Command Palette
Search for a command to run...
Paper Roundup | Latest Advances in Large-Scale Reinforcement Learning: Microsoft, Google, Stanford, Renmin University, Xiaohongshu, and Others Release Major Achievements in Credit Allocation, Complex Reasoning, and Agent Reinforcement Learning

Looking at the current development of reinforcement learning, whether it's improving credit allocation capabilities in long-chain inference, enhancing the model's autonomous exploration in complex environments, or building intelligent agent systems with long-term planning and feedback learning capabilities, their core goals all point in the same direction—Breaking through the limitations of sparse rewards and static supervision,It empowers the model to continuously learn and evolve through interaction.
Reinforcement learning is essentially a method that allows an intelligent agent to continuously optimize its behavioral strategies through a closed loop of "perception-decision-execution-feedback". Unlike traditional supervised learning, which relies on a fixed data distribution, reinforcement learning emphasizes the model's ability to learn through trial and error in environmental interactions, enabling it to gradually form a decision-making mechanism that maximizes long-term benefits in dynamic tasks.In short, reinforcement learning is driving artificial intelligence from "being able to answer questions" to "being able to act autonomously," completing a significant leap from "passive generation" to "active intelligence."
This week,HyperAI has selected 6 of the latest research papers in the field of large-model reinforcement learning for you.The team behind it includes top universities such as Stanford University and Renmin University of China, as well as tech giants like Microsoft, Google, Kuaishou, and Xiaohongshu. Their related papers provide highly inspiring new solutions for building next-generation large-scale models with strong reasoning and self-learning capabilities. Let's learn together! ⬇️
In addition, to allow more users to understand the latest developments in the field of artificial intelligence in academia,HyperAI's official website now features a "Latest Papers" section, allowing users to stay up-to-date with cutting-edge AI research.
Latest AI Papers:https://go.hyper.ai/hzChC
This week's paper recommendation
1 ECHO
Paper title:
ECHO: Terminal Agents Learn World Models for Free
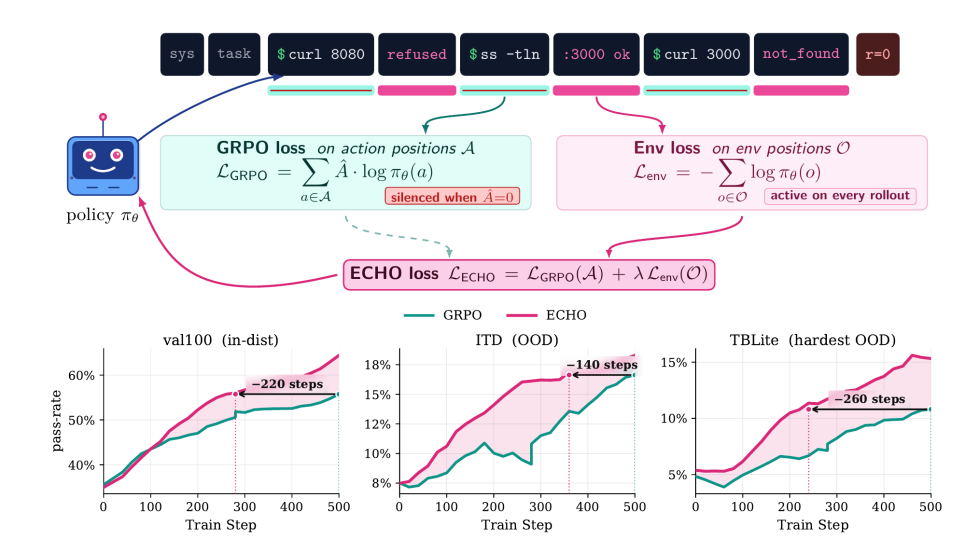
Terminal agent interactions generate massive amounts of environmental feedback, but conventional reinforcement learning only uses sparse rewards to update action labels, severely wasting observation data. This research proposes the ECHO method, which, while preserving action loss, additionally calculates cross-entropy prediction loss for environmental feedback labels. This mechanism does not increase forward propagation overhead, enabling the policy to synchronously predict the terminal's responses to instructions during training, essentially learning the world model for free.
Experimental results show that the method doubles the first-response accuracy on the terminal control benchmark, significantly enhances the ability to predict unseen terminal dynamics, greatly reduces reliance on expert demonstrations, and can even achieve self-evolution without external verification.
Paper and detailed interpretation:https://go.hyper.ai/qma4O
2 DelTA
Paper title:
DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
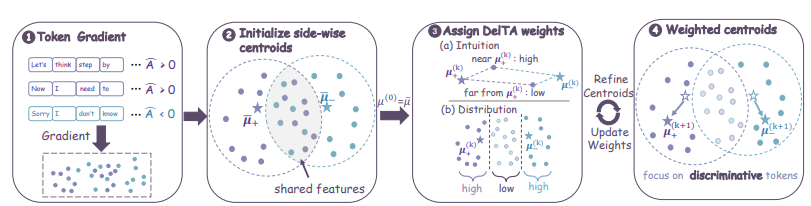
Reinforcement learning based on verifiable rewards often faces the challenge of overly coarse credit allocation granularity. Regular updates are easily dominated by high-frequency shared patterns such as typesetting, failing to effectively identify the key inference markers that truly generate high returns. To address this issue, this research proposes DelTA, which reweights the self-normalized objective function by calculating unique coefficients. This mechanism accurately amplifies the gradient directions of markers unique to both positive and negative reward sides, strongly suppressing shared, weakly discriminative directions, and significantly improving the contrast of gradient updates. In mathematical inference and code generation evaluations, this method comprehensively outperforms the best baselines of its scale and demonstrates excellent generalization ability across different architectures.
Paper and detailed interpretation:https://go.hyper.ai/IdI42
3 GoLongRL
Paper title:
GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
Long-context reinforcement learning is often limited by homogeneous retrieval training data, and conventional algorithms are prone to distorted advantage estimation due to scale and difficulty differences when dealing with mixed rewards across multiple tasks. This research proposes the capability-oriented GoLongRL scheme, pioneering an open-source dataset covering nine core capabilities and customized rewards. Addressing optimization challenges, a TMN-Reweight mechanism is designed, utilizing task-level normalization to align different reward scales and combining difficulty-adaptive weights to focus on high-value, difficult samples. Evaluations show that this scheme comprehensively outperforms existing leading models on multiple long-text benchmarks and effectively avoids the decline in general reasoning and memory capabilities.
Paper and detailed interpretation:https://go.hyper.ai/omy5E
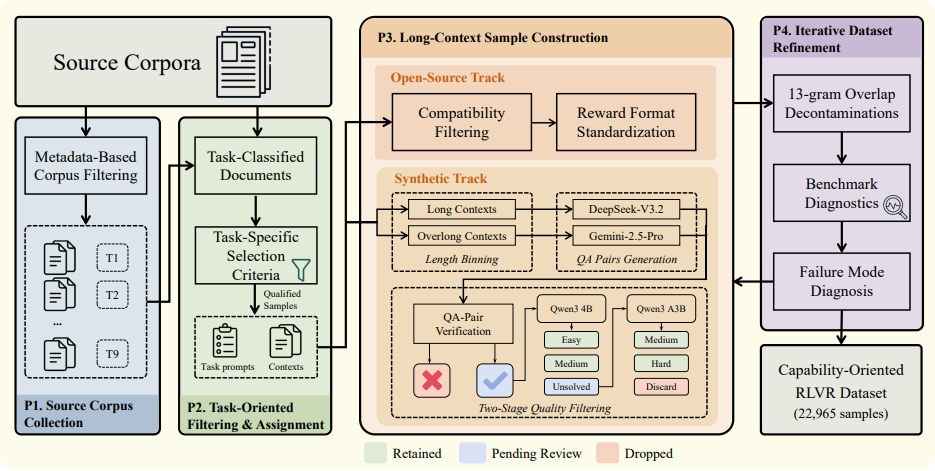
The authors constructed a dataset containing 22,965 samples, covering nine capability-oriented tasks, with context lengths ranging from 0.1K to 256K tokens.
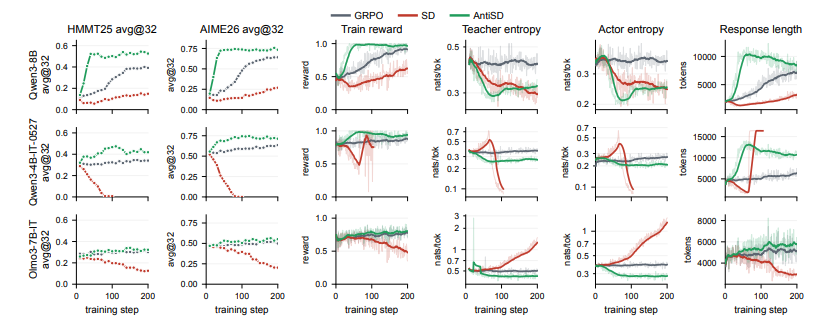
4 AntiSD
Paper title:
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Conventional self-distillation in mathematical reasoning tasks easily leads models to "take shortcuts," over-relying on known answers and suppressing the thought process that truly drives multi-step searches. To address this issue, this research proposes the Anti-Self-Distillation (AntiSD) method. Instead of passively narrowing the gap between teacher and student models, it maximizes the JS divergence to reverse the gradient signal, specifically rewarding exploratory thought markers, and supplements this with an entropy-based gating mechanism to maintain training stability. In tests on multiple large models with varying parameter scales, this method requires only one-fifth to one-half of the baseline training steps to achieve the target, while improving the final accuracy by up to 11.5 percentage points on multiple mathematical reasoning benchmarks.
Paper and detailed interpretation:https://go.hyper.ai/Vax3f
5 RubricEM
Paper title:
RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
Long-term, in-depth research tasks often lack objective rewards, and conventional reinforcement learning provides coarse feedback that fails to accumulate effective experience. This research proposes the RubricEM framework, innovatively using a "rating scale" as its core interface. The model breaks down long trajectories into planning, retrieval, review, and response stages based on a self-built scale, thereby achieving fine-grained credit allocation. Simultaneously, the framework asynchronously trains meta-policies, extracting historical interactions into reusable reflective memories. In multiple long-term research evaluations, this 8B model surpasses numerous open-source solutions and approaches top-tier closed-source systems, achieving efficient long-context learning and excellent cross-task generalization with minimal training steps.
Paper and detailed interpretation:https://go.hyper.ai/xSVTh
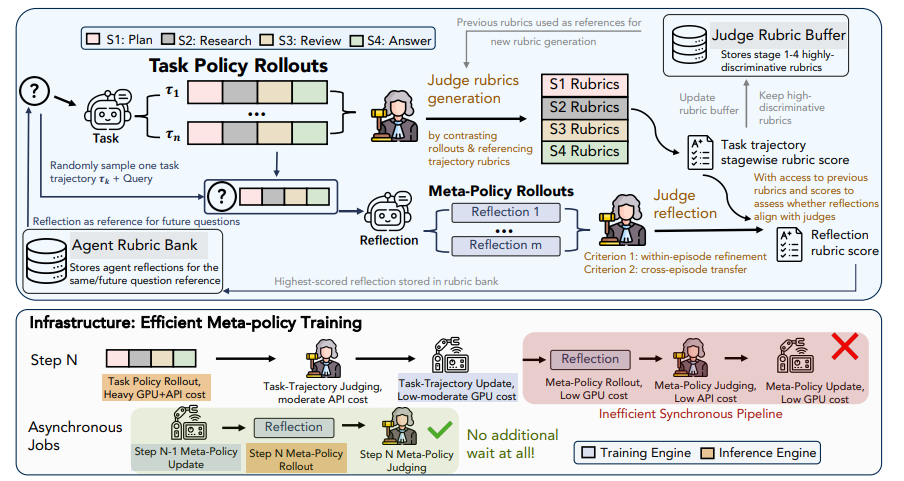
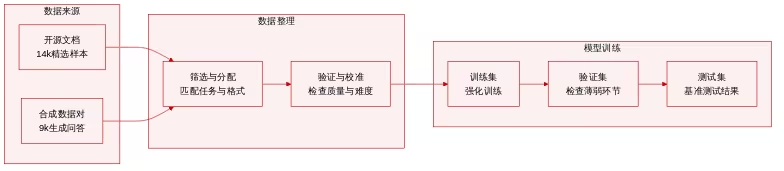
Dataset composition and source: The research team constructed a supervised fine-tuning dataset containing approximately 11,000 samples. The data source is agent trajectories generated by the Gemini teacher model and adapted for Qwen3.

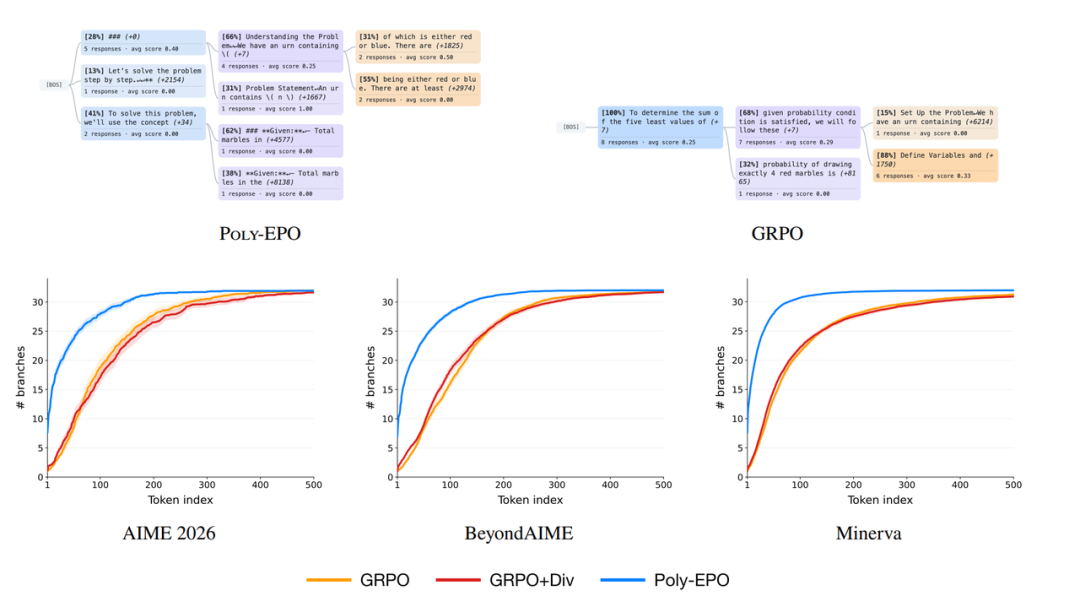
6 Poly-EPO
Paper title:
Poly-EPO: Training Exploratory Reasoning Models
Post-training of large-scale reinforcement learning models often leads to a collapse in generative diversity, hindering the exploration of new inference paths and the expansion of computation during testing. To address collaborative exploration and utilization, this study proposes the Poly-EPO algorithm based on ensemble reinforcement learning. This method breaks away from the traditional approach of evaluating individual responses in isolation, multiplying the average reward of a set of responses by the diversity score of the inference policy as a joint optimization objective, thus natively embedding signals encouraging diverse exploration into the advantage function. In mathematical reasoning evaluations, this algorithm successfully avoids policy homogenization, achieving a pass@k coverage improvement of up to 20%, and demonstrating stronger expansion potential under majority voting mechanisms.
Paper and detailed interpretation:https://go.hyper.ai/j9Z3C
The above is all the content of this week’s paper recommendation. For more cutting-edge AI research papers, please visit the “Latest Papers” section of hyper.ai’s official website.
See you next week!








