Command Palette
Search for a command to run...
A New Breakthrough in small-sample Biomedical Research: a German Team Has Achieved Data Augmentation Based on a Generative AI Model, Potentially Reducing the Number of Laboratory Animals Required by 30-50 Per TP3T.

The "effective therapeutic effects" verified in animal experiments often fail to be replicated in clinical trials, with insufficient sample size being one of the core reasons. Multiple constraints, including ethical regulations, experimental costs, and research conditions, further exacerbate the problem.Preclinical biomedical research often faces challenges in conducting large-scale animal experiments, which directly leads to insufficient statistical power.Researchers are unable to reliably extract real biological signals and are highly susceptible to false positive results, which seriously hinders the translation of basic research into clinical applications.
To address this challenge, academics have attempted to integrate research data using methods such as meta-analysis and data merging.However, these methods are highly dependent on the comparability of experimental designs, detection indicators, and operational procedures between different studies.Its practical application scope is extremely limited.
In recent years, generative artificial intelligence has provided a novel approach for small-sample research—by learning the inherent distribution structure of the original data, it generates synthetic data to expand the sample size. However, general generative models have significant shortcomings:If the original data contains random errors, the model will further amplify the noise and generate a large number of false positive results, which will reduce the credibility of the research conclusions.How to suppress error propagation while generating data has become a core bottleneck for the application of generative AI in the biomedical field.
To address this critical pain point, a joint research team from the University of Frankfurt and the Fraunhofer Institute for ITMP developed genESOM—Generative AI models based on emergent self-organizing maps are designed specifically for small-sample biomedical data.The core innovation of this model is the decoupling of structure learning from the data generation process. It blocks error propagation through dimensionality adjustment and introduces a negative control variable to monitor the quality of data generation in real time. The research team used preclinical lipidome data of multiple sclerosis as the research object, first artificially reducing the sample size to the statistical failure threshold, and then using genESOM to perform data augmentation.
The results confirm that this method can effectively recover key biological signals lost in small sample data while strictly controlling false positives, providing a reliable new approach for small-sample biomedical research. Furthermore, in exploratory research scenarios, this model is expected to reduce the number of experimental animals required by approximately 30%–50% while still maintaining the reproducibility and scientific validity of the results.
The related research findings, titled "Self-organizing neural network-based generative AI with embedded error inflation control enhances effective knowledge extraction from preclinical studies with reduced sample size," have been published in Pharmacological Research.
Research highlights:
* Built-in data-driven error control mechanism effectively suppresses false positive inflation, unlike unconstrained methods such as GAN.
* Successfully restored key lipid signals (such as lysophosphatidic acid) after sample size reduction, without increasing the false positive rate.
* It can reduce the amount of animal use by 30–50 %, serving as a supplementary analytical tool while taking into account both research robustness and the 3R ethical principles.

View the paper:
https://www.sciencedirect.com/science/article/pii/S1043661826000745
Datasets: From Full Experiments to Small Sample Statistical Failure
The data for this study comes from a publicly published preclinical animal study of multiple sclerosis.The study used SJL/J mice to establish a relapsing-remitting experimental autoimmune encephalomyelitis (EAE) model.The study aims to elucidate the mechanisms of neuroinflammation and to validate the therapeutic efficacy of the approved drug fingolimod.
Note: Fingolimod is a sphingosine-1-phosphate receptor modulator that can interfere with immune signaling pathways by regulating sphingolipid metabolism. It is a commonly used drug in the clinical treatment of multiple sclerosis.
The experiment included 26 eight-week-old female mice, which were randomly divided into three groups: blank control group, EAE model group, and EAE + fingolimod treatment group. The treatment group was administered the drug via drinking water at a dose of 0.5 mg/kg/d starting from day 18 of immunization induction.
The research team simultaneously collected behavioral and molecular-level data:Behavioral indicators cover motor ability, physical coordination, and social behavior; at the molecular level, LC-MS/MS targeted quantification technology was used to detect the concentration of 62 lipid mediators in four tissues: plasma, cerebellum, hippocampus, and prefrontal cortex, covering four major categories: lysophosphatidic acid, ceramides, sphingolipids, and endocannabinoids.Finally, a standard data matrix of "individual mouse × lipid characteristics" was constructed.
Before data analysis,The research team performed a logarithmic transformation on the lipid concentration data to make it conform to the distribution assumptions of the statistical analysis.For the missing values in the original data 5.3%, after multi-method alignment, the missing values were filled using the Random Forest algorithm (missForest). Subsequently, one-way ANOVA was conducted on 62 lipid indicators, and Šidák correction was used to control for multiple test errors. At the same time, three machine learning models—random forest, support vector machine, and k-nearest neighbors—were introduced to cross-validate the stability of biological signals in the data from two dimensions: the significance of inter-group differences and classification prediction ability.
After completing the basic analysis, the study conducted a core validation experiment: systematically reducing the sample size to pinpoint the critical value for statistical failure with small samples. The researchers progressively reduced the number of mice in each group, repeating the entire analysis procedure after each reduction. The results showed that when the sample size was reduced to 6 mice per group,The complete disappearance of all significant statistical results from the original data serves as a benchmark for evaluating the data augmentation capabilities of genESOM.—In small-sample scenarios where statistics are completely ineffective, verify whether AI can recover biological signals that have been buried by noise.
Generative AI designed specifically for small-sample biomedical data
Traditional generative models consistently face a dilemma when processing small sample data: the generated data is either lacking in information and unable to recover the original biological signals, or it is overloaded with noise, producing a large number of false positives. The core design of genESOM is to establish a rigorous balance mechanism between these two factors, achieving safe and interpretable small sample data augmentation.
genESOM is based on the Emergent Self-Organizing Map (ESOM) neural network and achieves two key upgrades compared to the classic Self-Organizing Map (SOM):Firstly,The neurons are arranged in a two-dimensional circular grid to preserve the neighborhood structure relationship of high-dimensional data to the greatest extent.Secondly,The addition of a third dimension, encoding the subgroup spacing and projection error, significantly improves the accuracy of identifying potential clustering structures.
After standardization and missing value removal, the data is projected onto the ESOM network for training. The model continuously matches the optimal neuron for each sample, dynamically adjusts the neuron weights, and gradually reduces the learning rate to ensure training stability. After training, the model outputs two core matrices: the U matrix characterizes the spacing between neurons and identifies cluster boundaries; the P matrix is used to statistically analyze local data density, providing a basis for generating synthetic data. The radius parameter, which controls the range of synthetic data generation, is automatically determined by fitting a distance distribution using a Gaussian mixture model, requiring no manual intervention.
The most groundbreaking design of genESOM is the complete separation of the structure learning and data generation processes.The model first independently learns the representation of the data's inherent structure, and then generates synthetic data based on the stable structure, thus avoiding the accumulation of errors from the two steps. More importantly, the model can introduce permutation variables as negative controls to monitor in real time whether the importance of features is abnormally amplified; once error accumulation is detected, data augmentation is immediately and automatically stopped, thus mitigating the risks of overfitting and false positives.
In this study, the research team used a 1:1 safe enhancement ratio (one synthetic sample generated from each original sample) to expand the sample size in each group from 6 to 12. After enhancement,A complete set of statistical and machine learning analyses is performed on the original data to quantitatively evaluate the signal recovery effect.Meanwhile, the study compared genESOM head-to-head with two mainstream generative methods: Gaussian Mixture Model (GMM) and Conditional Table Generative Adversarial Network (CT-GAN), using false positive rate, false negative rate, and original signal recovery rate as core indicators to verify the model's advantages.
It significantly outperforms traditional generation methods in small sample scenarios.
As shown in the figure below, analysis of the complete original dataset reveals significant inter-group differences in 27 of the 62 lipid variables, with the changes in lysophosphatidylcholine lipids being the most significant. This result is highly consistent with previous research findings on multiple sclerosis. Simultaneously, the random forest model classifies the samples with an accuracy far exceeding that of random probability, corroborating these two results.This confirms the presence of stable and reliable biological signals in the original data.
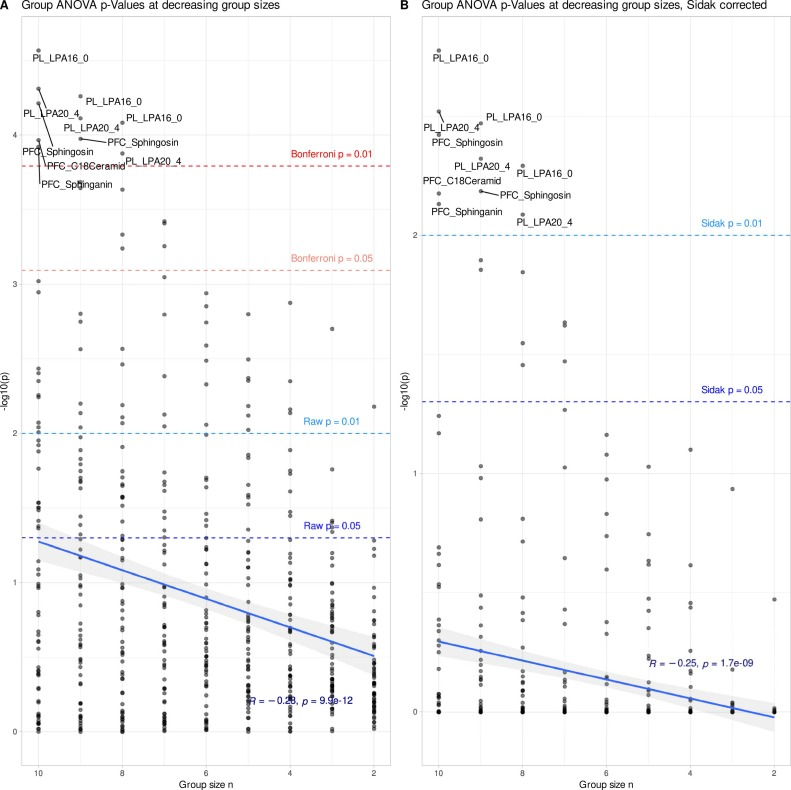
However, when the sample size in each group was reduced to 6 animals, as shown in the figure below, the data characteristics changed dramatically: after multiple validation corrections, the statistical significance of all lipid indicators completely disappeared, and the classification efficiency of the random forest also decreased significantly. It is important to emphasize that this does not mean the biological effects have truly disappeared.Instead, the small sample size leads to insufficient statistical detection power, and the true signal is drowned out by noise.
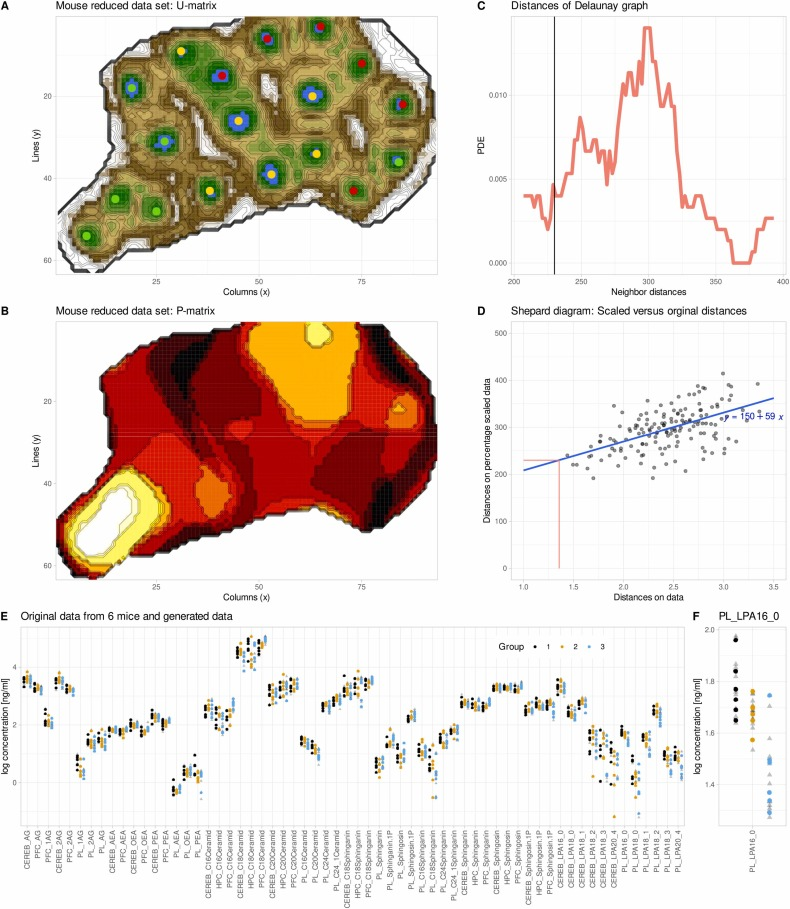
Subsequently, the research team used genESOM to augment the reduced data.After 20 rounds of training, the model was still able to identify some separation trends of the three groups of samples in the ESOM space.This confirms that even when statistical significance disappears, the data still retains potential biological structural information.
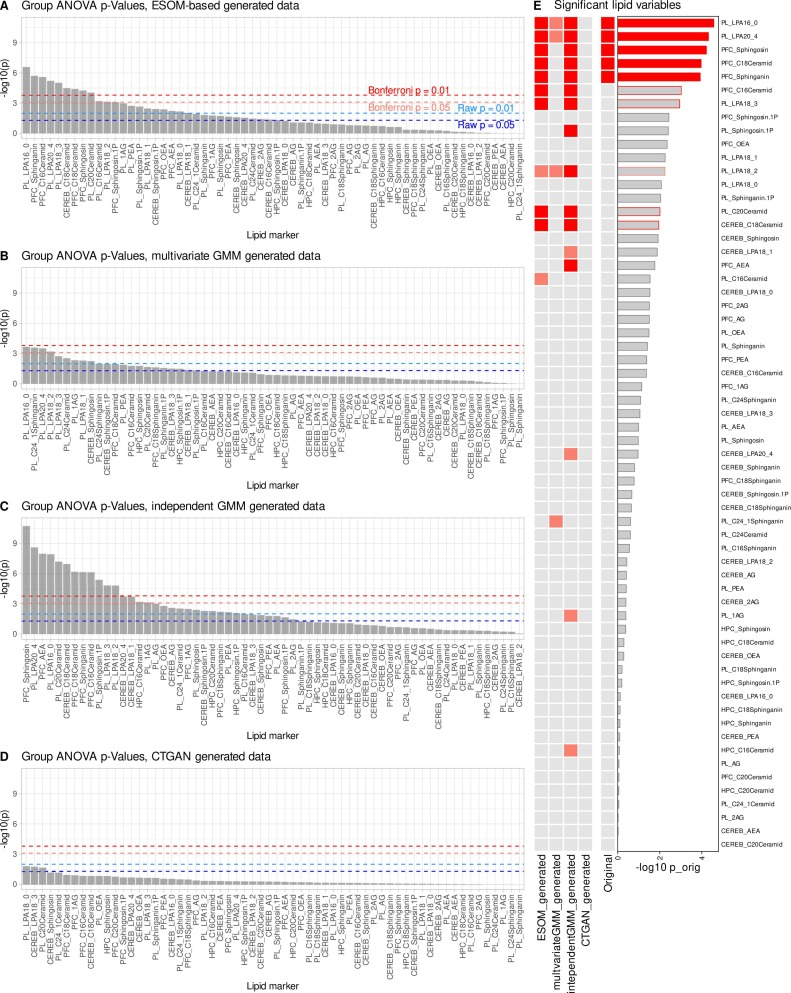
After data augmentation, key lipid indicators such as lysophosphatidic acid and sphingolipids in the prefrontal cortex in plasma showed significant intergroup differences again. These indicators had completely failed in small sample data, but were successfully restored through AI augmentation. At the same time, the model did not introduce a large number of unreasonable new features, and only a few additional indicators with close significance levels appeared.This indicates that genESOM does not create new signals out of thin air, but rather amplifies real biological signals that already exist but cannot be detected due to insufficient sample size.
Under the same small sample conditions, as shown in the figure below, the two control generation methods performed poorly: the multivariate Gaussian mixture model could only recover part of the original signal; the independent Gaussian mixture model, while recovering some significant indicators, was accompanied by obvious false positives; and the conditional table GAN could not effectively recover the core results, with a high false negative rate. Overall,genESOM demonstrates significantly better stability and reliability than traditional generation methods in small-sample scenarios.It can accurately recover key biological signals while strictly controlling error expansion and false discoveries.
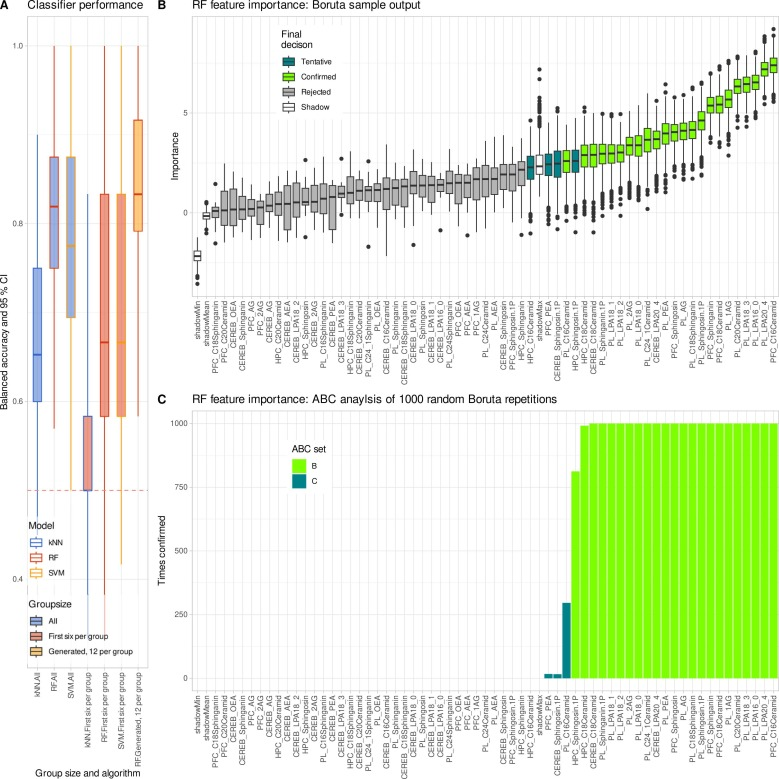
As shown in the figure below, machine learning analysis further validated this conclusion: the enhanced data restored the classification ability of the random forest, and the key features selected were highly consistent with the original study.
Final Thoughts
Small sample sizes have long been a challenge in biomedical research: high costs, ethical hurdles, and difficulty in obtaining samples lead to insufficient statistical power. Traditional data augmentation is limited by comparability, and general generative AI is prone to false positives with small samples. The breakthrough of genESOM lies in not "manufacturing" data, but rather steadily recovering existing biological signals from limited data.
Its core design separates structure learning from data generation, suppresses errors through dimensionality adjustment, and introduces a negative control for real-time monitoring, forming a restrained framework of "only enhancing what already exists, not creating what doesn't exist." It's important to be aware that enhancement cannot replace real experiments; this method is still in the exploratory stage, and its applicability requires further validation. However, this research sends an important signal: under strict control of errors and false positives, generative AI has the potential to become an effective auxiliary tool for small-sample studies, helping to more reliably uncover true conclusions from limited data.








