Command Palette
Search for a command to run...
Paper Weekly Report | ProgramBench Enables AI to Write Software From Scratch, With 9 Major Models Failing En Masse; ExoActor Demonstrates Strong Scene Generalization Ability Without Additional real-world Data… A Quick Overview of the week's cutting-edge AI Papers

As language models are increasingly used in long-term software development, existing benchmarks are no longer sufficient to measure their performance in system architecture design, module partitioning, and overall engineering implementation. To address this, the SWE-Bench team proposed the ProgramBench benchmark: providing models only with the executable file and usage documentation, requiring them to rewrite the code and reproduce the program's behavior.
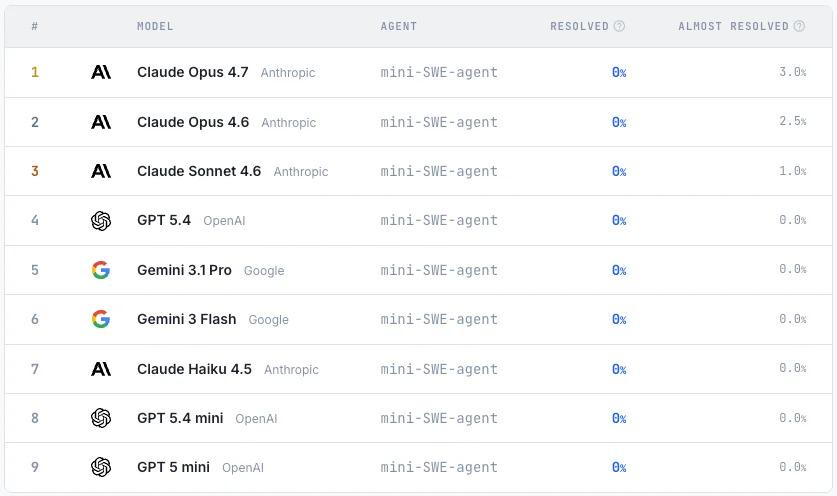
The study constructed 200 tasks covering various software types, including databases, compilers, and command-line tools, and evaluated the consistency between the model-generated program and the original program through behavioral testing.Experimental results show that current mainstream models still struggle to complete complex software reconstruction tasks, and no model can pass all tests.Even the best-performing Claude Opus 4.7 only achieved a high pass rate on a few tasks, indicating that large language models still have significant shortcomings in terms of overall software engineering capabilities.
Paper link:https://go.hyper.ai/wExzR
Latest AI Papers:https://go.hyper.ai/hzChC
To help more users understand the latest developments in the field of artificial intelligence in academia,The HyperAI website (hyper.ai) now features a "Latest Papers" section, which is regularly updated with cutting-edge AI research papers.Here are 8 popular AI papers we recommend. Let's quickly take a look at the latest AI achievements this week ⬇️
This week's paper recommendation
1. ProgramBench
Paper title:
ProgramBench: Can Language Models Rebuild Programs From Scratch?
The research team proposed ProgramBench to evaluate the ability of software engineering agents to build complete software projects from scratch. This benchmark requires the agent to implement a codebase that behaves consistently with a reference executable, based solely on the program and documentation, and to perform end-to-end evaluation through agent-driven fuzz testing.
ProgramBench contains 200 tasks, covering various software types including CLI tools, FFmpeg, SQLite, and PHP interpreters. Experiments on nine language models show that the current models have limited overall performance. The best model only passed the test of 95% in the 3% task, and the generated code generally exhibits a monolithic, single-file structure, which differs significantly from human software engineering practices.
Paper and detailed interpretation:https://go.hyper.ai/wExzR
Dataset Composition and Sources: The authors compiled 200 task instances from open-source GitHub repositories. The sources were selected from projects that produce standalone executables, primarily in Rust, Go, or C/C++. The collection includes diverse functional categories such as text processing, system utilities, and language interpreters.

2. Uni-OPD
Paper title:
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
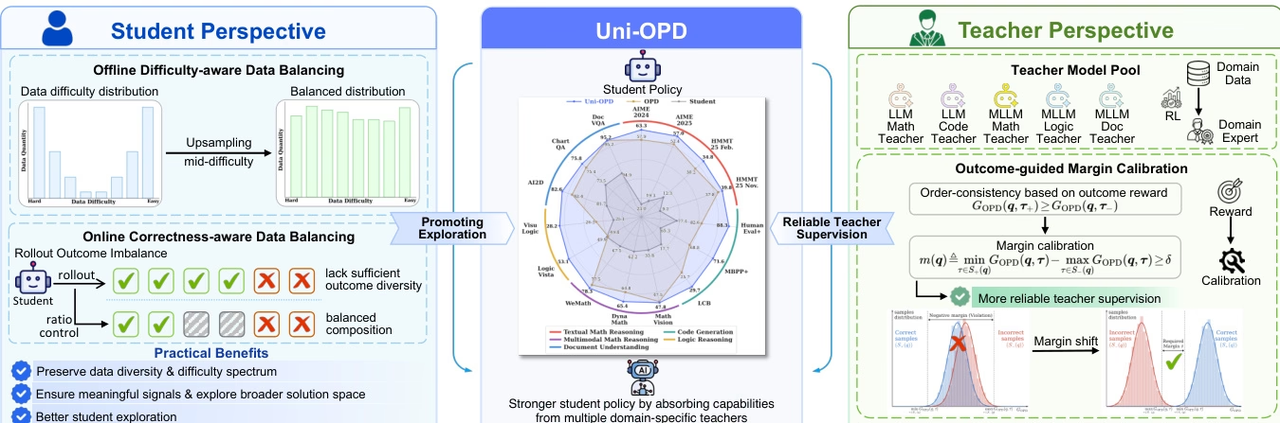
Uni-OPD is a unified online distillation framework for LLMs and MLLMs, designed to improve the transfer of multi-expert knowledge to student models. Research indicates that existing OPD methods are primarily limited by two problems: insufficient exploration of high-information states and unreliable teacher supervision signals.
To address this, Uni-OPD employs a dual-perspective optimization strategy: from the student side, it introduces a data balancing strategy to enhance the exploration of high-information states; from the teacher side, it proposes an outcome-guided marginal calibration mechanism to restore the sequential consistency between correct and incorrect trajectories, thereby improving the reliability of supervision. Experiments covering five domains and 16 benchmarks, encompassing various settings such as single-teacher, multi-teacher, strong-to-weak, and cross-modal distillation, validated the effectiveness of the method.
Paper and detailed interpretation:https://go.hyper.ai/8k4du
3. Faithful Uncertainty
Paper title:
Hallucinations Undermine Trust; Metacognition is a Way Forward
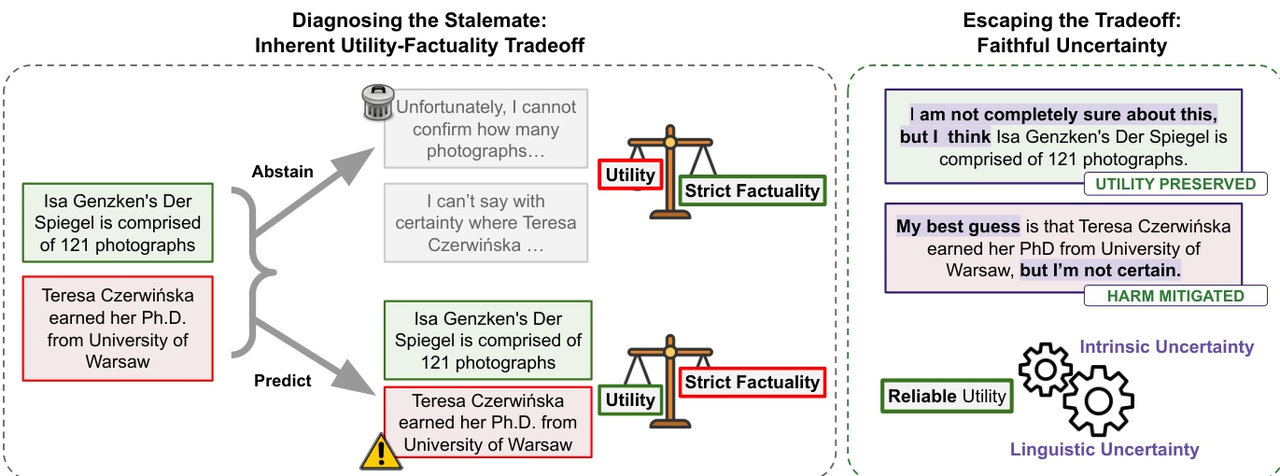
The research team points out that although large language models are constantly improving in terms of factual reliability, the "illusion" problem remains prevalent, especially in factual question-answering scenarios where external tools are lacking. The study argues that current progress stems more from expanding the scale of knowledge than from the model's true ability to distinguish between the "known" and the "unknown." Therefore, completely eliminating illusions may form a natural trade-off with the model's practicality.
Based on this perspective, the study proposes the concept of "faithful uncertainty," emphasizing that models should truthfully express their own uncertainty, ensuring consistency between linguistic uncertainty and internal cognition. This metacognitive ability not only helps improve model credibility but also provides a more reliable control mechanism for search and decision-making in intelligent agent systems.
Paper and detailed interpretation:https://go.hyper.ai/G77rj
Dataset composition and source: The authors constructed a synthetic dataset containing 25,000 samples to reproduce the empirical confidence distribution characteristics recorded by Nakkiran et al. (2025).

4. PRISM
Paper title:
Beyond SFT-to-RL: Pre-alignment via Black-Box On-Policy Distillation for Multimodal RL
To address the issue of distribution shift affecting subsequent reinforcement learning during fine-tuning of large multimodal models, the research team proposed a three-stage process called PRISM. This method inserts a distribution alignment stage based on intra-policy distillation between supervised fine-tuning and reinforcement learning, and utilizes a hybrid expert (MoE) discriminator to provide decoupling correction signals.
Using 113,000 high-quality Gemini demo datasets, PRISM significantly improved the performance of downstream reinforcement learning in the Qwen3-VL experiment, increasing the accuracy of 4B and 8B models by 4.4 and 6.0 points, respectively.
Paper and detailed interpretation:https://go.hyper.ai/5fsD3
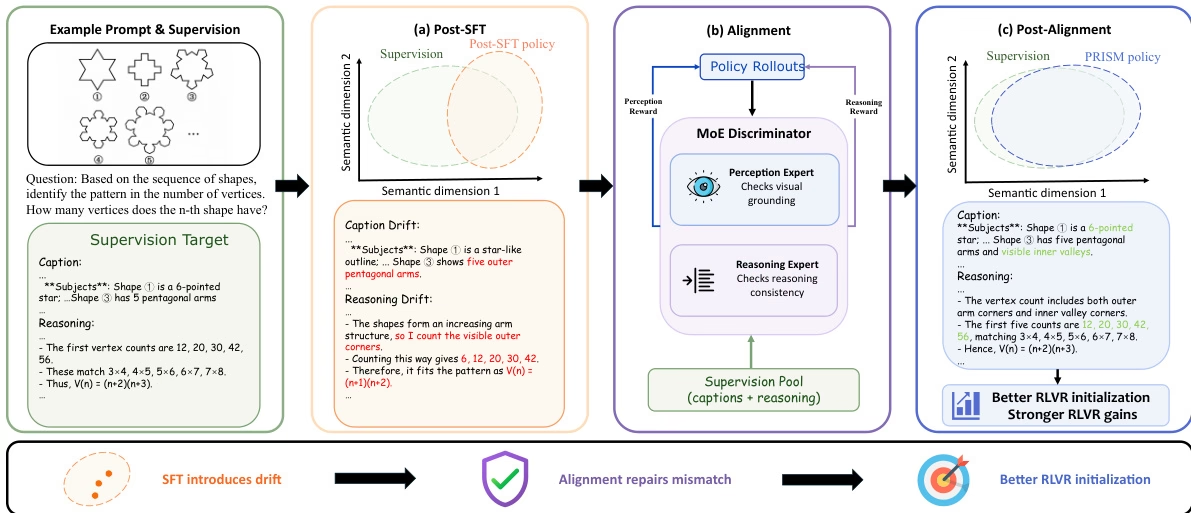
Dataset Composition and Sources: This paper constructs a multimodal reasoning corpus, with data sourced from publicly available benchmark tests covering mathematical reasoning, scientific graph understanding, graph interpretation, and spatial reasoning. To expand coverage and stability, this carefully selected set is supplemented with 1.26 million publicly available demo data generated by the same series of Gemini models.
5. ExoActor
Paper title:
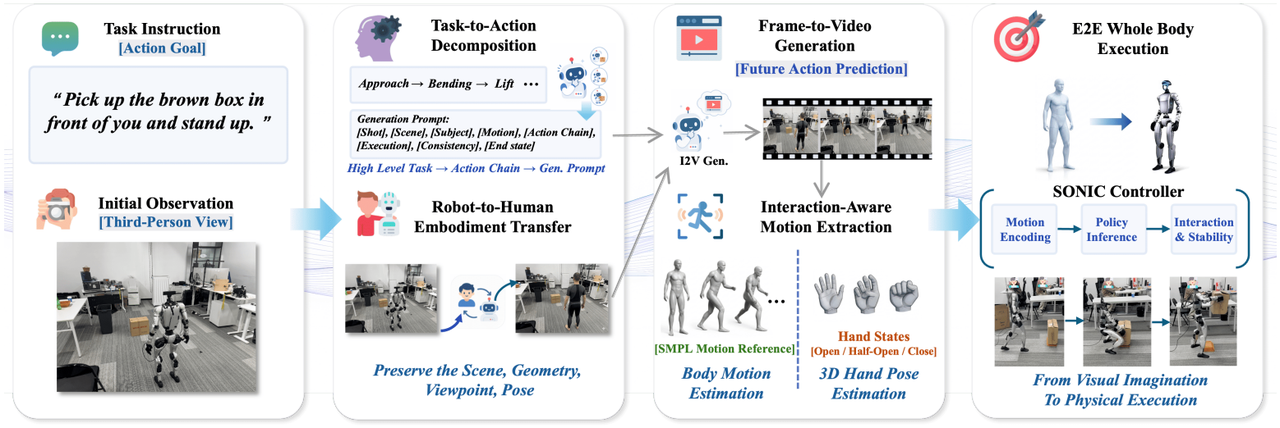
ExoActor: Exocentric Video Generation as Generalizable Interactive Humanoid Control
The research team proposed the ExoActor framework, which uses exocentric video generation as a unified interface to implicitly encode the collaborative interactions between the robot, the environment, and objects. It also converts the synthesized execution video into executable humanoid robot behaviors through human motion estimation and a general motion controller, thus demonstrating the ability to generalize to new scenarios without the need for additional on-site data collection.
Paper and detailed interpretation:https://go.hyper.ai/OE5IH
6. Edit-R1
Paper title:
Leveraging Verifier-Based Reinforcement Learning in Image Editing
The research team proposed Edit-R1, a reinforcement learning framework for image editing. Unlike traditional reward models that only output an overall score, Edit-R1 breaks down editing instructions into multiple principles and verifies the editing results item by item based on thought chain reasoning, thereby generating more fine-grained and interpretable reward signals. The research further combines supervised fine-tuning with GCPO reinforcement learning strategies to improve the reward model's ability to model human preferences, and utilizes GCPO to train downstream editing models.
Experimental results show that Edit-RRM outperforms powerful VLMs such as Seed-1.5-VL and Seed-1.6-VL in image editing evaluation, and significantly improves the performance of editing models such as FLUX.1-kontext, while also demonstrating significant benefits from parameter expansion.
Paper and detailed interpretation:https://go.hyper.ai/MtBLB
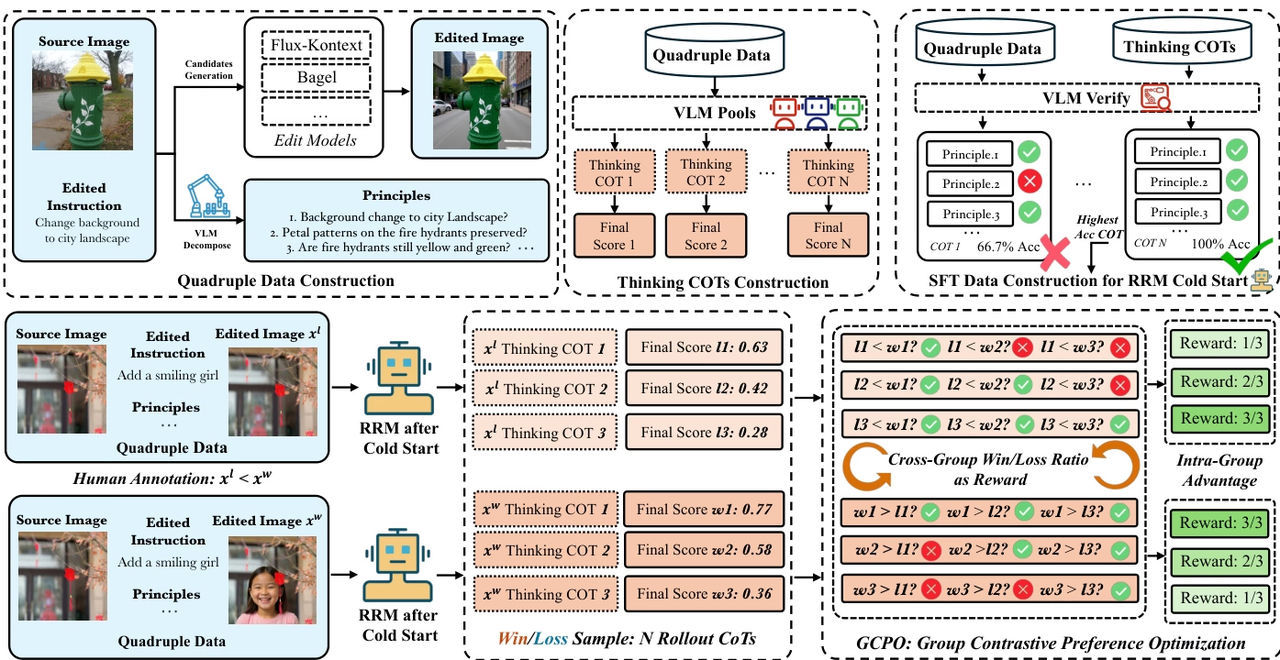
Dataset Composition and Source: The research team constructed a supervised dataset for a cold-start inference reward model by compiling 200,000 samples from publicly available image editing benchmarks. This initial set was expanded to approximately 2 million data quadruples through multi-model generation and systematic validation.

7. Co-Evolving Policy Distillation
Paper title:
Co-Evolving Policy Distillation
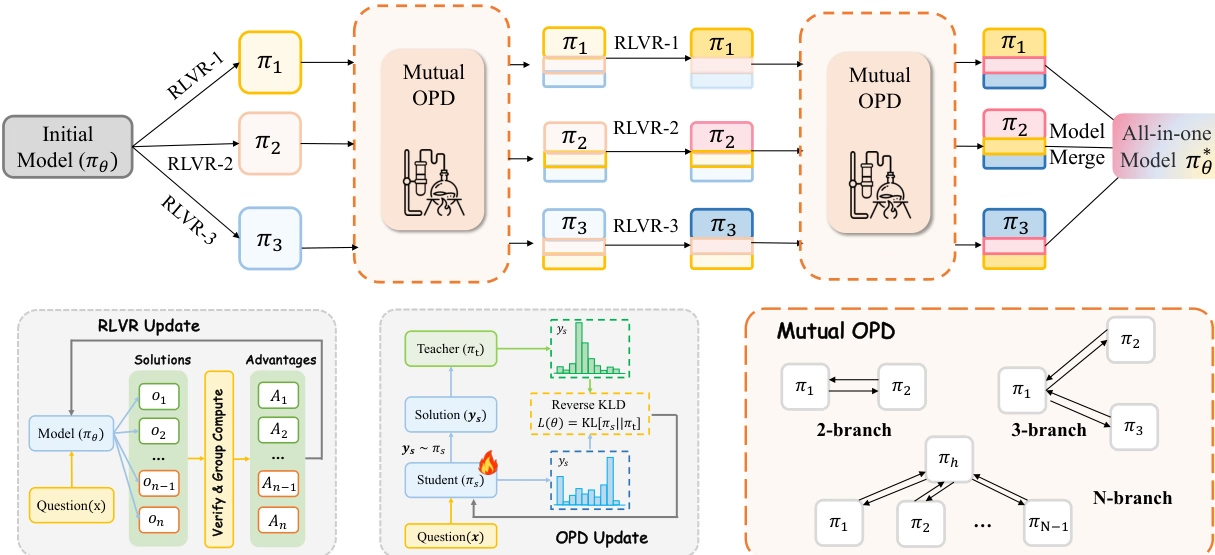
The research team conducted a unified analysis of the two mainstream post-training paradigms, RLVR and OPD, and pointed out that they have different limitations in the process of integrating multiple expert capabilities: hybrid RLVR is prone to "cross-capability divergence costs", while the traditional process of "training experts first and then implementing OPD" avoids capability conflicts, but due to the large differences in behavioral patterns between teachers and students, it is difficult to fully inherit expert capabilities.
To address this issue, this study proposes a co-evolutionary strategy, CoPD (Co-Evolutionary Processing), which introduces bidirectional OPD (Optical Processing Derivative) simultaneously while experts continuously train for RLVR (Reference-Based RLVR). This allows experts to act as teachers to each other and co-evolve, thereby improving behavioral consistency while maintaining complementary capabilities. Experimental results show that CoPD effectively integrates text, image, and video reasoning capabilities, significantly outperforming strong baselines such as hybrid RLVR and MOPD, and even surpassing domain expert models on some tasks.
Paper and detailed interpretation:https://go.hyper.ai/cCyrG

8. ClawGym
Paper title:
ClawGym: A Scalable Framework for Building Effective Claw Agents
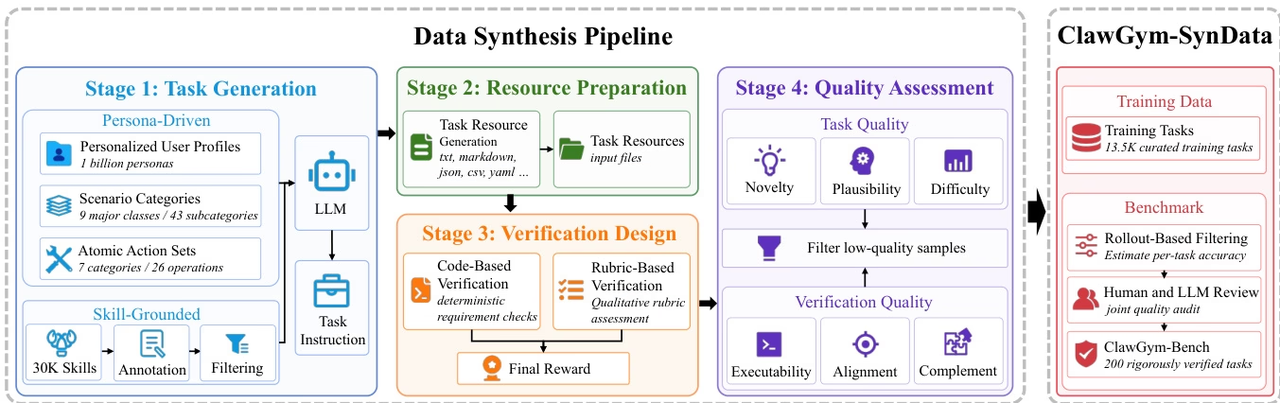
The research team proposed ClawGym, a scalable framework for the entire lifecycle of Claw-style personal agent development, to support complex, multi-step workflows involving local files, tool calls, and persistent workspace states.
The framework includes the synthetic dataset ClawGym-SynData, covering 13,500 selected tasks, and combines human intent, skill operation, simulated workspace, and hybrid verification mechanisms. ClawGym-Agents are trained based on black-box rollout trajectories and their capabilities are improved through a lightweight reinforcement learning pipeline. In addition, a benchmark set ClawGym-Bench, which is automatically selected and jointly reviewed and calibrated by humans and LLM, is built for reliable evaluation.
Paper and detailed interpretation:https://go.hyper.ai/yZwa5
Dataset source: The research team generated training data using the ClawGym-SynData framework, which combines personality-driven top-down synthesis for diverse user scenarios with bottom-up synthesis based on the technology of connecting OpenClaw capabilities into a real workflow.
The above is all the content of this week’s paper recommendation. For more cutting-edge AI research papers, please visit the “Latest Papers” section of hyper.ai’s official website.
We also welcome research teams to submit high-quality results and papers to us. Those interested can add the NeuroStar WeChat (WeChat ID: Hyperai01).
See you next week!








