Command Palette
Search for a command to run...
ICLR 2026 | 125-fache Reduzierung Der Trainierbaren Parameter Pro Aufgabe! Die Neue Methode Task Tokens Hilft Der Verkörperten Intelligenz, Ihre Fähigkeit Zur Bewältigung Komplexer Aufgaben Zu verbessern.

In den letzten Jahren haben Fortschritte im Bereich des Imitationslernens in der Robotersteuerung die Entwicklung von Transformer-basierten Verhaltensmodellen (BFMs) vorangetrieben, die die multimodale Steuerung humanoider intelligenter Agenten ermöglichen. Diese Modelle generieren Lösungen anhand übergeordneter Ziele oder Vorgaben, beispielsweise um einen Roboter anhand seiner Beckenposition zu einer bestimmten Koordinate zu führen. Obwohl BFMs sich durch die Generierung robuster Verhaltensweisen mit Zero-Shot-Beispielen auszeichnen, erfordern sie bei der Ausführung spezifischer Aufgaben oft ein aufwendiges Prompt-Engineering, was zu suboptimalen Ergebnissen führen kann.
In diesem ZusammenhangEin Forschungsteam des Technion – Israel Institute of Technology hat eine Methode namens Task Tokens vorgeschlagen, mit der sich BFM effektiv an spezifische Aufgaben anpassen lässt und gleichzeitig seine Flexibilität beibehält.Im Vergleich zu herkömmlichen Basismethoden kann die neue Methode die Anzahl der trainierbaren Parameter pro Aufgabe um bis zu 125 Mal reduzieren und die Konvergenzgeschwindigkeit um bis zu 6 Mal verbessern.
Die Forscher validierten zudem die Effektivität von Task-Tokens in verschiedenen Aufgaben (einschließlich Szenarien außerhalb der Verteilung) und demonstrierten deren Kompatibilität mit anderen Prompting-Methoden. Die experimentellen Ergebnisse zeigen, dass Task-Tokens, unter Beibehaltung der Generalisierungsfähigkeit, eine vielversprechende Lösung für die Anpassung von BFM an spezifische Steuerungsaufgaben darstellen.
Die zugehörigen Forschungsergebnisse mit dem Titel „Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models“ wurden für die ICLR 2026 angenommen.
Forschungshighlights:
* Aufgabenspezifische Anpassung: Task Tokens passen MaskedMimic (GC-BFM) durch tokenisierte Steuerung an spezifische Aufgaben an, ohne dass eine Feinabstimmung des Basismodells erforderlich ist, wobei die Zero-Shot-Fähigkeit erhalten bleibt.
* Hybrides Kontrollparadigma: Ermöglicht die nahtlose Integration von benutzerdefinierten übergeordneten Vorannahmen (wie Text oder gemeinsamen Zielen) mit belohnungsbasierter Lernoptimierung.
* Leistungsfähigkeit und Generalisierungsfähigkeit: Sie ist hinsichtlich der Aufgabenleistung mit der vollständigen Feinabstimmungsmethode vergleichbar, übertrifft jedoch andere Methoden in Bezug auf die Robustheit gegenüber Änderungen der Umgebungsdynamik (wie Schwerkraft und Reibung).

Papieradresse:
https://hyper.ai/papers/2503.22886
Weitere hochaktuelle KI-Veröffentlichungen ansehen:
Aufgabenstellung: Die Allgemeingültigkeit des Modells in einer Reihe von praxisnahen Szenarien testen.
Die Studie entwickelte eine Reihe standardisierter Aufgaben, um die Allgemeingültigkeit und Anpassungsfähigkeit des Modells in einer Reihe von praxisnahen Szenarien zu testen. Jede Aufgabe führte dabei unterschiedliche Komplexitätsgrade in das Steuerungsproblem ein.
Richtung (Gehen in eine bestimmte Richtung)
Diese Aufgabe erfordert, dass sich die Spielfigur in eine vorgegebene Richtung bewegt, um die Fähigkeiten des Modells in Bezug auf grundlegende Gehsteuerung und Zielorientierung zu testen. Das Erfolgskriterium ist, dass die Geschwindigkeitsabweichung des humanoiden Modells entlang der Zielrichtung innerhalb der Messzeit 20% der Zielgeschwindigkeit nicht überschreitet.
Lenkung
Diese Aufgabe erfordert, dass sich ein humanoides Modell in eine vorgegebene Richtung bewegt und dabei die Beckenausrichtung beibehält. Dies testet ausgefeiltere Bewegungssteuerungsfunktionen und führt zu komplexeren Szenarien. Das Erfolgskriterium ist, dass die Geschwindigkeitsabweichung der Figur in Zielrichtung maximal 20% beträgt, während die Gesamtorientierungsabweichung 45° nicht überschreitet.
Erreichen
Bei dieser Aufgabe muss das humanoide Modell mit der rechten Hand einen vorgegebenen Koordinatenpunkt erreichen. Dies erfordert eine hohe Bewegungsgenauigkeit. Das Erfolgskriterium ist, dass der Abstand zwischen der Position der rechten Hand und der Zielposition weniger als 20 Zentimeter beträgt.
Schlagen
Die Aufgabe erfordert, dass sich die Spielfigur zunächst in die Nähe des Zielobjekts begibt und dieses dann umwirft. Dies testet nicht nur die grundlegende Gehfähigkeit, sondern untersucht auch komplexe, aufgabenorientierte Verhaltensweisen wie Zeitmanagement und räumliches Vorstellungsvermögen. Das Zielobjekt gilt als umgestoßen und neigt sich in einer bestimmten Position, wobei der Abweichungswinkel etwa 78° nicht überschreiten darf.
Weitsprung
Die Spielfigur muss in einen 1 Meter breiten Tunnel hineinlaufen, nach 20 Metern eine Linie überqueren und abspringen. Nach dem Überqueren der Absprunglinie darf sie den Boden nicht mehr berühren. Als erfolgreich gilt eine Sprungweite von mehr als 1,5 Metern.
Effiziente Lösung zur Aufgabenanpassung basierend auf der MaskedMimic-Architektur
Die in dieser Studie vorgeschlagene Methode basiert auf einem „Zielkonditionierten Verhaltensgrundlagenmodell (GC-BFM)“ namens MaskedMimic. Im Gegensatz zu traditionellen GCRL-Methoden, die auf Belohnungssignalen zum Lernen beruhen,MaskedMimic kombiniert die Transformer-Architektur und führt eine zufällige Maskierung der zukünftigen Ziele durch, die als Eingabetoken verwendet werden.Dies ermöglicht das Erlernen und Nachahmen menschenähnlichen Verhaltens aus verschiedenen Modalitäten, wie z. B. zukünftigen Gelenkpositionen, Textanweisungen und interaktiven Objekten.
Diese Kombination aus Architektur und Kontrollmechanismen macht MaskedMimic zu einer idealen Grundlage für den Task-Tokens-Ansatz; darüber hinaus verbessern Forscher seine Fähigkeiten weiter, indem sie aufgabenspezifische Tokens lernen, um die Leistung nachfolgender Aufgaben zu optimieren.
Aufgaben-Tokens
Wie im folgenden Diagramm dargestellt, integriert Task Tokens drei Arten von Eingabequellen:
* Prior Token: Optionale Eingabe, die verwendet wird, um benutzerdefinierte Verhaltensvorannahmen über Texteingabeaufforderungen oder gemeinsame Bedingungen einzuführen;
* Aufgaben-Token: Wird von einem trainierten Aufgaben-Encoder generiert, der die aktuelle Zielbeobachtung verarbeitet;
* Status-Token: Stellt den aktuellen Zustand der Umgebung dar.
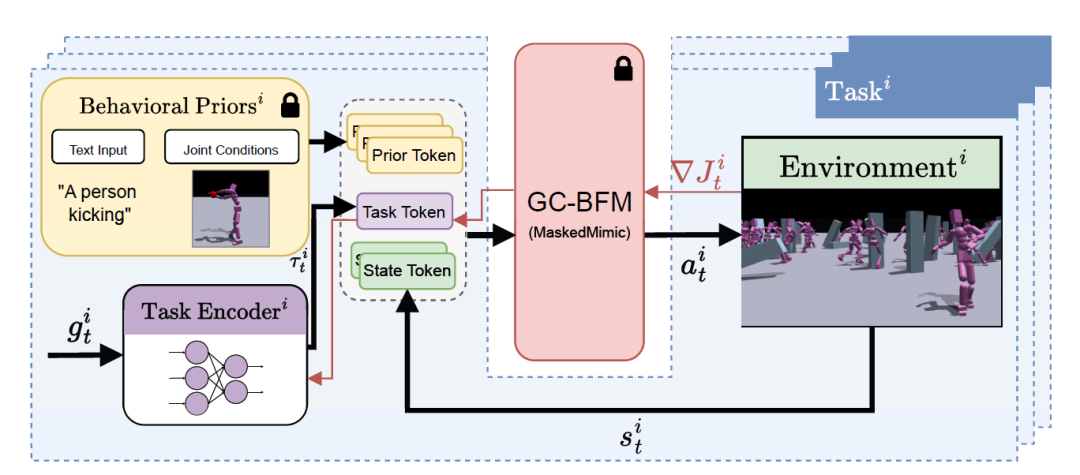
Die Forscher trainierten für jede neue Aufgabe einen speziellen Aufgaben-Encoder, um entsprechende eindeutige Token zu generieren. Diese Aufgaben-Token kapseln die spezifischen Anforderungen und Einschränkungen des Zielverhaltens und liefern dem Basismodell prägnante, aber informative Steuerungssignale. Dadurch kann das Modell Ausgaben generieren, die den spezifischen Aufgabenanforderungen entsprechen und gleichzeitig allgemeine Verhaltensmuster beibehalten.
Aufgabenencoder
Der Aufgaben-Encoder empfängt Beobachtungen, die das aktuelle Aufgabenziel definieren. Diese Beobachtungen werden mit dem Agenten selbst als Bezugssystem dargestellt und geben ein Aufgaben-Token aus. Die Form der Beobachtungen variiert je nach Aufgabe – beispielsweise umfassen die Beobachtungen bei einer Drehaufgabe die Bewegungsrichtung, die Orientierung und die gewünschte Geschwindigkeit des Ziels.
Da MaskedMimic auf Basis zukünftiger Poseziele trainiert wird, erhält der Aufgabenencoder auch propriozeptive Informationen, um sich mit der vortrainierten Repräsentation abzustimmen und so aussagekräftige Zielsignale zu generieren.
Die Forscher implementierten den Aufgaben-Encoder als Feedforward-Neuronales Netzwerk. Dessen Ausgabe (das Aufgaben-Token) wird mit anderen Encoder-Token im BFM-Eingaberaum zu einem Token-„Satz“ verknüpft. In dieser Struktur entsprechen die vom Aufgaben-Encoder ausgegebenen Token spezialisierten „Wörtern“, die das Modell anleiten, eine bestimmte Aufgabe zu erfüllen und dabei die Natürlichkeit der Aktionen zu wahren.
Ausbildung
Um den Aufgaben-Encoder an neue nachgelagerte Aufgaben anzupassen, nutzten die Forscher die Proximal Policy Optimization (PPO). Während des Trainings sagt das BFM die Aktionswahrscheinlichkeitsverteilung anhand einer Kombination von Eingabe-Tokens, einschließlich des Aufgaben-Tokens, voraus. Die PPO-Zielfunktion wird anschließend auf Basis der aufgabenspezifischen Belohnung und der vom BFM ausgegebenen Aktionswahrscheinlichkeiten berechnet. Dadurch werden die Gradienten ermittelt, die zur Aktualisierung der Parameter des Aufgaben-Encoders verwendet werden, während das BFM selbst unverändert bleibt.
BFM effizient und effektiv an spezifische Aufgaben anpassen
Die Forscher evaluierten die Effektivität der Task-Tokens-Methode anhand einer Reihe umfassender Experimente, validierten ihre Leistungsfähigkeit und Anwendbarkeit in vier Schlüsselaspekten und verglichen sie mit mehreren konkurrierenden Basismethoden, darunter:
Reines RL: Verwendet ausschließlich die PPO-Trainingsstrategie und ist von keinem Basismodell abhängig;
* MaskedMimic Fine-Tune: Optimiert das gesamte MaskedMimic-Modell unter Verwendung des Belohnungssignals (ohne Parameter einzufrieren);
* MaskedMimic (Nur Gelenkbedingungen): Das ursprüngliche MaskedMimic, das ausschließlich Gelenkbedingungen als Hinweismechanismus verwendet;
* PULSE: Ein hierarchischer Ansatz, der den latenten Fähigkeitsraum in Bewegungserfassungsdaten wiederverwendet;
* AMP: Nutzt einen Diskriminator, um die Aufgabenleistung zu optimieren und gleichzeitig die Qualität der Aktionen sicherzustellen.
Fähigkeit zur Aufgabenanpassung
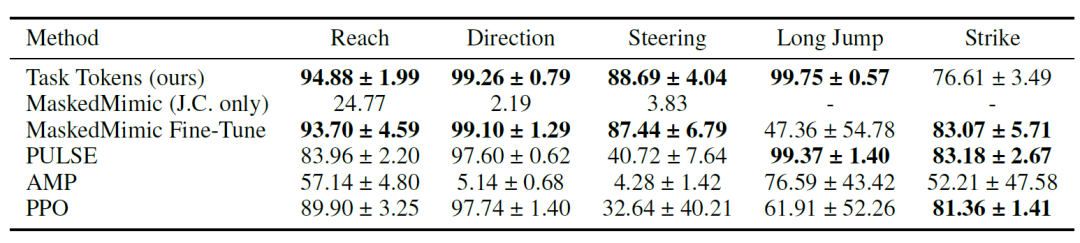
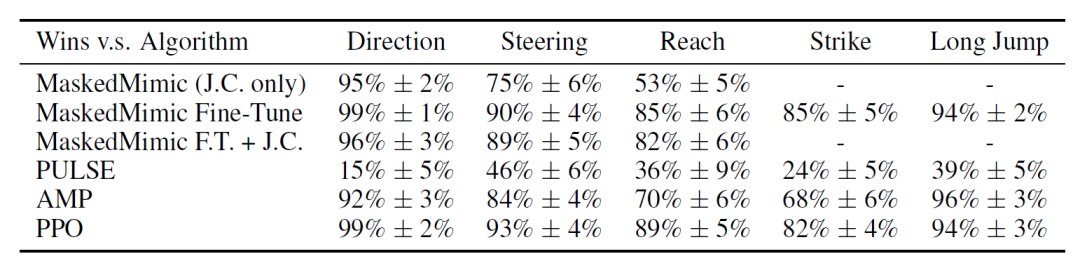
Die Forscher zeigten zunächst, dass Task Tokens MaskedMimic effektiv an nachgelagerte Aufgaben anpassen können; die numerischen Ergebnisse sind in der folgenden Tabelle dargestellt. Die Ergebnisse deuten darauf hin, dass…Task Tokens erzielte in den meisten Umgebungen hohe Punktzahlen, wobei PULSE, MaskedMimic Fine-Tune und PureRL bei der Strike-Aufgabe höhere Punktzahlen erreichten.
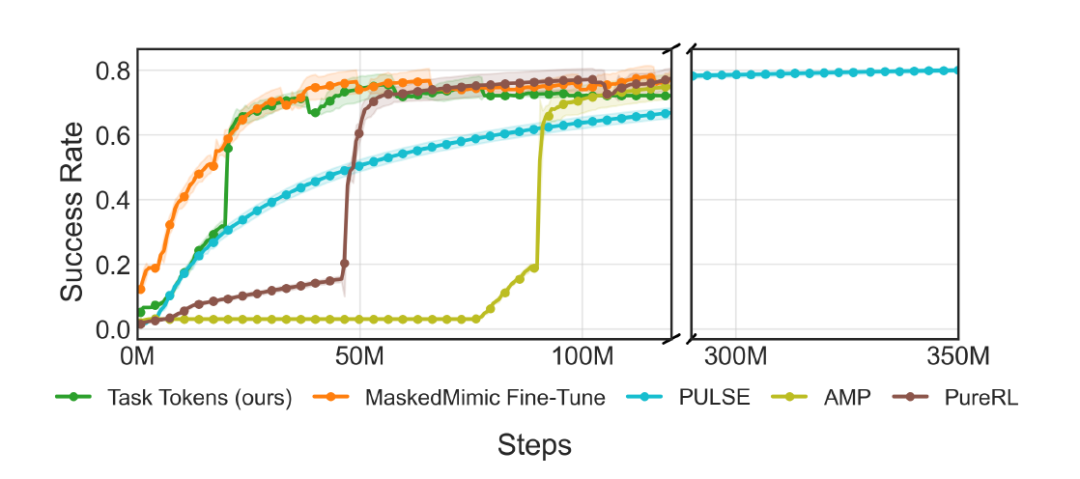
Des Weiteren zeigt die folgende Abbildung die Erfolgskurve während des Trainingsprozesses. Es ist zu erkennen, dass Task Tokens in etwa 50 Millionen (50 Mio.) Schritten konvergiert, während PULSE etwa 300 Millionen (300 Mio.) Schritte benötigt, um die gleiche Leistung zu erzielen.
Um die oben genannten Ergebnisse zu erzielen,Für Task Tokens muss lediglich ein einziger Encoder mit etwa 200.000 (~200K) Parametern trainiert werden.PULSE und MaskedMimic Fine-Tune benötigen 9,3 Millionen (9,3 Mio.) bzw. 25 Millionen (25 Mio.) Parameter, was etwa dem 46,5- bzw. 125-Fachen entspricht. Diese Effizienz ist in realen Anwendungen besonders wichtig, da das Training umfangreicher Modelle extrem aufwendig ist.
Diese Ergebnisse zeigen, dass Task Tokens Verhaltensgrundlagenmodelle wie MaskedMimic effizient und effektiv an neue und unbekannte Aufgaben anpassen kann.
Generalisierungsfähigkeit außerhalb der Verteilung (OOD)
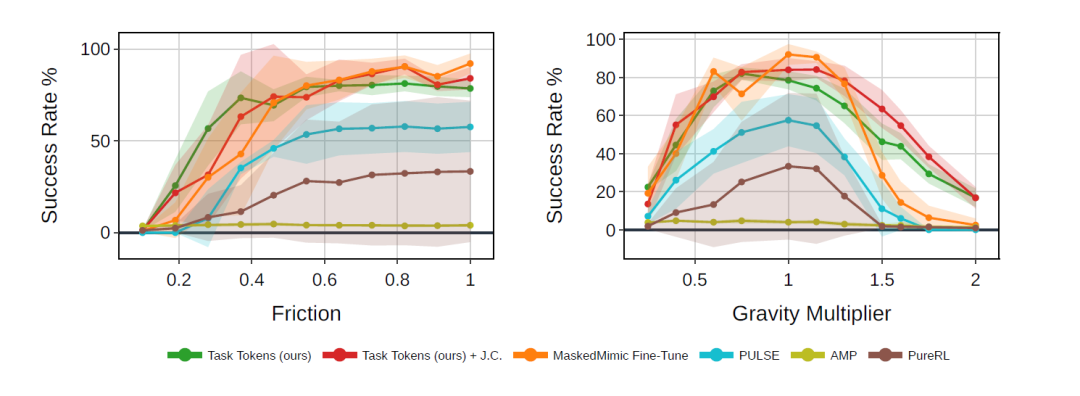
Die Forscher führten vergleichende Experimente unter Out-of-Distribution-Störungsbedingungen (OOD) durch, die während des Trainings der ursprünglichen BFM- und Task-Tokens nicht auftraten, und berücksichtigten hauptsächlich zwei Arten von Veränderungen: Schwerkraft und Bodenreibung.
Die Ergebnisse in der folgenden Abbildung zeigen, dass mit Hilfe von BFM,Task Tokens weisen eine deutlich verbesserte Robustheit in neuen, unbekannten Szenarien auf.Zunächst erzielt Task Tokens unter Basisbedingungen (ohne Störung) nahezu identische Ergebnisse wie ein vollständig feinabgestimmtes MaskedMimic und übertrifft alle anderen Basismethoden. Anschließend verbessert sich die Leistung von Task Tokens mit zunehmender Störungsstärke deutlich. Bemerkenswerterweise weist Task Tokens selbst unter extrem niedriger Reibung (z. B. ×0,4) und hoher Schwerkraft (z. B. ×1,5) eine signifikant höhere Erfolgsquote auf.
Humanstudie
Die folgende Tabelle zeigt den prozentualen Anteil der Aufgaben-Tokens, die im Vergleich zu den einzelnen Vergleichsmethoden als „menschlichere“ Handlung ausgewählt wurden. Die Ergebnisse deuten darauf hin, dass…Task Tokens sind MaskedMimic (nur JC) und MaskedMimic Fine-Tune deutlich überlegen.Dies deutet darauf hin, dass die vom Benutzer festgelegten Bedingungen bestimmte Out-of-Distribution-Eigenschaften für das grundlegende MaskedMimic-Modell aufweisen und dass Task Tokens im Vergleich zur Feinabstimmung eine effektivere Methode zur Anpassung an die Aktionsqualität darstellen.
Darüber hinaus lässt sich feststellen, dass Task Tokens zwar hinsichtlich Konvergenzgeschwindigkeit, Parametergröße und Aufgabenleistung überlegen ist, PULSE jedoch in Bezug auf die „Ähnlichkeit von Aktionen und menschlichen Handlungen“ höhere Werte erzielt.
Auf Grundlage der obigen Ergebnisse kann geschlossen werden, dass Task Tokens ein gutes Gleichgewicht zwischen Effizienz, Aktionsqualität und Robustheit erreichen.
Multimodaler Prompting-Effekt
Abschließend untersuchten die Forscher die Synergieeffekte von Task Tokens mit anderen Prompting-Methoden und demonstrierten dabei deren gute Kompatibilität und Flexibilität.
Bei der Richtungsaufgabe motiviert die Belohnungsfunktion den Agenten lediglich dazu, sich in die richtige Richtung zu bewegen, ohne die menschenähnliche Körperhaltung zu berücksichtigen. Daher kann die Strategie dazu führen, dass er rückwärts geht. Obwohl dieses Verhalten höhere Belohnungen und eine höhere Erfolgsquote erzielt, entspricht es eindeutig nicht den Erwartungen.
Das Bild unten veranschaulicht die Einführung künstlich entworfener Vorannahmen (wie etwa Einschränkungen hinsichtlich der Höhe und Ausrichtung des Kopfziels).Der Trainingsprozess kann zu einem Bewegungsmuster des „aufrechten Gehens“ führen.

Bei der Aufgabe „Angriff“ muss der Agent das Ziel treffen. Ein häufiges Verhalten besteht darin, dass der Agent zum Ziel zurückweicht und dann eine wirbelnde Bewegung ausführt, um das Ziel durch eine Drehung auf der Stelle zu treffen. Die Abbildung unten veranschaulicht die Kombination der beiden zuvor beschriebenen Vorgehensweisen.
Zunächst wird mithilfe von Orientierungsbedingungen, die denen einer Richtungsaufgabe ähneln, sichergestellt, dass sich der Agent während der Bewegung stets dem Ziel zuwendet. Sobald er sich dem Ziel nähert, wird ihm der Text „Eine Person führt eine Trittbewegung aus“ angezeigt, um ihn anzuweisen, die Trittbewegung mit dem Fuß auszuführen.

Forscher stellten fest, dass die Feinabstimmung des gesamten Modells zum bekannten Problem des katastrophalen Vergessens führt und dadurch die Fähigkeit des Modells schwächt, multimodale Hinweise zu speichern und zu verknüpfen. Im Gegensatz dazu bewahrt Task Tokens durch das Einfrieren des Basismodells seine vortrainierten Hinweisfunktionen, wodurch gelernte Verhaltensweisen konsistenter mit vom Menschen vorgegebenen Verhaltensweisen verknüpft werden können.
Abschluss
Aktuelle Experimente basieren primär auf der MaskedMimic-Architektur; zukünftige Arbeiten erfordern die Validierung der Generalisierbarkeit der Methode innerhalb einer umfassenderen GC-BFM-Architektur. Während die Gestaltung aufgabenbezogener Belohnungen und Beobachtungen weiterhin auf Expertenwissen beruht, könnte zukünftige Forschung (halb-)automatisierte Ansätze untersuchen, um den Einstieg zu erleichtern. Ein wichtiger Ansatzpunkt ist die Übertragung von Task-Tokens-angepassten Strategien auf reale Robotersysteme, die Lösung des Problems der Übertragung von Simulationen in die Realität und die Erweiterung auf komplexe reale Aufgaben, die über reine Animationssimulationen hinausgehende Entscheidungen auf hohem Niveau erfordern.
Schließlich könnte die Erforschung komplexerer Architekturen für Aufgabenkodierer (über die aktuelle Feedforward-Netzwerkarchitektur hinaus) zu weiteren Leistungsverbesserungen führen. Die Lösung dieser Probleme wird das Task-Tokens-Framework weiter verfeinern und die Entwicklung vielfältigerer, anpassungsfähigerer und leistungsfähigerer humanoider intelligenter Agenten vorantreiben.
Quellen:
https://openreview.net/forum?id=6T3wJQhvc3
https://arxiv.org/pdf/2503.22886








