Command Palette
Search for a command to run...
NeurIPS 2025 | MIT Proposes AutoSciDACT, an Automated Scientific Discovery Tool That Is Highly Sensitive to Anomalous Data in Astronomy, Physics, and biomedicine.

Throughout history, scientific discoveries have often involved an element of chance. For example, penicillin was accidentally discovered in a moldy petri dish, and the cosmic microwave background radiation originated from "abnormal noise" captured by an antenna. These unintentional observations have ultimately become key driving forces for the progress of human civilization. Today, in the "data-intensive" research environment, massive amounts of interdisciplinary data contain even more peculiar and inexplicable observations, theoretically multiplying the chances of accidental scientific discoveries. However, paradoxically, accurately capturing "new discoveries" from complex and massive amounts of research data is far more difficult than finding a needle in a haystack.
Traditional scientific discovery methods rely heavily on scientists' intuition and expertise, requiring a complex process of observation, research, hypothesis, experimentation, and verification to determine the true scientific value of a "new discovery." However, with the exponential growth and increasing complexity of scientific data, identifying "new discoveries" solely through keen observation is now virtually impossible. While automated scientific inquiry methods based on artificial intelligence and large language models have recently shown promise,However, due to the lack of an integrated framework capable of rigorous and automated hypothesis testing and verification,Even with such methods, it is still inevitable that "the will is willing but the ability is insufficient".
To address the challenges of scientific discovery, a team from MIT, UW-Madison, and the National Science Foundation's Institute for Artificial Intelligence and Fundamental Interactions (IAIFI) has proposed a method called AutoSciDACT (Automated Scientific Discovery with Anomalous Contrastive Testing).It can be used to automate the detection of "new discoveries" in scientific data, thereby simplifying scientific inquiry.Researchers validated the method on real datasets in astronomy, physics, biomedicine, and imaging, as well as on a synthetic dataset, demonstrating that the method is highly sensitive to small amounts of injected anomalous data across all domains.
The related research findings, titled "AutoSciDACT: Automated Scientific Discovery through Contrastive Embedding and Hypothesis Testing," were published in NeurIPS 2025.
Research highlights:
* AutoSciDACT is an end-to-end general framework for detecting the novelty of scientific data, with cross-domain transferability;
* A systematic process was designed by integrating scientific simulation data, manually labeled data, and expert knowledge into a comparative dimensionality reduction workflow;
* A statistically rigorous framework was constructed to quantify the significance of observed anomalies and to determine from a statistical perspective whether anomalies have scientific significance.
* The results were validated with real data in four significantly different scientific fields, demonstrating significant effectiveness, persuasiveness, and promotional value.

Paper address:
https://openreview.net/forum?id=vKyiv67VWa
Follow the official account and reply to " AutoSciDACT Get the full PDF
More AI frontier papers:
https://hyper.ai/papers
Datasets: Diverse, cross-disciplinary datasets validate AutoSciDACT's superior performance
To rigorously verify the superior performance of AutoSciDACT,Researchers tested it on five datasets from completely different domains.These datasets include data from four distinct fields: astronomy, physics, biomedicine, and imaging, as well as a synthetically constructed dataset.
Regarding astronomical datasets,The team selected gravitational wave data recorded by the Laser Interferometer Gravitational-Wave Observatory (LIGO) in Hanford, Washington, and Livingston, Louisiana, as the astronomical benchmark, spanning the third observation run from April 2019 to March 2020. This data consists of 50-millisecond time-series signals from two channels (one channel per interferometer), sampled at a frequency of 4096 Hz (200 measurements per channel). Different categories of data were included, such as "pure noise," "instrument interference," "known astrophysical signals," and a hidden type of signal called "white noise burst (WNB)" (as an anomaly). WNB signals were excluded during pre-training and subsequently injected into the data to test whether the model could identify this unseen signal from the gravitational wave signals.
Physics datasetsThe team chose the JETCLASS dataset as the particle physics benchmark, a large dataset containing simulated "jet" from proton-proton collisions at the Large Hadron Collider (LHC). The study used a subset of this dataset, which included jets from quantum chromodynamics (QCD) processes (quark/gluon), top quark decay (t → bqq′), and W/Z vector boson decay (V → qq′). Signal jets from enhanced Higgs boson decay to bottom quark (H → bb¯) were also retained. The team used the Particle Transformer (ParT) as the contrastive encoder, a variant of the Transformer architecture suitable for particle physics.
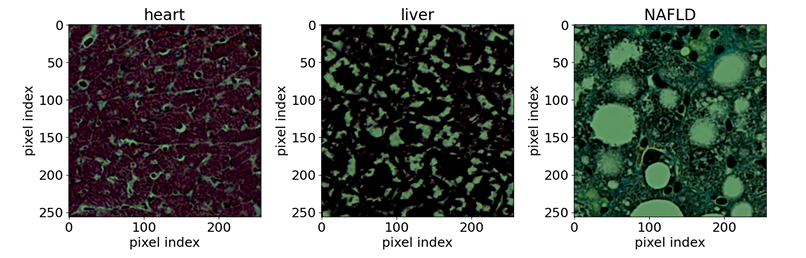
In the field of biomedicine,The team used publicly available optical microscope images of stained tissue samples. Reference samples included seven types of mouse tissue (brain, heart, kidney, liver, lung, pancreas, and spleen) and one type of normal rat liver tissue. The research objective was to detect abnormal mouse liver tissue caused by non-alcoholic fatty liver disease (NAFLD). Input samples were 256 x 256 pixel resolution tissue sections extracted from whole-section images, stained using Masson's trichrome staining. The backbone network used was EfficientNet-B0.
In terms of image science,The team used the CIFAR-10 image dataset (50,000 images in total), randomly selecting the first class as the anomaly class, and pre-training on the remaining nine classes. During the discovery phase, the team supplemented the CIFAR-10 test set with 100,000 images from CIFAR-5m, increasing the number of data points available for hypothesis testing. The encoder backbone used a ResNet-50 with pre-trained weights, replacing only the final fully connected layer with a slightly larger MLP, and fine-tuning it on the CIFAR contrastive embedding task.
Regarding synthetic datasets,Its main purpose is to demonstrate the core capabilities of AutoSciDACT and verify that it is unaffected by specific details of real scientific datasets. The synthetic dataset consists of X⊂R^D+M, containing D meaningful dimensions and M noisy dimensions. The noisy dimensions are generated uniformly from 0 to 1, while the meaningful dimensions are composed of N Gaussian clusters with a uniform 0-1 mean and randomly generated covariances (uniformly distributed 0, 0.5). Then, all dimensions are randomly rotated to hide the original effective discriminative variables. Training is performed using a contrastive embedding method, using only N-1 clusters as training data and reserving one cluster as the "signal" to be detected. The basic model used for training is a simple multilayer perceptron (MLP).
In addition, supplementary validation involved other datasets, such as the genome dataset for identifying butterfly hybrids and real data on the decay of tetraleptons in the LHC Higgs boson, to further verify the model's cross-domain generalization ability. In summary, these different datasets were all constructed using "background data" + "abnormal signal data," and were used for model pre-training and detecting whether the model could detect novelty, respectively. The validation results all demonstrate the effectiveness of AutoSciDACT as a general process for detecting novelty in scientific data, as well as its cross-domain generalization ability.
Model Architecture: A Two-Stage Process of "Pre-training" + "Discovery" Creates New Methods for Scientific Discovery
The core of AutoSciDACT is through two steps: "pre-training" and "discovery".By combining low-dimensional feature embedding with statistical tests, we can extract statistically significant "novel signals" from high-dimensional scientific data.
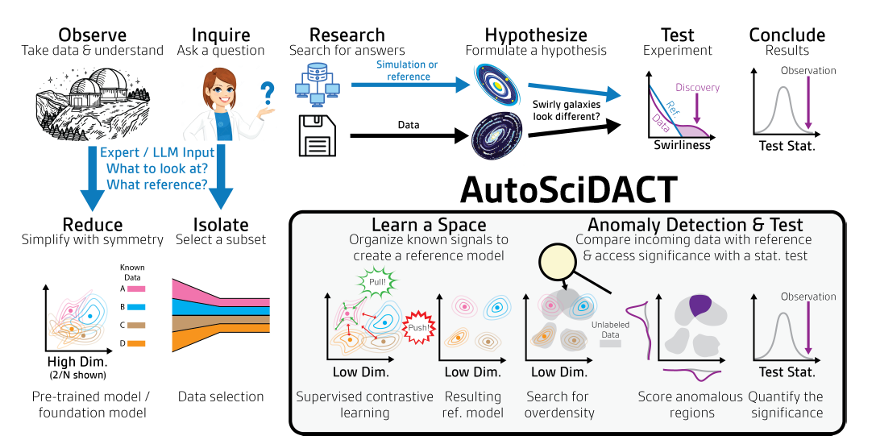
Specifically, the pre-training stage addresses the problem of high-dimensional data redundancy. It mainly compresses the hundreds or thousands of dimensions of input features that may be contained in the original scientific data into low-dimensional vectors, while retaining the key semantic features of the data—that is, the core information in a scientific sense—laying the foundation for subsequent analysis.
In terms of implementation, the backbone of the pre-trained pipeline is an encoder fθ : X → Rᵈ trained through contrastive learning, which maps the raw data from the high-dimensional input space X to a low-dimensional representation in Rᵈ. The contrastive objective is designed to maximize the alignment between similar inputs (positive pairs) while separating dissimilar inputs (negative pairs) in the learning space. The underlying framework uses SimCLR, which trains the encoder fθ and the projection head gϕ.After training, only the encoder fθ is retained for outputting the final low-dimensional embedding.In practice, supervised contrastive learning (SupCon) is employed. It utilizes labeled training data to create positive pairs from the same class and negative pairs from different classes, with the loss function being the SupCon loss. Data augmentation strategies can be designed incorporating domain knowledge to supplement the positive pair construction. Furthermore, supervised cross-entropy loss (LCE) can be optionally added, resulting in a total loss of L = LSupCon + λCELCE (where λCE ranges from 0.1 to 0.5 to ensure the classification objective does not dominate).
The discovery phase utilizes the low-dimensional embeddings obtained in the previous step within the NPLM (New Physics Learning Machine) framework for anomaly detection and hypothesis testing.Search for potential "novel signals" in the data and quantify their significance through statistical tests.
In this phase, researchers use embedding vectors fθ to process unseen datasets and search for anomalous clusters, density distortions, or outliers deviating from the background distribution in low-dimensional space. The search process employs a classic scientific hypothesis testing approach, comparing a reference dataset R composed of a known background with an observed dataset D of unknown composition, attempting to accept or reject the null hypothesis that R and D have the same distribution. The hypothesis is tested using the NPLM algorithm (based on the classic likelihood ratio test proposed by Neyman et al.).When combined with expressive learned embedding vectors, this model becomes highly sensitive to novel signals.
It is worth noting that dimensionality reduction during pre-training is crucial because the effectiveness of any statistical testing method, including NPLM, decreases significantly as the data dimensionality increases. In other words, higher dimensionality requires a larger sample size to detect statistically significant small signals, but in practical scientific research, the sample size often falls short of such high-dimensional requirements. Therefore, only by compressing high-dimensional data can tools like NPLM function effectively, enabling the discovery of statistically significant anomalies and thus enhancing their scientific value.
Experimental Results: Multi-dimensional and broad-domain comparisons highlight AutoSciDACT's transferability and cross-domain capabilities
The researchers trained and evaluated AutoSciDACT on each dataset using the same method, making only minor adjustments during the pre-training phase to suit the specific needs of each dataset.
All encoders have an embedding dimension of d=4. The embedding results are visualized as shown in the figure below.In addition, the experiment set up three types of comparison benchmarks, including supervised benchmark, ideal supervised benchmark, and Mahalanobis Baseline.
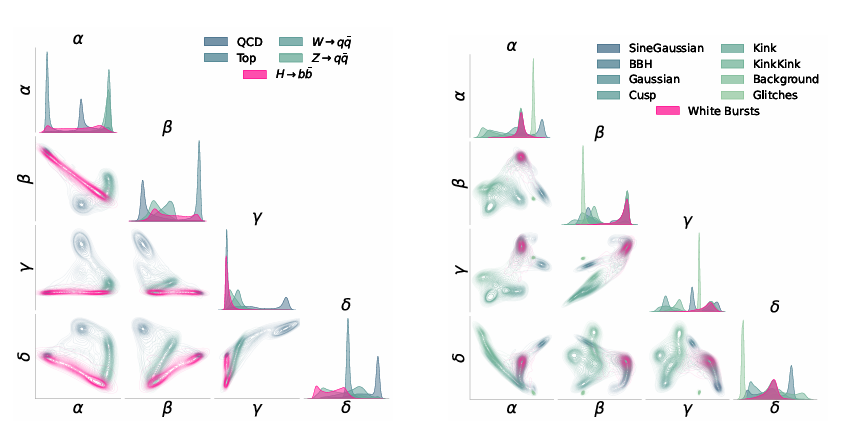
As shown in the figure below, the results demonstrate that NPLM can detect highly statistically significant biases (Z≳3 or p≲10⁻³) with signal proportions as low as 11TP³T. Two supervised baselines, with a full understanding of the signal distribution in the embedding space, provide a reasonable upper limit for signal sensitivity, and in some cases, NPLM's performance approaches this limit. Above approximately 5σ, some trends become invalid, but at this significance level (p∼10⁻⁷), the findings are machine-defined.
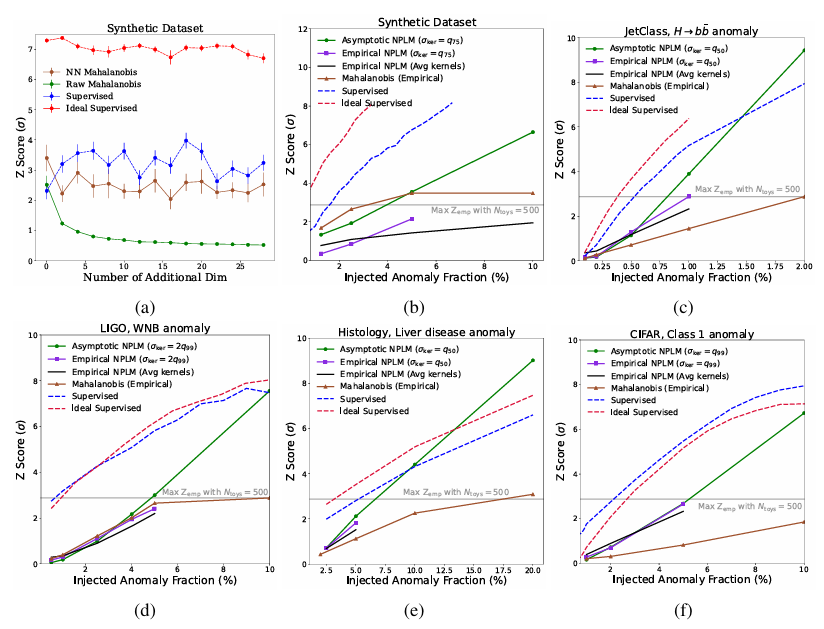
In addition to synthetic dataIn all other datasets, NPLM significantly outperforms the Mahalanobis distance baseline.This is because it is able to model various distortions in the input space.
For the LIGO and JETClass datasets, the proposed method approaches the supervised upper bound with a Z-score of 3, which is comparable to or surpasses all anomaly detection algorithms in their respective fields. While astronomy and particle physics have long utilized statistically evolved anomaly detection techniques, applying them to histology demonstrates the methodological transferability across scientific disciplines.
In terms of histology,Experiments show that the embedding space constructed using label information is superior to the embedding space constructed solely based on data augmentation.With the help of AutoSciDACT, researchers have introduced a new method that can detect localized abnormalities that may only exist in small parts of tissue. This ability is crucial for the early detection of diseases and for guiding pathologists in identifying toxic compounds.
In an era of explosive data growth, "AI scientists" have become a reality.
The AI wave is surging forward, threatening to disrupt everything. Scientific exploration, as the forefront of scientific research, is undergoing unprecedented changes under the empowerment of AI, becoming a core area profoundly reshaped by the AI wave.
In addition to AutoSciDACT mentioned in the aforementioned paperIn the same field, teams from Google, Stanford University, and others have also proposed AI co-scientists that can mimic human scientists.It can generate ideas, discuss and question, and optimize and improve, just like a human. Specifically, it is a multi-agent system built on Gemini 2.0 that can help scientists discover new and original knowledge and, based on existing evidence and in conjunction with the research goals and guidance provided by Science Journal, propose provably innovative research hypotheses and solutions.
Paper title:Towards an AI co-scientist
Paper address:https://arxiv.org/abs/2502.18864
Moreover, AI's ability to conduct scientific research continues to expand, even progressing from "automatically thinking about research on electrons" to "writing complete scientific papers." A team from Oxford University and Columbia University has proposed such an AI scientist.This is the first comprehensive framework for fully automated scientific discovery.This enables advanced large language models to conduct research independently and disseminate their findings. Simply put, this AI scientist can generate novel research ideas, write code, conduct experiments, visualize results, describe their findings by writing complete scientific papers, and then run a simulated peer review process for evaluation.
Paper title:The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Paper address:https://arxiv.org/abs/2408.06292
In the first half of this year, AI Scientist underwent a key upgrade, evolving into AI Scientist-v2. Compared to its predecessor,AI Scientist-v2 no longer relies on human-portable code templates; it can effectively generalize across different machine learning domains.It employs a novel progressive agent tree search method managed by a dedicated trial management agent and integrates a visual-language model (VLM) feedback loop to enhance the AI review component, iteratively optimizing the content and aesthetics of the graphs. Researchers evaluated AI Scientist-v2 by submitting three fully self-written manuscripts to a peer-reviewed ICLR workshop, with highly positive results. One manuscript received a score high enough to exceed the average human threshold, marking the first time a fully AI-generated paper successfully passed peer review.
Paper title:The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Paper address:https://arxiv.org/abs/2504.08066
It's clear that AI and scientific exploration are deeply integrating and evolving, from assisting in hypothesis formulation to fully autonomous scientific research, and from single-domain verification to broad interdisciplinary application. These systems not only break through the efficiency bottlenecks of traditional scientific discovery but also drive the transformation of scientific discovery from "experience-driven" to "data-driven." In the future, with the realization of the human-machine collaboration model, AI will open a new chapter of efficient discovery for the scientific community, while injecting new momentum into the advancement of global civilization.








