Command Palette
Search for a command to run...
1.1 T arXiv Dataset: 1.7 Million Papers, You Can See Your Next Life
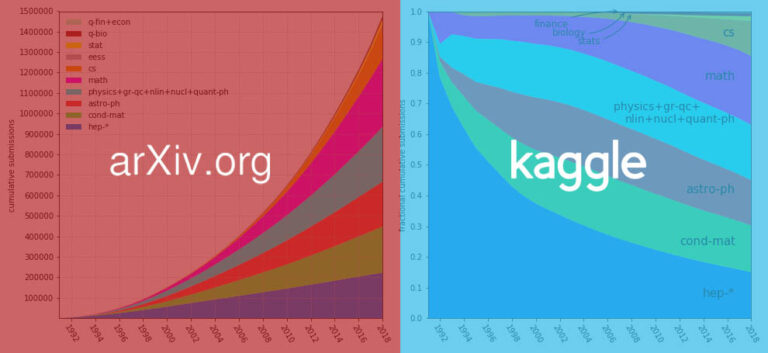
Recently, arXiv packaged more than 1.7 million papers into a dataset and put it on the Kaggle platform, making it more convenient to access and download papers in the future. The dataset is currently about 1.1 TB in size and will continue to grow with weekly updates.
1.7 million+ academic papers, 1.1 TB in size, this is a set of data sets recently opened by arXix on Kaggle. When netizens inquired about it, they exclaimed: So cool!
The dataset compilation team said that they hope to inspire related researchers to explore richer machine learning technologies and come up with more discoveries and innovations.
Open datasets make paper searches easier
For nearly 30 years, arXiv has provided the public and research communities with open access to scholarly articles covering a wide range of fields.From the vast branches of physics, to the many branches of computer science, to all disciplines such as mathematics, statistics, electrical engineering, quantitative biology, and economics.
There are a lot of research papers on arXiv, and although many people benefit from them,However, it is often reported that it has shortcomings such as inconvenient browsing, searching and sorting.Some people even found some tips on searching for papers on arXiv and shared them with you.
So, to make arXiv more accessible, Cornell University now offers a free, open arXiv dataset on Kaggle.
The dataset contains 1.7 million academic papers, as well as paper-related elements (features), such as article title, author, category, abstract, and full-text PDF.
Eleonora Presani, Executive Director of arXiv, said: "Having the entire arXiv corpus on Kaggle greatly increases the potential of arXiv papers. By providing the dataset on Kaggle, we are no longer just letting people learn knowledge by reading these articles,More importantly, the data and information behind arXiv should be made available to the public in a machine-readable format.”

Presani added: “arXiv is more than just a repository of papers; it is a platform for knowledge sharing. This requires us to innovate in the way we present and interpret available knowledge. Kaggle users can help push the limits of this innovation, and it becomes a new channel for us to collaborate with the community.”
Watch: What does the arXiv dataset include?
The basic information of the arXiv dataset is as follows:
arXiv Dataset
Published by: Paul Ginsparg, Moonshot Factory, Jack Hidary
Quantity included:1.7 million+ academic papers
Data format:json
Data size:1.1 TB
Release time:August 2020
Download address:https://www.kaggle.com/Cornell-University/arxiv
Currently, the arXiv dataset provides a metadata file in json format, which contains the relevant entries for each paper, as follows:
- id: paper access address, which can be used to access the paper;
- submitter: paper submitter;
- authors: authors of the paper;
- title: paper title;
- comments: other information such as the number of pages and figures in the paper;
- journal-ref: information about the journal where the paper was published;
- doi: digital object identifier;
- abstract: Abstract of the paper;
- categories: the categories or tags to which the paper belongs in arXiv;
- versions: paper versions.
You can easily browse, filter and check these vast papers.
Additionally, users can access each paper directly on arXiv via the following two links:
- https://arxiv.org/abs/{id}: the paper page, including the abstract and other links;
- https://arxiv.org/pdf/{id}: Paper PDF download page.
Bulk access is also available: users can get the full PDF file for free on the bucket gs://arxiv-dataset on Google Cloud Storage, or through the Google API (json documentation and xml documentation).
The paper PDF files are grouped into several .tar.gz files in the tarpdfs folder, and the entire dataset is about 1.1TB in size. The details are as follows (the following are the 1st, 2nd, and 3rd fields of January 2010 (1001)):
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz)
Users can also download data to their local machine using tools such as gsutil.

However, what are the specific usage scenarios of this dataset? Many netizens have already had ideas, such as topic modeling and using this data to train GPT-3.
arXiv: A huge repository of academic papers
Students in the scientific research and academic circles must be familiar with arXiv.
It is a website that collects preprints of papers in physics, mathematics, computer science and biology. It not only provides a platform for scientific researchers to "reserve ideas", but also serves as a huge resource library for everyone to search and read papers.
As of October 2008, arXiv.org had collected more than 500,000 preprints; by the end of 2014, its collection reached 1 million;As of October 2016, arXiv submissions exceed 10,000 per month.
arXiv was first established by physicist Paul Ginsbag in 1991. Its original intention was to collect preprints of physics papers, and later expanded to other fields such as astronomy and mathematics.
arXiv was originally hosted at Los Alamos National Laboratory (LANL), so it was called the "LANL Preprint Database" in its early days. Currently, arXiv is hosted at Cornell University and has mirror sites around the world. The website was renamed arXiv.org in 1999.
Now, in layman's terms, arXiv is a website used for "reserving a spot". In order to prevent their ideas from being plagiarized by others before the paper is included, researchers will publish their drafts on arXiv to prove their originality.
References:
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
-- over--








