Command Palette
Search for a command to run...
ACL-Verbatim: hallucination-free question answering for research
ACL-Verbatim: hallucination-free question answering for research
Gábor Recski Szilveszter Tóth Nadia Verdha István Boros Ádám Kovács
Abstract
Academic researchers need efficient and reliable methods for collecting high-quality information from trusted sources, but modern tools for AI-assisted research still suffer from the tendency of Large Language Models (LLMs) to produce factually inaccurate or nonsensical output, commonly referred to as hallucinations. We apply the extractive question answering system VerbatimRAG (Kovacs et al., 2025) to research papers in the ACL Anthology, directly mapping user queries to verbatim text spans in retrieved documents. We contribute a novel ground truth dataset for the task of mapping user queries to relevant text spans in research papers, and use it to train and evaluate a variety of extractive models. Human annotation is performed by NLP researchers and is based on synthetic user queries generated using a custom pipeline based on the ScIRGen methodology (Lin et al., 2025), paired with chunks of research papers retrieved by VerbatimRAG. On this benchmark, a 150M-parameter ModernBERT token classifier trained on silver supervision from our pipeline achieves the best word-level F1 (53.6), ahead of the strongest evaluated LLM extractor (48.7).
One-sentence Summary
ACL-Verbatim enables hallucination-free question answering by applying the extractive VerbatimRAG system to ACL Anthology papers and contributing a novel ground truth dataset for mapping queries to text spans, where a 150M-parameter ModernBERT token classifier trained on silver supervision achieves a word-level F1 of 53.6, outperforming the strongest evaluated LLM extractor at 48.7.
Key Contributions
- A novel ground truth dataset is contributed for mapping user queries to relevant text spans in research papers from the ACL Anthology. This dataset is used to train and evaluate a variety of extractive models.
- Human annotation is performed by NLP researchers using synthetic user queries generated via a custom pipeline based on the ScIRGen methodology. These queries are paired with chunks of research papers retrieved by VerbatimRAG.
- A 150M-parameter ModernBERT token classifier trained on silver supervision from the pipeline achieves the best word-level F1 score of 53.6 on the benchmark. This performance exceeds the strongest evaluated LLM extractor, which achieved a score of 48.7.
Introduction
Researchers rely on scientific literature for trusted information, yet large language models introduce significant risks regarding transparency and reliability. Even retrieval-augmented generation systems struggle with hallucinations where models override retrieved evidence with prior knowledge, making verification tedious and often omitted. The authors address these challenges with ACL-Verbatim, an extractive question answering system that returns only text spans verbatim from source documents to eliminate hallucinations. They further contribute a benchmark dataset for this task and demonstrate that fine-tuning a compact extraction model on generated data outperforms larger LLM extractors with fewer parameters.
Dataset
-
Dataset Composition and Sources
- The authors build the corpus from the ACL Anthology state as of February 2026.
- They begin with 120,034 entries but discard 5,000 papers hosted by third-party publishers to ensure permissive licensing.
- The remaining 114,567 papers are converted to markdown using the docling library, resulting in 114,475 usable files.
- Metadata and full text are distributed under a CC-BY 4.0 license.
-
Key Details for Each Subset
- Indexing Corpus: Comprises 114,475 markdown documents segmented into chunks ranging from 500 to 5,000 characters.
- Query Generation Sample: Includes 333 randomly selected English papers with at least one author.
- Gold Annotation Set: Contains human labels for 20 queries and 100 chunks annotated by NLP researchers.
- Silver Data: Generated queries and retrieved chunks form the training data for the extractive models.
-
Model Training and Evaluation
- A 150M-parameter ModernBERT token classifier is trained using the silver supervision pipeline.
- The model is evaluated on the human-annotated benchmark to measure word-level F1 scores.
- The system performs extractive question answering by mapping queries to verbatim text spans.
-
Processing and Annotation Strategy
- Chunking Strategy: The pipeline parses section structures and prefixes titles to chunks while preventing splits within tables or code blocks.
- Query Synthesis: Synthetic queries follow the ScIRGen methodology, converting long questions into shorter, fragmented user queries.
- Indexing: Chunks are indexed for both full-text and dense vector search using the granite-embedding-english-r2 model.
- Annotation Workflow: Annotators assign binary relevance labels and highlight specific text spans or figure captions for relevant chunks.
Method
The authors leverage a pipeline to generate silver supervision for training a self-contained student model. This process involves creating synthetic queries from the ACL Anthology corpus and retrieving relevant chunks. As shown in the figure below, the query generation workflow begins with a paper chunk input, which undergoes question type selection (e.g., Comparison, Causal consequence, Goal orientation). This step guides the subsequent question generation phase, where specific inquiries are formulated based on the selected types. Finally, these questions are rewritten into optimized queries (e.g., "matrix factorization vs Dirichlet hierarchical topic modeling") to facilitate retrieval.
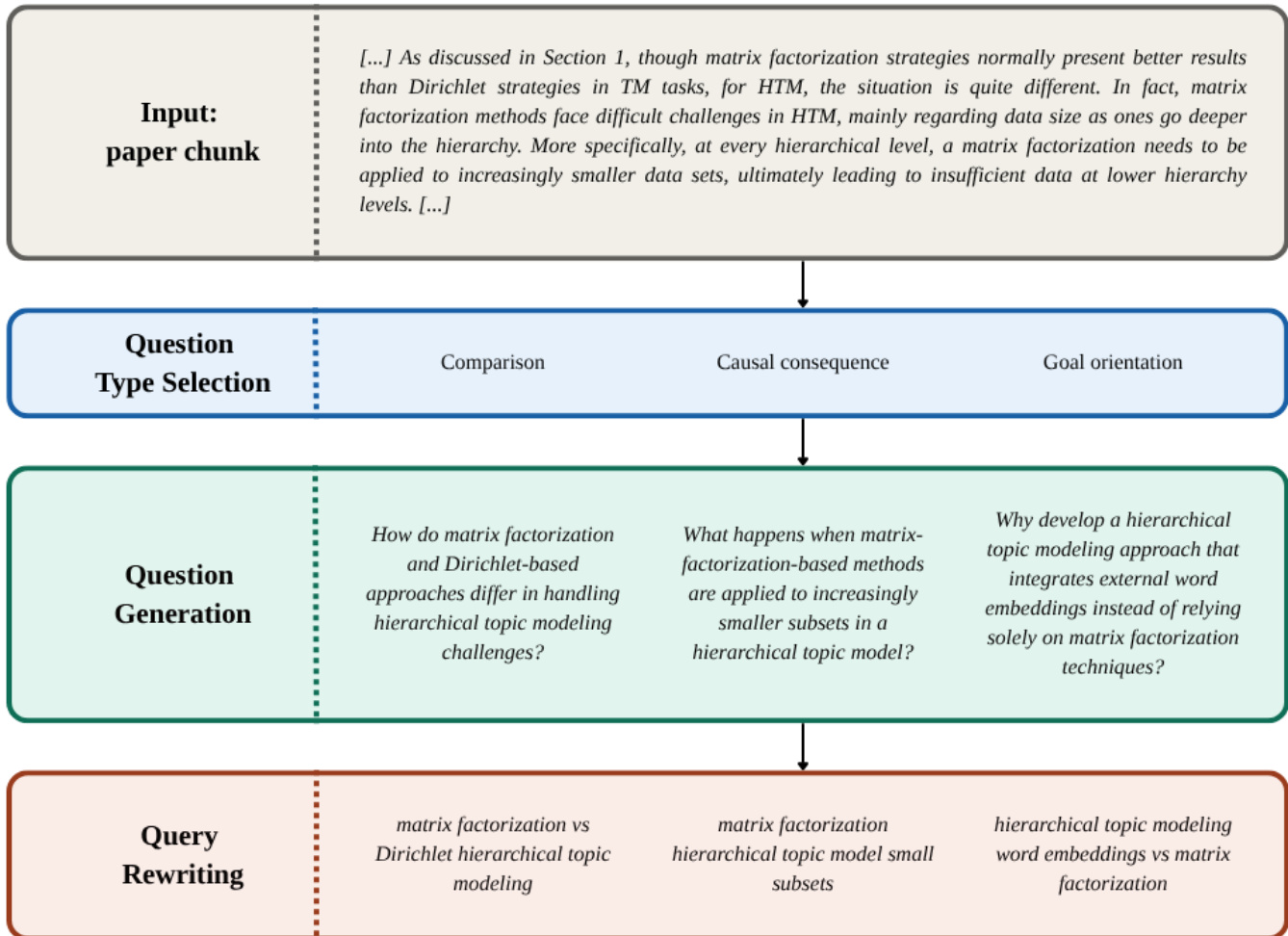
Once the synthetic queries and chunks are established, a large language model (Qwen 3.6 35B) acts as a silver teacher to extract evidence spans or paragraphs using specific prompts (e.g., verbatim or paragraph-style extraction). The resulting dataset consists of query–chunk pairs with binary token labels indicating evidence presence.
The student architecture is designed as a query-conditioned token classifier built upon an 8192-token ModernBERT backbone. The input consists of the concatenation of the question and the document chunk, while the output predicts a binary evidence label for each token, which is subsequently decoded into character spans. The authors compare two backbone configurations: a vanilla ModernBERT-base masked language modeling checkpoint and a cross-encoder reranker model post-trained on query–passage relevance. Training is conducted for 5 epochs with a batch size of 8 and a learning rate of 2×10−5, with the best checkpoint selected based on silver-dev token F1. During inference, two post-processing steps are applied to refine the output: spans shorter than 10 characters are discarded, and neighbouring spans separated by at most 20 characters are merged to prevent token-level fragmentation.
Experiment
The evaluation utilizes a manually annotated benchmark to compare LLM-based extractors, existing pruning baselines, and a compact student model trained on synthetic data. Results indicate that the specialized student model achieves superior precision by effectively abstaining on irrelevant chunks, whereas LLMs tend to extract false positives despite higher recall. Overall, the experiments demonstrate that small, customized architectures trained with task-oriented data outperform zero-shot large language models in evidence extraction while operating at a fraction of the computational cost.
The authors evaluate extractive models on a benchmark of 100 query-chunk pairs, comparing LLM-based extractors, pruning baselines, and their own compact student models. The results indicate that the authors' specialized student model achieves the highest word-level precision and F1 score, outperforming larger LLM extractors and standard baselines while operating with significantly lower latency. While LLM extractors often achieve higher recall, they tend to have lower precision by extracting evidence from irrelevant chunks, whereas the student model demonstrates a stronger ability to abstain on non-relevant content. The specialized student model outperforms LLM extractors and baselines in word-level precision and F1 score. LLM extractors generally achieve higher recall but suffer from lower precision, often extracting spans from irrelevant chunks. The student models operate with significantly lower latency compared to the larger LLM extractors.
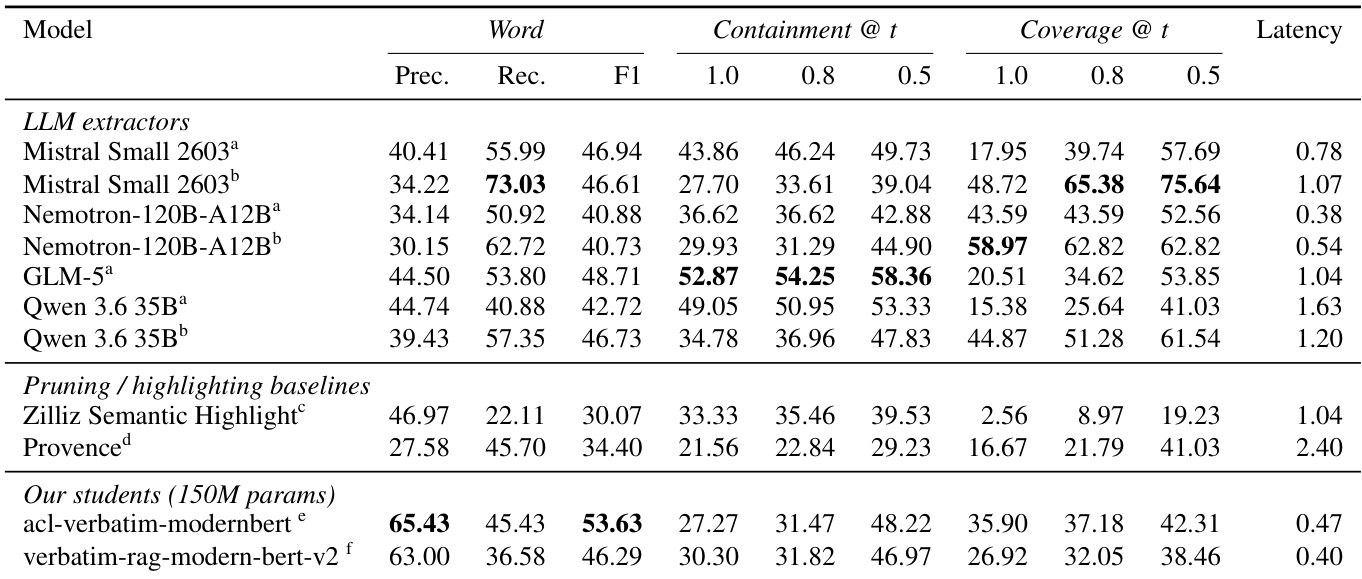
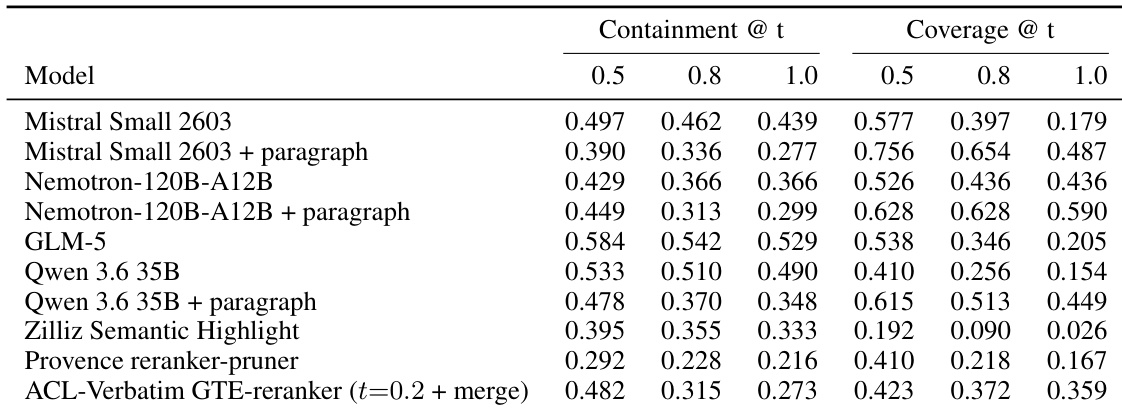
The the the table compares containment and coverage scores across various extraction models, including LLMs with different prompting strategies and specialized baselines. Results indicate that while standard LLM configurations often prioritize containment, utilizing paragraph-oriented prompts significantly boosts coverage at the cost of containment. LLM-based extractors generally achieve higher scores than the Zilliz and Provence baselines across both containment and coverage metrics. Applying paragraph-oriented prompts to LLMs consistently increases coverage while decreasing containment compared to their default configurations. The ACL-Verbatim GTE-reranker achieves moderate performance levels that balance the high coverage of paragraph-prompted models with the higher containment of standard LLMs.
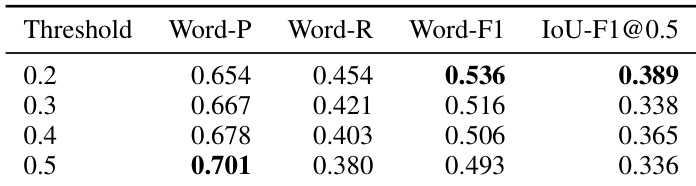
The authors evaluate the student model across various probability thresholds to determine optimal inference settings. The results demonstrate that the lowest threshold setting yields the highest Word-F1 score. Increasing the threshold value leads to higher precision but lower recall, which negatively impacts the overall F1 metric. The lowest threshold setting yields the highest Word-F1 score. Precision improves as the probability threshold increases. Recall declines as the probability threshold increases.
The authors evaluate extractive models on a benchmark of query-chunk pairs to compare LLM-based extractors, baselines, and compact student models. Results indicate that the specialized student model achieves higher precision and efficiency while avoiding irrelevant content, whereas standard LLM extractors prioritize recall at the cost of precision. Additional experiments on containment and coverage demonstrate that prompting strategies significantly impact retrieval balance, and threshold tuning confirms that lower probability settings optimize the model's overall performance.