LLMs have human-like attributes, then so does Age of Empires II
The Last Human-Written Paper: Agent-Native Research Artifacts
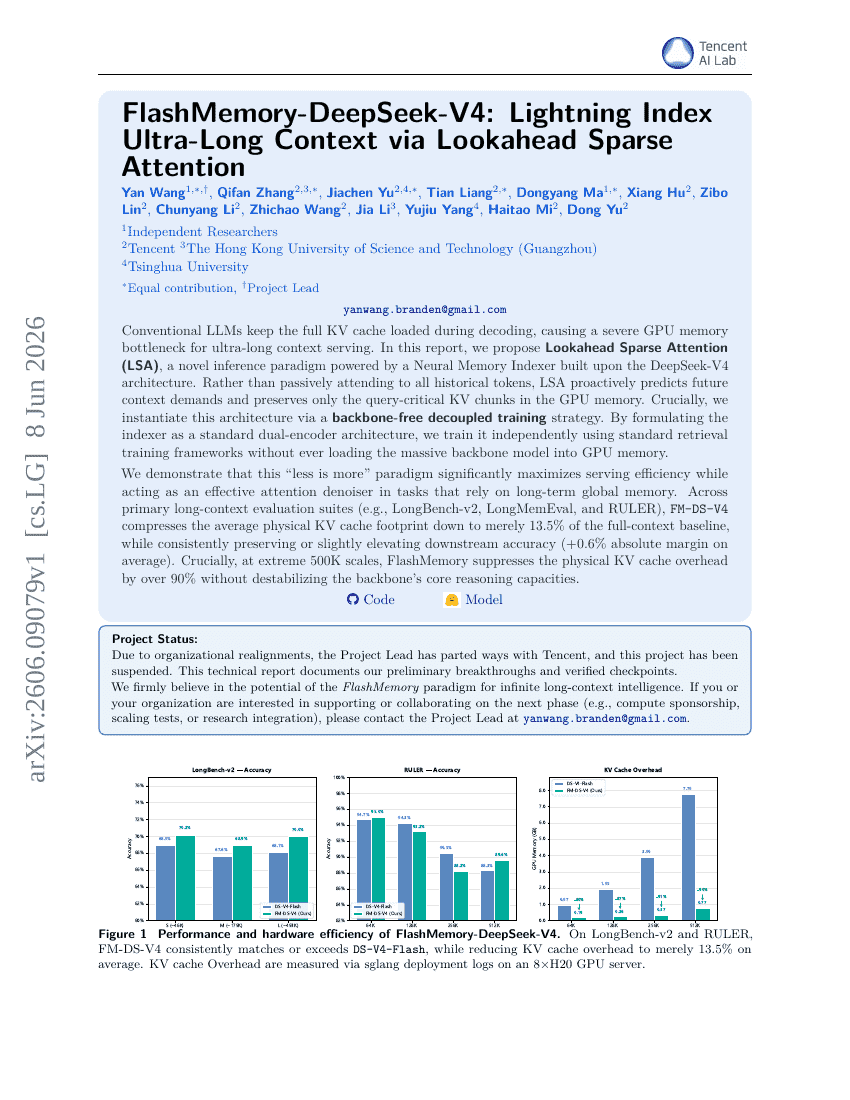
FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
CoVEBench: Can Video Editing Models Handle Complex Instructions?
Latent Spatial Memory for Video World Models
On the Geometry of On-Policy Distillation
SWE-Explore: Benchmarking How Coding Agents Explore Repositories
VoxCPM2 Technical Report
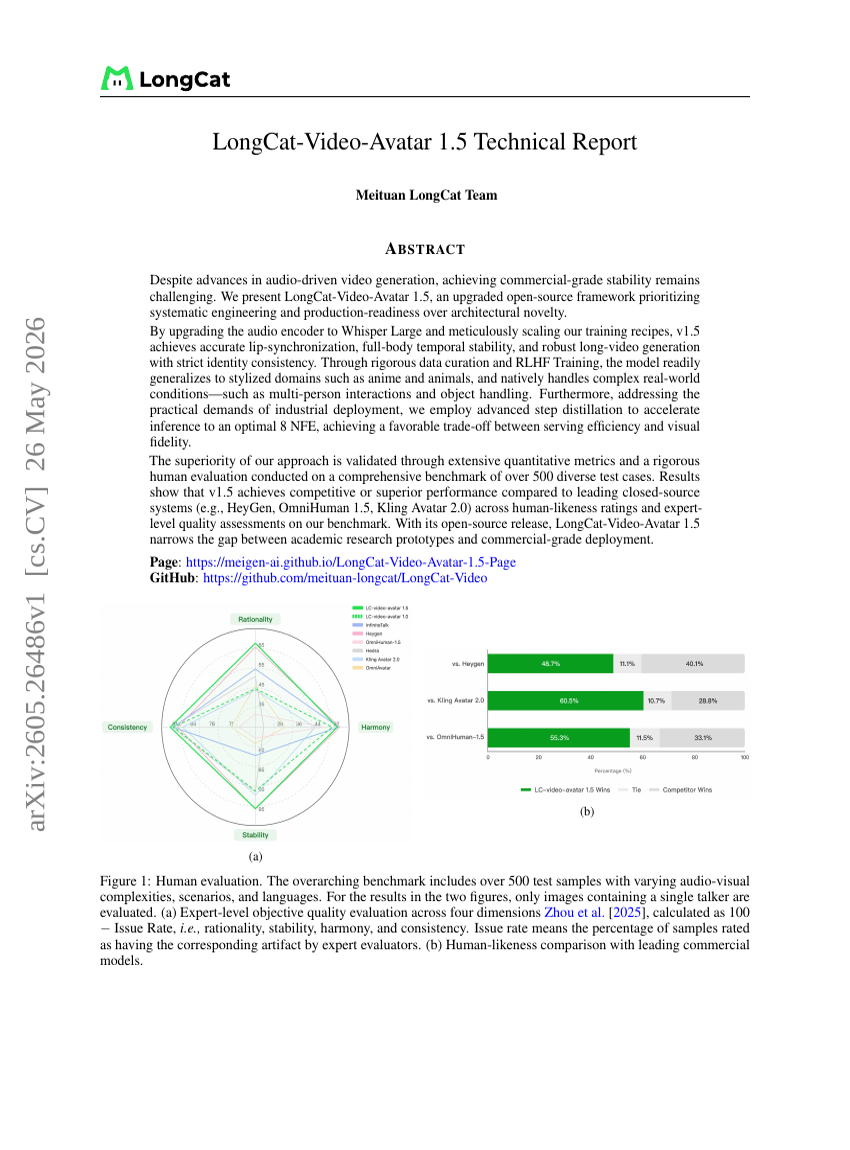
LongCat-Video-Avatar 1.5 Technical Report
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
ACL-Verbatim: hallucination-free question answering for research
Beyond Static Dialogues: Benchmarking Realistic, Heterogeneous, and Evolving Long-Term Memory
The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Direct 3D-Aware Object Insertion via Decomposed Visual Proxies
Modality Forcing for Scalable Spatial Generation
From AGI to ASI
World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Regularized f-Divergence Kernel Tests
Pretraining Recurrent Networks without Recurrence
Trajectory-Refined Distillation
MemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism
SearchSwarm: Towards Delegation Intelligence in Agentic LLMs for Long-Horizon Deep Research
Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
ABot-Earth 0.5: Generative 3D Earth Model
Kwai Keye-VL-2.0 Technical Report
TESSERA: Temporal Embeddings of Surface Spectra for Earth Representation and Analysis
If LLMs have human-like attributes, then so does Age of Empires II
The Last Human-Written Paper: Agent-Native Research Artifacts
FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
CoVEBench: Can Video Editing Models Handle Complex Instructions?
Latent Spatial Memory for Video World Models
On the Geometry of On-Policy Distillation
SWE-Explore: Benchmarking How Coding Agents Explore Repositories
VoxCPM2 Technical Report
LongCat-Video-Avatar 1.5 Technical Report
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
ACL-Verbatim: hallucination-free question answering for research
Beyond Static Dialogues: Benchmarking Realistic, Heterogeneous, and Evolving Long-Term Memory
The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Direct 3D-Aware Object Insertion via Decomposed Visual Proxies