Command Palette
Search for a command to run...
4-step Image output/4K quality/6x Speedup, PiD Uses Pixel Diffusion to Unify Decoding and super-resolution Output; SA-3DAO: a Dataset Containing 1000 Pairs of Real Images Paired With Handcrafted 3D Meshes by artists.

PiD is a new latent space decoding paradigm released by NVIDIA. It redefines the traditional VAE decoding process as conditional pixel diffusion generation, unifying decoding and super-resolution upsampling into a single generation module. Traditional latent diffusion models restore latent variables to the image through VAE, resulting in limited output resolution. Furthermore, reconstruction-oriented decoders struggle to recover high-frequency details and cannot correct artifacts in latent variables.PiD introduces a lightweight noise-aware latent variable adapter (Sigma-aware adapter) to inject noisy latent variables into the pixel spatial diffusion backbone network.This allows the model to handle both fully denoised latent variables and to prematurely terminate the diffusion process for partially denoised latent variables. With the help of DMD2 distillation technology, inference can be completed in just four denoising steps.
The HyperAI website now features "PiD: 4K Super-Resolution Image Generation and Editing," so come and try it out!
Online use:https://go.hyper.ai/a34Cx
Welcome to visit our official website for more information:
A quick overview of hyper.ai's official website updates from June 19th to June 26th:
* High-quality public datasets: 7
* A selection of high-quality tutorials: 14
* Community article interpretation: 4 articles
* Popular encyclopedia entries: 5
Visit the official website:hyper.ai
Selected public datasets
1. SAM 3D Artist Objects 3D Object Reconstruction Dataset
SAM 3D Artist Objects is a 3D mesh pairing dataset released by Meta in June 2026. It aims to evaluate the performance of 3D reconstruction algorithms for object shapes and layouts in real-world scenes, and is widely used for performance testing of image-to-3D object algorithms, model optimization, and related research in computer vision. This dataset contains 1,000 pairs of real images paired with 3D meshes handcrafted by professional artists.
Online use:https://go.hyper.ai/rn2aF
2. RHELM Long-Term Memory Assessment Dataset
RHELM is a long-term memory assessment dataset released by Microsoft in 2026. It aims to improve the long-term memory, multi-hop reasoning, and temporal information synthesis capabilities of large models in complex and dynamic scenarios. This dataset is widely used in research scenarios such as long-term temporal memory evaluation of large language models, verification of long-term interaction capabilities of AI assistants, multi-hop reasoning of large models, temporal information fusion, and hallucination detection.
Online use:https://go.hyper.ai/OGkUl
3. MAKIEVAL Multilingual Cultural Knowledge Assessment Dataset
MAKIEVAL is a multilingual cultural knowledge evaluation dataset released in 2026 by the MaiNLP Research Laboratory at the University of Munich in collaboration with the Munich Machine Learning Center. It aims to provide a large-scale benchmark for evaluating multilingual cultural knowledge for large language models and is widely used in research on multilingual knowledge representation and cultural knowledge modeling. This dataset contains texts generated by seven large language models in 13 languages, 19 countries/regions, and 6 cultural domains, along with their automatically extracted cultural entities and alignment results with Wikidata.
Online use:https://go.hyper.ai/v7zip
4. Verbatim Spans query condition evidence extraction dataset
Verbatim Spans, released in April 2026 by TU Wien in collaboration with KRLabs, is a multi-domain query conditional evidence extraction dataset. It aims to build a general benchmark for training query conditional evidence extraction models, widely applicable to Retrieval Augmentation (RAG) and extractive question answering tasks. The dataset contains 174,383 rows of training data and 20,174 rows of validation data, covering three main types of corpora: natural language processing papers, multi-domain question answering, and code and tool outputs.
Online use:https://go.hyper.ai/hbpjR
5. Nemotron-SFT-Math-v4 Mathematical Inference SFT Dataset
Nemotron-SFT-Math-v4 is a mathematical reasoning dataset released by NVIDIA in May 2026. It aims to address the problems of inconsistent quality, non-standard reasoning trajectories, low accuracy, and limited scenario diversity in traditional mathematical datasets, effectively improving the model's structured reasoning, multi-trajectory reasoning, and answer verification capabilities. This dataset contains 545,431 training samples, including 285,516 COT (Content-Oriented Reasoning) reasoning samples and 259,915 TIR (Tracking Inference) tool reasoning samples, covering competition and research-level mathematical scenarios in algebra, geometry, number theory, combinatorics, and other subjects.
Online use:https://go.hyper.ai/6ooPw
6. AI Impact on Jobs and Layoff Risk: AI-powered employment impact dataset
AI Impact on Jobs and Layoff Risk is a synthetic structured machine learning dataset on the impact of artificial intelligence on employment. It aims to explore the impact of AI adoption, job automation, job characteristics, and workforce skills on employment outcomes in the modern economy. It is widely used in tasks such as classification modeling, workforce analysis, automation impact research, and human resource decision support.
Online use:https://go.hyper.ai/38bZl
7. Global Climate & Energy Transition 2000 – 2026 Global Climate and Energy Dataset
The Global Climate & Energy Transition 2000 – 2026 dataset is a global climate and energy transition dataset for research on climate change, energy transition, and carbon emission reduction, aiming to systematically depict the global climate change and energy transition processes. This dataset records the global climate change and energy transition processes from 2000 to 2026, covering global and regional temperature anomalies.
Online use:https://go.hyper.ai/ogrSa
Selected Public Tutorials
1. PiD: 4K Super-Resolution Image Generation and Editing
PiD is a plug-and-play super-resolution decoder from the NVIDIA team. Traditional diffusion models use a VAE decoder to restore the latent representation to an image, with the output resolution limited to approximately 1024 pixels. PiD replaces the final step of VAE decoding with a pixel-space diffusion process, requiring only 4 steps of denoising to directly generate a clear 4K image without any post-processing techniques. It significantly breaks through the resolution bottleneck of traditional methods without changing the original model architecture.
Run online:https://go.hyper.ai/a34Cx
2. LTX-2.3-turbo Video Generator
LTX-2.3-turbo is an open-source video generation model released by Lightricks in March 2026, designed to push the limits of open-source video generation capabilities. This model employs an advanced diffusion transformer architecture and combines it with multimodal understanding capabilities to achieve high-quality, multi-resolution video content generation.
Run online: https://go.hyper.ai/oepch
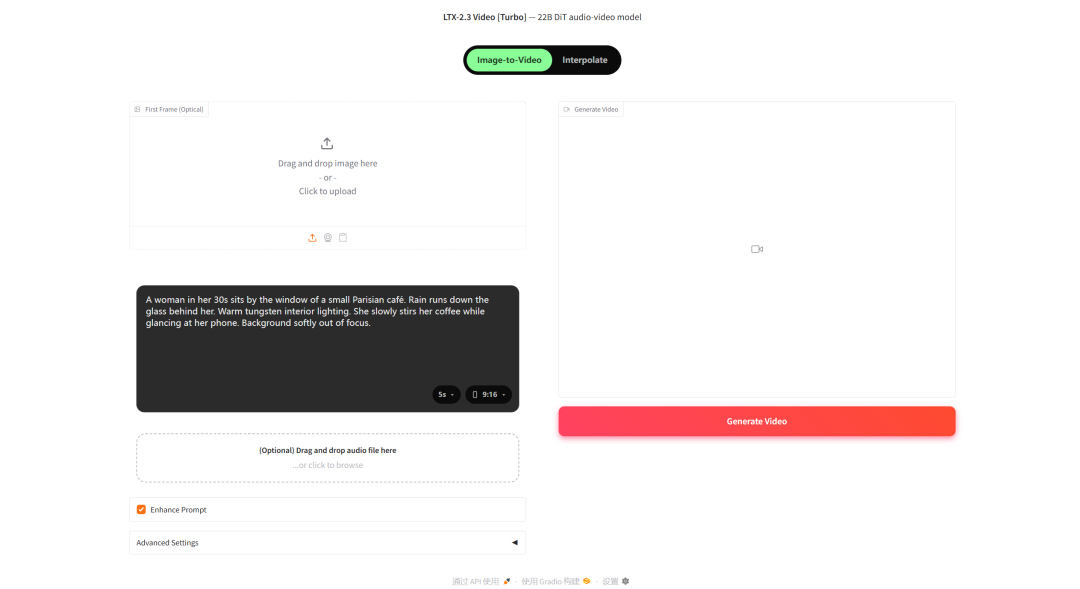
3. DiffBrush: Generating handwritten text lines
Nankai University and Kunlun Tech jointly released the DiffBrush handwritten text line generation model in August 2025, which was officially accepted by ICCV 2025 in October of the same year. Based on the Stable Diffusion VAE+UNet architecture, the model supports arbitrary English text input and 496 handwriting styles from the IAM dataset, outputting a 1024×64 grayscale image. Text content and handwriting style are independently controllable. Inference deployment is lightweight, and it can be directly used for OCR training set generation, handwritten data augmentation, and document simulation.
Run online: https://go.hyper.ai/qVvl5
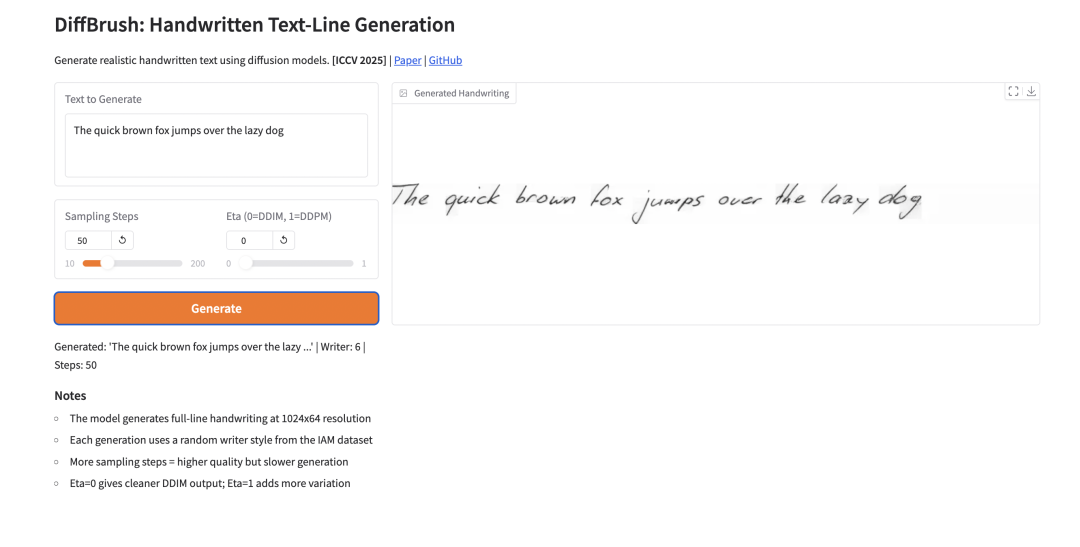
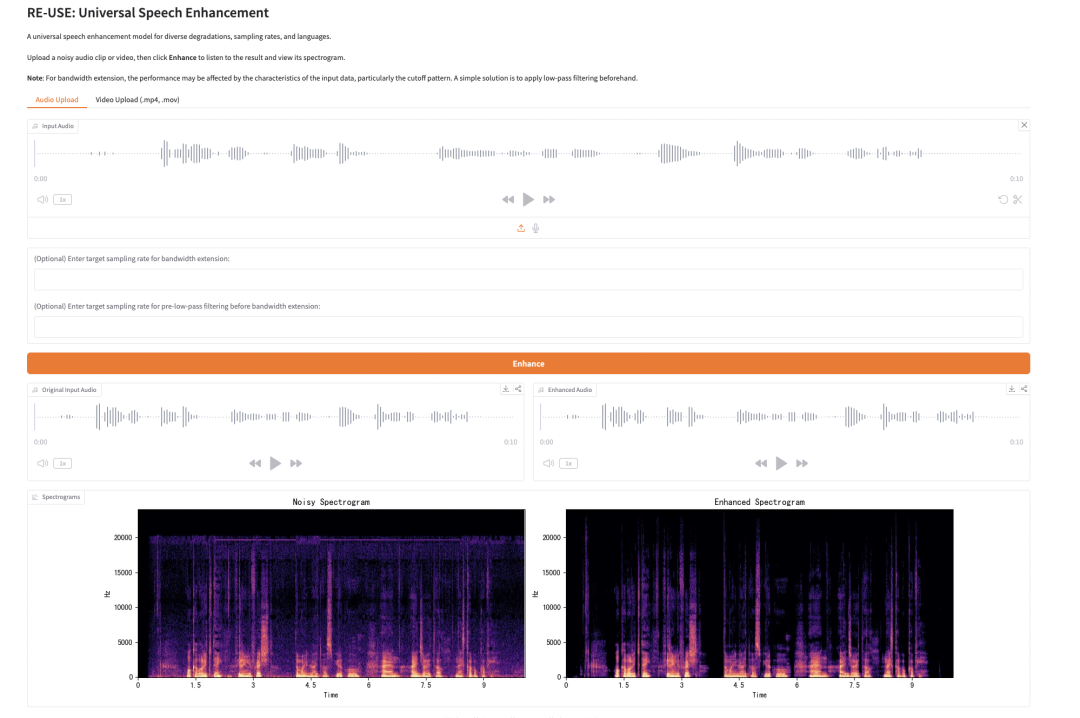
4. RE-USE: A general speech enhancement model
RE-USE is a general-purpose speech enhancement model released by NVIDIA in March 2026. Based on the Mamba architecture, it can handle noisy speech signals with various sampling rates and degradation types, and is language-independent.
Run online:https://go.hyper.ai/MJ0p5
5. TADA-1b: Unified Speech-Language Model
TADA-1b is a unified speech and language model released by the HumeAI team in February 2026, designed specifically for audio generation tasks such as speech synthesis, speech cloning, and multilingual dubbing. Based on Llama 3.2-1B, this model features lightweight, high-speed, and stable audio generation capabilities, suitable for English text-to-speech (TTS), zero-shot speech cloning, long narratives, and speech continuation.
Run online: https://go.hyper.ai/nCSpT
6. Gsplat 3D Gaussian Splash Training and Visualization
Gsplat is an open-source 3DGS CUDA-accelerated rasterization library jointly developed by Berkeley, NVIDIA, ShanghaiTech University, and other institutions. It is deeply optimized based on the original implementation, reducing training memory usage by 4 times and shortening training time by 151 TP3T. Its core technical highlights include: a high-efficiency CUDA differential rasterization engine, an adaptive Gaussian density control strategy, a flexible data backend compatible with mainstream data formats such as COLMAP, and a real-time web visualization interface based on Viser. Application scenarios cover digital twins, autonomous driving environmental perception, cultural relic digitization, and e-commerce visual synthesis.
Run online: https://go.hyper.ai/Zihdr

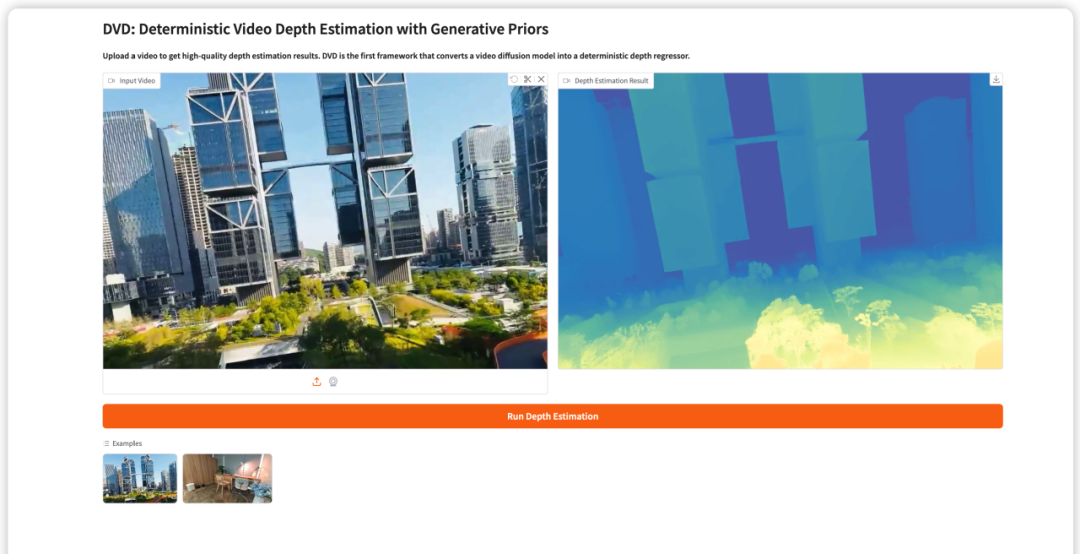
7. DVD: Deterministic Video Depth Estimation Based on Generative Priors
DVD (Deterministic Video Depth Estimation) is the first deterministic video depth estimation framework proposed by the Hong Kong University of Science and Technology (Guangzhou) team in March 2026. By transforming the pre-trained video diffusion model (Wan2.1) into a single forward propagation depth regressor, it completely eliminates the geometric illusion problem caused by randomness while maintaining the strong semantic prior of the generative model.
Run online:https://go.hyper.ai/AisLp
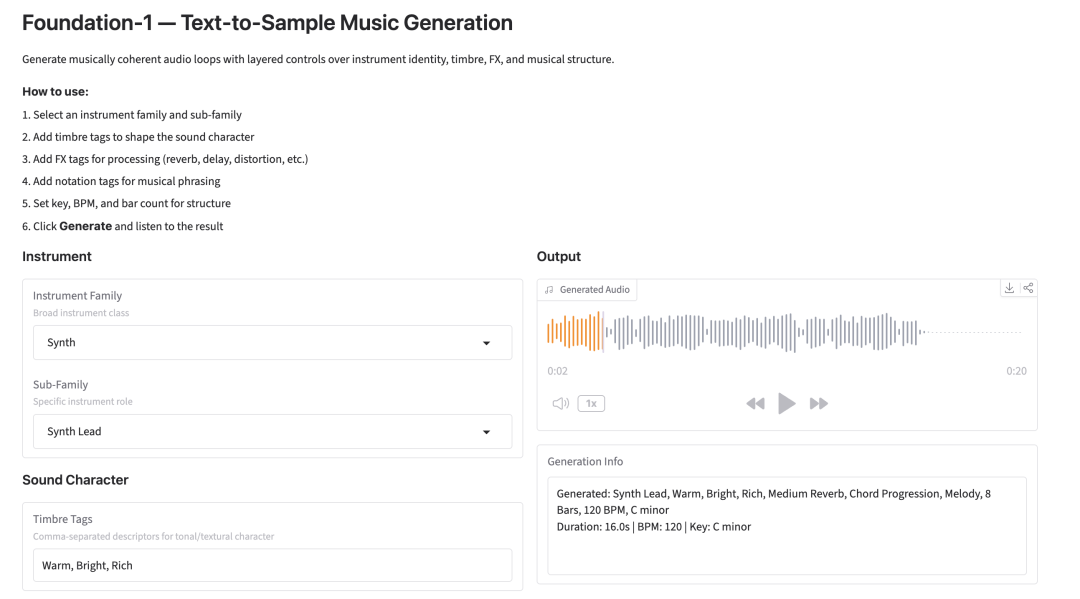
8. Foundation-1: Structured Text to Music Sample Generation
Foundation-1, released by the RoyalCities team in March 2026, is a text-to-sample audio generation model designed for professional music production workflows. The official version supports layered, controllable generation, allowing users to customize instrument families, subgenres, timbres, effects, theoretical chords, tempo/key signatures, and measure lengths to generate rhythmically synchronized, tonally locked music loops. Furthermore, the software provides a unified web demo offering complete interactive generation capabilities.
Run online: https://go.hyper.ai/NxUAC
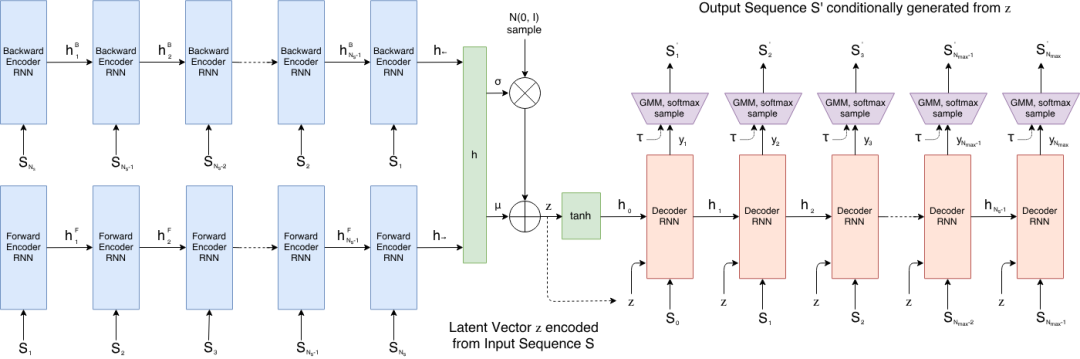
9. Sketch-RNN: Vector Sketch Generation and Latent Spatial Interpolation
Sketch-RNN is a vector sketch sequence generation model released by the Google Brain team in 2017. This method is specifically designed for hand-drawn sketch data, which includes stroke offsets and pen state information. It can learn successive latent representations of sketches and generate new vector sketch sequences. Sketch-RNN employs an encoder-decoder architecture. It maps the input sketch to a latent space and then uses a recurrent neural network decoder to progressively generate strokes.
Run online: https://go.hyper.ai/HmcT9
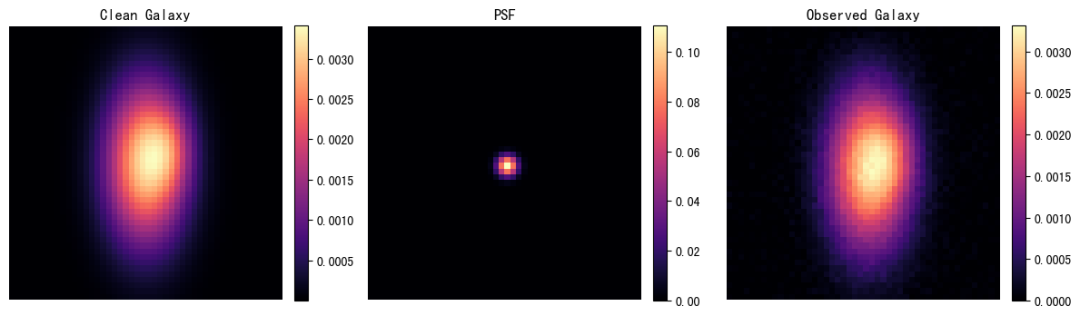
10. Galaxy-Deconv: A deconvolution framework for weakly gravitational lensing galaxy images
Galaxy-Deconv was developed by Tianyao Li of Tsinghua University and Emma Alexander of Northwestern University. The project focuses on the restoration of images of weakly gravitationally lensed galaxies. It uses the unfolded plug-and-play ADMM algorithm to deconvolve images of galaxies affected by point spread function (PSF) blur and noise. This tutorial organizes common galaxy deconvolution workflows into a notebook, covering image simulation, COSMOS data loading, deconvolution inference, HDF5 dataset checking, and basic deconvolution exercises.
Run online: https://go.hyper.ai/qGvI1
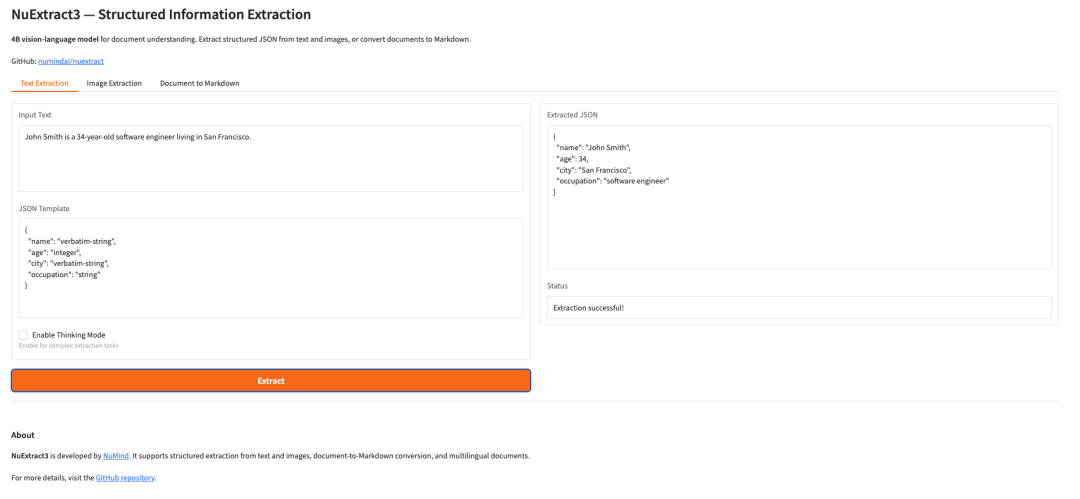
11. NuExtract3: A Multimodal Document Understanding and Structured Information Extraction Model
NuExtract3 is a 4B-parameter multimodal visual language model released by NuMind in June 2026, designed specifically for document understanding. The model integrates structured information extraction and document image-to-Markdown conversion capabilities, supports text, images, and mixed text-image input, and can directly output structured results based on user-provided JSON templates, fully preserving tables, formulas, and layout information.
Run online:https://go.hyper.ai/xirTj
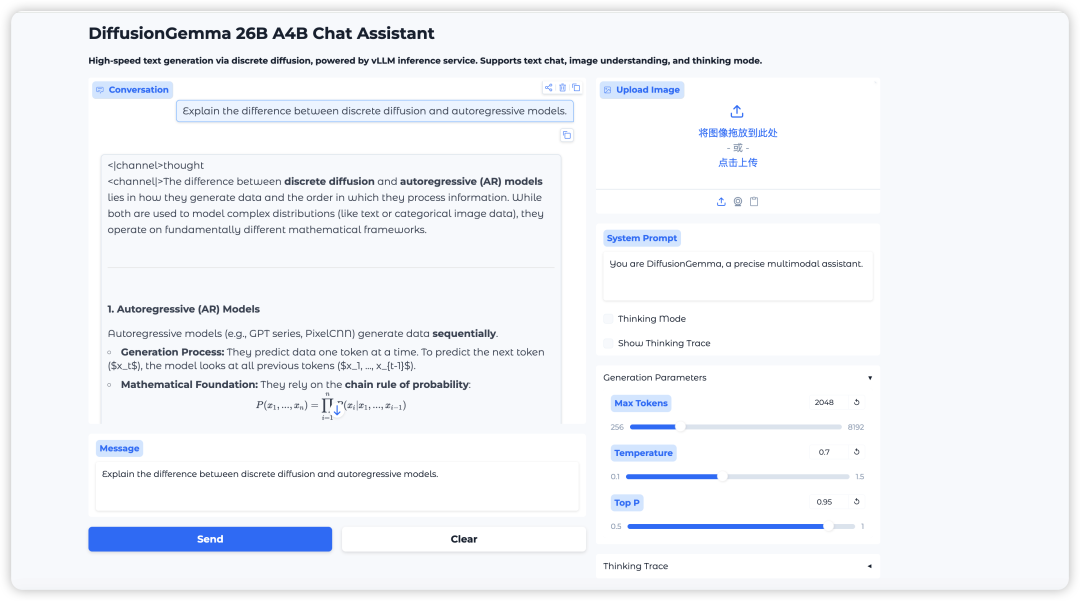
12. DiffusionGemma: A high-speed text generation model based on discrete diffusion
DiffusionGemma is a text generation model built by Google DeepMind using discrete diffusion techniques. It employs a mixture of experts (MoE) architecture with 26 billion parameters, totaling 25.2 billion parameters, of which only 3.8 billion are valid. Through parallel block-level diffusion sampling, it achieves ultra-fast text generation speeds, generating over 1100 tokens per second on a single H100 GPU.
Run online: https://go.hyper.ai/HV3eM
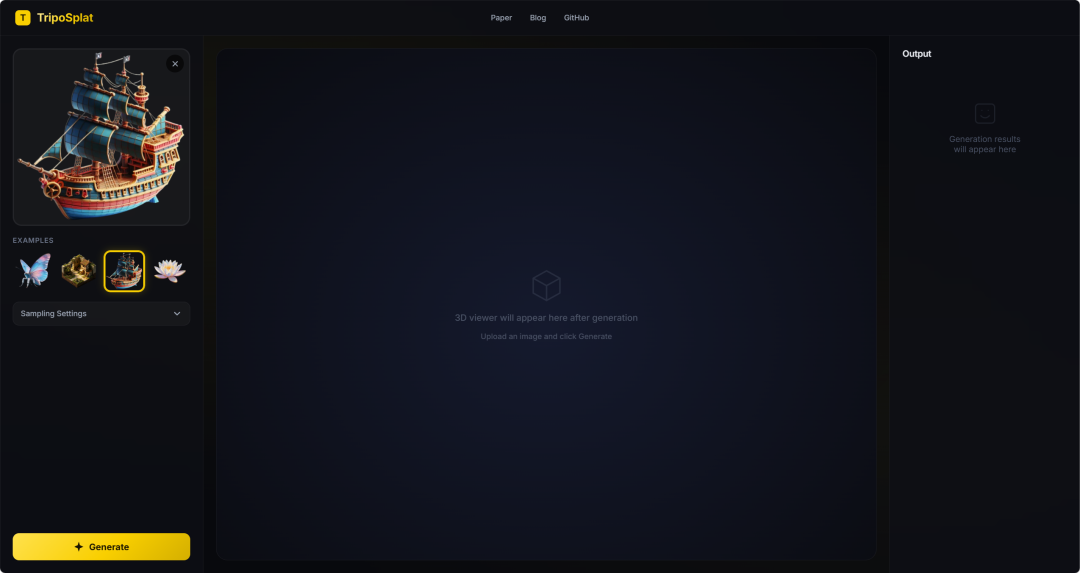
13. TripoSplat: Generate high-quality 3D Gaussian assets from a single image.
TripoSplat is a single-image to 3D Gaussian generation method jointly released by VAST-AI Research and TripoAI in May 2026. The model can convert a single 2D image into a high-quality 3D Gaussian model and allows control over the number of Gaussian distributions. The model employs density-sampled Gaussian (DeG) technology, adaptively distributing Gaussian centers according to the geometric complexity of the object, and uses VecSeq to deterministically reorder disordered latent variables, thereby improving the stability of the generation training.
Run online: https://go.hyper.ai/wOxUG
14. North Mini Code 1.0: An Agent Model for Code Generation and Software Engineering Tasks
North Mini Code 1.0 is an open-weighted code model released by Cohere and Cohere Labs in June 2026, optimized for code generation, endpoint tasks, and agent software engineering scenarios. The model supports long coding sessions, code reasoning, tool calls, and interleaved thinking, and excels in feature implementation, script writing, debugging, endpoint task planning, and multi-round software engineering workflows.
Run online: https://go.hyper.ai/ycCuG

Community article interpretation
1. MIT/IBM has released ChartNet, the largest synthetic chart dataset to date, generating 1.5 million diverse chart samples.
A group of experts from MIT, MIT-IBM Computing Research Lab, and IBM Research proposed ChartNet—a high-quality, multimodal dataset of millions of records for graph understanding, designed to advance graph understanding and reasoning capabilities.
View the full report:https://go.hyper.ai/Kk87Q
2. Google DeepMind's latest paper reveals the ultimate goal of AI: From AGI to ASI, there are 4 paths and 6 hurdles.
Google DeepMind, in collaboration with several top universities, has published a new paper exploring the profound questions surrounding the evolution from Artificial General Intelligence (AGI) to Artificial Superintelligence (ASI). This research views intelligence as a continuum, calmly dissecting the potential paths and bottlenecks that AI will face as it continues to evolve after surpassing the average human level. The paper provides a structured and objective reference for understanding the long-term trajectory of AI development.
View the full report:https://go.hyper.ai/AOObx
3. Leveraging Gemini 1.5's long contextual capabilities, Google's conversational healthcare system AMIE achieved the reasoning level of a general practitioner in 100 scenarios involving multiple patient visits.
A recent study by Google DeepMind and Google Research has further developed a novel LLM-based intelligent agent system based on their conversational healthcare system AMIE. This system enables clinical management and optimizes doctor-patient dialogue for multiple follow-up scenarios. AMIE leverages the long contextual capabilities of the Gemini model, combining contextual retrieval and structured reasoning to ensure its output aligns with the latest clinical practice guidelines and drug prescription catalogs.
View the full report:https://go.hyper.ai/65aHo
4. Materials AI is moving towards an "explainable era": A Japanese team cracks the black box of high-dimensional spectroscopy, pinpointing key features for new material discovery.
A research team from the Tokyo Institute of Science in Japan has proposed a deep learning model interpretation method capable of handling high-dimensional spectral data in materials science. The researchers constructed a first-principles calculation dataset containing the optical absorption spectra of 2681 oxides, chalcogenides, and related compounds. Compared to standard density functional calculations, after correcting for the spectral onset energy and shape, the calculated results show significantly improved agreement with reported experimental spectra.
View the full report:https://go.hyper.ai/VJbaU
Popular Encyclopedia Articles
1. Large Language Model (LLM)
2. Structure
3. World Action Model WAM
4. Rotational Position Encoding (RoPE)
5. Large-scale Multi-task Language Understanding (MMLU)
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provides domestic accelerated download nodes for 2100+ public datasets
* Includes 700+ classic and popular online tutorials
* Analyzing 300+ AI4Science Paper Cases
* Supports searching for 700+ related terms
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








