Command Palette
Search for a command to run...
Tencent open-sources Hy-MT1.5 Translation Model: 440MB Achieves top-tier Translation Capabilities; MIT Jointly Releases MathNet: a Multimodal Mathematical Inference Benchmark Covering 27,000 Real Olympiad Math problems.

Hy-MT1.5-1.8B-1.25bit is a lightweight machine translation model launched by Tencent. It is built on Hy-MT1.5-1.8B and optimized through multi-stage training, including MT pre-training, supervised fine-tuning, distillation, and reinforcement learning.The model supports 33 languages, 5 dialects and minority languages, and 1,056 translation directions.With only 1.8 billion parameters, its translation performance has surpassed that of some larger-scale open-source models and mainstream commercial translation APIs.
The HyperAI website now features "Hy-MT1.5-1.8B-1.25bit: A Lightweight Multilingual Translation Model." Give it a try!
Online use:https://go.hyper.ai/PCK8X
Welcome to visit our official website for more information:
A quick overview of hyper.ai's official website updates from May 6th to May 15th:
* High-quality public datasets: 12
* A selection of high-quality tutorials: 7
* Community article interpretation: 3 articles
* Popular encyclopedia entries: 5
Visit the official website:hyper.ai
Selected public datasets
1. QCalEval Quantum Calibration Graph Understanding Dataset
QCalEval, released by NVIDIA in 2026, is a visual language dataset for graph understanding in quantum computing experiments. It aims to evaluate the ability of visual language models (VLMs) to interpret, classify, and reason about the results of quantum computing calibration experiments, and is widely used in research on visual language models and scientific image understanding. The dataset contains 309 PNG-formatted two-dimensional scientific images, 243 benchmark entries, and 236 few-shot benchmark entries, covering 22 experimental series and 87 scene types.
Online use:https://go.hyper.ai/Ke7cu
2. Claw-Eval Real-World Benchmark Dataset
Claw-Eval, released in 2026 by Peking University and the University of Hong Kong, is an end-to-end transparent benchmark dataset for evaluating AI agents in real-world tasks. It aims to assess autonomous agents' capabilities in task execution, tool invocation, multimodal understanding, and multi-turn interaction in real-world environments. The dataset supports both English and Chinese and includes three core task groups: General, Multimodal, and Multi-turn, covering 24 task categories such as communication, finance, office work, and productivity tools.
Online use:https://go.hyper.ai/Tznpa
3. MathNet Multimodal Mathematical Benchmark Inference Dataset
MathNet is a large-scale, multilingual, multimodal mathematical reasoning dataset released in 2026 by the MIT team in collaboration with King Abdullah University of Science and Technology and other institutions. It aims to evaluate and improve the capabilities of large models in Olympiad-level mathematical reasoning and structured retrieval tasks, and is widely used in mathematical reasoning evaluation, RAG research, and multimodal AI training.
Online use:https://go.hyper.ai/HLxNw
4. RSRCC Remote Sensing Area Change Understanding Baseline Dataset
RSRCC, released by Google Research in 2026, is a benchmark dataset for understanding semantic change in remote sensing. It aims to support a deep understanding of temporal changes in remote sensing scenes by pairing multi-temporal image evidence with natural language question answering, elevating traditional binary change detection to a semantic change description dimension. The dataset contains 126,000 question-and-answer samples for remote sensing change detection, covering scenarios such as new construction, demolition, road changes, vegetation changes, and residential development.
Online use:https://go.hyper.ai/jtCaK
5. Medical Waste Detection Dataset
Medical Waste is a high-resolution image dataset designed for intelligent identification and target detection of medical waste. It aims to help computer vision models achieve automatic detection and classification of medical waste in complex medical environments and is widely used in research areas such as smart healthcare, public health, automated waste sorting, and robot vision.
Online use:https://go.hyper.ai/PrUKd
6. Grape Leaf Diseases Dataset
GRAPE Leaf Diseases is a grape leaf image dataset specifically designed for precision agriculture target detection tasks, aiming to improve the ability of computer vision models to detect, classify, and locate diseases in real agricultural scenarios. The dataset contains 4,195 grape leaf images, covering four categories: healthy grape leaves and three common diseases: black rot, Escafé fulva, and leaf blight.
Online use:https://go.hyper.ai/tJrkm
7. Aquatic Wildlife Atlas: A global dataset of aquatic life.
The Aquatic Wildlife Atlas: Global Species Records is a large-scale aquatic animal observation dataset designed for aquatic ecological research and biodiversity analysis. It aims to provide researchers, students, and data scientists with high-quality aquatic ecological data resources. The dataset contains 200,000 aquatic animal observation records, covering more than 100 aquatic species and encompassing major aquatic ecosystems worldwide, including coral reefs, tropical rivers, the Arctic Ocean, and deep-sea areas up to 7,000 meters deep.
Online use:https://go.hyper.ai/calNa
8. Global Earthquake-M4.5: A global dataset of earthquakes of magnitude 4.5 and above.
Global Earthquake Events – M4.5+ is a global earthquake event dataset designed for seismic activity analysis and geospatial research. It aims to help researchers analyze the frequency, distribution, and magnitude variations of long-term seismic activity. The dataset contains 230,608 earthquake records, covering global earthquakes of magnitude 4.5 and above from 1900 to 2026.
Online use:https://go.hyper.ai/D7j95
9. Synthetic Drug Effectiveness Dataset
Synthetic Drug Effectiveness is a generated dataset of synthetic drugs designed to support drug safety analysis and clinical risk assessment, suitable for data analysis, model building, and experimental research. This dataset contains structured medical information on drug use and adverse reaction monitoring. Each record is indexed by a unique report number and includes basic information such as patient age and gender, as well as treatment details such as drug name, dosage, duration of use, and concomitant medications.
Online use:https://go.hyper.ai/1ZaA0
10. Fundus Eye Disease Classification Dataset
The Eye Disease Classification Fundus is a medical vision dataset designed for fundus image classification tasks, aiming to improve the classification capabilities of computer vision models in ophthalmic disease identification and assisted diagnosis scenarios. The dataset contains 6,086 images, including four categories of fundus images: cataracts, diabetic retinopathy, glaucoma, and normal fundus.
Online use:https://go.hyper.ai/FFFE7
11. Breast Cancer: Multi-Modal Fusion Dataset
Breast Cancer: Multi-Modal Fusion is a preprocessed multimodal dataset built for patients with invasive breast cancer (BRCA), designed to provide a plug-and-play foundation for building multimodal fusion networks. This dataset rigorously aligns multi-source data from 122 BRCA patients, with all samples mapped across modalities using TCGA Case IDs, achieving a one-to-one correspondence between macroscopic medical imaging (MRI), microscopic digital pathology (Histopathology), molecular omics (Multi-Omics), and clinical treatment information.
Online use:https://go.hyper.ai/199WV
12. Long-Distance Wildfire & Smoke Detection Dataset
Long-Distance Wildfire & Smoke Detection is a computer vision dataset designed for early warning and environmental monitoring of forest fires. It aims to improve the model's ability to detect smoke and wildfires in long-distance forest monitoring scenarios. This dataset is generated using a fully synthetic approach, simulating high-angle, long-distance monitoring scenarios such as forest fire towers and ridge surveillance cameras, with a focus on detecting wildfire smoke plumes, which are more easily observed in the early stages of a fire.
Online use:https://go.hyper.ai/LnuXC
Selected Public Tutorials
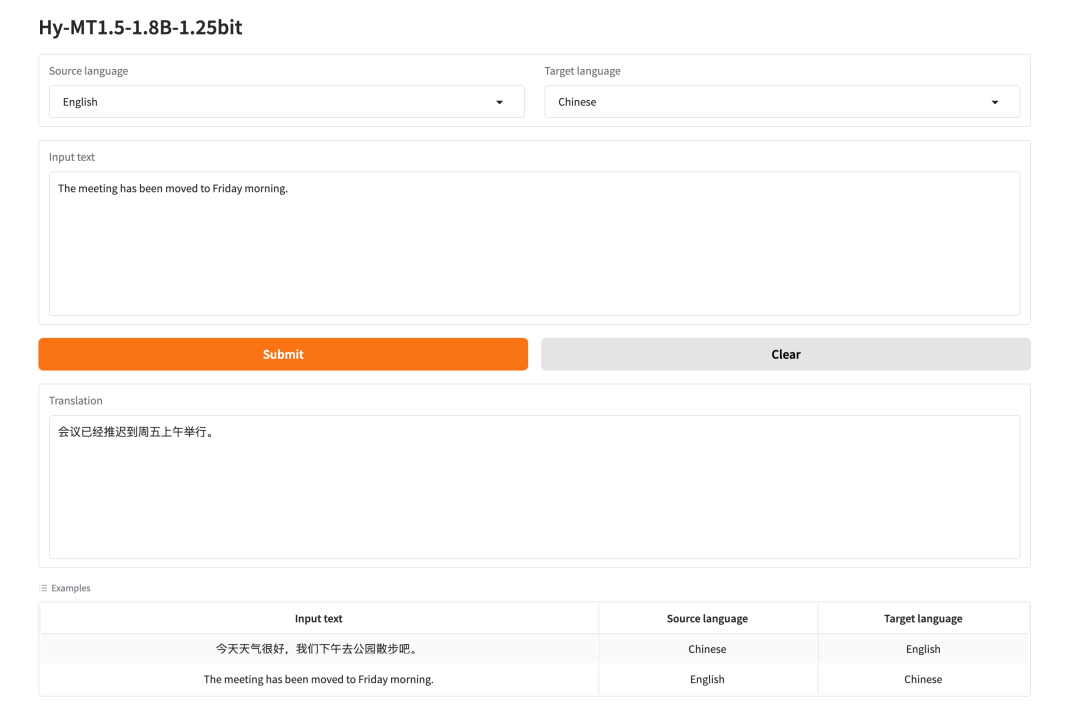
1. Hy-MT1.5-1.8B-1.25bit: Lightweight Multilingual Translation Model
Hy-MT1.5-1.8B-1.25bit, released by Tencent in April 2026, is a 1.25-bit quantized multilingual translation model based on Hy-MT1.5-1.8B. The core value of this model lies in compressing high-quality multilingual translation capabilities into a more lightweight deployment form.
Run online:https://go.hyper.ai/PCK8X
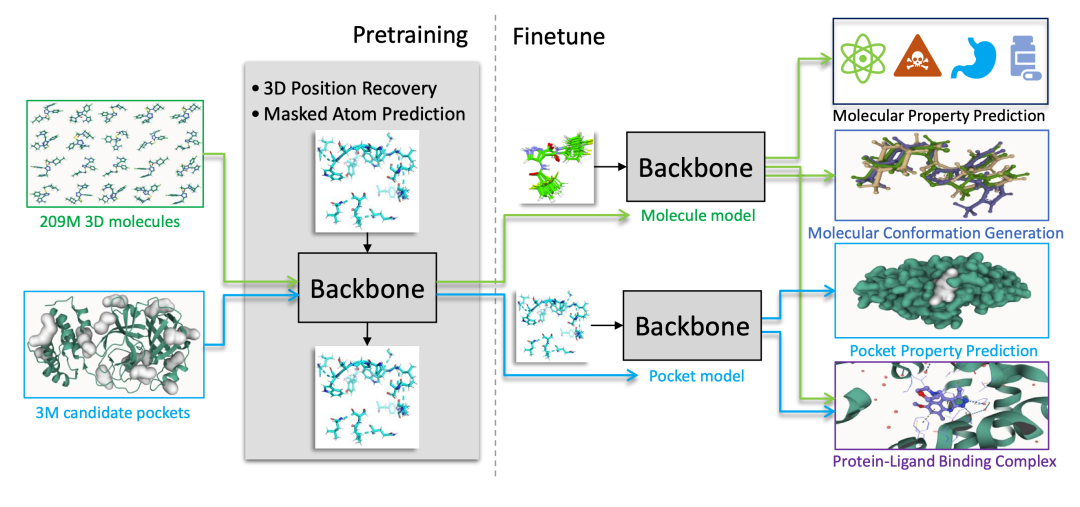
2. Uni-Mol: A General 3D Molecular Representation Learning Framework
Uni-Mol is a general-purpose 3D molecular pre-training framework released by DP Technology in 2022. Uni-Mol expands molecular representation capabilities through large-scale 3D molecular structure pre-training and can be used for tasks such as drug design, molecular property prediction, and protein-ligand interaction modeling.
Run online:https://go.hyper.ai/RukIx
3. One-click deployment of Mistral-Medium-3.5-128B
Mistral Medium 3.5, released by Mistral AI in 2025, is a flagship fusion model with 128 billion (128B) parameters and 256k context windows, unifying instruction compliance, inference, and programming capabilities within a single set of weights. This model replaced the previous Mistral Medium 3.1 and Magistral models, and also replaced Devstral 2 in the Vibe programming agent.
Run online:https://go.hyper.ai/PXiHc
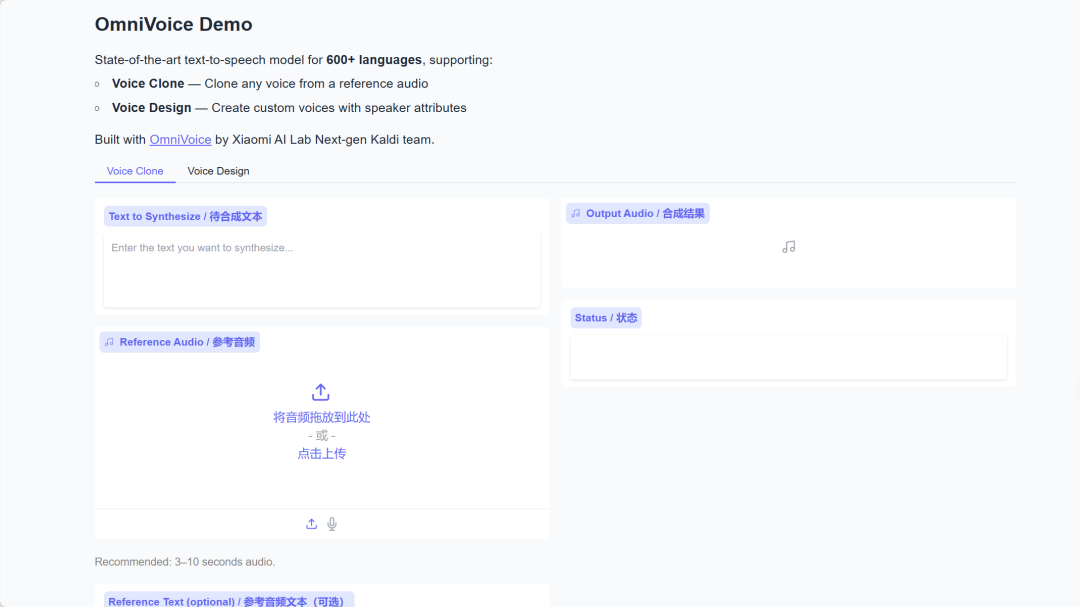
4. OmniVoice: Supports high-quality TTS in 600+ languages.
OmniVoice is a multilingual text-to-speech (TTS) model developed by Xiaomi AI Lab's Next-gen Kaldi team, supporting high-quality speech synthesis in over 600 languages. Based on an iterative unmasked decoding architecture, the project implements three core functions: voice cloning, voice design, and automatic voice.
Run online:https://go.hyper.ai/7F7IR
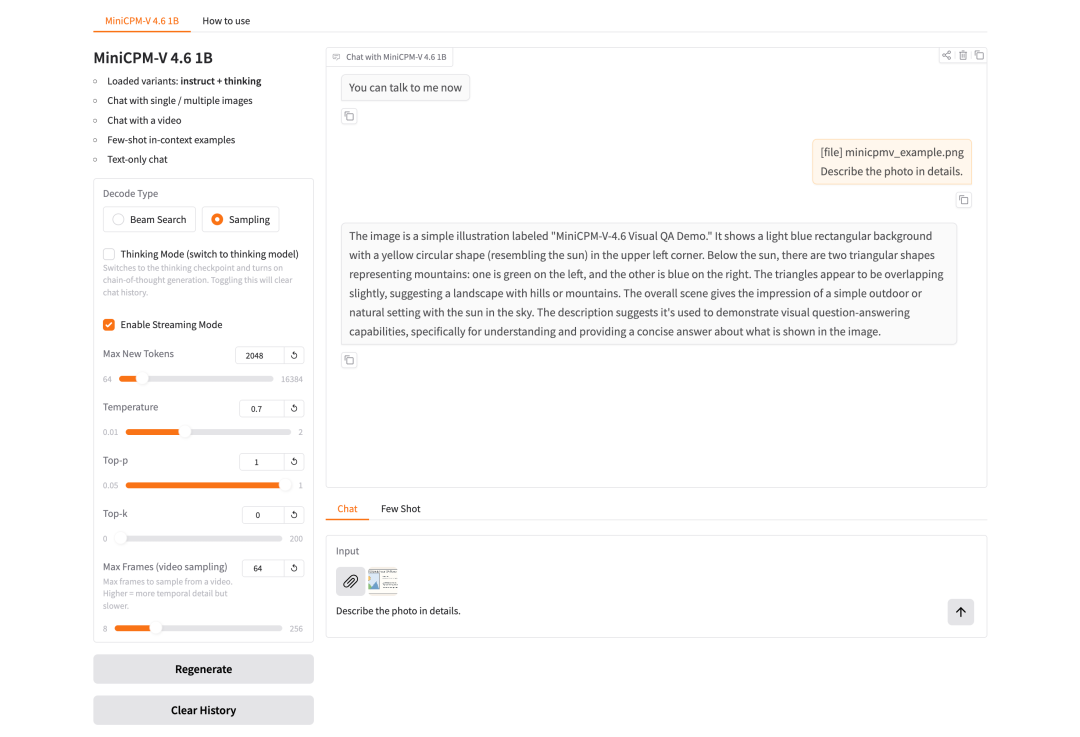
5. MiniCPM-V-4.6: High-efficiency multimodal visual language model for edge devices
MiniCPM-V-4.6, released in May 2026 by the OpenBMB team and the Tsinghua University Natural Language Processing Laboratory, is an efficient edge-side multimodal visual language model for image understanding, video understanding, visual question answering, OCR, and multi-turn multimodal dialogue scenarios. Its core value lies in covering common multimodal understanding tasks with a relatively small model size, making it more suitable for image question answering, short video summarization, screenshot understanding, document image OCR, and multi-turn multimodal dialogue validation in resource-constrained environments.
Run online:https://go.hyper.ai/azdHU
6. LingBot-Map: Geometric Context Transformer for Streaming 3D Reconstruction
LingBot-Map is a streaming 3D reconstruction project released by the Robbyant Team in April 2026. The project takes image sequences or video frames as input and can perform online 3D scene reconstruction in a feed-forward manner. Point clouds, camera trajectories and frame-by-frame results can be viewed through a 3D Viewer in a browser.
Run online:https://go.hyper.ai/BR4me

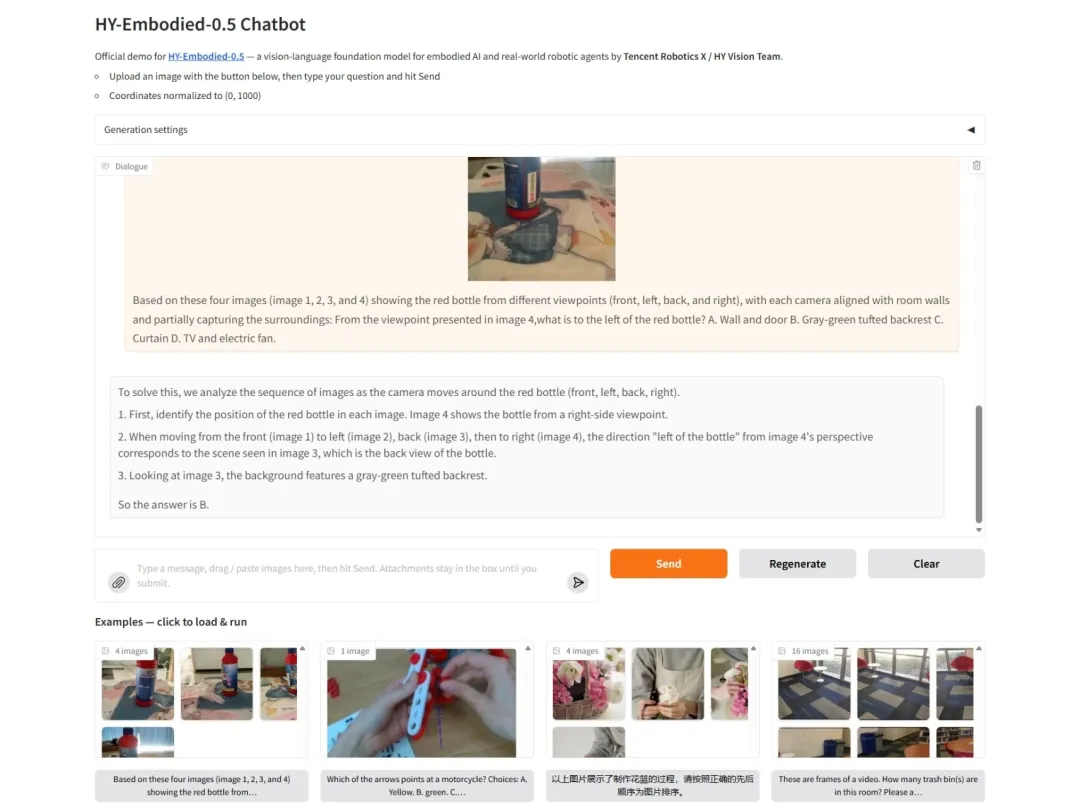
7. HY-Embodied-0.5: An Embodied Foundation Model for Real-World Intelligent Agents
HY-Embodied-0.5 is a foundational model specifically designed for embodied intelligence, jointly open-sourced by Tencent's Hunyuan team and Tencent Robotics X Lab in April 2026. This series of models is not a simple tweak of a general-purpose base, but a complete reconstruction from architecture to training paradigm. The team simultaneously released two main models: MoT-2B (4B total parameters, 2B activations) focusing on real-time edge-side response, and MoE-32B (407B total parameters, 32B activations) pursuing ultimate inference performance.
Run online:https://go.hyper.ai/u8lJk
Community article interpretation
1. EnergAIzer, a GPU power estimation framework developed by MIT and others, completes predictions in an average of 1.8 seconds with an error of approximately 81 TP3T.
Researchers from MIT and the MIT-IBM Watson AI Lab have developed EnergAIzer, a fast GPU power estimation framework for AI workloads that provides hardware utilization information directly to power models without the need for expensive simulations or performance analysis. This new framework completes end-to-end power estimation in an average of just 1.8 seconds. On NVIDIA Ampere GPUs, EnergAIzer achieves a power error of approximately 81 TP3T, which is competitive with traditional models that rely on complex, cyclic simulations or hardware performance analysis.
View the full report:https://go.hyper.ai/1PeMV
2. Token usage decreased by 30%. Eywa, a heterogeneous intelligent agent framework inspired by "Avatar," efficiently combines language models with domain-specific basic models.
A research team from the University of Illinois at Urbana-Champaign (UIUC) has proposed Eywa, a heterogeneous agent framework for connecting language agents with domain-specific foundational models. By combining domain-specific foundational models with language models, the researchers constructed a novel EywaAgent, a design that enables the language agent to guide the foundational model's reasoning, planning, and decision-making processes in its specialized tasks.
View the full report:https://go.hyper.ai/CzRL4
3. A hundred universities have launched the world's largest multi-cohort proteogenomics study, unlocking disease-causing genes and repurposing existing drugs based on data from nearly 80,000 participants.
A team from over a hundred universities and research institutions, including Queen Mary University of London and the University of Cambridge, has published the world's largest multi-cohort proteogenomics study to date. Based on a large-scale meta-analysis of proteoglyphics covering 38 independent research cohorts and a total of 78,664 participants, the study systematically identified 24,738 quantitative trait loci of proteins and associated them with 1,116 circulating proteins, comprehensively revealing the extensive proximity and distance genetic regulatory characteristics at the protein level.
View the full report:https://go.hyper.ai/lGD68
Popular Encyclopedia Articles
1. World Models
2. Calibration Curve
3. Gated Attention
4. Human-in-the-loop
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provides domestic accelerated download nodes for 2100+ public datasets
* Includes 700+ classic and popular online tutorials
* Analyzing 300+ AI4Science Paper Cases
* Supports searching for 700+ related terms
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








