Command Palette
Search for a command to run...
Erreichen Sie „Sprachausgabefreiheit“ Mit Nur 3 Sekunden Audio: Mistral Open-Source-Sprachmodell Voxtral-4B-TTS-2603; Setzen Sie Einen Neuen Maßstab Für Datenqualität: Sutra 10B Pretraining.

Aktuell haben schlanke Sprachmodelle oft Schwierigkeiten, Natürlichkeit und Einsatzeffizienz in komplexen, mehrsprachigen Kontexten und bei längeren Synchronisationen in Einklang zu bringen. In der Praxis benötigen Sprachagenten und Content-Broadcasting-Anwendungen nicht nur ein extrem hohes Sprachverständnis, sondern auch geringe Latenz im lokalen Betrieb und nahtloses Umschalten zwischen mehreren Sprachen. Diese anspruchsvollen Szenarien stellen die Parameterskalierung und die Entwicklungsmöglichkeiten bestehender Open-Source-Modelle vor Herausforderungen.
In diesem ZusammenhangMistral hat das Modell Voxtral-4B-TTS-2603 offiziell auf den Markt gebracht. Voxtral TTS ist ein mehrsprachiges Zero-Shot-Text-to-Speech-Modell, das auf einem hybriden Modellierungsframework basiert. Es kodiert Sprache mithilfe des Voxtral-Codecs in semantische und akustische Token. Der semantische Anteil wird durch ASR-Destillation mit dem Text abgeglichen. Während der Generierungsphase generiert ein autoregressives Modell, das ausschließlich den Decoder verwendet, schrittweise semantische Token, um langfristige Konsistenz zu gewährleisten. Gleichzeitig wird ein Flow-Matching-Modell eingeführt, um akustische Token effizient in einem kontinuierlichen Raum zu generieren und dabei Generierungsqualität und Recheneffizienz in Einklang zu bringen. Diese hybride Architektur aus „semantischer Autoregression + akustischem Flow-Matching“ integriert effektiv die Vorteile diskreter und kontinuierlicher Modellierung. Dadurch erreicht das Modell eine hohe Sprachqualität mit nur etwa 3 Sekunden Referenzsprache und zeigt eine gute Generalisierungsfähigkeit in mehrsprachigen Szenarien.
Auf der HyperAI-Website wird jetzt „Voxtral 4B TTS 2603 Multilingual Speech Generation“ vorgestellt – probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/AoY2t
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 30. März bis zum 5. April:
* Hochwertige öffentliche Datensätze: 8
* Eine Auswahl hochwertiger Tutorials: 10
* Interpretation von Community-Artikeln: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im April: 6
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Jobbörsen-Datensatz zur Jobsuche von Studierenden
Dieser Datensatz ist ein synthetischer Datensatz zum Bewerbungsprozess von Hochschulabsolventen und umfasst 100.000 Einträge. Er enthält detaillierte demografische Informationen zu den Studierenden (z. B. Studienfach, Hochschulranking und Region), zu ihren Studienleistungen (z. B. Notendurchschnitt und Praktika) sowie zu ihrem Bewerbungsprozess (Bewerbungseinreichung, Erstgespräch, Zweitgespräch und Stellenangebot). Für Studierende, die ein Stellenangebot erhalten, sind außerdem relevante Variablen wie Gehalt, Unternehmensgröße und Stellenrelevanz enthalten.
Direkte Verwendung:https://go.hyper.ai/Rj94B
2. Groundsource Global Flood Events Dataset
Dieser Datensatz ist ein hochauflösender, automatisch aus globalen Nachrichtendaten erstellter historischer Hochwasserdatensatz mit 2,6 Millionen Einträgen aus über 150 Ländern. Das Forschungsteam nutzte während der Datenverarbeitung Gemini Large Language Models (LLMs), um systematisch strukturierte Informationen wie Zeitpunkt und Ort der Hochwasserereignisse aus unstrukturierten Nachrichtentexten zu extrahieren und so eine automatisierte Erstellung umfangreicher historischer Katastrophendaten zu ermöglichen.
Direkte Verwendung:https://go.hyper.ai/Aj8bq
3. Sutra 10B Pretraining Teaching and Training Dataset
Dieser Datensatz ist ein hochwertiger Lerndatensatz für das Vortraining großer Sprachmodelle. Er wurde mit dem Sutra-Framework generiert, erstellt strukturierte Lerninhalte und optimiert das Vortraining von Sprachmodellen. Als größter Datensatz der Sutra-Reihe demonstriert er, wie dichte, sorgfältig kuratierte Datensätze optimale Ergebnisse beim Vortraining kleiner Sprachmodelle erzielen können.
Direkte Verwendung:https://go.hyper.ai/okKgZ
4. zh-meme-sft-8k Chinesischer Internet-Meme-Kultur-Datensatz
Dieser Datensatz dient der Feinabstimmung von Anweisungen zur chinesischen Internet-Meme-Kultur und wird primär zum Trainieren von Dialogmodellen verwendet, um trendige Internet-Memes zu verstehen und anzuwenden. Er basiert auf Kommentarinteraktionen auf Social-Media-Plattformen wie Douyin, Xiaohongshu und Bilibili und wurde mehrfach bereinigt und optimiert. Zu seinen Merkmalen gehören Dialogstrukturen aus authentischen Quellen, die hohe Qualität der beibehaltenen Trend-Memes nach mehreren Bereinigungsrunden sowie die Standardisierung im ChatML-Format.
Direkte Verwendung:https://go.hyper.ai/O0asZ
5. Datensatz für kreative Aufgabenanweisungen für Kreativprofis
Dieser umfangreiche, detailgetreue Datensatz mit synthetischen Aufgaben dient dem Training, der Evaluierung und der Feinabstimmung multimodaler KI-Agenten. Er umfasst 1.070.917 Agentenbefehle aus 36 kreativen, technischen und ingenieurwissenschaftlichen Softwareumgebungen. Ziel des Datensatzes ist die Erforschung komplexer Softwareinteraktionen und mehrstufiger Denkprozesse.
Direkte Verwendung:https://go.hyper.ai/Da6qF
6. Nemotron Personas France (Französischer Datensatz synthetischer Personen)
Dieser 2026 von NVIDIA in Zusammenarbeit mit Pleias veröffentlichte Datensatz ist ein französischer Datensatz mit synthetischen Charakteren. Er enthält Daten zu synthetischen Charakteren, die auf Basis realer demografischer, geografischer und persönlicher Merkmale Frankreichs generiert wurden. Ziel ist es, vielfältige Daten zu synthetischen Charakteren bereitzustellen, um die Modellentwicklung zu unterstützen und die geografische und demografische Verteilung Frankreichs widerzuspiegeln.
Direkte Verwendung:https://go.hyper.ai/8CmKo
7. Datensatz zur psychischen Gesundheit von Studierenden (Psychische Gesundheit und Burnout bei Studierenden)
Dieser umfangreiche, synthetische Datensatz dient der Analyse und Vorhersage von Burnout-Symptomen bei Studierenden anhand akademischer, psychologischer und lebensstilbedingter Faktoren. Er umfasst 150.000 Datensätze von Studierenden und kombiniert numerische und kategoriale Merkmale, wodurch er sich für maschinelles Lernen, Klassifizierung und Datenanalyse eignet.
Direkte Verwendung:https://go.hyper.ai/YL24S
8. Historische Pandemien und Epidemien: Globaler Datensatz historischer Epidemien
Dieser Datensatz ist eine umfassende Dokumentation der wichtigsten globalen Pandemien im Laufe der Geschichte und dient als sofort verfügbare Analyseressource. Er enthält 50 bedeutende Pandemien von der Antoninischen Pest im Jahr 165 n. Chr. bis hin zu COVID-19 und den Affenpocken im Jahr 2023 und deckt alle Epochen, Regionen und Erregertypen ab.
Direkte Verwendung:https://go.hyper.ai/AbhHY
Ausgewählte öffentliche Tutorials
1. Voxtral 4B TTS 2603 Mehrsprachige Sprachgenerierung
Voxtral-4B-TTS-2603 ist ein Text-to-Speech-Modell (TTS) der Stufe 4B, das von Mistral AI im März 2026 veröffentlicht wurde. Es bietet offene Gewichtungen und mehrsprachige Sprachgenerierungsfunktionen und unterstützt die direkte Synthese von natürlichsprachlichem Text in abspielbares Audio. Dieses Modell ist für Szenarien wie Sprachagenten, Sprachübertragungen, Synchronisation und lokalisierte TTS-Dienste konzipiert und eignet sich für den lokalen Einsatz und Aufruf über standardisierte Serviceschnittstellen.
Online ausführen:https://go.hyper.ai/AoY2t
2. LingBot-World: Ein Open-Source-Weltmodell
LingBot-World ist ein Open-Source-Weltsimulator, der auf Videogenerierung basiert. Als erstklassiges Weltmodell zeichnet er sich durch eine hochpräzise Umgebung, Langzeitgedächtnis und Echtzeit-Interaktivität aus. LingBot-World nutzt eine fortschrittliche Videogenerierungsarchitektur, die qualitativ hochwertige Videos mit räumlich-zeitlicher Konsistenz auf Basis von Eingabebildern, Texteingaben und Kamerapositionssignalen erzeugt.
Online ausführen:https://go.hyper.ai/fzF6R
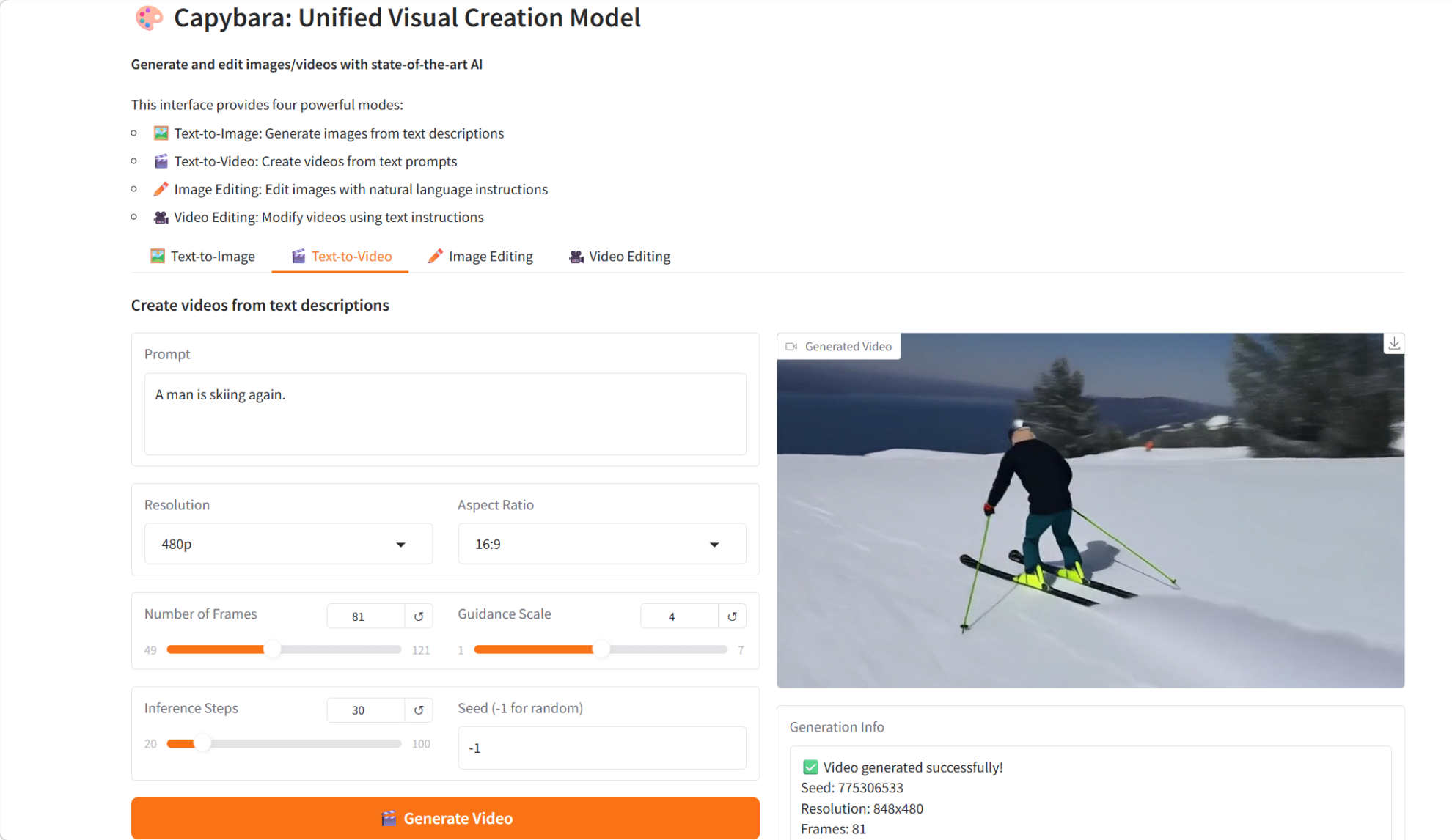
3. Capybara: Ein einheitliches visuelles Erstellungsmodell
Capybara, im Februar 2026 vom xgen-universe-Team veröffentlicht, ist ein einheitliches visuelles Erstellungsmodell für diverse Aufgaben, darunter die Umwandlung von Text in Bilder und Videos sowie die anweisungsbasierte Bild- und Videobearbeitung. Basierend auf einem fortschrittlichen Diffusionsmodell und der Transformer-Architektur bietet Capybara ein einheitliches und effizientes Framework für die visuelle Generierung und Bearbeitung.
Online ausführen:https://go.hyper.ai/yX0Pc
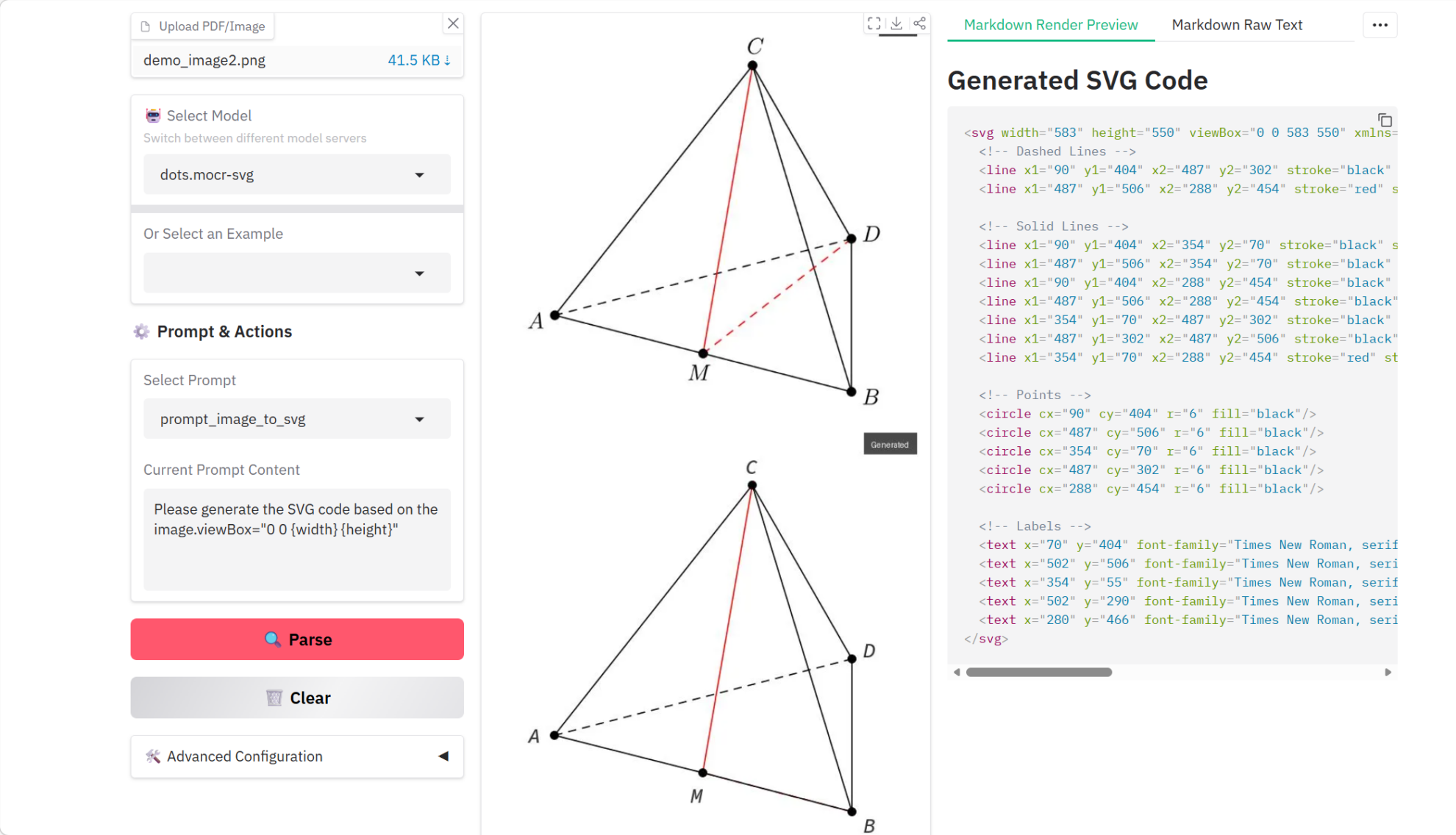
4. dots.mocr Multimodales Dokumenten-Parsing-Tutorial
dots.mocr ist ein multimodales OCR-Dokumentenanalysemodell, das im März 2026 von der Huazhong University of Science and Technology und dem Xiaohongshu HI-Lab gemeinsam veröffentlicht wurde. Im Vergleich zu Modellen ähnlicher Größenordnung erzielt es Bestleistungen bei Standardaufgaben der mehrsprachigen Dokumentenanalyse. Neben der Dokumentenanalyse eignet sich dots.mocr auch hervorragend zur direkten Konvertierung strukturierter Grafiken (wie Diagramme, UI-Layouts, wissenschaftliche Grafiken usw.) in SVG-Code.
Online ausführen:https://go.hyper.ai/g2oB3
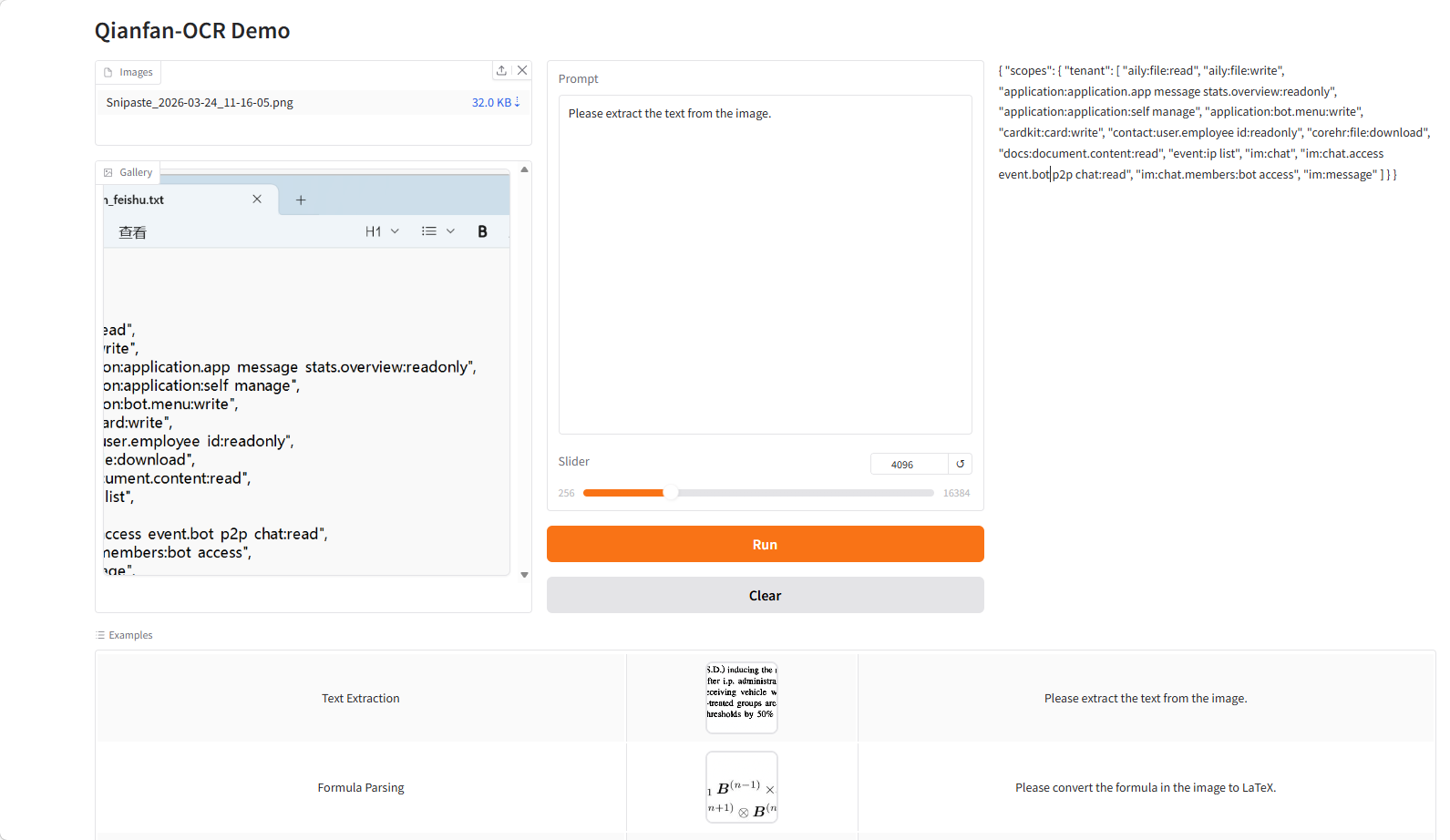
5. Qianfan-OCR: Intelligentes End-to-End-Dokumentenmodell
Qianfan-OCR ist ein umfassendes Dokumentenanalysemodell, das im März 2026 von Baidu AI Cloud Qianfan als Open Source veröffentlicht wurde. Basierend auf einer visuellen Spracharchitektur mit vier Milliarden Parametern integriert es Dokumentenanalyse, Layoutanalyse, Texterkennung und semantisches Verständnis. Die Kerninnovation liegt im „Layout-as-Thought“-Mechanismus: Vor der Ergebnisgenerierung durchläuft das Modell eine „Denkphase“, in der es die Dokumentstruktur (z. B. Elementpositionen, -typen und Lesereihenfolge) explizit modelliert, bevor die eigentliche Analyse abgeschlossen wird. Dies ermöglicht ein einheitliches Framework, das Strukturbewusstsein und semantisches Verständnis in Einklang bringt und so die Genauigkeit und Stabilität in komplexen Dokumentenszenarien verbessert.
Online ausführen:https://go.hyper.ai/WZIRF
6. Bereitstellen von sarvam-30b mit vLLM + Open WebUI
Sarvam-30B ist ein Open-Source-Sprachmodell für große Sprachdaten, das von Sarvam AI im März 2026 veröffentlicht wurde. Als 30B-Version der neuesten Open-Source-Modellreihe von Sarvam verwendet es eine Mixture-of-Experts-Architektur (MoE) mit insgesamt 30 Milliarden Parametern und ca. 2,4 Milliarden aktivierten Parametern pro Token. Es wurde systematisch für mehrsprachige Dialoge, Inferenz, Kodierung und praktische Einsatzszenarien optimiert.
Online ausführen:https://go.hyper.ai/UUJWe
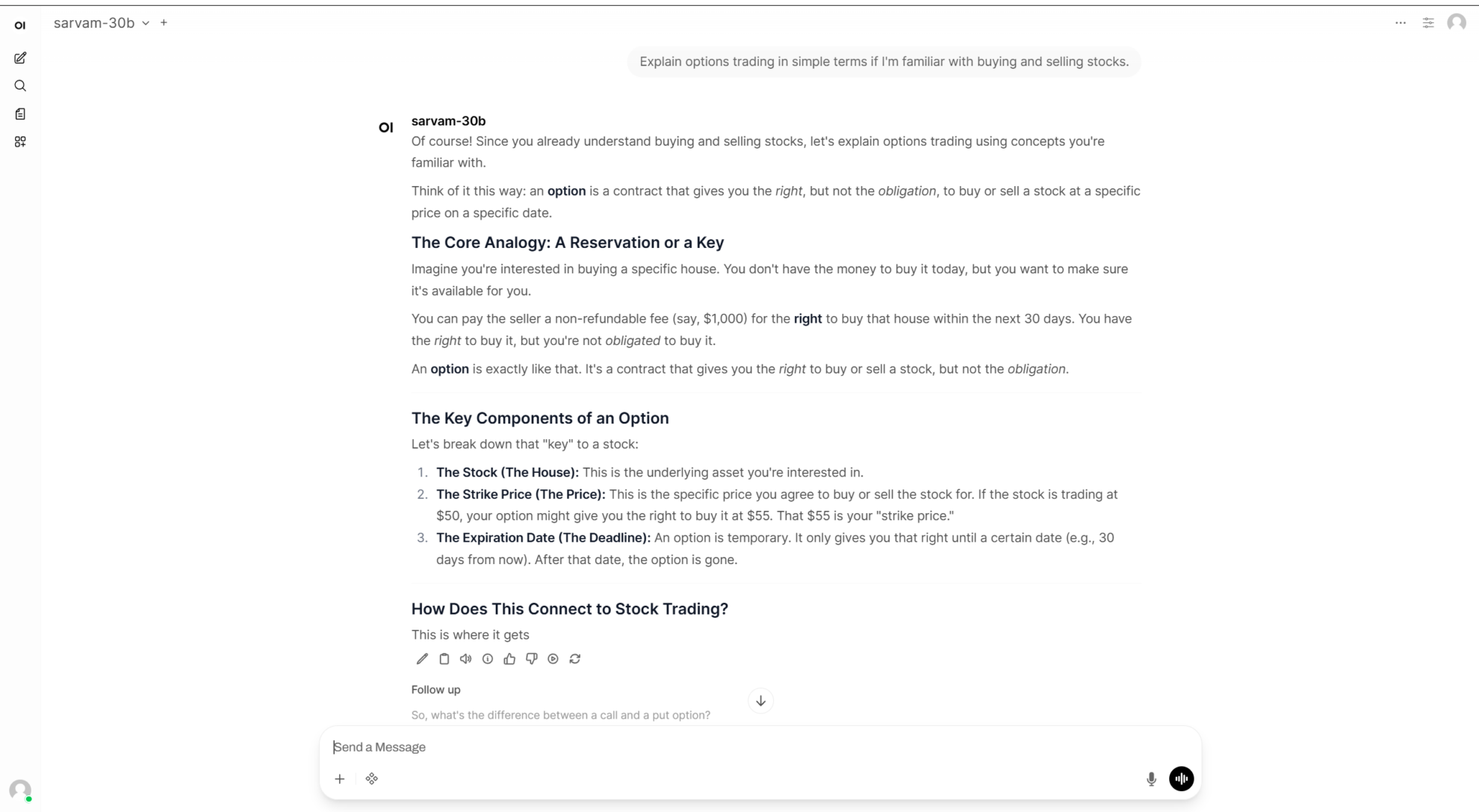
7. Phi-4-reasoning-vision-15B Multimodales Denkmodell – Visuelle Demonstration
Phi-4-reasoning-vision-15B ist ein multimodales visuelles Sprachmodell mit 15 Milliarden Parametern, das von Microsoft im März 2026 veröffentlicht wurde. Basierend auf der Phi-4-Architektur kombiniert dieses Modell leistungsstarke Fähigkeiten zur Textanalyse und zum visuellen Verständnis und ist somit in der Lage, komplexe Text-Bild-Analyseaufgaben zu bewältigen.
Online ausführen:https://go.hyper.ai/JQlDE
8. Slime: Ein SGLang-natives Post-Training-Framework, das für die Skalierung von Reinforcement Learning entwickelt wurde
Slime ist ein vom Knowledge Engineering Lab (THUDM) der Tsinghua-Universität entwickeltes LLM-Post-Training-Framework, das speziell zur Erweiterung von Reinforcement Learning konzipiert wurde. Durch die Verbindung von Megatron und SGLang erzielt dieses Framework eine optimale Kombination aus leistungsstarkem Training und flexibler Datengenerierung.
Online ausführen:https://go.hyper.ai/Xrxev
9. Bereitstellung von NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 mit einem Klick
Der NVIDIA Nemotron 3 Super NVFP4 wurde im März 2026 von der NVIDIA Corporation veröffentlicht. Dieses große Sprachmodell verfügt über 120 Parameter und 12 Aktivierungsparameter, nutzt eine hybride LatentMoE-Architektur und unterstützt Kontexte mit bis zu 1 Million Token. Es ist für Szenarien mit Langzeitkontext-Schlussfolgerungen, Agenten-Workflows, Tool-Aufrufen, RAGs und Frage-Antwort-Systemen mit hohem Durchsatz konzipiert. Im Hinblick auf die Interaktion unterstützt das Modell sowohl das Aktivieren als auch das Deaktivieren eines Schlussfolgerungsmodus und ermöglicht das Umschalten zwischen normaler Frage-Antwort und erweitertem Schlussfolgerungsmodus über standardisierte Chat-Vorlagenparameter.
Online ausführen:https://go.hyper.ai/WJmbe
10. Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled lässt sich mit einem Klick bereitstellen.
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled ist ein leistungsstarkes Dialogmodell, das von Jackrong im März 2026 entwickelt wurde. Es basiert auf dem Plattformmodell Qwen3.5-27B und integriert die Reasoning-Funktionen von Claude-4.6 und Opus zur Wissensdestillation. Dieses Modell verbessert die Fähigkeiten zum komplexen Schlussfolgern und das interaktive Dialogerlebnis deutlich, während die ursprünglichen Sprachverständnisfähigkeiten erhalten bleiben.
Online ausführen:https://go.hyper.ai/SNlOk
Interpretation von Gemeinschaftsartikeln
1. Auf Basis simulierter Spektraldaten von 2.000 Halbleitermaterialien entwickelte ein Team des MIT das Programm DefectNet, das sechs gleichzeitig auftretende Substitutionsdefekte analysieren kann.
Ein Forschungsteam des MIT hat mit DefectNet ein grundlegendes Modell des maschinellen Lernens entwickelt, das die chemischen Arten und Konzentrationen von Substitutionspunktdefekten direkt aus Schwingungsspektren vorhersagen kann, selbst bei gleichzeitigem Vorhandensein mehrerer Elemente. Das Modell zeigt eine gute Generalisierungsfähigkeit bei unbekannten Kristallen mit 56 Elementen und kann mithilfe experimenteller Daten feinabgestimmt werden.
Den vollständigen Bericht ansehen:https://go.hyper.ai/4qtAH
2. Künstliche Intelligenz entdeckt 118 neue Exoplaneten! Ein Team der Universität Warwick entwickelte RAVEN, das einen direkten Vergleich von Planetenszenarien mit jedem falsch-positiven Szenario ermöglicht.
Ein Forschungsteam der Universität Warwick hat RAVEN entwickelt, ein neuartiges Screening- und Validierungsverfahren für TESS-Kandidaten. Dieses Verfahren nutzt einen synthetischen Trainingsdatensatz und geht damit über die alleinige Verwendung von Schwellenwertüberschreitungsdaten (TCE-Daten) hinaus, die durch die Aufgabe selbst generiert werden. Diese Verbesserung erweitert und optimiert den Parameterraum für planetare und falsch-positive Szenarien, der vom Modell für maschinelles Lernen abgedeckt wird. Auf einem unabhängigen externen Testdatensatz mit 1361 vorklassifizierten TESS-Kandidaten erreichte das Verfahren eine Gesamtgenauigkeit von 91% und demonstrierte damit seine Effektivität bei der automatischen Rangfolge der TESS-Kandidaten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/phEO5
3. Das MIT hat VibeGen vorgeschlagen, das erste durchgängige dynamische Proteingenerierungsmodell, das eine bidirektionale Abbildung zwischen Sequenz und Vibration ermöglicht.
Ein Forschungsteam des MIT und der Carnegie Mellon University hat VibeGen vorgestellt, ein intelligentes Agentenmodell zur Proteingenerierung, das die Entwicklung von Proteinen von Grund auf ermöglicht, indem es Sequenzgenerierung mit der Vorhersage von Schwingungsdynamiken kombiniert. Die Ergebnisse zeigen, dass die mit diesem generativen Agenten entworfenen Proteine nicht nur stabile und neuartige Strukturen bilden, sondern auch die Verteilungseigenschaften der gewünschten Schwingungsamplituden auf der Hauptkettenebene reproduzieren können.
Den vollständigen Bericht ansehen:https://go.hyper.ai/jDaSW
Beliebte Enzyklopädieartikel
1. Umgekehrtes Sortieren in Kombination mit RRF
2. Künstliche neuronale Netze (NNs)
3. Visuelles Sprachmodell (VLM)
4. Rotationspositionskodierung (RoPE)
5. Bidirektionales Long Short-Term Memory (Bi-LSTM)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








