Command Palette
Search for a command to run...
Online Tutorial | Hong Kong University of Science and Technology Team Open-Sources First Deterministic Video Depth Framework DVD, Achieving State-of-the-Art With Zero-Shot Results

Depth estimation is one of the most fundamental and critical tasks in the field of 3D vision. From autonomous driving and robot navigation to AR/VR, digital twins, and video content generation, systems need to accurately understand the spatial relationships between objects and the camera in a scene. However, video depth estimation has long faced an irreconcilable contradiction: generative methods, represented by diffusion models, have strong semantic understanding capabilities and can infer complex scene structures using massive amounts of pre-trained data, but their prediction results are often affected by random sampling processes, making them prone to geometric illusions, scale drift, and temporal instability; while traditional discriminative methods, although possessing better determinism, heavily rely on large-scale labeled data, resulting in high training costs and limited generalization ability in complex scenes.
To address this industry pain point, the Hong Kong University of Science and Technology (Guangzhou) team proposed DVD (Deterministic Video Depth Estimation).For the first time, a pre-trained video diffusion model has been deterministically transformed into a single forward propagation video depth estimator.Unlike traditional diffusion models that require multiple iterations to generate results, DVD can complete depth prediction with a single forward computation. This not only significantly improves inference efficiency but also completely eliminates the geometric illusion problem caused by random sampling, fundamentally ensuring temporal consistency and structural stability in video sequences.
More importantly,DVD successfully preserved a large amount of geometric and semantic prior knowledge contained in the basic video model.Through innovative structural anchoring mechanisms and latent manifold correction (LMR) technology, the model can accurately recover object edges, high-frequency textures, and motion details while maintaining global scene stability, significantly improving the structural fidelity of depth maps.
In multiple publicly available benchmark tests, DVD's zero-sample performance reaches state-of-the-art (SOTA) levels.Furthermore, it achieved a leading level using only 367,000 frames of training data, a reduction of approximately 163 times compared to the 60 million frames required by mainstream discriminative methods. This not only validates the enormous potential of generative base models in geometric understanding but also provides a completely new technical route for low-cost, high-precision video 3D perception in the future.
To help developers quickly experience DVDs, HyperAI has launched an easy-to-deploy Notebook, lowering the barrier to entry and providing one-click access to state-of-the-art (SOTA) models. ⬇️
Run online:https://go.hyper.ai/w8kUO
Open source address:https://github.com/EnVision-Research/DVD
More online tutorials:
Demo Run
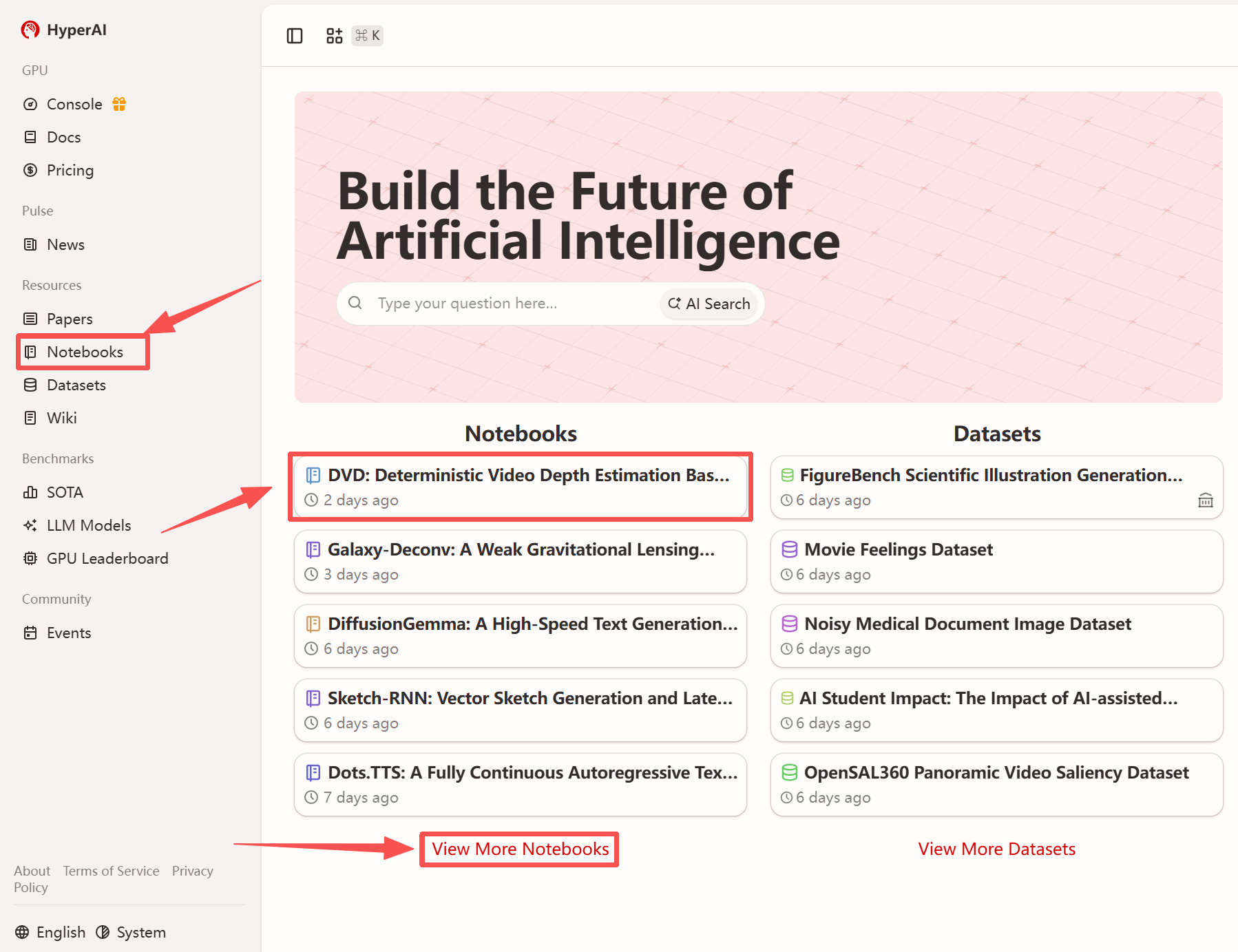
1. After entering the hyper.ai homepage, select the "Tutorials" page, or click "View More Tutorials", select "DVD: Deterministic Video Depth Estimation Based on Generative Priors", and click "Run this tutorial".
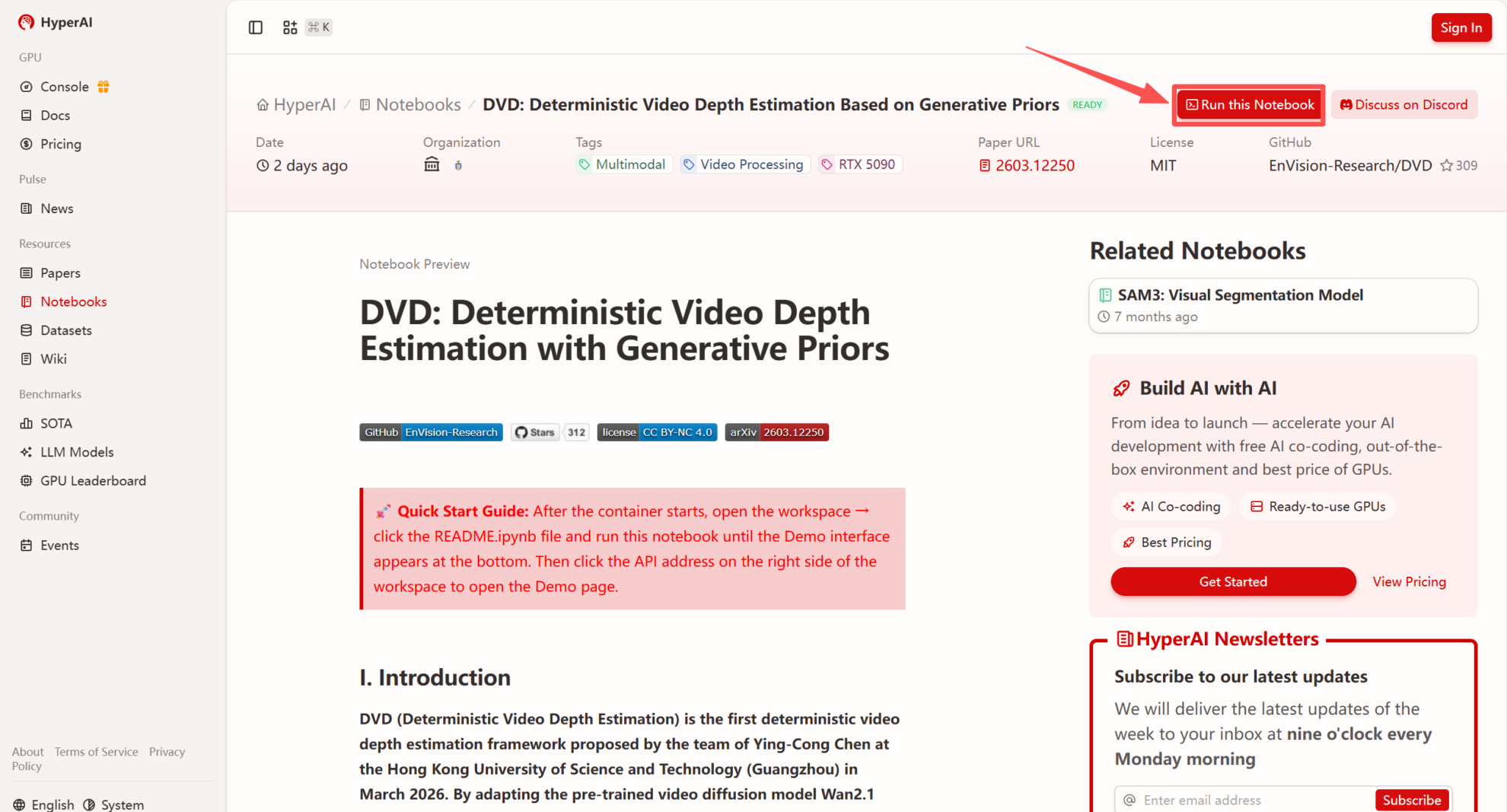
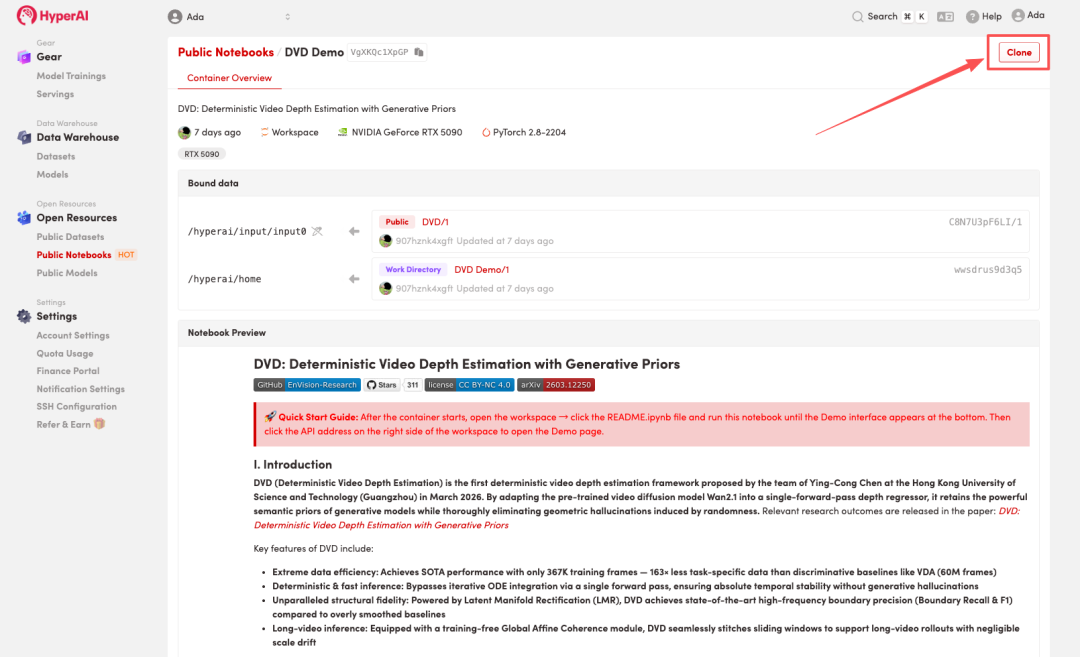
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
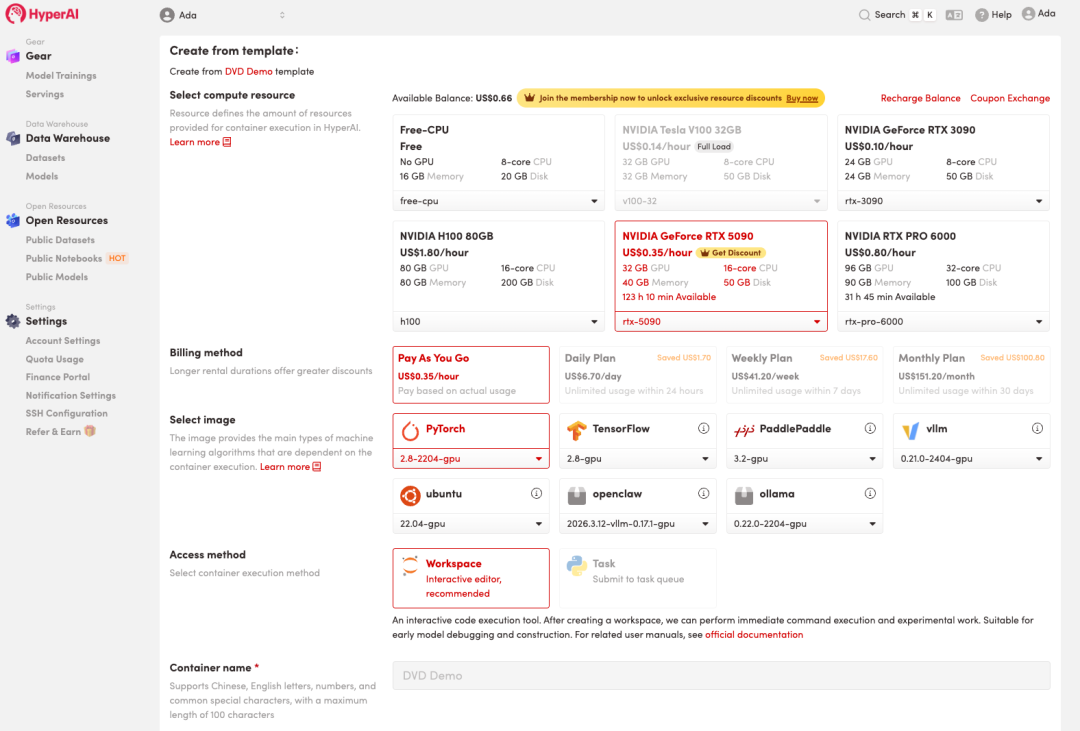
3. Select the "NVIDIA RTX 5090" and "PyTorch" images, and click "Continue job execution".
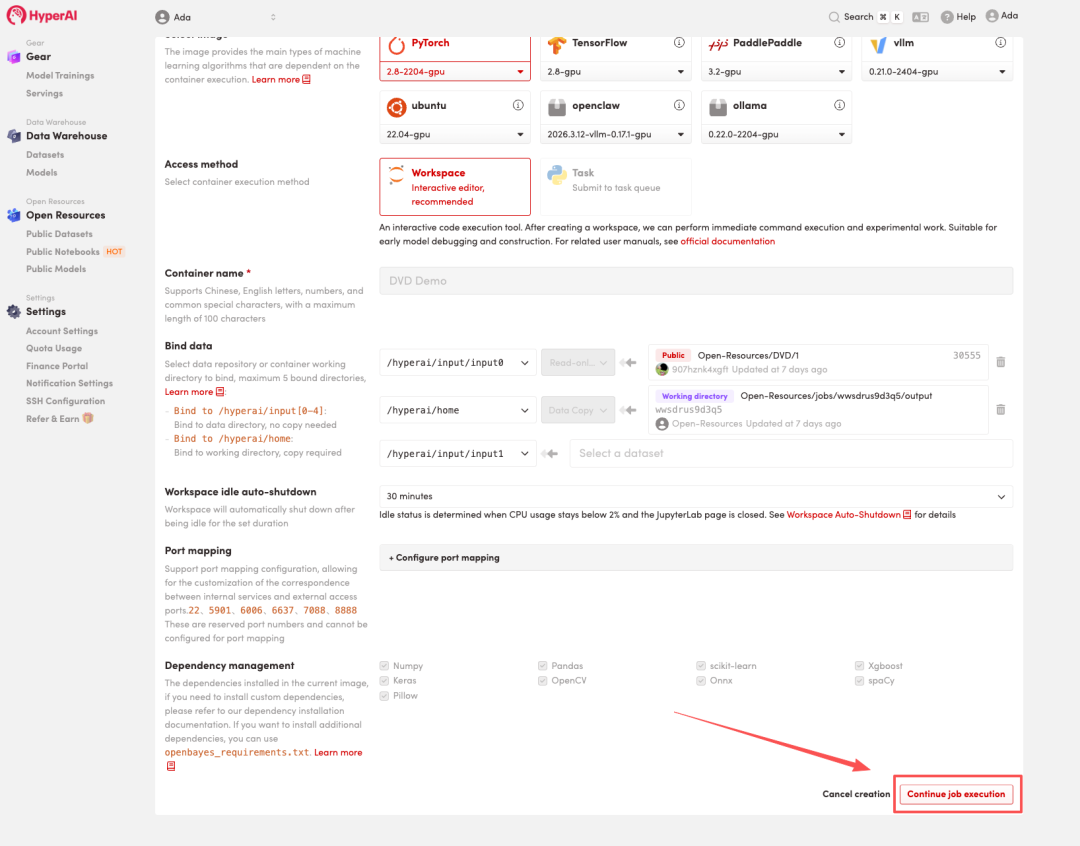
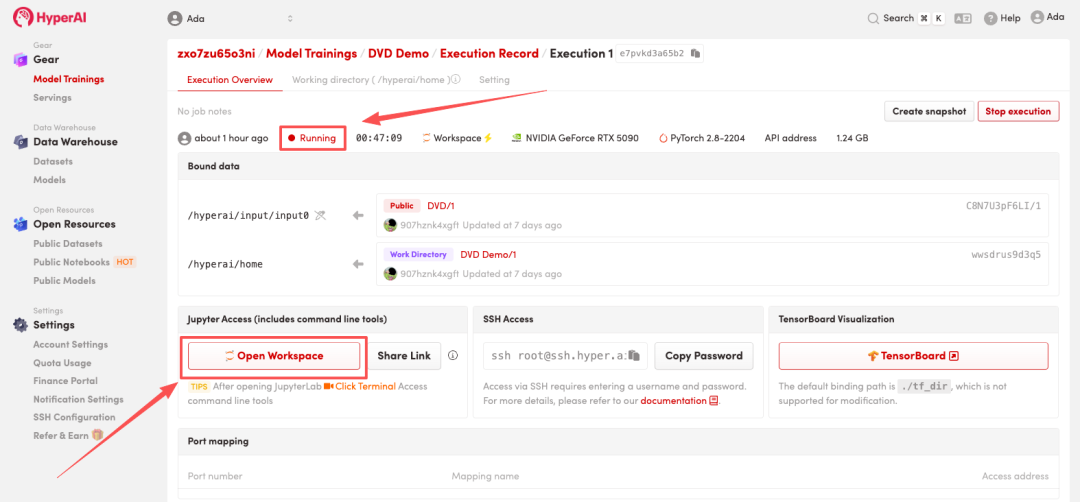
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
Effect display
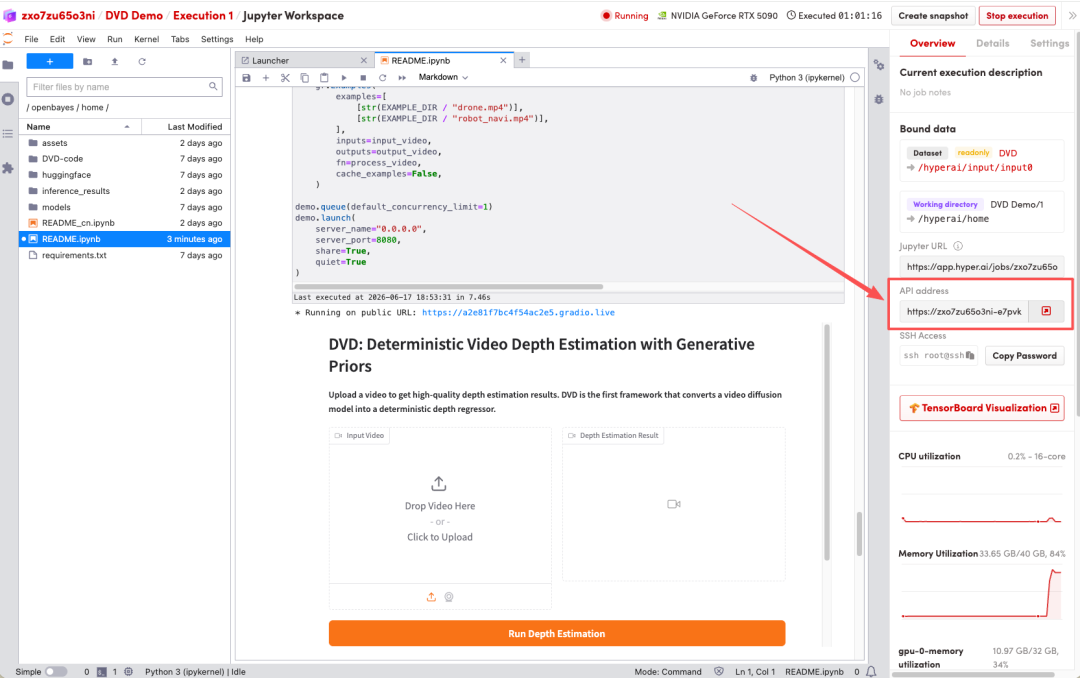
1. After the page redirects, click on the README file on the left, and then click on Run at the top.
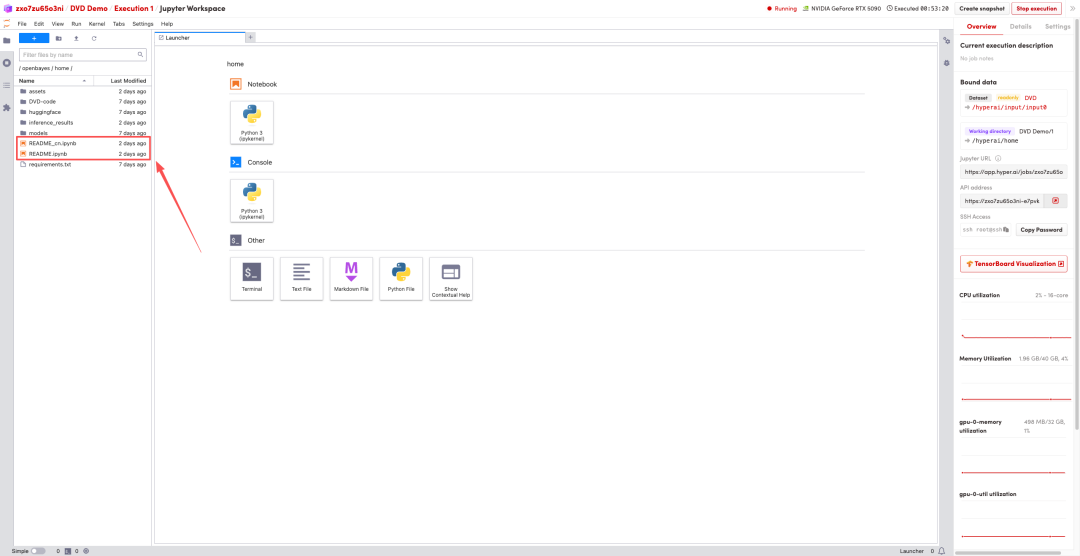
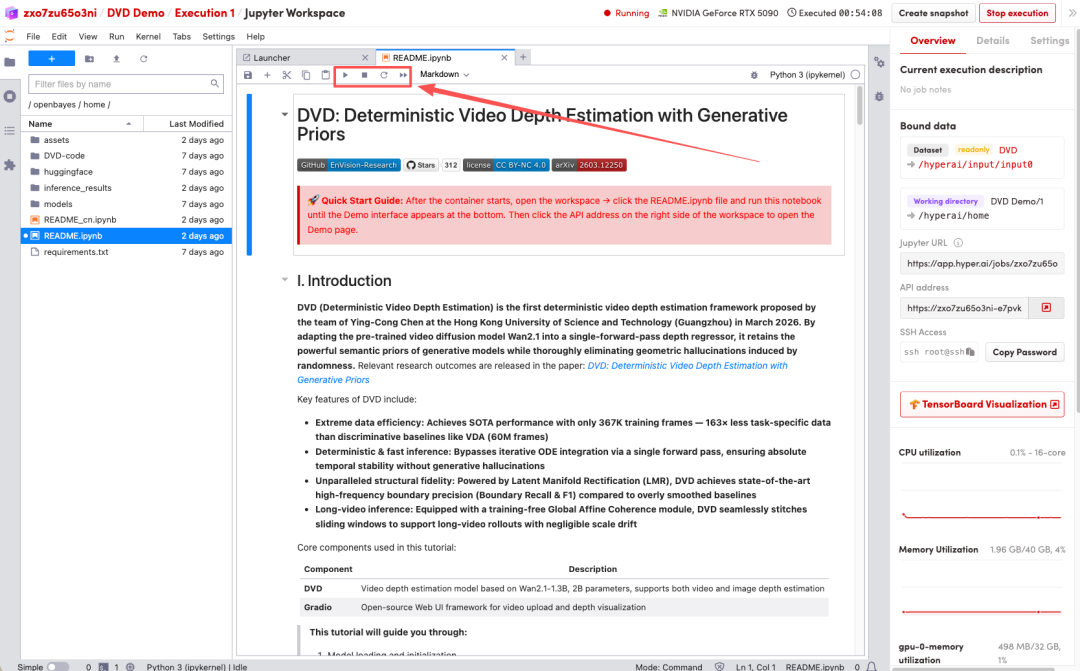
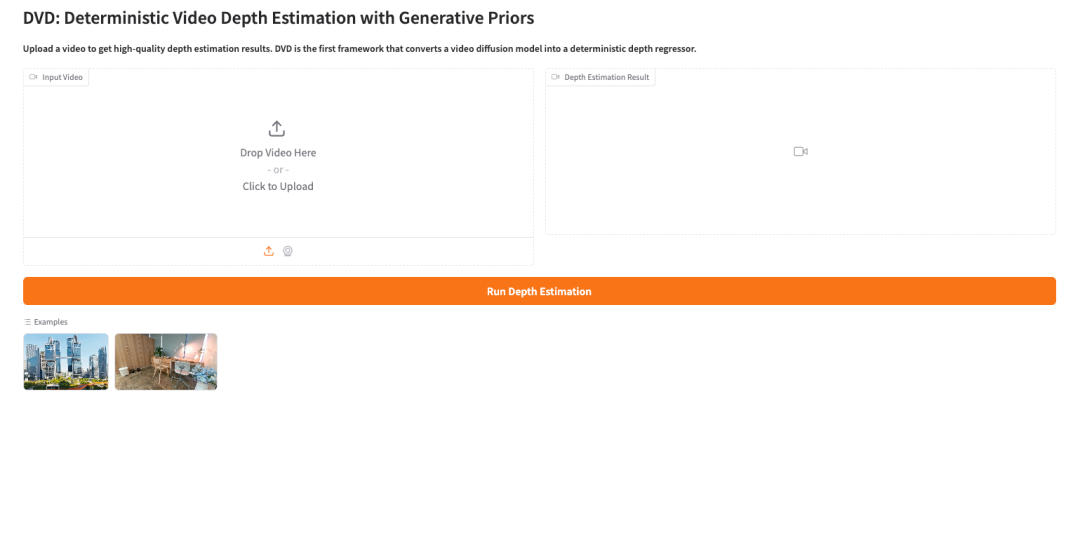
2. After the process is complete, click the API address on the right to open the Demo interface.