Command Palette
Search for a command to run...
Achieving 1.4-3.7x Inference Speedup, MIT Proposes DRiffusion to Overcome the Sampling Latency Bottleneck in Diffusion models.

In the field of generative AI, diffusion models, with their unique iterative denoising mechanism, effectively overcome the limitations of traditional models in terms of generation quality and diversity, and have been widely applied in various cutting-edge areas such as image processing, video processing, audio processing, and molecular design. However, this "time-for-quality" refining process typically requires dozens or even hundreds of iterations to output high-fidelity results.This results in extremely slow sampling speeds and high inference costs.This has become a core bottleneck for diffusion models to move towards real-time applications and large-scale deployment.
To address the challenge of slow sampling, researchers have proposed acceleration methods such as rectified flow and distillation: the former reduces invalid iterations by optimizing the denoising path, while the latter uses knowledge distillation to lightweight the model. However, when the number of sampling steps is drastically compressed in pursuit of a high speedup ratio,Both methods significantly sacrifice the quality of the output (such as loss of detail and blurring of textures), and distillation may even severely reduce the diversity of results.
While parallelization techniques offer a complementary approach without sacrificing quality, existing system-level methods are limited by model architectures (such as U-Net and Transformer), resulting in poor versatility. Mathematical methods, which model the diffusion process as differential equations and design efficient solvers, often suffer from poor compatibility with mainstream frameworks and are prone to deviating from the original sampling distribution. None of these solutions fundamentally overcome the inherent serial dependency of diffusion models—each denoising step depends on the output of the previous step.
To address this challenge, researchers at MIT recently tackled the fundamental problem and, through a concise mathematical discovery and innovative scheduling model, have for the first time demonstrated the untapped intrinsic parallelism within the diffusion framework. Based on this,Researchers have proposed the DRiffusion draft-and-refine diffusion model.By combining the advantages of system-level methods and mathematical methods, significant acceleration is achieved without sacrificing generation quality, providing a novel solution for balancing high fidelity and sampling efficiency in diffusion models.
The related research findings, titled "DRiffusion: Draft-and-Refine Process Parallelizes Diffusion Models with Ease," have been published as a preprint on arXiv.
Research highlights:
* Pioneering the DRiffusion "draft-refinement" parallel framework, revealing the inherent parallelism of diffusion models.
* Offers both aggressive and conservative acceleration modes, allowing for a flexible trade-off between quality and speed.
* Achieves a real-world speedup of 1.4 to 3.7 times in multi-model field tests, with near-lossless generation quality and comprehensive superiority over existing methods.

Paper address:
https://arxiv.org/abs/2603.25872
Follow our official WeChat account and reply "DRiffusion" in the background to get the full PDF.
MS-COCO dataset: contains 5,000 images and 25,000 descriptions.
The experiment used the MS-COCO 2017 validation set as the benchmark dataset, which contains 5,000 images.Each image is accompanied by 5 descriptive text lines. Following standard practice, only the first description line for each image is used for image-text alignment evaluation to ensure a one-to-one correspondence between the generated image and the reference text, thus guaranteeing the rigor of the evaluation.
Considering the insufficient sensitivity of traditional metrics to fine-grained visual preferences, this study further introduces PickScore and Human Preference Score v2.1 (HPSv2.1) as supplementary evaluations. For efficiency evaluation, up to four NVIDIA V100 GPUs were used, and the average sampling latency was measured through multiple steady-state runs. The relative speedup compared to the single-GPU diffusion model baseline is reported, along with the additional memory overhead introduced by the method.
To compare with the baseline, two representative diffusion model acceleration methods were selected: direct skipping (i.e., reducing the number of sampling steps) and AsyncDiff (parallelizing denoising by distributing subnetworks on different devices and performing asynchronous sampling). To ensure the consistency of the evaluation, the researchers reproduced the experimental results based on the official implementation of AsyncDiff under the same measurement settings.
DRiffusion: Easily Parallelize Diffusion Models Through a Draft-Refinement Process
DRiffusion's design is based on a fundamental question: Can a diffusion model simultaneously compute noise predictions for multiple time steps? In the original diffusion model, this goal is difficult to achieve directly because each denoising step depends on the output state of the previous step.Skip-step transitions offer a new perspective on overcoming this limitation:If the skip operation can be regarded as an independently callable local operator, then intermediate states can be directly constructed without stepping along the complete trajectory, thereby achieving parallel computation across time steps.
The concept of jump transitions is not new. As shown in the figure below, from a continuous-time perspective, system dynamics can be integrated over a longer time interval, and skipping intermediate steps is a natural operation. However, currently...Diffusion model frameworks typically utilize this degree of freedom only at the global level (e.g., by reselecting the time step sequence).There is a lack of a step-by-step mechanism that can be called locally and used on demand.

to this end,DRiffusion first converts the jump transition into an operator.Specifically, for mainstream diffusion models such as DDPM, DDIM, and solvers based on ordinary differential equations (ODE), a unified jump transition formula is derived, which enables direct connection between any two diffusion states without the need to re-define the global time step schedule.
Taking DDPM as an example, the jump transition from the current state x_t to the future state x_t-k has a closed-form solution; DDIM can also be generalized based on the consistency of the marginal distribution; and under ODE modeling, skipping intermediate steps is equivalent to directly using a larger numerical integration step size. The introduction of this operator significantly improves the flexibility of sampling pattern design and lays the foundation for subsequent parallelization.
Based on the jump transition operatorThe core workflow of DRiffusion can be summarized into two stages: draft generation and refinement.Given the state x_t at anchor time step t, the states for the subsequent k time steps are generated in parallel using jump transitions to obtain draft estimates. Due to the increased step size, the accuracy of these drafts is slightly lower than that of the successive iterations, but the overall results still maintain consistency with the original denoised trajectory.
Subsequently, these drafts are input into the noise predictor in parallel to obtain the corresponding noise estimates. Then, standard denoising updates are performed to refine each draft, and finally, the refined state and its corresponding noise are obtained, which serve as the anchor point for the next iteration.
This design faces a potential problem: a large jump step size may lead to a decrease in generation quality due to imperfections in noise prediction. Existing research has indeed pointed out this risk, but our experimental observations reveal two mitigating factors.First,A slight decrease in perceived quality does not equate to a significant reduction in representational ability; the generated images or latent vectors typically retain most of the underlying semantic and structural information.second,While the noise predictor is not perfectly accurate, its generalization ability is sufficient to map reasonable neighborhoods of samples to reasonable results. Based on these two points, DRiffusion can still output sufficiently high-quality images even when using a large stride.
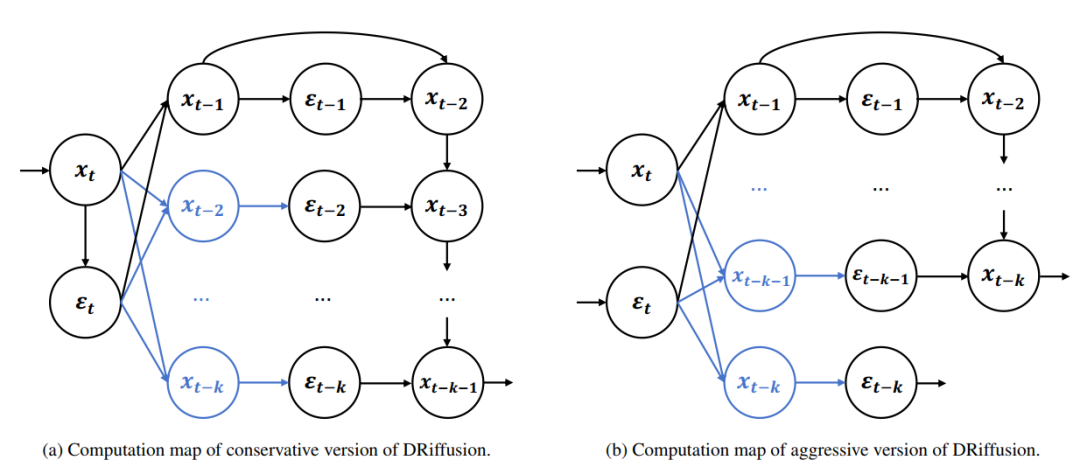
In terms of implementation, DRiffusion includes two versions: radical and conservative.
As shown in the figure below, the radical version fully parallelizes multiple noise predictions in one iteration. Under the condition of ignoring minor overhead such as communication, the ideal speedup can reach k times, that is, the running time is reduced to 1/k of the original.
The conservative version first independently calculates a high-precision current noise (generated from the refined state), and then uses this as a basis to reproduce the process of the aggressive version, advancing an additional time step, achieving an ideal speedup of 2k+1 times. The core idea of both versions is the same: trading a draft for parallel computing power, and refining to ensure output quality.
Achieved nearly 3x real-world speedup on 3 GPUs.
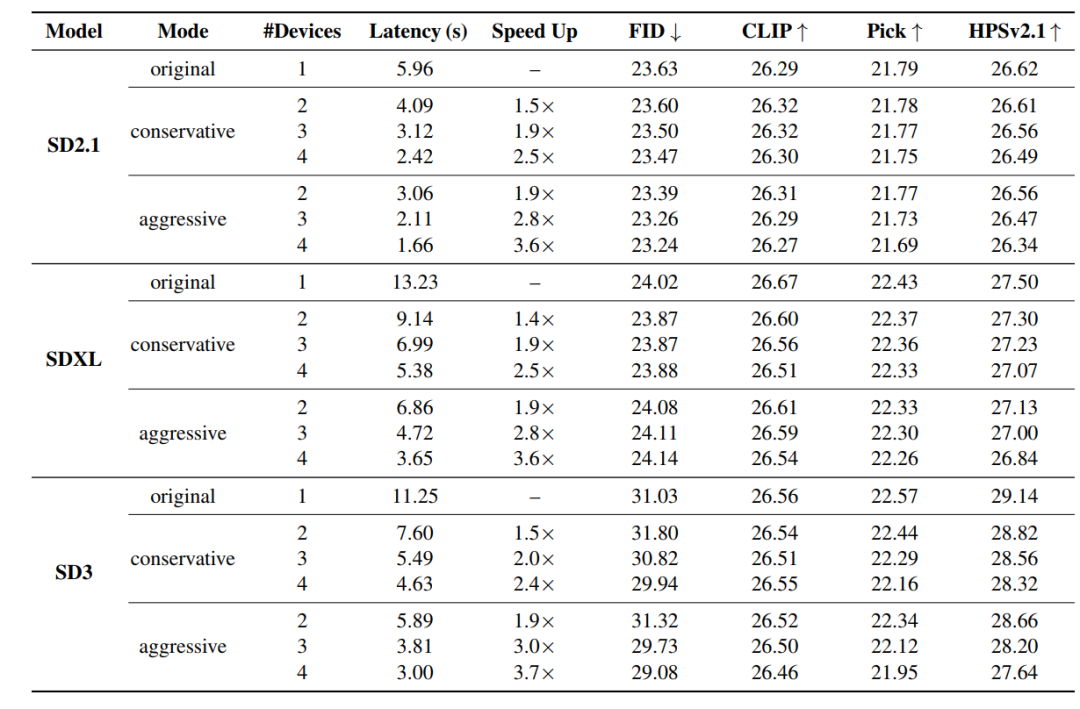
To verify the performance of DRiffusion, experiments covered diffusion models of various architectures and scales, including Stable Diffusion 2.1 (SD2.1) based on U-Net, Stable Diffusion XL (SDXL) based on U-Net, and Stable Diffusion 3 (SD3) based on Transformer for flow matching. This multi-model coverage not only facilitates fair comparisons with existing methods but also fully tests the generality of the method.
The qualitative results are shown in the figure below. Under high acceleration ratios,While DRiffusion struggles to fully reproduce the pixel-by-pixel output of the baseline, it consistently maintains semantic consistency and effectively preserves fine-grained details (such as wood texture and highlights on a cat's chest).By moderately skipping some noise sampling steps, the accelerated version can sometimes generate images with stronger contrast and sharper details (such as cat eye reflections). Aggressive acceleration (close to 4x) may result in slight quality loss, such as color oversaturation or minor artifacts, but overall it still maintains high consistency with the baseline.

The quantitative results are shown in the table below.Under all configurations, the FID value is very close to the baseline, and the maximum decrease in CLIP score does not exceed 0.16.In some scenarios, FID improved slightly, mainly due to statistical variance rather than methodological improvements. Supplementary PickScore and HPSv2.1 evaluations show average decreases of 0.17 and 0.43, respectively. The only exception is SD3 in aggressive 4-device mode, where HPSv2.1 decreased by 1.50. This is because SD3's default sampling step count is only 28 steps, and the extreme step size amplifies the approximation error. Considering the stability of the four metrics and the significant speedup gains, this quality degradation is acceptable.
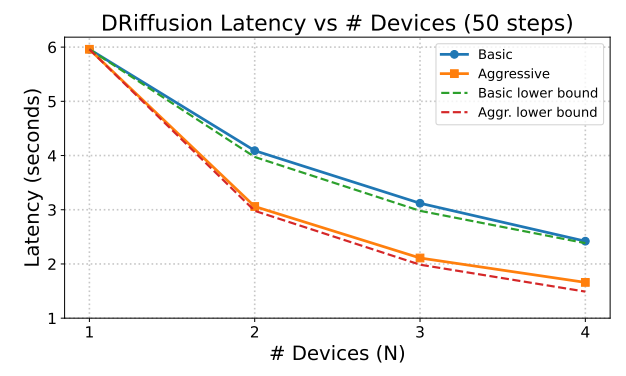
In terms of acceleration performance,The actual speedup is between 1.4 and 3.7 times, and the total computational cost per sample is almost the same as the original model.Experimental data show that the delay scaling of the aggressive mode is close to the theoretical lower bound O(1/N), while the conservative mode is highly consistent with O(2/(N+1)), proving that DRiffusion achieves efficient and scalable parallelization.
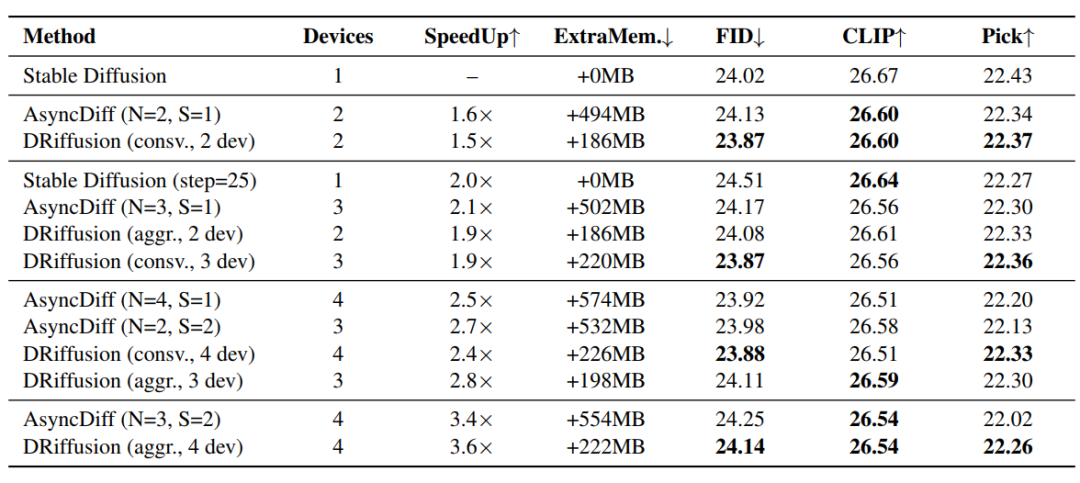
The results of the method comparison are shown in the table below.In all speedup groups, DRiffusion outperformed AsyncDiff and simple skip baseline in terms of generation quality.Using PickScore, which is more sensitive to acceleration, as the core metric, DRiffusion reduced the performance degradation gap by an average of 48.61 TP3T, with a maximum reduction of 58.51 TP3T for 4 devices. The acceleration effect is nearly linearly related to the number of devices, and the acceleration ratio is on par with or slightly better than AsyncDiff for a similar number of devices.
The memory efficiency advantage is more pronounced: AsyncDiff requires up to 574MB of additional memory, increasing with the number of devices, while DRiffusion only introduces a stable overhead of 186-226MB. Compared to the SDXL baseline memory requirement of approximately 13GB, this overhead is negligible. At a batch size of 5, AsyncDiff experienced a memory shortage anomaly on a 32GB node, while DRiffusion functioned normally.The reason is that DRiffusion only modifies the sampling iteration process, decoupling it from the model structure and core computation.
In summary,DRiffusion achieves nearly 3x speedup on 3 GPUs while maintaining generation quality and fine-grained detail, significantly improving inference speed.By combining concise theoretical features with practical parallel implementation, high-quality and stable experimental results were achieved.
Parallelization of diffusion models accelerates the process
Parallelization of diffusion models has become a core research hotspot pursued by both academia and industry worldwide. In academia, many leading institutions have made breakthroughs in this direction. The Fast-dLLM proposed jointly by MIT and the University of Hong Kong achieves a 27.6x end-to-end speedup for large-scale diffusion language models (long text generation tasks) without retraining the model, while keeping the accuracy loss within 2%.
Paper Title: FAST-DLLM V2: Efficient Block-Diffusion LLM
Paper link:https://arxiv.org/pdf/2509.26328
The StreamDiffusionV2 streaming system developed by UC Berkeley integrates a SLO-aware batch scheduler and a motion-aware noise controller for video diffusion models, increasing the video generation frame rate to 58 FPS in a multi-GPU environment, breaking through the computing power bottleneck of real-time generation.
Paper Title: StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Paper link:https://arxiv.org/abs/2511.07399
In the enterprise sector, NVIDIA has deeply integrated parallelization technology into its hardware and software ecosystem. By optimizing computational paths and multi-device collaboration, it significantly improves the inference speed of diffusion models and reduces the computational costs in image and video generation scenarios. Stability AI, on the other hand, explores parallel sampling strategies in its Stable Diffusion series of models. By optimizing batch processing parameters and enabling samplers that support parallel processing, such as DDIM and PLMS, it improves image generation efficiency by 3-5 times while maintaining generation quality.
In summary, the combined efforts of academia and industry have made the parallelization of diffusion models a hot topic for technological breakthroughs. DRiffusion, as a typical solution, has verified the feasibility and efficiency of exploiting inherent parallelism. In the future, with deep collaboration between hardware and algorithms, diffusion models are expected to achieve a truly real-time generation experience while maintaining high fidelity, clearing efficiency barriers for the wider application of AI.
Reference Links:
1.https://mp.weixin.qq.com/s/70OiIuuNP2PWgIV_hiRZBQ








