Command Palette
Search for a command to run...
Cambridge University and Others Have Proposed a pixel-level Fundamental Model for Earth Observation Missions, Achieving state-of-the-art (SOTA) Accuracy in Multiple missions.

Earth observation satellites, capable of monitoring the Earth over large areas and long periods, have become crucial tools in fields such as agricultural production, forest management, ecological monitoring, and land governance. Using long-term remote sensing data acquired by satellites, researchers can track dynamic changes on the Earth's surface. However, real satellite observation data is far from perfect: cloud cover, irregular orbital revisit periods, sensor resolution mismatch, and equipment noise are among the interference factors.This results in incomplete, heterogeneous, and disordered raw data, making it difficult to use directly for high-precision intelligent analysis.Especially in detailed scenarios such as agricultural phenology and short-term ecological disturbances, clouds can directly obscure key change processes.
Currently, the industry commonly uses image compositing technology to remove clouds and reduce noise, generating standardized cloudless images. While this does improve data quality and usability, it also leads to significant information loss.Fine temporal features such as phenological dynamics and short-term abrupt changes are often weakened or even erased during the synthesis process, resulting in the loss of some key information.
In recent years, remote sensing basic models have made great progress through large-scale pre-training. However, most models still rely on ideal data that has undergone deep filtering and normalization, using only cloudless synthetic imagery or time-series mean data during training. This approach effectively discards a large amount of observational data that, although affected by cloud cover, still contains real patterns of change. Consequently, when faced with sparse, incomplete, and complex cloud-covered time-series data in actual operational scenarios, the models struggle.Unstable feature extraction significantly reduces generalization ability.
To overcome this bottleneck, a joint research team from the University of Cambridge, Aalto University, and the University of Bristol constructed a new temporal feature learning paradigm based on the Barlow Twins algorithm. Instead of filtering cloud-containing data, this paradigm constrains the feature consistency between different subsets of observations at the same location, allowing the model to autonomously learn stable spatiotemporal variations of the Earth's surface and form remote sensing feature representations with temporal sampling invariance. Based on this,The research team further proposed TESSERA, a pixel-level remote sensing foundation model for Sentinel-1/Sentinel-2 multimodal time-series data.
The related research findings, titled "TESSERA: Temporal Embeddings of Surface Spectra for Earth Representation and Analysis," have been published on the preprint platform arXiv.
Research highlights:
* Construct a global-scale, pixel-level feature embedding with high label utilization, design a novel self-supervised architecture, and train a pixel-level remote sensing basic model that integrates Sentinel-1/Sentinel-2 multimodal data.
* Introducing a data-as-embedded solution compliant with FAIR guidelines, releasing a global annual dataset of 10-meter resolution pixel-level 8-bit integer feature embeddings, providing compliant remote sensing resources that can be directly deployed.
* Experiments have shown that TESSERA can achieve state-of-the-art accuracy with extremely high labeling efficiency in diverse classification, segmentation, and regression tasks, typically requiring only a lightweight task header and minimal computation.

View the paper:
https://hyper.ai/papers/2506.20380
Dataset: Constructing a multi-dimensional evaluation system from global to local levels
This study constructed a large-scale, global time-series remote sensing data system, used both for model pre-training and for system evaluation of the model's generalization ability. The entire data system consists of a pre-training dataset and a downstream evaluation dataset.All data are based on Sentinel-1 radar data and Sentinel-2 optical data.Give full play to the complementary advantages of radar and optical observation.

During the pre-training phase, the research team constructed a large-scale time-series dataset on a global scale, spanning from 2017 to 2024, and spatially encompassing over three thousand grid tiles worldwide.A total of approximately 800 million d-pixel samples.Unlike many rigorously selected and standardized datasets, this dataset retains as much of the original characteristics of real observations as possible, including missing data, irregular sampling, and cloud cover. Furthermore, each time step is accompanied by a binary mask to mark the valid states of the observations, enabling the model to explicitly perceive missing data and differences in observation quality.
Downstream evaluation stage,The research team selected six publicly available benchmark datasets, covering three mainstream tasks: classification, segmentation, and regression.The evaluation area covers multiple countries and regions, including Germany, France, Austria, Finland, and Malaysia, encompassing typical application scenarios such as agriculture and forestry. Each task includes both large-scale regional datasets and refined local datasets to evaluate the model's cross-regional transferability and fine-grained feature modeling capabilities, respectively.
Furthermore, in response to the current scarcity of high-resolution, multi-temporal Sentinel-1/2 multimodal annotation data,The research team also independently constructed two new evaluation benchmarks:The first is the Austrian plot-level crop mapping dataset, used to evaluate the classification and segmentation capabilities in precision agriculture scenarios; the second is the Southeast Asian forest canopy height dataset constructed based on lidar correction, used to verify the performance in forest structure parameter inversion tasks.
A pixel-level basic model for Earth observation missions
TESSERA is designed to allow models to learn stable representations directly from complex and incomplete time-series data while preserving as much original observation information as possible, thereby reducing reliance on data preparation, completion, and repair processes.
to this end,This study first proposed a new way of organizing time-series data—d-pixel.Traditional analysis typically uses single-scene images or fixed time series as input, while d-pixel focuses on a single spatial location, organizing multi-source observations of the same pixel acquired at different times into an observation sequence in chronological order.Each d-pixel contains not only Sentinel-2 optical information and Sentinel-1 radar information, but also identifies which time steps have cloud obstruction or missing data through mask vectors.This representation method fully preserves the temporal characteristics of surface changes. Whether it is the slow changes brought about by vegetation growth or the short-term abrupt changes caused by disasters, disturbances, etc., they can all be preserved, fundamentally avoiding information loss in the traditional regularization process.
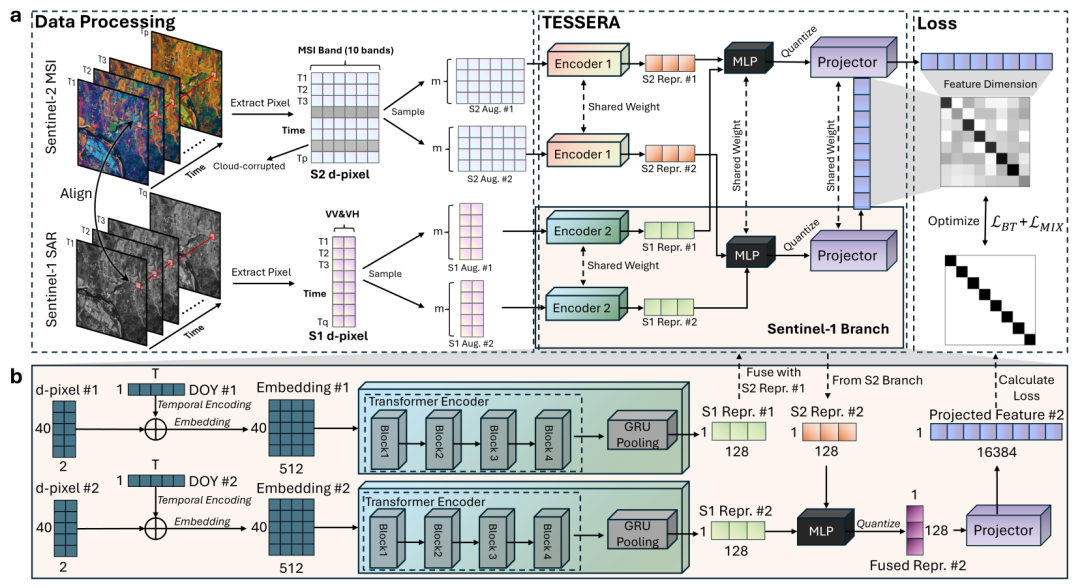
In terms of model architecture,TESSERA employs a dual-branch encoder to process optical and radar data separately.The two types of data have significantly different imaging mechanisms and physical properties. Independent encoding can fully explore their respective features, and then fusion can achieve multimodal complementarity. For each modality, the model first embeds the effective observations and adds learnable intra-annual daily location encoding to introduce temporal information. Then, a Transformer encoder is used to model long-term temporal dependencies. Finally, a gated recurrent unit is used to aggregate the entire time series to generate a fixed-dimensional single-modal representation. After fusing optical and radar features, a 128-dimensional multimodal surface representation is formed. The study also introduces quantized perception training, compressing the final features into 8-bit integers.The storage size was reduced by approximately 75% with almost no loss of accuracy.
The pre-training strategy is a core innovation of TESSERA. Based on the Barlow twin self-supervised learning framework, for the same d-pixel, the system randomly extracts two subsets of observations from its complete time series to construct two different "viewpoints". Although the two sets of observations contain different time points, and even some time steps are missing, they describe the same surface object.
During training, the model is required to map the two sets of observations to a feature space that is as consistent as possible. In this way,The model no longer learns the instantaneous features of a specific observation, but rather the stable surface patterns hidden behind different observations.This yields feature representations robust to temporal sampling methods. Furthermore, the study introduces a hybrid regularization and global shuffling strategy to further enhance the model's robustness to observational perturbations and spatial autocorrelation.
TESSERA demonstrates its advantages in low-label and sparse data.
To comprehensively evaluate TESSERA's performance, this study designed a systematic experiment based on typical application scenarios in the field of remote sensing. Starting with three tasks—classification, segmentation, and regression—the experiment verified the model's performance under different data scales, annotation conditions, and regional scenes. Several mainstream remote sensing basic models and classic visual models were selected as baselines, and three uniform annotation ratios of 1%, 30%, and 100% were set.The focus is on assessing learning ability in scenarios where tags are scarce.To ensure fairness, lightweight adapters are used for downstream inference across different tasks.
In classification tasks, TESSERA demonstrates a significant advantage in learning temporal features. The model achieves leading performance in both national-scale tree species classification and refined crop classification tasks.Especially in scenarios with extremely low sample sizes using only 1% labeled data, TESSERA maintains stable performance.The classification accuracy was improved by approximately 8 percentage points compared to the optimal baseline. This advantage mainly stems from the model's effective modeling of long-term surface changes. By utilizing complete temporal observations to capture vegetation growth cycles and phenological characteristics, highly discriminative category representations can be formed even with minimal annotations.
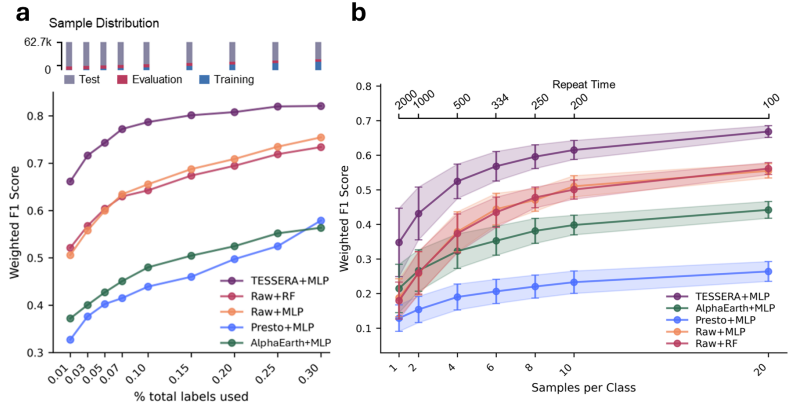
In segmentation tasks, TESSERA also demonstrated excellent spatial detail rendering capabilities. When faced with large-scale farmland segmentation tasks, the model achieved industry-leading performance under fully labeled conditions; in low-label scenarios, its performance further surpassed all control models. It is worth noting that...TESSERA can effectively learn spatial context information using only a lightweight decoder, maintaining accuracy while also ensuring deployment efficiency.On the Austrian crop semantic segmentation dataset, the model generates clearer plot boundaries, significantly reduces confusion between different crops, and demonstrates stronger overall semantic consistency.
The regression task primarily examines the model's ability to represent continuous surface parameters. In the aboveground biomass estimation task, TESSERA achieved the best results across different labeling scales, with lower prediction errors and more continuous spatial distribution. In the forest canopy height inversion task, the model further demonstrated its ability to capture three-dimensional forest structure information, with the estimation results showing the highest agreement with lidar measurement data, effectively recovering the vertical structure characteristics of the forest.
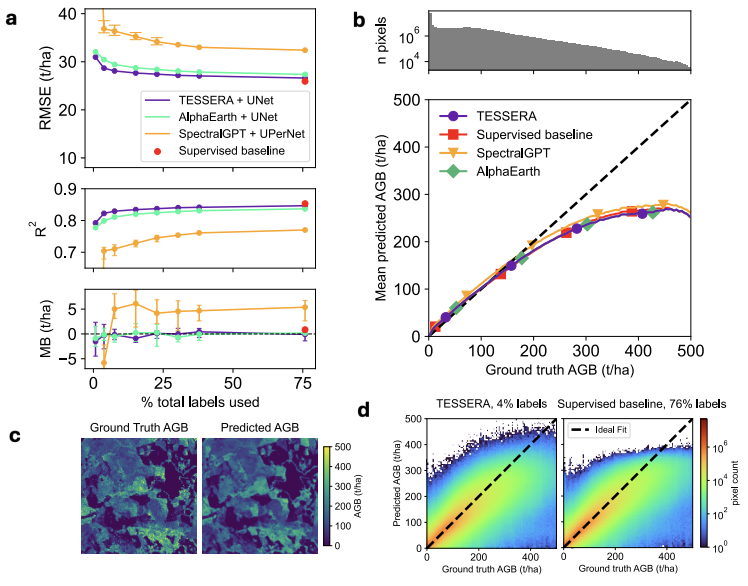
Based on all experimental results,TESSERA maintains a stable advantage in all three types of tasks: classification, segmentation, and regression, and its advantage is even more obvious under complex conditions such as low annotation, sparse data, and missing observations.Compared to many models that rely on high-quality training data, TESSERA exhibits a more gradual performance degradation in real-world remote sensing scenarios, demonstrating stronger robustness and generalization ability.
Final Thoughts
Do remote sensing foundational models truly require "ideal data"? TESSERA's approach offers a different answer: allowing models to directly engage with incomplete, irregular, and frequently cloud-interferenced observation sequences from the real world, learning feature representations with time-series sampling invariance within a self-supervised framework. This doesn't mean data cleaning is no longer important, but rather suggests that researchers could shift their focus from "cleaning up the data" to "teaching models to handle imperfect data." After all, every satellite image containing clouds is a part of real-world observation. Compared to constantly pursuing more "perfect" data, enabling models to understand the complexities of the real world may be a crucial direction for the generalization of remote sensing foundational models.








