Command Palette
Search for a command to run...
Leveraging Gemini 1.5's Long Contextual Capabilities, Google's Conversational Healthcare System AMIE Achieved the Reasoning Level of a General Practitioner in 100 Scenarios Involving Multiple Patient visits.

Large language models are rapidly entering the healthcare field, with applications extending from literature retrieval and medical record generation to clinical decision support. Among these applications, assisted diagnosis is one of the more mature directions: medically fine-tuned models can provide high-quality differential diagnoses based on medical history, physical signs, and examination results; systems with multi-turn dialogue capabilities can also supplement medical history information through consultation-style interaction.
However, diagnosis is only the starting point for clinical decision-making. What truly impacts the quality of treatment are often the management decisions made after diagnosis—whether further testing is needed, how to choose a treatment plan, when to adjust medication, how to schedule follow-up visits, and how to continuously revise the plan based on changes in the patient's condition. This type of "management reasoning" is closer to the core of real clinical work.It also puts a greater test on the model's comprehensive understanding of evidence-based guidelines, clinical pathways, drug knowledge, and individual patient differences.
Compared to diagnostic reasoning, managerial reasoning is more difficult to assess. Diagnostic problems usually have relatively clear standard answers, while managerial decisions often lack a single solution and are constrained by medical resources, guidelines, drug accessibility, and physician experience. Currently, the main method for evaluating this type of comprehensive ability in medical education is the Objective Structured Clinical Examination (OSCE), but it relies on real-person interaction and expert scoring, making it difficult to directly apply to automated assessment of large language models.
To address this gap, a recent study by Google DeepMind and Google Research has further developed a novel LLM-based intelligent agent system based on their conversational healthcare system AMIE. This system enables clinical management and doctor-patient dialogue optimization for multiple follow-up scenarios. AMIE leverages the long-context capabilities of the Gemini model, combining in-context retrieval with structured reasoning to ensure its output aligns with the latest clinical practice guidelines and drug prescription catalogs.
In a randomized, double-blind virtual objective structured clinical examination (OSCE) study, researchers compared AMIE with 21 primary care physicians (PCPs). The test covered 100 multi-visit scenarios, with the case design referencing the UK NICE guidelines and BMJ Best Practice clinical guidelines. Results showed that...In terms of disease management reasoning ability assessed by specialists, AMIE performed no worse than (non-inferior) human doctors;Meanwhile, AMIE scored higher than the physician group in terms of the accuracy of treatment plans and examination recommendations, as well as the degree of adherence to clinical guidelines and the reliability of knowledge base.
The relevant research findings, titled "Towards Conversational AI for Disease Management," have been published in Nature.
Research highlights:
* This research advances the capabilities of the conversational healthcare system AMIE from single-round diagnosis to a full-process clinical management reasoning that covers disease progression, multiple visit decisions, treatment response feedback, and medication prescribing.
* The system leverages Gemini's long-contextuality capabilities, combining contextual retrieval with structured reasoning to ensure that management protocols are highly consistent with authoritative clinical knowledge such as NICE guidelines and BMJ best practices.
* The system performed at or above the level of a general practitioner in multiple indicators, including overall appropriateness of the protocol, quality of treatment recommendations, and accuracy of examination recommendations.
View the paper:
https://www.nature.com/articles/s41586-026-10764-5
Datasets: From Single Question-Answering to Vertical Clinical Scenarios
To assess the real-world capabilities of conversational healthcare AI in long-term management reasoning, the research team constructed a multi-level data system.It covers clinical scenarios involving multiple visits and also incorporates evidence-based guidelines and drug knowledge.Used for model training, scheme generation, and standardized evaluation.
The core evaluation tool is a set of "Multiple Visits Virtual OSCE Scenario Dataset".The study compiled a total of 100 independent case studies.The cases are evenly distributed across five specialties: cardiology, pulmonology, obstetrics and gynecology/urology, gastroenterology, and neurology/musculoskeletal medicine, with 20 cases per specialty. All cases were jointly designed by clinicians from Canada and India and constructed with reference to the treatment pathways in the NICE Clinical Guidelines and BMJ Best Practice Guidelines.
Unlike typical single-round medical Q&A sessions, these cases were designed to involve three consecutive consultations. Each scenario includes not only the patient's initial complaint,It also includes longitudinal information such as symptom evolution, treatment response, and reports of auxiliary examination results.The aim was to accurately reflect the real-world decision-making process in chronic disease management and follow-up of complex cases. To increase clinical difficulty, some cases also incorporated elements such as information inconsistencies and multi-system comorbidities, in order to test the system's judgment capabilities under non-standard conditions.In addition to 100 formal evaluation cases, the study also set up 20 validation scenarios for pre-experimentation and scoring calibration.
The evidence-based approach comes from a clinical guidelines knowledge base.This knowledge base contains 627 documents, including 527 NICE guidelines and 100 BMJ best practice documents.The total size is approximately 10.5 million tokens, covering diagnostic criteria, examination pathways, treatment plans, and follow-up guidelines. During the evaluation process, this knowledge base is open to both the AI system and participating general practitioners to simulate the scenario of consulting guideline materials in real clinical settings, and to ensure fairness in the human-machine comparison as much as possible.
Drug decision-making is an indispensable part of management reasoning. Therefore,The research team also constructed a special benchmark for RxQA.This benchmark is used to assess a model's understanding of drug instructions, indications, contraindications, dosage, and medication risks. It contains 600 multiple-choice questions derived from drug instructions in the US OpenFDA and the UK National Formulary, divided into two categories: basic short questions and long-scenario comprehensive questions.The initial draft of the questions was generated by the Gemini model according to the instructions, and then reviewed, revised and marked with difficulty by 8 licensed pharmacists from both countries.Due to licensing restrictions, only 300 questions from OpenFDA are currently available for public release, providing a standardized reference for comparing drug reasoning abilities.
AMIE model: Enabling systems to possess both "dialogue capabilities" and "deep management capabilities"
This research builds upon Google's previously proposed conversational healthcare system, AMIE, and features specific upgrades to address management reasoning needs. The new system employs a dual-agent collaborative architecture, drawing inspiration from the "two-process theory" in cognitive science.One agent is responsible for fast, continuous doctor-patient dialogue, while another agent is responsible for slower but deeper management reasoning.The underlying model uniformly uses Gemini 1.5 Flash to balance real-time response speed and long-context reasoning capabilities.
Specifically,The system consists of a Dialogue Agent and an Mx Management Inference Agent.The dialogue agent is closer to "System 1": it is responsible for real-time communication with patients, inquiring about medical history, explaining treatment plans, and maintaining the patient's status during the dialogue. The Mx agent is closer to "System 2": it is primarily responsible for generating structured, traceable management plans based on complete disease information and clinical guidelines. Both synchronize information through a shared state module, allowing the dialogue agent to access Mx's inference results at any time, thus ensuring that medical advice has strong guidance while maintaining natural communication.
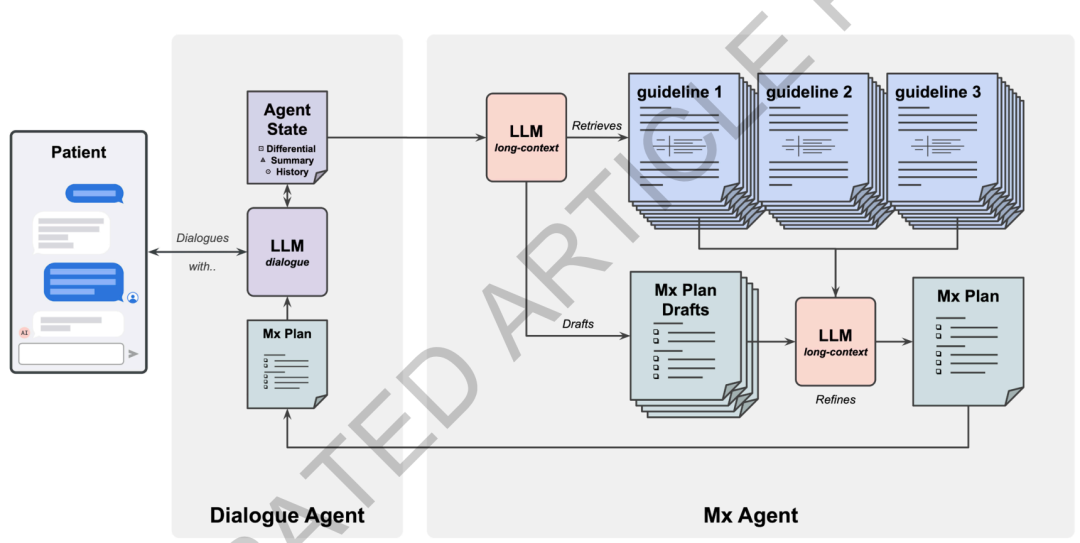
As an interactive hub, the dialogue agent has undergone three upgrades compared to the original diagnostic model.First,The base model was replaced with Gemini 1.5 Flash, which has long contextual capabilities, enabling it to handle longer medical records and multi-turn dialogue information.second,The training data included several simulated medical consultations to enhance the system's understanding of disease progression and long-term management.third,Following supervised fine-tuning, the study further incorporated reinforcement learning based on both human and AI feedback to optimize dialogue quality and decision-making performance.
During real-time reasoning, the dialogue agent adopts a three-step process of "planning-generation-refinement":First, it plans the next steps for consultation or response based on the current status, then generates natural language responses for the patient, and finally performs self-checking and correction. To support continuous management across different patient visits, it also maintains a modular status structure, including patient summary, differential diagnosis, current management plan, and other information, and continuously updates it in the background to avoid starting from scratch for each conversation.
The Mx agent is the core module in the entire system responsible for deep management inference.It fully utilizes the long context capabilities of Gemini 1.5 Flash, employing a strategy of "coarse retrieval + full context reasoning".To minimize information fragmentation that can result from traditional chunked retrieval, the system first indexes all guideline documents using a Gecko 1B embedding model. Then, it generates a natural language query based on the current patient's case, selecting approximately six highly relevant complete documents from the guideline library, totaling about 256,000 tokens. Subsequently, the system inputs these full-text guidelines along with the patient's complete medical history into the model, allowing the model to perform holistic reasoning across documents and stages in a single call.
To improve the usability and auditability of the output, the Mx agent uses JSON schema constraints to generate results and outputs them according to the framework of "analyzing clinical situation - defining management goals - formulating management steps and citing guideline sources". Each suggestion needs to be accompanied by the corresponding guideline citation. At the same time, the system will first generate four management drafts independently, and then integrate and improve them based on the original guideline text to improve the completeness and adaptability of the final solution.
It was not inferior to general practitioners in all 15 indicators.
To validate the clinical management reasoning ability of the upgraded system, this study employed a randomized, blinded virtual OSCE framework, combined with RxQA drug benchmark testing.The AMIE system was compared with 21 general practitioners.The overall assessment revolves around three dimensions: the overall quality of the management plan, the quality of investigation recommendations, and the quality of treatment recommendations.
In clinical evaluation, both systemic and general practitioners are required to complete 100 sets of multiple outpatient cases. Thirty specialist physicians and standardized patients conducted blinded scoring from two perspectives: professional quality and patient experience. This means that the scorers did not know whether the treatment plan came from an AI system or a human doctor, thus minimizing the impact of identity bias on the results. Drug testing employed both closed-book and open-book environments to observe whether external data would alter the system and physician performance.
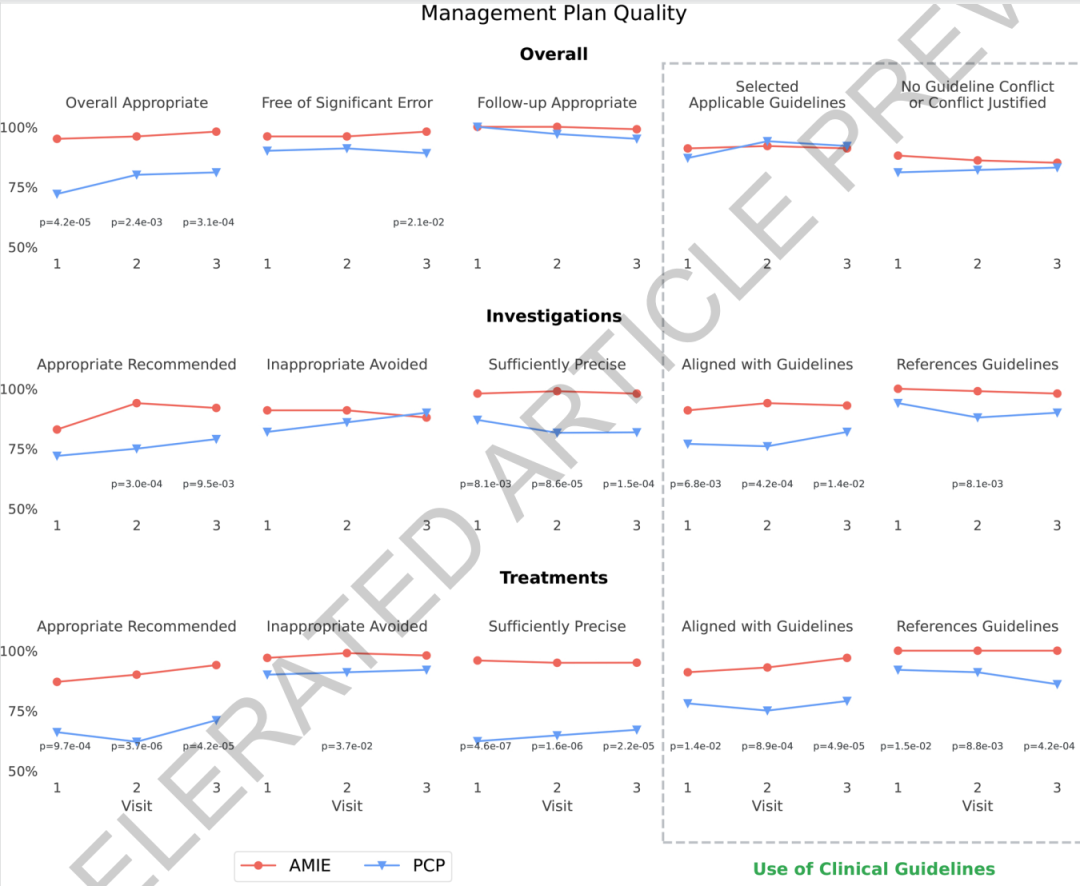
The results show thatIn terms of the overall quality of the treatment plan, the system is no worse than general practitioners in all 15 assessment dimensions and shows statistical advantages in many indicators.Taking the overall appropriateness of the treatment plan as an example, the system scored 95%, 96%, and 98% in the three visits, respectively, which is higher than the general practitioner's scores of 72%, 80%, and 81%. Regarding the appropriateness rate of treatment recommendations, the system scored 87%, 90%, and 94%, respectively, also higher than the general practitioner's scores of 66%, 62%, and 71%.
The system also demonstrates a consistent advantage in the accuracy of its examination and treatment recommendations.The accuracy rate of its treatment recommendations is consistently above 95%, while that of general practitioners is between 62% and 67%.Regarding guideline compliance, the system's traceability is significantly better than that of human doctors because each recommendation requires explicit citation. This result suggests that the integration mechanism of long-context reasoning with the original guideline text may help improve the model's stability and interpretability in complex management tasks.
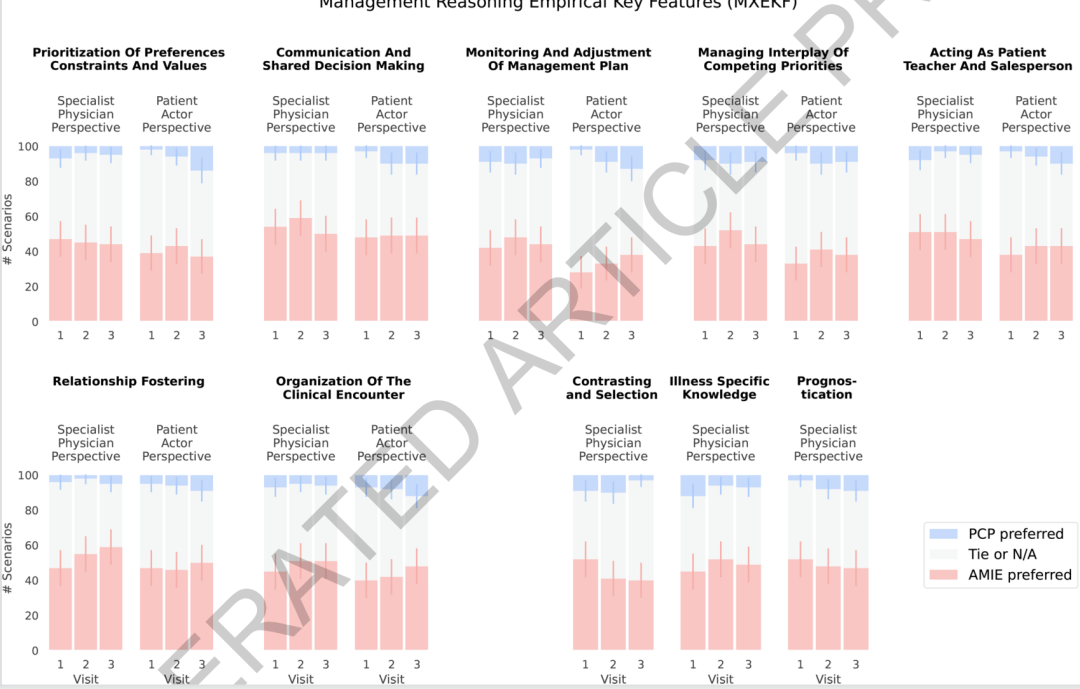
In the dual-perspective preference assessment, the study covered 10 core dimensions of managerial reasoning, resulting in 51 sets of comparisons. In nearly half of the cases, both the specialist and the patient considered their performance to be comparable.In cases where a clear preference was observed, the system's win rate was 47%, significantly higher than the 7% for general practitioners.More notably, the evaluation trends of specialist physicians and patients are largely consistent, indicating that the system's advantages are reflected not only in professional judgment but also in dimensions related to patient experience.
As the number of visits increases, the system's advantages in time-related dimensions such as dynamic monitoring, patient flow, and doctor-patient relationships become more apparent. This aligns with the research's initial purpose: the difficulty in managing reasoning lies not in whether a single answer is correct, but in the ability to continuously connect changes in the patient's condition, treatment feedback, and the next steps in the plan.
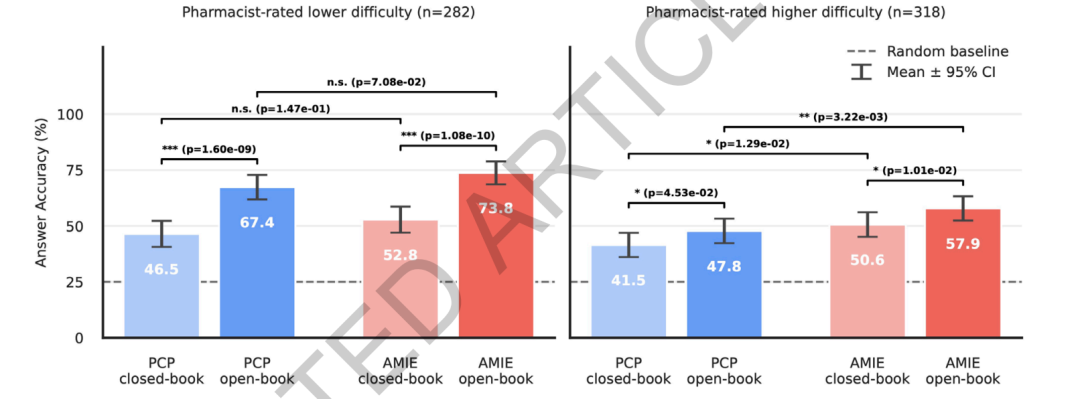
In terms of drug reasoning,RxQA benchmarks show that the system outperforms general practitioners on highly difficult questions assessed by pharmacists.In a closed-book environment, the system's accuracy was 50.61 TP3T, while that of general practitioners was 41.51 TP3T. In an open-book environment, the system's accuracy was 57.91 TP3T, and that of general practitioners was 47.81 TP3T. There was no significant difference between the two methods for easier questions. Open-book materials were helpful to both the system and the physicians, especially improving accuracy by more than 20 percentage points for easier questions; the improvement was smaller for more difficult questions, but still statistically significant. This indicates that the model has a certain relative advantage in complex drug information integration tasks, but external materials alone cannot completely solve highly difficult drug reasoning problems.
Final Thoughts
The value of this study lies not in proving that large-scale medical models can replace doctors, but in shifting the focus of evaluation from "diagnosis" to "continuous management." Compared to single-round question-and-answer sessions, management reasoning is closer to real clinical practice: doctors need to constantly adjust their judgments based on changes in disease progression, treatment feedback, guideline evidence, and individual patient differences. The study's proposed multi-visit virtual OSCE, guideline knowledge base, drug-specific benchmarks, and dual-agent system provide a more clinically relevant framework for evaluating medical AI. However, the virtual environment still cannot fully replicate the physical examinations, resource constraints, patient compliance, and liability boundaries in real-world healthcare.
Therefore, a more prudent assessment is that the medical big data model is shifting from "aiding diagnosis" to "aiding management." Its short-term value is not to replace doctors in making final decisions, but to become a traceable, auditable, and continuously updated clinical decision support tool in areas such as disease progression analysis, guideline matching, medication verification, follow-up planning, and patient communication.








