Command Palette
Search for a command to run...
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Guibao Shen Yihua Du Wenhang Ge Jing He Chirui Chang Donghao Zhou Zhen Yang Luozhou Wang Xin Tao Ying-Cong Chen
Abstract
The rapid growth of stereoscopic displays, including VR headsets and 3D cinemas, has led to increasing demand for high-quality stereo video content. However, producing 3D videos remains costly and complex, while automatic Monocular-to-Stereo conversion is hindered by the limitations of the multi-stage ``Depth-Warp-Inpaint'' (DWI) pipeline. This paradigm suffers from error propagation, depth ambiguity, and format inconsistency between parallel and converged stereo configurations. To address these challenges, we introduce UniStereo, the first large-scale unified dataset for stereo video conversion, covering both stereo formats to enable fair benchmarking and robust model training. Building upon this dataset, we propose StereoPilot, an efficient feed-forward model that directly synthesizes the target view without relying on explicit depth maps or iterative diffusion sampling. Equipped with a learnable domain switcher and a cycle consistency loss, StereoPilot adapts seamlessly to different stereo formats and achieves improved consistency. Extensive experiments demonstrate that StereoPilot significantly outperforms state-of-the-art methods in both visual fidelity and computational efficiency. Project page: https://hit-perfect.github.io/StereoPilot/.
One-sentence Summary
Researchers from HKUST(GZ) and Kuaishou's Kling Team et al. propose StereoPilot, an efficient feed-forward model for monocular-to-stereo video conversion that directly synthesizes target views without depth maps or diffusion sampling. Using a learnable domain switcher and cycle consistency loss, it overcomes error propagation in traditional depth-warp-inpaint pipelines, significantly improving quality and speed for VR and 3D content generation.
Key Contributions
- The paper addresses key limitations in monocular-to-stereo video conversion, where traditional multi-stage "Depth-Warp-Inpaint" pipelines suffer from error propagation, depth ambiguity in reflective/translucent scenes, and format inconsistency between parallel and converged stereo configurations.
- It introduces StereoPilot, an efficient feed-forward model that directly synthesizes target views in a single step without explicit depth maps or iterative diffusion sampling, using a learnable domain switcher for cross-format compatibility and cycle consistency loss for view alignment.
- Built upon the first large-scale unified UniStereo dataset covering both stereo formats, extensive experiments show StereoPilot significantly outperforms state-of-the-art methods in visual fidelity and computational efficiency.
Introduction
Stereoscopic displays like VR headsets and 3D cinemas drive demand for high-quality stereo video, but producing 3D content remains expensive and manual. Current monocular-to-stereo conversion relies on multi-stage Depth-Warp-Inpaint pipelines that suffer from error propagation, depth ambiguity, and inconsistent handling of parallel versus converged stereo formats. Prior novel view synthesis methods also struggle due to requirements for multi-view training data or limited camera controllability. The authors introduce UniStereo, the first large-scale unified dataset covering both stereo formats, and StereoPilot, an efficient feed-forward model that directly synthesizes target views without explicit depth maps or iterative diffusion. StereoPilot incorporates a learnable domain switcher and cycle consistency loss to seamlessly adapt between stereo formats while significantly improving visual quality and computational speed over existing approaches.
Dataset
The authors introduce UniStereo, the first large-scale unified dataset for stereo video conversion, combining parallel and converged stereo formats to address evaluation inconsistencies in prior work. It comprises two key subsets:
• Stereo4D (parallel format): Sourced from 7,000 YouTube VR180 videos, yielding ~60,000 clips after processing. Clips are standardized to 832×480 resolution, 16 fps, and fixed 81-frame lengths (5 seconds). Non-informative content is filtered, and ShareGPT4Video generates captions for left-eye views.
• 3DMovie (converged format): Built from 142 verified 3D films, producing ~48,000 clips. The authors manually excluded "pseudo-stereo" content and non-SBS formats. Processing includes removing credits/logos, symmetric black-border cropping, resampling to 16 fps, and segmenting into 81-frame clips with ShareGPT4Video captions.
For training, the authors mix 58,000 Stereo4D and 44,879 3DMovie clips. Evaluation uses separate 400-clip test sets per subset. All data undergoes strict standardization: resolution fixed at 832×480, temporal alignment to 81 frames, and caption generation exclusively for left-eye videos to support text-guided conversion.
Method
The authors leverage a novel “diffusion as feed-forward” architecture to address the deterministic nature of monocular-to-stereo video conversion, circumventing the inefficiencies and artifacts inherent in iterative diffusion or depth-warp-inpaint pipelines. The core innovation lies in repurposing a pretrained video diffusion transformer—not as a generative model requiring dozens of sampling steps, but as a single-step deterministic predictor. This is achieved by fixing the diffusion time-step to a near-zero value t0=0.001, where the model’s input state closely approximates the real data distribution. The transformation from left to right view is then expressed as a direct mapping: zr=vθ(zl,t0,c), where zl and zr denote the latent representations of the left and right views, respectively, and c is a text conditioning signal. This formulation enables inference in a single forward pass, drastically reducing computational cost while preserving the rich generative priors of the pretrained model for occlusion completion.
To handle the coexistence of parallel and converged stereo formats—which exhibit fundamentally different geometric relationships—the authors introduce a learnable domain switcher s. This switcher, implemented as a one-dimensional vector added to the time embeddings of the diffusion model, allows a single unified architecture to conditionally generate either format. The model’s behavior is governed by a piecewise function: for a stereo pair (zl,zr) belonging to the converged domain Dc, the output is computed as vθ(zl,t0,c,sc); for the parallel domain Dp, it uses vθ(zl,t0,c,sp). This design avoids the need for separate models and mitigates domain-specific biases, enabling robust generalization across diverse content types, including synthetic animation styles that typically challenge models trained on only one format.
Refer to the framework diagram for a visual overview of the training architecture. The model employs two symmetric transformers: vl→r,θl for left-to-right synthesis and vr→l,θr for right-to-left synthesis. Both are conditioned on the same time-step t0, text caption c, and domain switcher s. The training objective combines reconstruction and cycle-consistency losses. The reconstruction loss Lrecon=∥z^r−zr∥22+∥z^l−zl∥22 ensures fidelity to ground-truth views. The cycle-consistency loss Lcycle=∥zl−z^lc∥22, where z^lc=vr→l,θr(z^r,t0,c,s), enforces geometric alignment by requiring that translating a view to the opposite eye and back recovers the original. The total loss is L=Lrecon+λ⋅Lcycle, jointly optimizing both generators for high-fidelity, temporally consistent stereo output.

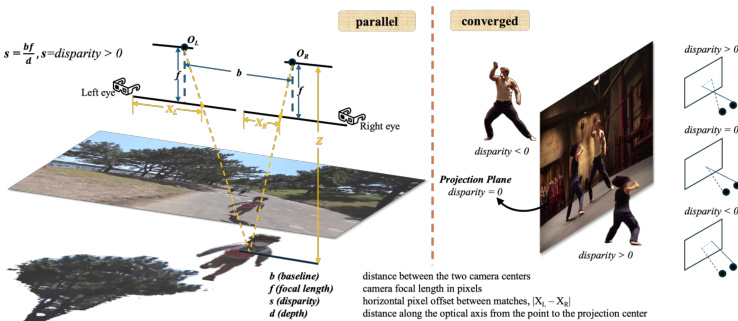
As shown in the figure below, the geometric disparity relationships differ significantly between parallel and converged stereo configurations. In parallel setups, disparity d is inversely proportional to depth Z, following Z=f⋅B/d, where f is focal length and B is baseline. In converged setups, the optical axes intersect at a convergence distance, introducing keystone distortion and breaking the simple inverse relationship. The domain switcher in StereoPilot implicitly learns to adapt to these distinct geometries without requiring explicit depth estimation or warping, thereby avoiding the depth ambiguity artifacts that plague multi-stage pipelines—such as virtual images appearing on reflective surfaces—as illustrated in the depth ambiguity diagram.
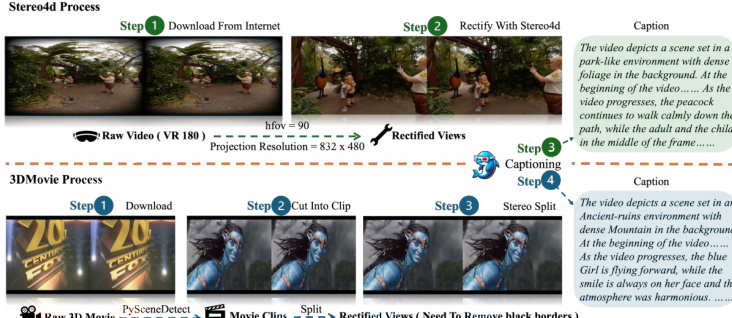
The data preprocessing pipeline, depicted in the figure below, unifies inputs from diverse sources—including VR180 and side-by-side (SBS) 3D movies—into a standardized format. For VR180 content, the authors rectify the video using Stereo4D with a horizontal field of view of 90∘ and a projection resolution of 832×480. For SBS films, they segment clips, filter non-informative segments, convert to left/right monocular views, and remove black borders. All resulting videos are captioned using ShareGPT4Video to provide the text conditioning signal c used during training and inference.
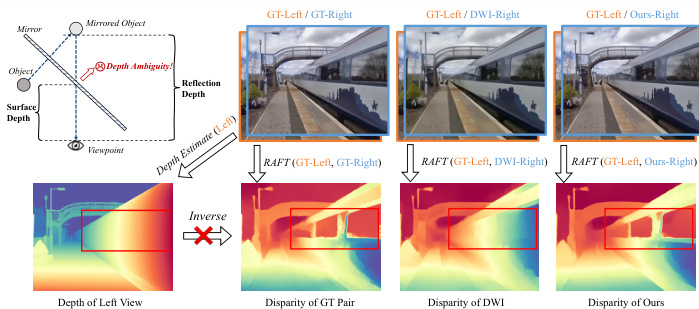
The authors further illustrate the failure modes of prior methods in the depth ambiguity diagram. Multi-stage pipelines that rely on a single depth map per pixel cannot resolve scenes with reflections or transparent materials, where a single pixel corresponds to multiple depth values. This leads to artifacts such as virtual images being “baked” onto mirror surfaces. In contrast, StereoPilot’s direct, diffusion-based synthesis bypasses depth estimation entirely, allowing it to generate physically plausible stereo views without such artifacts.
Experiment
- StereoPilot outperforms state-of-the-art methods including StereoDiffusion, SVG, and Mono2Stereo across all 5 quantitative metrics on Stereo4D and 3DMovies datasets while processing 81-frame videos in 11 seconds.
- Ablation studies validate the domain switcher's critical role in enhancing generalization, demonstrating significant performance gains on unseen UE5 synthetic data for parallel-style stereo conversion.
The authors evaluate ablation variants of StereoPilot using five quantitative metrics on averaged Stereo4D and 3DMovie test sets. Results show that adding the domain switcher improves all metrics over the baseline, and further incorporating the cycle consistent loss yields the best performance across SSIM, MS-SSIM, PSNR, LPIPS, and SIOU.

The authors use StereoPilot to outperform all compared methods across five quantitative metrics on both Stereo4D and 3D Movie datasets, while completing stereo conversion of an 81-frame video in just 11 seconds. Results show consistent superiority in SSIM, MS-SSIM, PSNR, LPIPS, and SIOU, with significantly lower latency than all baselines. The method also demonstrates strong generalization without requiring domain-specific training data.

The authors evaluate the impact of their domain switcher by comparing a baseline model with and without the switcher, using averaged performance across two datasets. Results show that adding the switcher improves all five metrics: SSIM, MS-SSIM, PSNR, and SIOU increase, while LPIPS decreases, indicating better structural similarity, perceptual quality, and semantic consistency. This confirms the switcher’s role in enhancing generalization and model performance.
