Command Palette
Search for a command to run...
The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm
The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm
Zhenfeng Cao
Abstract
For over half a century, software engineering has operated on a foundational premise: human engineers decompose problems, encode decision logic into static code, and manually adapt that code as requirements evolve. This paper argues that the emergence of AI agents – systems where large language models serve as the primary reasoning engine, dynamically generating and discarding code as an instrumental resource – constitutes not an incremental improvement but a fundamental restructuring of the software paradigm. Drawing on first-principles analysis of complexity scaling, we formalize the distinction between traditional software (where code is the carrier of decision logic) and agentic systems (where code is ephemeral tooling for an LLM-driven reasoning loop). We trace the historical arc from licensed software to SaaS to what we term Agent-as-a-Service (AaaS), showing that each shift transferred additional complexity away from end-users. We introduce the concept of Agentic Engineering as an emergent discipline – distinct from software engineering in its core object of study, control model, and human role. Through analysis of recent benchmark evidence including SWE-bench Verified, EvoClaw, and LangChain's multi-agent coordination studies, we demonstrate both the transformative potential of the agentic paradigm and its current limitations.
One-sentence Summary
This paper argues that AI agents fundamentally restructure the software paradigm by treating code as ephemeral tooling for LLM-driven reasoning loops rather than the carrier of decision logic, formalizing Agentic Engineering and Agent-as-a-Service (AaaS) through first-principles analysis of complexity scaling while demonstrating transformative potential and limitations via SWE-bench Verified, EvoClaw, and LangChain's multi-agent coordination studies.
Key Contributions
- This work formalizes the distinction between traditional software and agentic systems through a first-principles analysis of complexity scaling, defining code as either a carrier of logic or ephemeral tooling.
- The paper introduces Agentic Engineering as a distinct emergent discipline and proposes the term Agent-as-a-Service to characterize the historical shift from licensed software to SaaS.
- Analysis of recent benchmark evidence including SWE-bench Verified and EvoClaw demonstrates the transformative potential of the agentic paradigm alongside its current limitations in sustained autonomous development.
Introduction
Traditional software engineering relies on human engineers encoding decision logic into static code, yet this model struggles with exponential complexity scaling as system interactions grow combinatorially. Current AI-augmented development approaches fail to remove the human bottleneck from design decisions and maintain the latency of traditional software lifecycles. The authors contend that AI agents constitute a fundamental restructuring of the software paradigm where code serves as ephemeral tooling for an LLM-driven reasoning loop instead of the system itself. They formalize this shift as Agent-as-a-Service and introduce Agentic Engineering as a distinct discipline focused on intent architecture and multi-agent coordination.
Method
The proposed agentic system operates on a dynamic architecture where decision logic is generated at runtime rather than being statically pre-programmed. As defined in the formal model, an AI agent system A is characterized by the tuple A=(M,T,M,Π), where M represents the large language model serving as the reasoning engine, T denotes the set of executable tools, M is the memory subsystem, and Π is the planning mechanism.
The overall framework is illustrated in the diagram below, which depicts the central role of the LLM Reasoning Core in orchestrating interactions with the external environment.
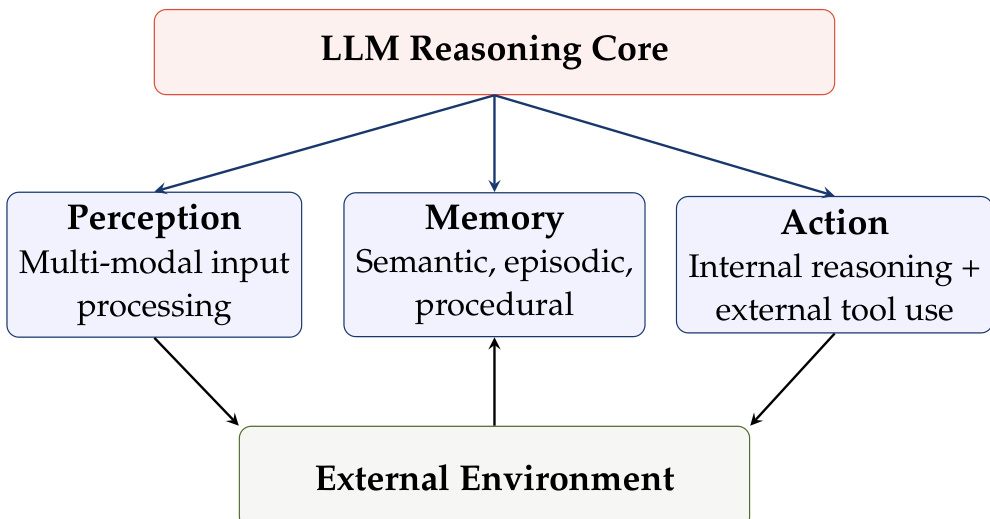
The architecture consists of three primary functional modules branching from the core. The Perception module handles multi-modal input processing, translating raw environmental data into a format the reasoning engine can utilize. The Memory module manages semantic, episodic, and procedural information, allowing the system to maintain context and learn from past interactions. The Action module encompasses both internal reasoning processes and the invocation of external tools, enabling the agent to execute code, query databases, or call APIs.
The system operates through an iterative execution loop. At each time step t, the model M selects an action at based on the current state st and the memory subsystem M, formalized as at←M(st,M). The system state is then updated by executing the chosen action, denoted as st+1←exec(at). Unlike traditional software where decision rules D are fixed, this agentic approach allows the LLM to dynamically produce code and adjust behavior based on intermediate results. This paradigm shifts the focus from delivering software artifacts to delivering outcomes, where the agent autonomously plans, executes, and validates tasks to fulfill user intent.
Experiment
Empirical evaluations utilizing benchmarks such as SWE-bench Verified and enterprise debugging workflows demonstrate that agentic engineering outperforms traditional paradigms through process-centric training and multi-agent orchestration. These studies validate that coordinated agents can reduce debugging time and autonomously evolve skills, yet the EvoClaw benchmark exposes significant limitations in continuous software evolution. Consequently, while current systems generalize across the software lifecycle, they face persistent challenges regarding context drift and error propagation during long-term maintenance tasks.