Command Palette
Search for a command to run...
Online-Tutorial | Umfangreiche Modifikation Mit Einer Einzigen SIM-Karte: MiniCPM-V-4.6, 1.3B Open Source Modell Unterstützt Bildverständnis/Videoverständnis/OCR/Multimodaler Dialog Mit Mehreren Gesprächsrunden (unter Verwendung Von Wallfacer Und Anderen Open-Source-Bibliotheken).

In den letzten Jahren war die gesamte KI-Branche fast ausschließlich vom Narrativ des Skalierungsgesetzes geprägt. Je größer die Parameter und je mehr Trainingsdaten, desto näher scheint das Modell der „allgemeinen Intelligenz“ zu kommen. Von Hunderten von Milliarden bis hin zu Billionen von Parametern haben große Modelle die Vorstellungskraft der Menschen hinsichtlich Denkvermögen und Weltwissen immer wieder neu beflügelt und die „Anhäufung von Rechenleistung und Skalierung“ zum Standardentwicklungspfad der Branche gemacht.
Doch mit dem tatsächlichen Einzug von KI in die Industrie zeichnet sich allmählich ein echtes Problem ab:Nicht in allen Szenarien ist der Einsatz von Supermodellen in Cloud-Rechenzentren erforderlich.Hohe Inferenzkosten, unkontrollierbare Netzwerklatenz und zunehmende Risiken für den Datenschutz führen zu Engpässen beim Ansatz „großer und umfassender“ Modelle. Das „unlösbare Dreieck“ zwischen Leistung, Aktualität und Kosten ist zu einem Problem geworden, das die Demokratisierung der KI lösen muss.
So begann sich ein scheinbar kontraintuitiver Trend abzuzeichnen: Modelle mit kleineren Parametern zeigten in einer zunehmenden Anzahl realer Szenarien eine höhere Effizienz und Kosteneffektivität, insbesondere bei Edge-Geräten und industriellen Umgebungen mit hoher Parallelität.Leichtgewichtige Modelle übernehmen grundlegende Aufgaben wie OCR, Bildfragebeantwortung und Absichtserkennung.Sie können offline auf mobilen Geräten in Millisekundengeschwindigkeit laufen und auch Routing und Kostenreduzierung innerhalb des RAG-Systems übernehmen, wodurch sie zu einer entscheidenden Infrastruktur für die tatsächliche Implementierung von KI-Anwendungen werden.
Kürzlich haben Facewall Intelligence, die Tsinghua-Universität und OpenBMB gemeinsam das Edge-Multimodalmodell der nächsten Generation, MiniCPM-V 4.6, als Open Source veröffentlicht. Dieses Modell verfügt über nur etwa 1,3 Milliarden Parameter, unterstützt aber Bildverständnis, Videoverständnis, OCR und multimodale Dialogfunktionen mit mehreren Gesprächsrunden und hat in mehreren Evaluierungen andere Modelle der gleichen Stufe übertroffen.
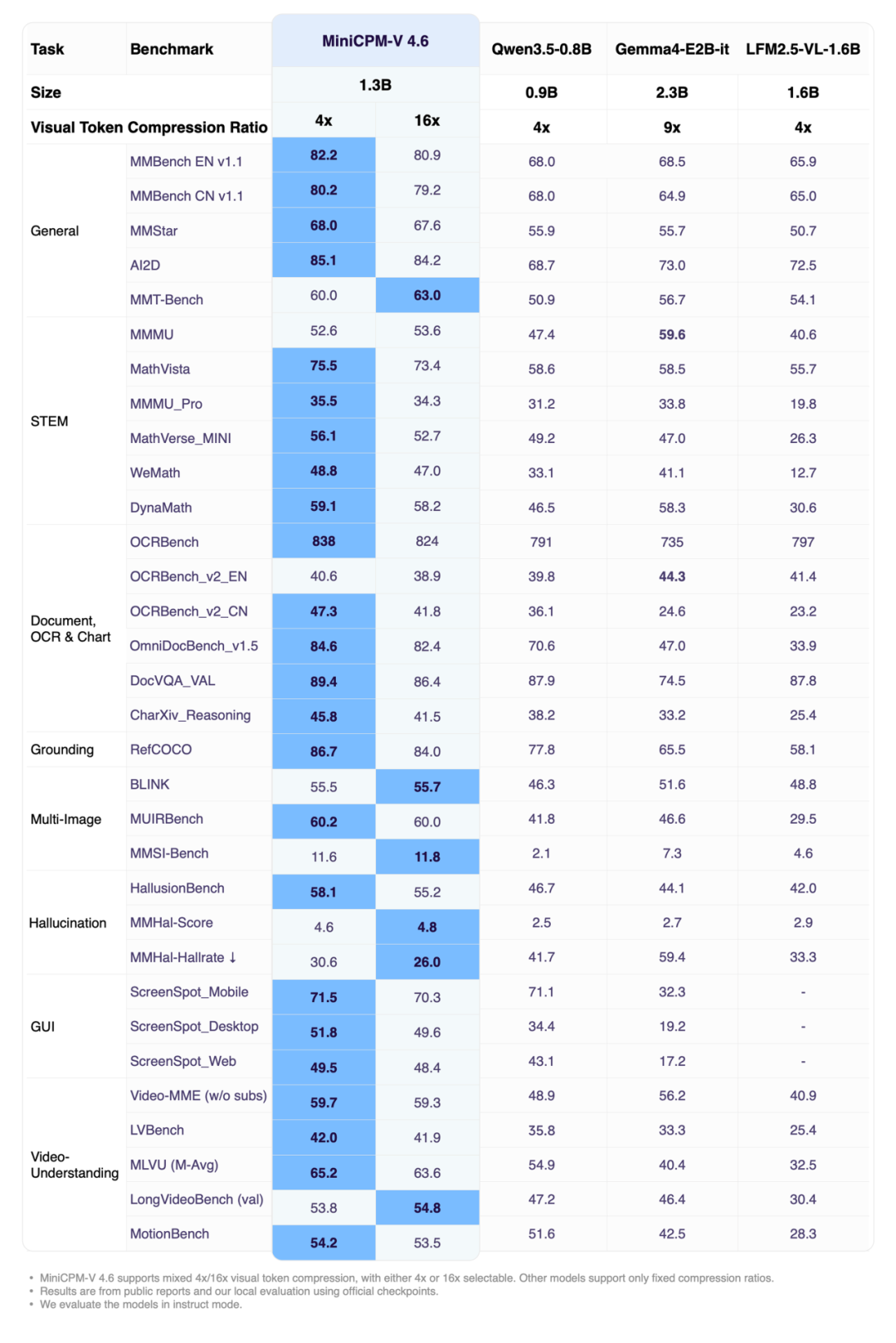
Es ist erwähnenswert, dass die offizielle Modellkarte eine auf Transformern basierende Inferenzlösung für AutoProcessor und AutoModelForImageTextToText bietet, die sich für die schnelle Verifizierung und das Prototyping von Anwendungen in einer Einzel-GPU-Umgebung eignet.
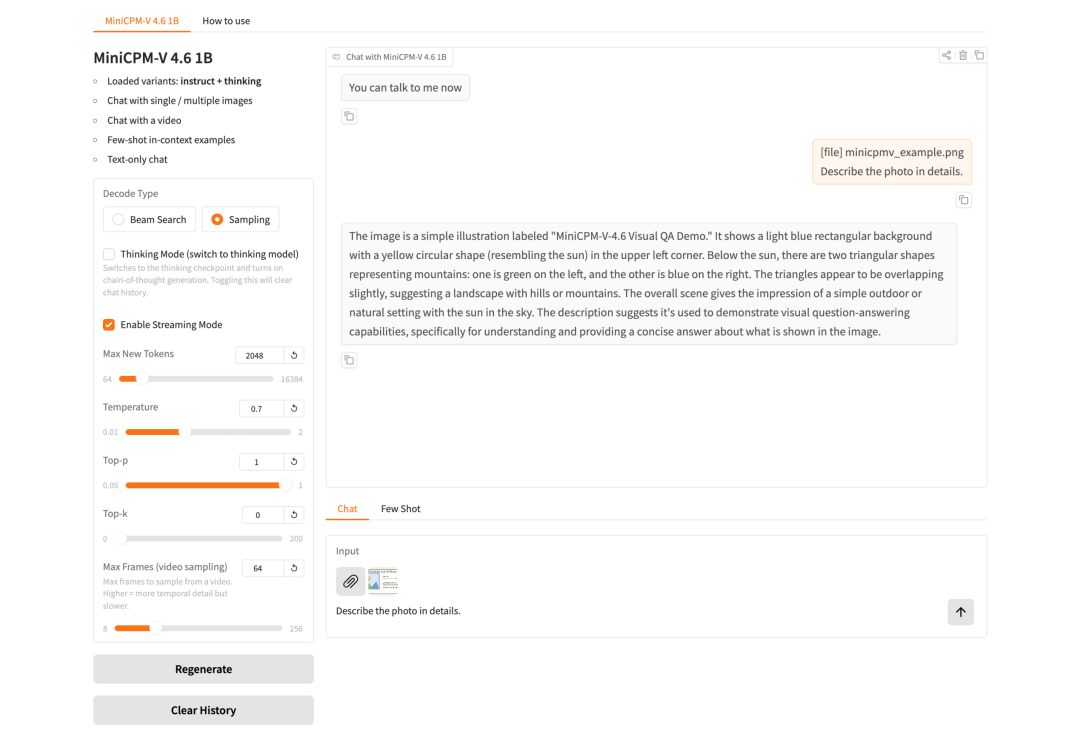
Um Entwicklern weltweit einen schnellen Einstieg in dieses schlanke Modell zu ermöglichen, hat HyperAI „MiniCPM-V-4.6: Effizientes multimodales visuelles Sprachmodell für Edge-Anwendungen“ veröffentlicht. Die Umgebungskonfiguration ist abgeschlossen, und die Online-Bereitstellung des Modells ist problemlos möglich.
Online ausführen:https://go.hyper.ai/GVDmw
Verwandte Forschungsarbeiten ansehen:
https://hyper.ai/papers/2605.08985
Weitere Online-Tutorials:
Besuchen Sie unsere offizielle Website für weitere Informationen:
Demolauf
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „MiniCPM-V-4.6: Efficient Multimodal Visual Language Model for Devices“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
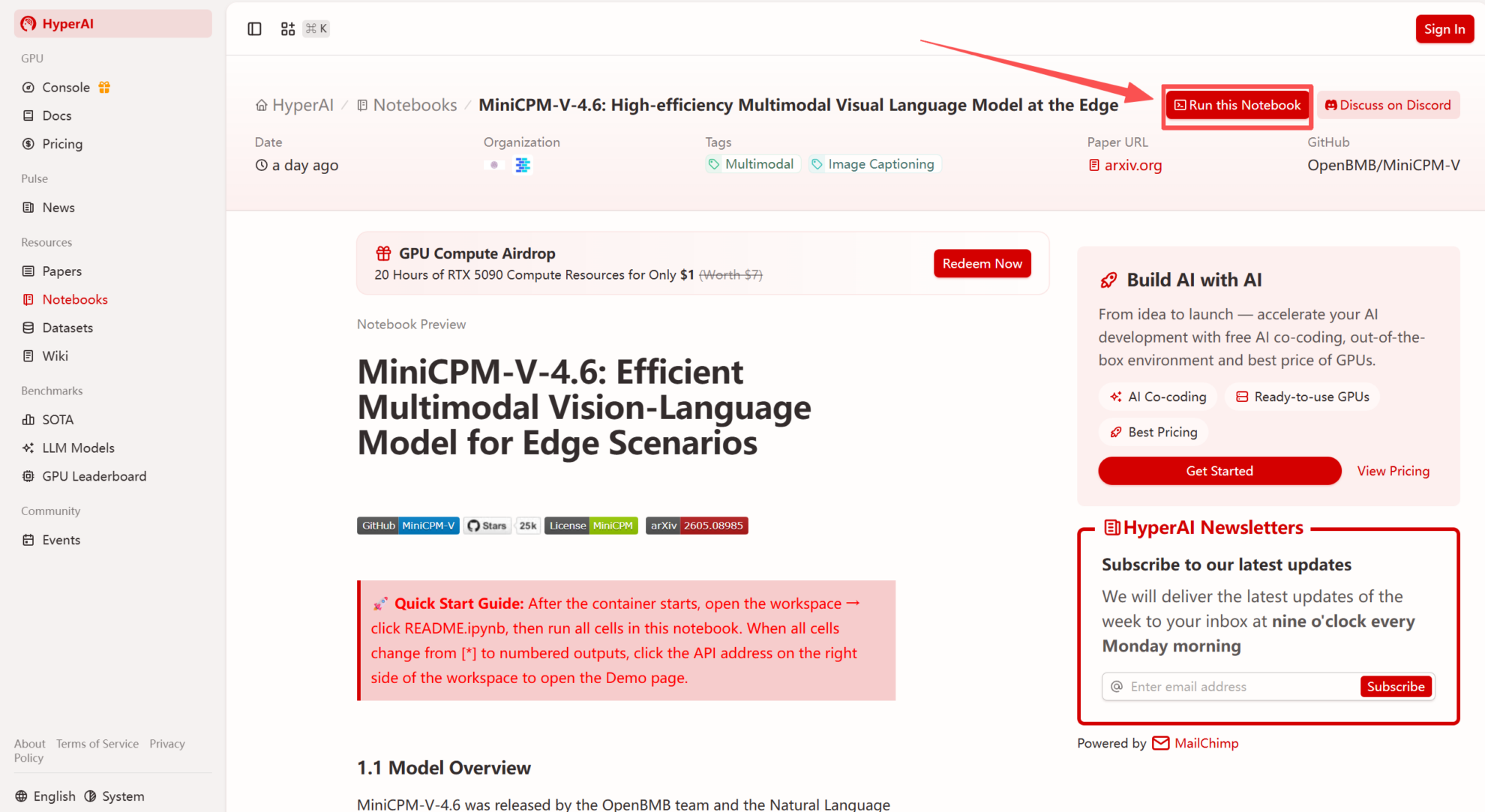
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
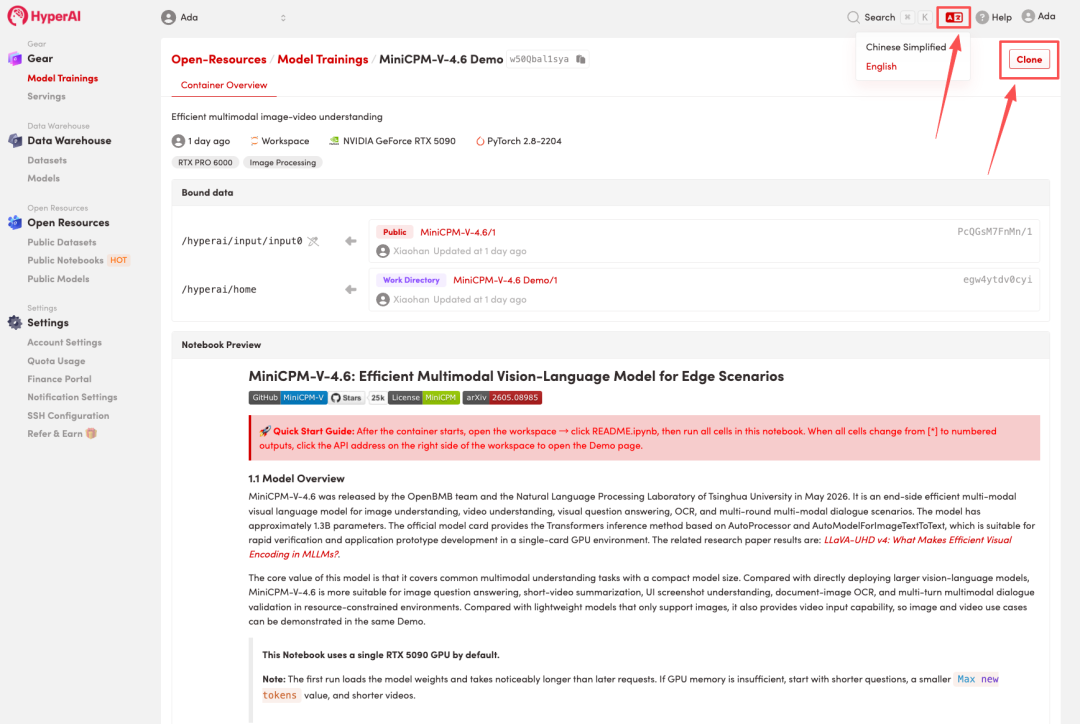
3. Wählen Sie die Images „NVIDIA RTX 5090“ und „PyTorch“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden einen Registrierungsbonus: Für nur $1 erhalten Sie 20 Stunden RTX 5090 Rechenleistung (ursprünglich $7), und die Ressourcen sind unbegrenzt gültig.
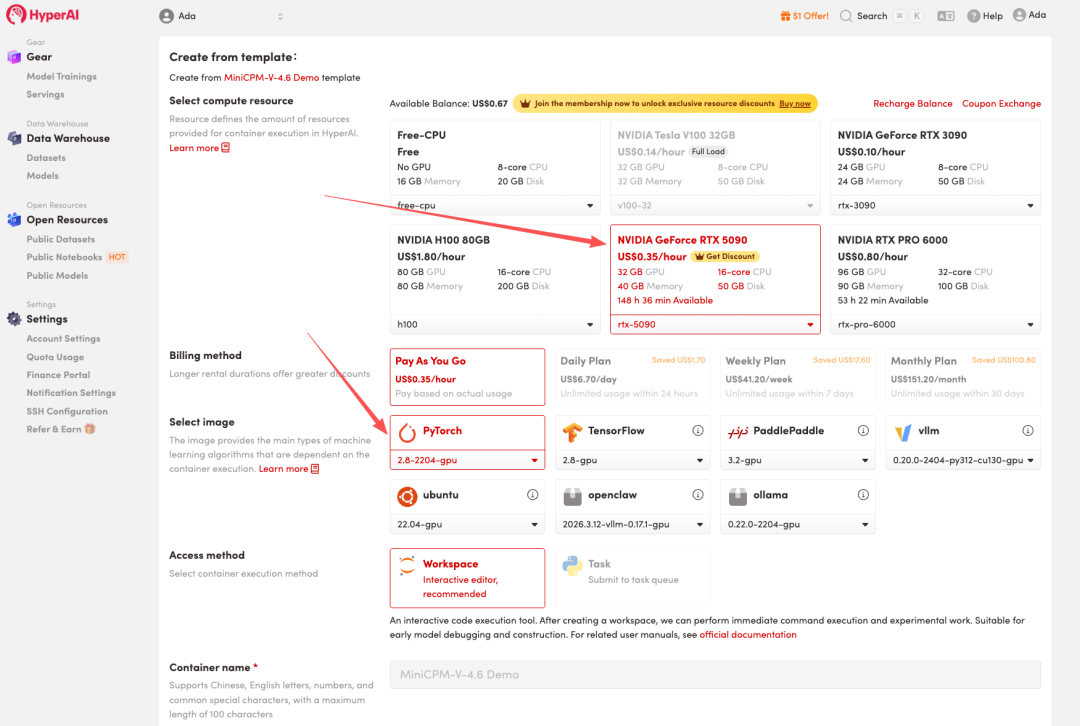
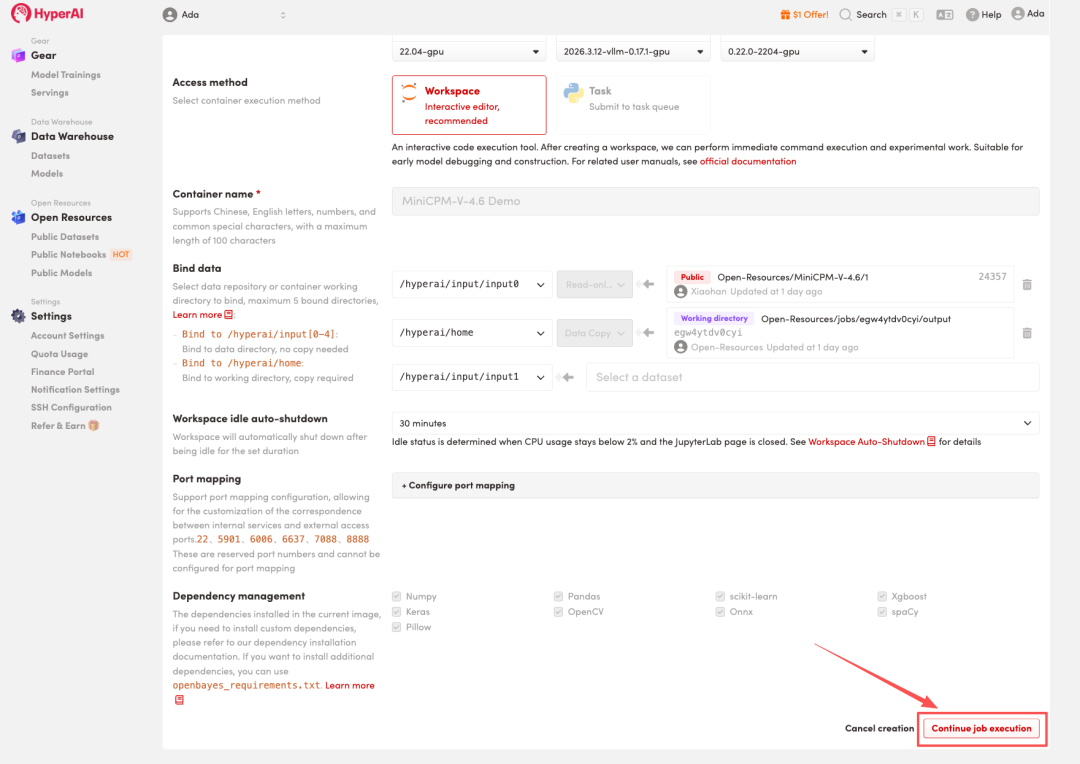
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
Effektanzeige
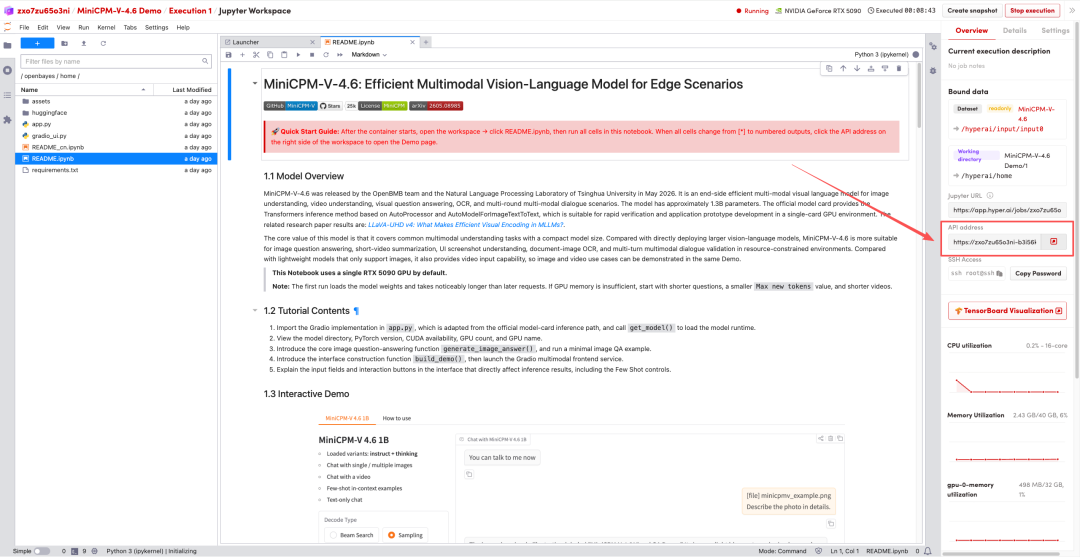
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.