Command Palette
Search for a command to run...
Supports live-action/animation/animal-driven Video Generation; Meituan's open-source multi-style audio-driven Video Generation Framework LongCat 1.5 Enhances VLM's Chart Reconstruction and Table Extraction Capabilities Using the million-level Chart Understanding Dataset ChartNet.

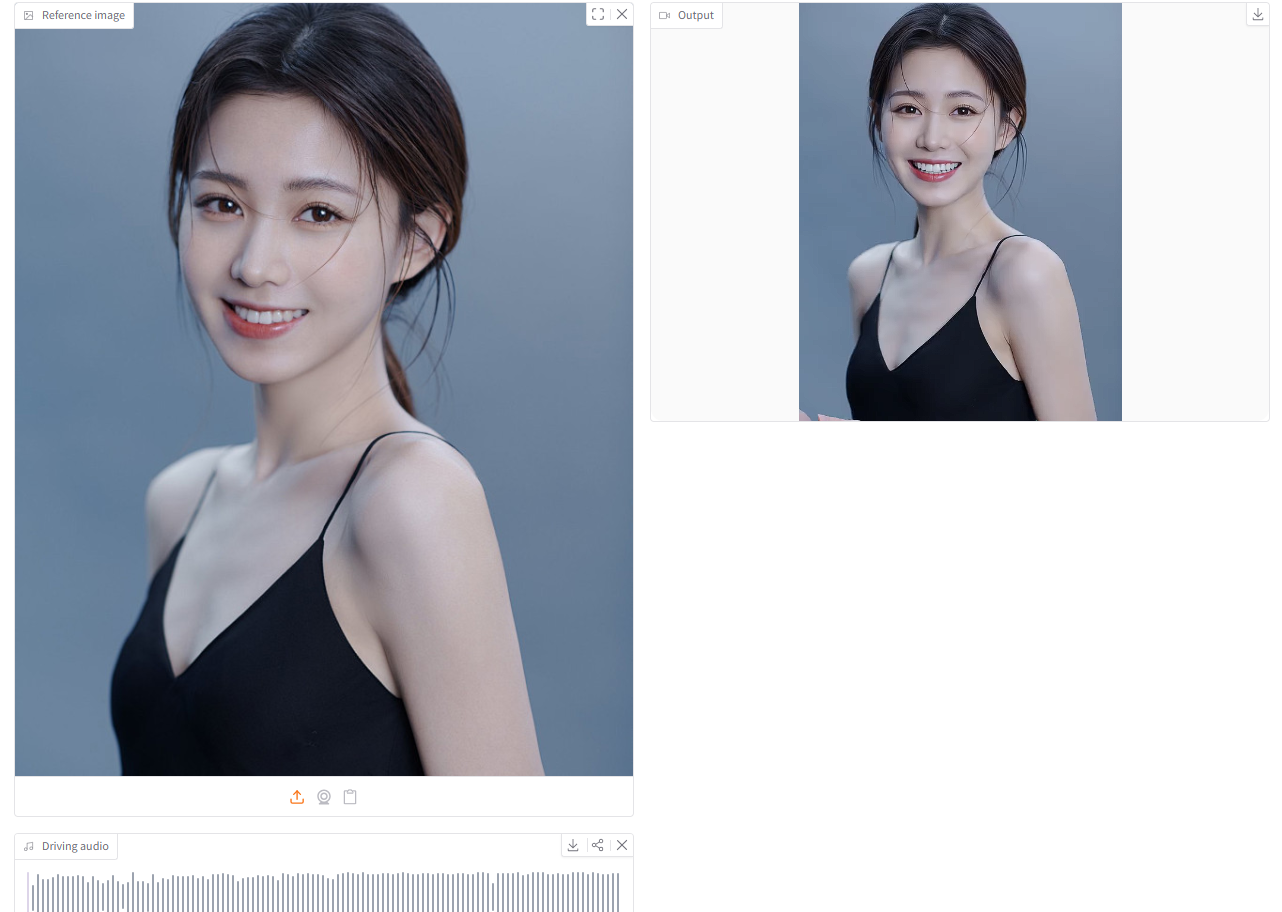
LongCat-Video-Avatar 1.5, launched by the Meituan LongCat team in May 2026, is a brand-new open-source audio-driven video generation (AI2V) framework.Users only need to provide a static reference image and an audio clip to generate a dynamic avatar video with precise lip-sync.This model employs Whisper-driven speech feature extraction; step distillation technology compresses the DiT generation process to an extremely fast 8 steps, ensuring not only high-fidelity visuals but also the generation of long video content. Its comprehensive generalization capability covers real-life portraits, 2D/3D anime characters, and animal avatars, providing an efficient and reliable solution for multi-scene video generation.
The HyperAI website now features the "LongCat-Video-Avatar 1.5 Digital Human Model," so come and try it out!
Online use:https://go.hyper.ai/NROTv
Welcome to visit our official website for more information:
A quick overview of hyper.ai's official website updates from June 6th to June 12th:
* High-quality public datasets: 6
* Selection of high-quality tutorials: 3
* Community article interpretation: 3 articles
* Popular encyclopedia entries: 5
Visit the official website:hyper.ai
Selected public datasets
1. ChartNet chart understanding multimodal dataset
ChartNet is a large-scale, high-quality multimodal dataset released in 2026 by MIT in collaboration with IBM Research and other institutions. It aims to address the shortcomings of existing models in joint inference using geometric visual patterns, structured numerical data, and textual descriptions. The dataset contains 4.2 million synthetic chart samples, 94,643 manually validated chart samples, and 30,000 real-world charts, covering 24 chart types and 6 plotting libraries.
Online use:https://go.hyper.ai/0CNr7
2. OpenSAL360 Panoramic Video Saliency Dataset
OpenSAL360 is currently the largest comprehensive video saliency dataset, designed to support research in visual attention, saliency prediction, and multimodal video analysis. The dataset contains 500 diverse panoramic videos from YouTube, with an average duration of 18.1 seconds, and data annotations completed by over 2,000 observers.
Online use:https://go.hyper.ai/u7NqD
3. Movie Feelings dataset
Movie Feelings is a dataset of film emotion features designed to systematically characterize the fine-grained emotional feelings evoked by movies, breaking through the limitations of traditional classifications based solely on positive/negative emotions or basic emotions. This dataset contains 1,500 representative and culturally influential films spanning from 1920 to 2024, covering 50 emotional states.
Online use:https://go.hyper.ai/b4m71
4. FigureBench: Generating benchmark datasets for scientific illustrations.
FigureBench is a benchmark dataset for scientific illustration generation released in 2026 by the Text Intelligence Lab at Westlake University. It aims to solve the task of automatically generating high-quality scientific illustrations from long scientific texts, providing a challenging and diverse testing platform for research on automatic scientific illustration generation.
Online use:https://go.hyper.ai/Agaku
5. AI Student Impact: AI-assisted learning impacts datasets.
The AI Student Impact Dataset is a large-scale educational behavior dataset encompassing multiple dimensions, designed to systematically analyze the real-world impact of generative AI tools in higher education learning scenarios. This dataset contains 50,000 student samples and 16 structured feature fields, covering data such as students' academic background, AI usage behavior, learning behavior, institutional background, mental health status, and application scenarios.
Online use:https://go.hyper.ai/zWoGM
6. Noisy Medical Document Image Dataset
Noisy Medical Document is a dataset of noise-enhanced medical document images designed for OCR and medical document understanding tasks. It aims to simulate the complex noise interference encountered when scanning documents in real-world medical scenarios, improving the robustness and generalization ability of OCR and document understanding models in real-world environments. The dataset contains 1,000 high-fidelity synthetic medical document images, including 500 hospital bills and 500 discharge summaries.
Online use:https://go.hyper.ai/kL7gc
Selected Public Tutorials
1. LongCat-Video-Avatar 1.5 Digital Human Model
LongCat-Video-Avatar 1.5, released by the Meituan team in May 2026, is a newly upgraded open-source audio-driven video generation (AI2V) framework. It can generate highly realistic, perfectly lip-synced dynamic avatar videos with just a static reference image and a driving audio clip, easily handling complex real-world scenes as well as stylized subjects such as animation and animals.
Run online:https://go.hyper.ai/NROTv
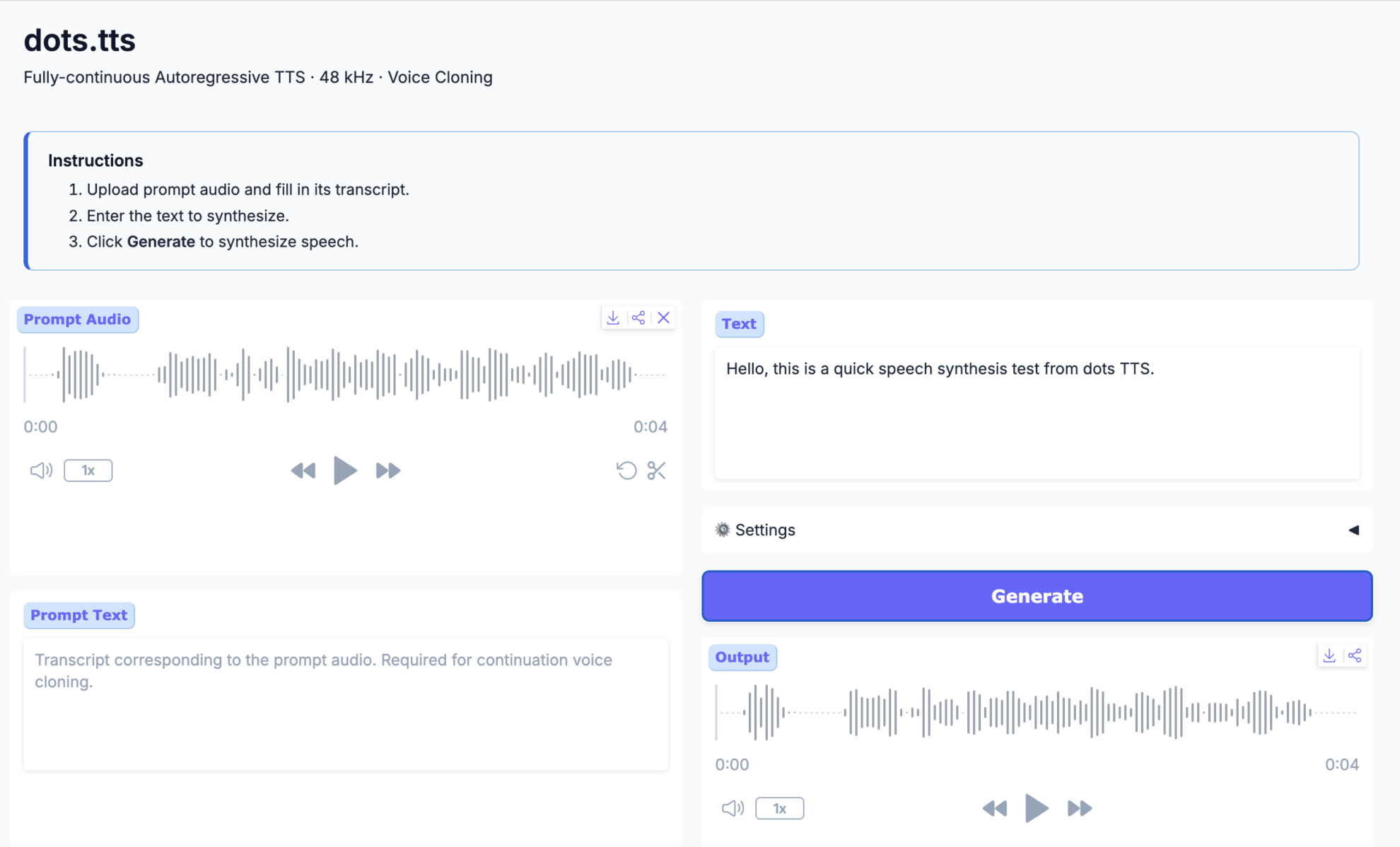
2. dots.tts: A fully continuous autoregressive text-to-speech system
Released by rednote-hilab in June 2026, dots.tts is a 2B-parameter, fully continuous, end-to-end autoregressive text-to-speech system. Its backbone consists of a semantic encoder, an LLM, and an autoregressive flow-matching acoustic head. It directly models continuous audio representations based on 48 kHz AudioVAE, without using discrete speech tokens.
Run online:https://go.hyper.ai/YT3g3
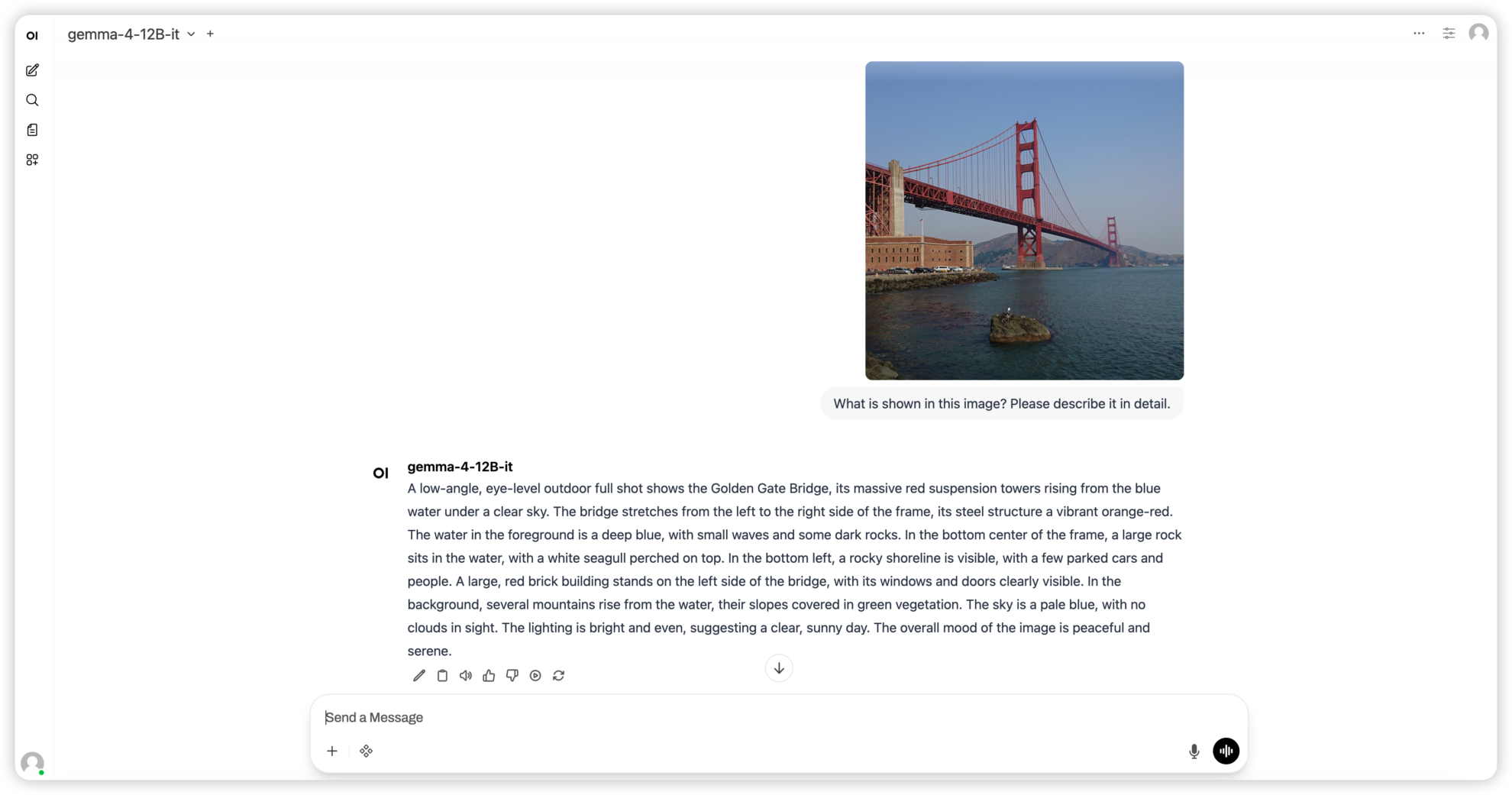
3. Gemma4 12B-it: A unified multimodal model of graph, text, and audio.
Gemma 4 12B-it is a unified multimodal model in the Gemma 4 series released by Google DeepMind. It adopts an encoder-free architecture, directly projecting images and audio into the embedding space of LLM. It can process text, image and audio modalities without a separate encoder, and achieves powerful inference, encoding and multimodal understanding capabilities at the 12B parameter level.
Run online:https://go.hyper.ai/0713z
Community article interpretation
1. Based on 220 marine bacteria species, scientists reconstructed the heterotrophic microbial classification system using a genome-scale model, identifying eight types of metabolic flora.
A team led by the University of Southern California used a global marine microbial database and genome-scale metabolic models to analyze massive amounts of marine bacterial genomes. By quantifying the sensitivity of microorganisms to the utilization of 11 types of organic substrates, they identified 8 differentiated metabolic communities.
View the full report:https://go.hyper.ai/dfq8T
2. Depth estimation accuracy reaches 0.9; Meta proposes VLM³, demonstrating that visual models are inherently capable of learning 3D, and achieves unified modeling for multiple tasks based on Qwen3-VL-4B.
Meta, in collaboration with Princeton University, proposed VLM³, which, based on the standard visual language model, achieves unified modeling for four types of tasks—object-level 3D understanding, metric depth estimation, pixel matching, and camera pose solving—through a unified data organization method and training paradigm. It also systematically evaluated the capability boundaries of the standard VLM in fine-grained 3D perception.
View the full report:https://go.hyper.ai/NihJA
3. Cambridge University and others proposed a pixel-level fundamental model for Earth observation missions, achieving state-of-the-art (SOTA) accuracy in multiple missions.
A joint research team from the University of Cambridge, Aalto University, and the University of Bristol has developed a novel temporal feature learning paradigm based on the Barlow twins algorithm. This paradigm enables models to autonomously learn stable spatiotemporal variations of the Earth's surface, forming remote sensing feature representations with temporal sampling invariance. Building upon this foundation, the team further proposed TESSERA, a pixel-level remote sensing foundation model for Sentinel-1/Sentinel-2 multimodal temporal data.
View the full report:https://go.hyper.ai/S3KBr
Popular Encyclopedia Articles
1. World Action Model WAM
2. Explainable artificial intelligence XAI
3. Visual Language Action Model (VLA)
4. Rule-Based System
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provides domestic accelerated download nodes for 2100+ public datasets
* Includes 700+ classic and popular online tutorials
* Analyzing 300+ AI4Science Paper Cases
* Supports searching for 700+ related terms
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








