Command Palette
Search for a command to run...
Durch Die Nutzung Der Umfangreichen Kontextanalysefähigkeiten Von Gemini 1.5 Erreichte Googles Dialogbasiertes Gesundheitssystem AMIE in 100 Szenarien Mit Mehreren Patientenbesuchen Das Denkvermögen Eines Allgemeinmediziners.

Große Sprachmodelle finden rasch Einzug in das Gesundheitswesen. Ihre Anwendungsgebiete reichen von der Literaturrecherche und der Erstellung von Patientenakten bis hin zur klinischen Entscheidungsunterstützung. Die assistierte Diagnose zählt zu den ausgereiftesten Anwendungsbereichen: Medizinisch optimierte Modelle können auf Basis der Anamnese, der klinischen Befunde und der Untersuchungsergebnisse hochwertige Differenzialdiagnosen stellen. Systeme mit mehrstufigen Dialogfunktionen können die Anamnese zudem durch interaktive Beratungsgespräche ergänzen.
Die Diagnose ist jedoch nur der Ausgangspunkt für klinische Entscheidungen. Entscheidend für die Behandlungsqualität sind oft die nach der Diagnose getroffenen Managemententscheidungen – ob weitere Untersuchungen erforderlich sind, wie ein Behandlungsplan gewählt wird, wann die Medikation angepasst wird, wie Nachsorgetermine geplant werden und wie der Plan fortlaufend an den sich verändernden Zustand des Patienten angepasst wird. Diese Art der „Management-Überlegung“ entspricht eher dem Kern der klinischen Praxis.Zudem wird ein größerer Fokus auf das umfassende Verständnis des Modells für evidenzbasierte Leitlinien, klinische Behandlungspfade, Arzneimittelkenntnisse und individuelle Patientenunterschiede gelegt.
Im Vergleich zum diagnostischen Denken ist das Managementdenken schwieriger zu beurteilen. Diagnostische Probleme weisen in der Regel relativ klare Standardantworten auf, während Managemententscheidungen oft keine eindeutige Lösung bieten und durch medizinische Ressourcen, Leitlinien, die Verfügbarkeit von Medikamenten und die Erfahrung der Ärzte eingeschränkt sind. Derzeit ist die Objective Structured Clinical Examination (OSCE) die wichtigste Methode zur Beurteilung dieser umfassenden Kompetenz in der medizinischen Ausbildung. Da sie jedoch auf der Interaktion mit anderen Personen und der Bewertung durch Experten beruht, lässt sie sich nur schwer direkt auf die automatisierte Bewertung großer Sprachmodelle anwenden.
Um diese Lücke zu schließen, haben Google DeepMind und Google Research in einer aktuellen Studie ein neuartiges, auf dem LLM-Modell basierendes intelligentes Agentensystem entwickelt, das auf ihrem dialogorientierten Gesundheitssystem AMIE aufbaut. Dieses System ermöglicht die Optimierung des klinischen Managements und des Arzt-Patienten-Dialogs für verschiedene Nachsorgeszenarien. AMIE nutzt die Langzeitkontext-Fähigkeiten des Gemini-Modells und kombiniert kontextbezogene Informationssuche mit strukturiertem Schließen, um sicherzustellen, dass die Ergebnisse den aktuellen klinischen Leitlinien und Arzneimittelkatalogen entsprechen.
In einer randomisierten, doppelblinden, virtuellen OSCE-Studie (Objective Structured Clinical Examination) verglichen Forscher AMIE mit 21 Hausärzten. Der Test umfasste 100 Szenarien mit mehreren Arztbesuchen. Die Fallgestaltung orientierte sich an den britischen NICE-Leitlinien und den BMJ Best Practice-Leitlinien. Die Ergebnisse zeigten, dass…Hinsichtlich der von Spezialisten beurteilten Fähigkeit zum logischen Denken im Krankheitsmanagement schnitt AMIE nicht schlechter ab als (nicht unterlegene) menschliche Ärzte;AMIE schnitt unterdessen besser ab als die Ärztegruppe hinsichtlich der Genauigkeit der Behandlungspläne und Untersuchungsempfehlungen sowie des Grades der Einhaltung klinischer Leitlinien und der Zuverlässigkeit der Wissensbasis.
Die entsprechenden Forschungsergebnisse mit dem Titel „Auf dem Weg zu konversationeller KI für das Krankheitsmanagement“ wurden in Nature veröffentlicht.
Forschungshighlights:
* Diese Forschung erweitert die Fähigkeiten des dialogbasierten Gesundheitssystems AMIE von einer einmaligen Diagnose hin zu einem umfassenden klinischen Managementprozess, der Krankheitsverlauf, Entscheidungen bei mehreren Arztbesuchen, Rückmeldungen zum Behandlungserfolg und die Verschreibung von Medikamenten umfasst.
* Das System nutzt die Langzeitkontextualitätsfähigkeiten von Gemini und kombiniert kontextbezogenes Abrufen mit strukturiertem Denken, um sicherzustellen, dass die Managementprotokolle in hohem Maße mit maßgeblichem klinischem Wissen wie den NICE-Leitlinien und den BMJ Best Practices übereinstimmen.
* Das System erreichte bei mehreren Indikatoren ein Niveau, das dem eines Allgemeinmediziners mindestens ebenbürtig war. Dazu zählten die allgemeine Angemessenheit des Protokolls, die Qualität der Behandlungsempfehlungen und die Genauigkeit der Untersuchungsempfehlungen.
Lesen Sie das Dokument:
https://www.nature.com/articles/s41586-026-10764-5
Datensätze: Von der Beantwortung einzelner Fragen bis hin zu vertikalen klinischen Szenarien
Um die praktischen Fähigkeiten von dialogorientierter KI im Gesundheitswesen im Hinblick auf langfristige Managemententscheidungen zu bewerten, hat das Forschungsteam ein mehrstufiges Datensystem aufgebaut.Es umfasst klinische Szenarien mit mehreren Arztbesuchen und berücksichtigt evidenzbasierte Leitlinien sowie Arzneimittelkenntnisse.Wird für das Modelltraining, die Schemaerstellung und die standardisierte Evaluierung verwendet.
Das zentrale Evaluierungsinstrument ist ein Datensatz mit dem Titel „Multiple Visits Virtual OSCE Scenario Dataset“.Die Studie umfasste insgesamt 100 unabhängige Fallstudien.Die Fälle verteilen sich gleichmäßig auf fünf Fachrichtungen: Kardiologie, Pneumologie, Gynäkologie/Urologie, Gastroenterologie und Neurologie/Muskuloskelettale Medizin, mit jeweils 20 Fällen pro Fachrichtung. Alle Fälle wurden gemeinsam von Klinikern aus Kanada und Indien konzipiert und unter Berücksichtigung der Behandlungspfade der NICE-Leitlinien und der BMJ-Leitlinien für bewährte Verfahren erstellt.
Anders als bei typischen, einstufigen medizinischen Frage-Antwort-Sitzungen waren diese Fälle so konzipiert, dass sie drei aufeinanderfolgende Konsultationen umfassten. Jedes Szenario beinhaltete nicht nur die anfängliche Beschwerde des Patienten,Dazu gehören auch Längsschnittdaten wie die Entwicklung der Symptome, das Ansprechen auf die Behandlung und Berichte über die Ergebnisse von Zusatzuntersuchungen.Ziel war es, den realen Entscheidungsprozess im Management chronischer Erkrankungen und der Nachsorge komplexer Fälle präzise abzubilden. Um den klinischen Schwierigkeitsgrad zu erhöhen, wurden in einigen Fällen auch Elemente wie Informationsinkonsistenzen und Multisystemkomorbiditäten integriert, um die Urteilsfähigkeit des Systems unter nicht-standardisierten Bedingungen zu testen.Zusätzlich zu 100 formalen Bewertungsfällen wurden im Rahmen der Studie auch 20 Validierungsszenarien für Vorversuche und die Kalibrierung der Bewertungsskala erstellt.
Der evidenzbasierte Ansatz basiert auf einer Wissensbasis klinischer Leitlinien.Diese Wissensdatenbank enthält 627 Dokumente, darunter 527 NICE-Leitlinien und 100 BMJ-Dokumente zu bewährten Verfahren.Der Gesamtumfang beträgt ca. 10,5 Millionen Tokens und umfasst Diagnosekriterien, Untersuchungsabläufe, Behandlungspläne und Nachsorgeleitlinien. Während des Evaluierungsprozesses steht diese Wissensdatenbank sowohl dem KI-System als auch den teilnehmenden Allgemeinmedizinern zur Verfügung, um die Konsultation von Leitlinienmaterialien im realen klinischen Alltag zu simulieren und einen möglichst fairen Vergleich zwischen Mensch und Maschine zu gewährleisten.
Die Arzneimittelentscheidung ist ein unverzichtbarer Bestandteil der Managemententscheidung. DaherDas Forschungsteam entwickelte außerdem einen speziellen Benchmark für RxQA.Dieser Benchmark dient der Beurteilung des Verständnisses eines Modells für Arzneimittelhinweise, Indikationen, Kontraindikationen, Dosierung und Medikamentenrisiken. Er umfasst 600 Multiple-Choice-Fragen, die auf Arzneimittelhinweisen des US OpenFDA und des britischen National Formulary basieren und in zwei Kategorien unterteilt sind: kurze Basisfragen und ausführliche Fragen zu längeren Szenarien.Der erste Entwurf der Fragen wurde nach den Vorgaben des Gemini-Modells erstellt und anschließend von 8 approbierten Apothekern aus beiden Ländern mit großer Mühe geprüft, überarbeitet und bewertet.Aufgrund von Lizenzbeschränkungen stehen derzeit nur 300 Fragen von OpenFDA zur öffentlichen Freigabe zur Verfügung und bieten eine standardisierte Referenz zum Vergleich der Fähigkeiten zum Arzneimittelverständnis.
AMIE-Modell: Systeme mit „Dialogfähigkeiten“ und „tiefgreifenden Managementfähigkeiten“ ausstatten
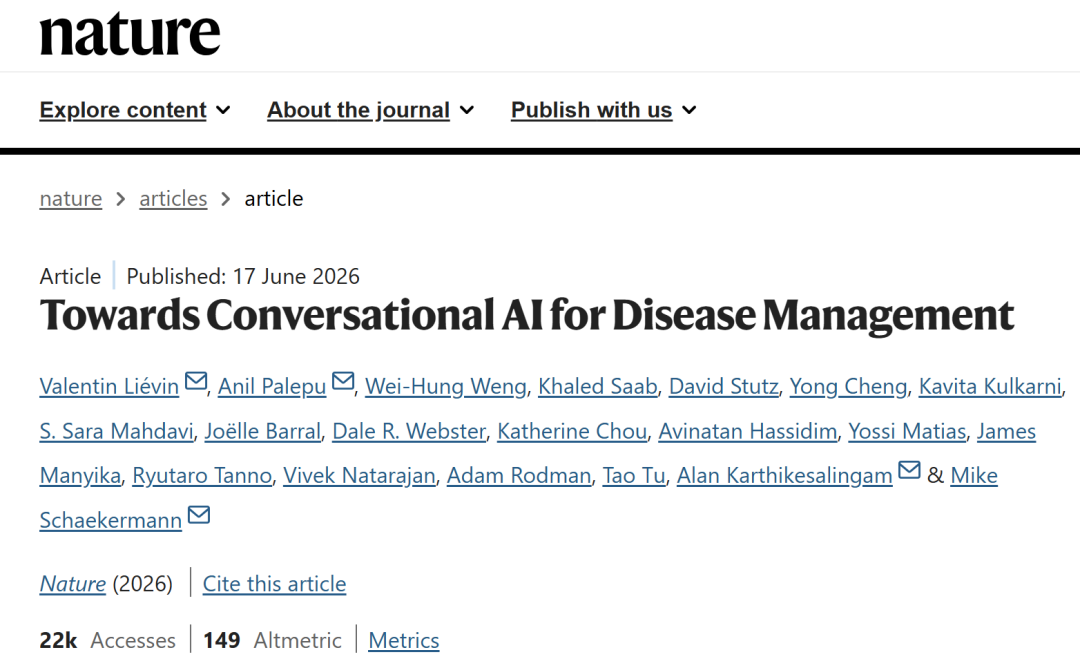
Diese Forschung baut auf Googles zuvor vorgeschlagenem dialogbasierten Gesundheitssystem AMIE auf und beinhaltet spezifische Verbesserungen, um den Anforderungen des Managements an die Entscheidungsfindung gerecht zu werden. Das neue System nutzt eine kollaborative Architektur mit zwei Agenten und orientiert sich dabei an der „Zwei-Prozess-Theorie“ der Kognitionswissenschaft.Ein Agent ist für den schnellen, kontinuierlichen Arzt-Patienten-Dialog zuständig, während ein anderer Agent für langsamere, aber tiefgründigere Management-Analysen verantwortlich ist.Das zugrundeliegende Modell verwendet einheitlich Gemini 1.5 Flash, um ein Gleichgewicht zwischen Echtzeit-Reaktionsgeschwindigkeit und Langzeitkontext-Schlussfolgerungsfähigkeit herzustellen.
Speziell,Das System besteht aus einem Dialogagenten und einem Mx-Management-Inferenzagenten.Der Dialogagent ist eher mit „System 1“ vergleichbar: Er ist für die Echtzeitkommunikation mit Patienten zuständig, erfragt die Krankengeschichte, erläutert Behandlungspläne und dokumentiert den Patientenzustand während des Dialogs. Der Mx-Agent ist eher mit „System 2“ vergleichbar: Er ist primär für die Erstellung strukturierter, nachvollziehbarer Behandlungspläne auf Basis vollständiger Krankheitsinformationen und klinischer Leitlinien verantwortlich. Beide synchronisieren Informationen über ein gemeinsames Statusmodul. Dadurch kann der Dialogagent jederzeit auf die Ergebnisse der Mx-Analyse zugreifen und so eine fundierte medizinische Beratung bei gleichzeitig natürlicher Kommunikation gewährleisten.
Als interaktive Drehscheibe wurde der Dialogagent im Vergleich zum ursprünglichen Diagnosemodell in dreierlei Hinsicht verbessert.Erste,Das Basismodell wurde durch Gemini 1.5 Flash ersetzt, das über umfangreiche Kontextfunktionen verfügt und somit längere medizinische Datensätze und mehrstufige Dialoginformationen verarbeiten kann.zweite,Die Trainingsdaten umfassten mehrere simulierte Arztkonsultationen, um das Verständnis des Systems für den Krankheitsverlauf und die Langzeitbehandlung zu verbessern.dritte,Nach der überwachten Feinabstimmung wurde in der Studie zusätzlich bestärkendes Lernen auf Basis von menschlichem und KI-Feedback eingesetzt, um die Dialogqualität und die Entscheidungsfindung zu optimieren.
Während der Echtzeit-Schlussfolgerung wendet der Dialogagent einen dreistufigen Prozess aus „Planung-Generierung-Verfeinerung“ an:Zunächst plant das System die nächsten Schritte für die Konsultation oder Reaktion auf Basis des aktuellen Status, generiert dann Antworten in natürlicher Sprache für den Patienten und führt schließlich eine Selbstprüfung und -korrektur durch. Um ein kontinuierliches Management über verschiedene Patientenkontakte hinweg zu gewährleisten, verwaltet es zudem eine modulare Statusstruktur mit Patientenübersicht, Differenzialdiagnose, aktuellem Behandlungsplan und weiteren Informationen und aktualisiert diese kontinuierlich im Hintergrund, sodass nicht bei jedem Gespräch von vorne begonnen werden muss.
Der Mx-Agent ist das Kernmodul des gesamten Systems und für die Durchführung von tiefgreifenden Management-Inferenzen zuständig.Es nutzt die Langzeitkontext-Fähigkeiten von Gemini 1.5 Flash voll aus und wendet dabei eine Strategie der „groben Suche + vollständigen Kontextanalyse“ an.Um die Informationsfragmentierung, die bei der herkömmlichen segmentierten Informationssuche auftreten kann, zu minimieren, indexiert das System zunächst alle Leitliniendokumente mithilfe eines Gecko-1B-Einbettungsmodells. Anschließend generiert es eine natürlichsprachliche Anfrage basierend auf dem aktuellen Patientenfall und wählt dabei etwa sechs hochrelevante, vollständige Dokumente aus der Leitlinienbibliothek aus, die insgesamt ca. 256.000 Tokens umfassen. Diese Volltextleitlinien werden zusammen mit der vollständigen Krankengeschichte des Patienten in das Modell eingespeist, sodass dieses in einem einzigen Aufruf eine ganzheitliche Analyse über alle Dokumente und Behandlungsstadien hinweg durchführen kann.
Um die Benutzerfreundlichkeit und Nachvollziehbarkeit der Ergebnisse zu verbessern, verwendet der Mx-Agent JSON-Schema-Constraints zur Ergebnisgenerierung und gibt diese gemäß dem Rahmenwerk „Analyse der klinischen Situation – Definition von Behandlungszielen – Formulierung von Behandlungsschritten und Angabe von Leitlinienquellen“ aus. Jeder Vorschlag muss mit der entsprechenden Leitlinienreferenz versehen sein. Gleichzeitig generiert das System zunächst unabhängig voneinander vier Behandlungsentwürfe und integriert und optimiert diese anschließend anhand des ursprünglichen Leitlinientextes, um die Vollständigkeit und Anpassungsfähigkeit der finalen Lösung zu verbessern.
In allen 15 Indikatoren steht es den Allgemeinmedizinern in nichts nach.
Zur Validierung der Fähigkeit des aktualisierten Systems zur klinischen Beurteilung wurde in dieser Studie ein randomisiertes, verblindetes virtuelles OSCE-Framework in Kombination mit RxQA-Arzneimittel-Benchmark-Tests eingesetzt.Das AMIE-System wurde mit 21 Allgemeinmedizinern verglichen.Die Gesamtbewertung basiert auf drei Dimensionen: der Gesamtqualität des Managementplans, der Qualität der Untersuchungsempfehlungen und der Qualität der Behandlungsempfehlungen.
Im Rahmen der klinischen Beurteilung müssen sowohl Systemärzte als auch Allgemeinmediziner 100 Sätze von ambulanten Mehrfachfällen bearbeiten. Dreißig Fachärzte und standardisierte Patienten führten eine verblindete Bewertung aus zwei Perspektiven durch: fachliche Qualität und Patientenerfahrung. Das bedeutet, dass die Bewertenden nicht wussten, ob der Behandlungsplan von einem KI-System oder einem Arzt stammte, wodurch der Einfluss von Identitätsverzerrungen auf die Ergebnisse minimiert wurde. Die Medikamententests wurden sowohl unter Verwendung von Hilfsmitteln als auch unter Verwendung von Hilfsmitteln durchgeführt, um zu beobachten, ob externe Daten die Leistung des Systems und der Ärzte beeinflussen würden.
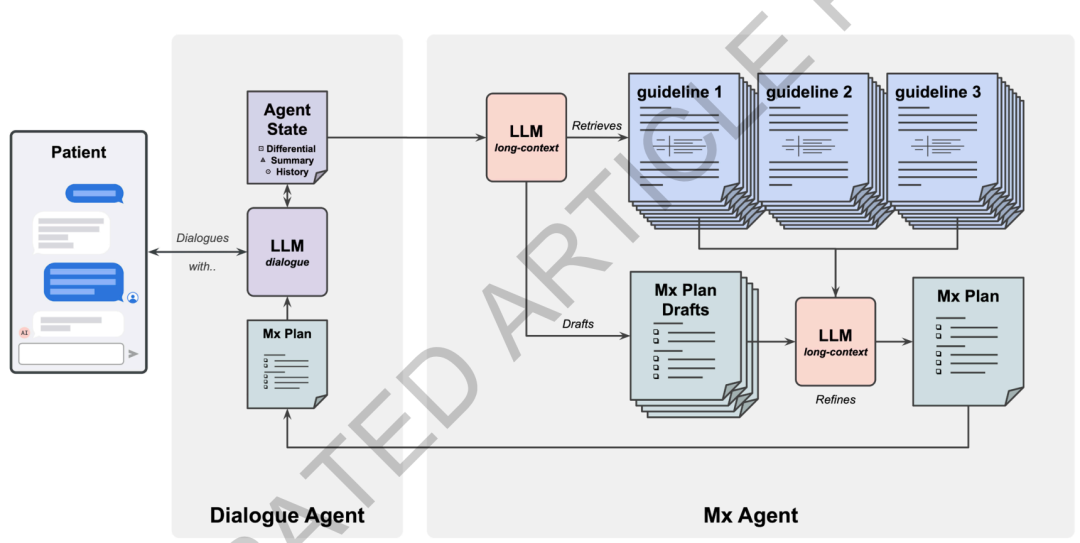
Die Ergebnisse zeigen, dassHinsichtlich der Gesamtqualität des Behandlungsplans steht das System den Allgemeinmedizinern in allen 15 Bewertungsdimensionen in nichts nach und weist bei vielen Indikatoren statistische Vorteile auf.Am Beispiel der Gesamtangemessenheit des Behandlungsplans erzielte das System bei den drei Besuchen jeweils 95%, 96% und 98% Punkte. Diese Werte liegen über den Bewertungen des Hausarztes von 72%, 80% und 81%. Auch hinsichtlich der Angemessenheit der Behandlungsempfehlungen erreichte das System 87%, 90% und 94% Punkte und lag damit ebenfalls über den Bewertungen des Hausarztes von 66%, 62% und 71%.
Das System weist zudem einen durchgängigen Vorteil in der Genauigkeit seiner Untersuchungs- und Behandlungsempfehlungen auf.Die Genauigkeit der Behandlungsempfehlungen liegt konstant über 95%, während die von Allgemeinmedizinern zwischen 62% und 67% liegt.Hinsichtlich der Leitlinienkonformität ist die Nachvollziehbarkeit des Systems deutlich besser als die von Ärzten, da jede Empfehlung eine explizite Quellenangabe erfordert. Dieses Ergebnis legt nahe, dass der Integrationsmechanismus von Kontextanalysen mit dem ursprünglichen Leitlinientext die Stabilität und Interpretierbarkeit des Modells bei komplexen Managementaufgaben verbessern kann.
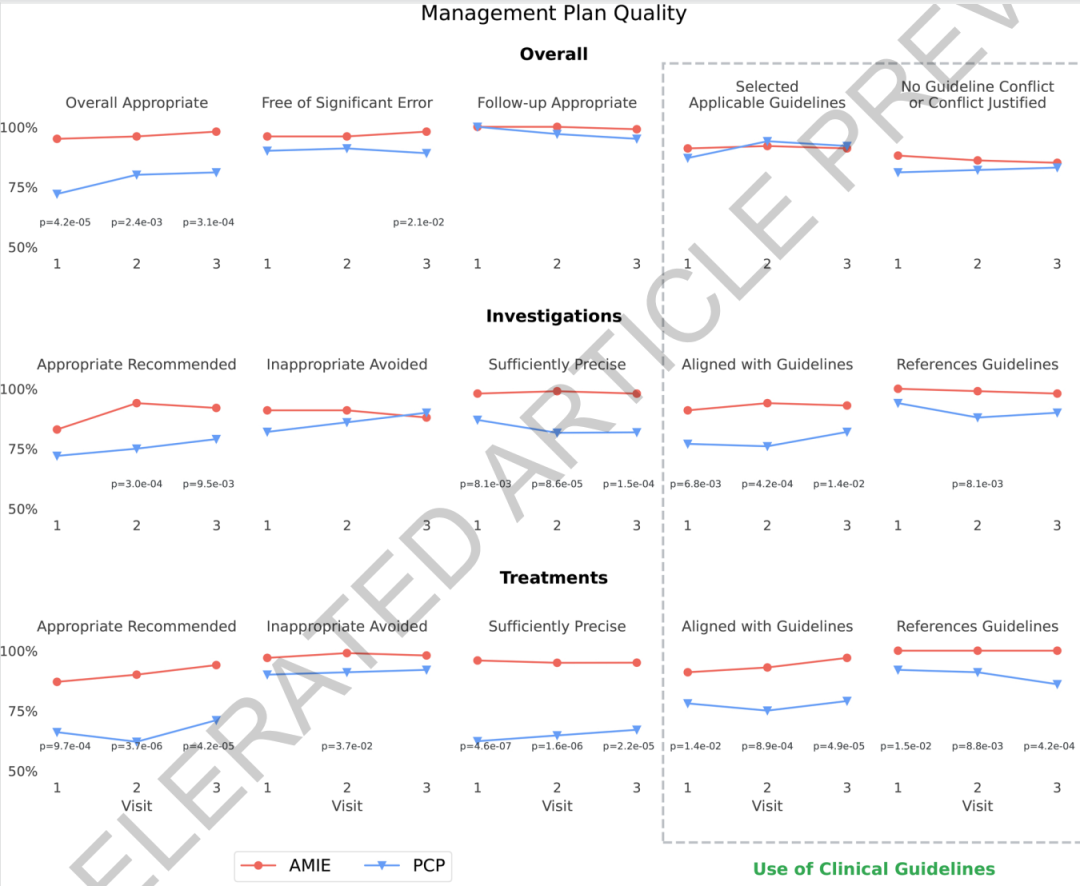
Die Studie untersuchte die Präferenz aus zwei Perspektiven und umfasste zehn Kerndimensionen des Managementdenkens, woraus 51 Vergleichspaare resultierten. In fast der Hälfte der Fälle stuften sowohl der Spezialist als auch der Patient ihre Leistung als vergleichbar ein.In Fällen, in denen eine klare Präferenz festgestellt wurde, lag die Trefferquote des Systems bei 47% und damit deutlich höher als die 7% bei Allgemeinmedizinern.Besonders bemerkenswert ist, dass die Bewertungstendenzen von Fachärzten und Patienten weitgehend übereinstimmen, was darauf hindeutet, dass sich die Vorteile des Systems nicht nur im professionellen Urteil, sondern auch in Dimensionen widerspiegeln, die mit der Patientenerfahrung zusammenhängen.
Mit zunehmender Anzahl an Besuchen werden die Vorteile des Systems in Bezug auf zeitbezogene Aspekte wie dynamisches Monitoring, Patientenfluss und Arzt-Patienten-Beziehung deutlicher. Dies entspricht dem ursprünglichen Forschungsziel: Die Schwierigkeit im Entscheidungsprozess liegt nicht in der Frage, ob eine einzelne Antwort richtig ist, sondern in der Fähigkeit, Veränderungen im Patientenzustand, Behandlungsrückmeldungen und die nächsten Schritte im Behandlungsplan kontinuierlich miteinander zu verknüpfen.
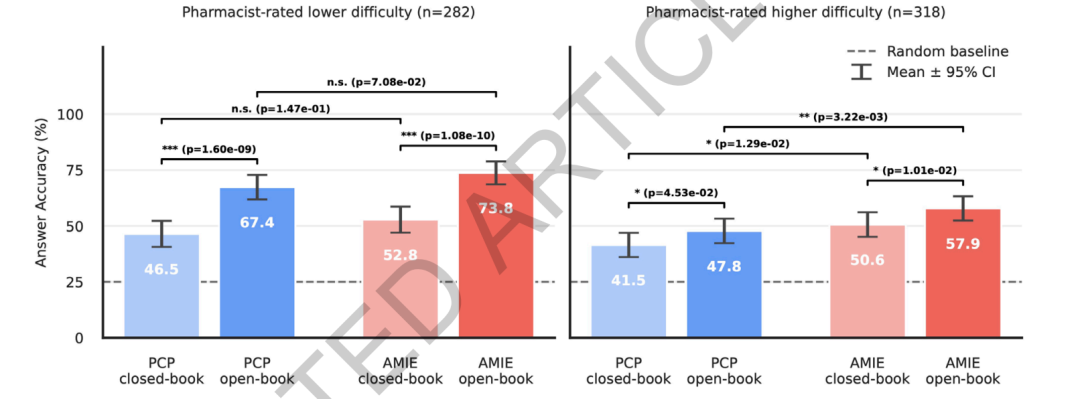
Im Hinblick auf die Argumentation bezüglich Drogen,Die RxQA-Benchmarks zeigen, dass das System bei sehr schwierigen, von Apothekern bewerteten Fragen Allgemeinmediziner übertrifft.In einer Umgebung ohne Hilfsmittel lag die Genauigkeit des Systems bei 50,61 TP3T, die der Allgemeinmediziner bei 41,51 TP3T. In einer Umgebung mit Hilfsmitteln betrug die Genauigkeit des Systems 57,91 TP3T und die der Allgemeinmediziner 47,81 TP3T. Bei einfacheren Fragen gab es keinen signifikanten Unterschied zwischen den beiden Methoden. Hilfsmittel erwiesen sich sowohl für das System als auch für die Ärzte als hilfreich und verbesserten die Genauigkeit insbesondere bei einfacheren Fragen um mehr als 20 Prozentpunkte. Bei schwierigeren Fragen fiel die Verbesserung geringer aus, war aber dennoch statistisch signifikant. Dies deutet darauf hin, dass das Modell bei komplexen Aufgaben der Arzneimittelinformationsintegration einen gewissen relativen Vorteil besitzt, externe Hilfsmittel allein jedoch nicht in der Lage sind, hochkomplexe Probleme der Arzneimittelbeurteilung vollständig zu lösen.
Letzte Worte
Der Wert dieser Studie liegt nicht im Beweis, dass groß angelegte medizinische Modelle Ärzte ersetzen können, sondern in der Verlagerung des Bewertungsschwerpunkts von der Diagnose hin zum kontinuierlichen Management. Im Vergleich zu einmaligen Frage-Antwort-Runden entspricht das Management-Denken eher der realen klinischen Praxis: Ärzte müssen ihre Beurteilungen fortlaufend an den Krankheitsverlauf, das Feedback zur Behandlung, die Leitlinien und die individuellen Unterschiede der Patienten anpassen. Die in der Studie vorgeschlagene virtuelle OSCE mit mehreren Visiten, die Leitlinien-Wissensdatenbank, die arzneimittelspezifischen Benchmarks und das Dual-Agenten-System bieten einen klinisch relevanteren Rahmen für die Bewertung medizinischer KI. Die virtuelle Umgebung kann jedoch die physischen Untersuchungen, Ressourcenbeschränkungen, die Patienten-Compliance und die Haftungsgrenzen im realen Gesundheitswesen noch nicht vollständig abbilden.
Eine umsichtigere Einschätzung ist daher, dass sich das medizinische Big-Data-Modell von der „Unterstützung der Diagnose“ hin zur „Unterstützung des Managements“ verschiebt. Sein kurzfristiger Nutzen besteht nicht darin, Ärzte bei der endgültigen Entscheidungsfindung zu ersetzen, sondern darin, ein nachvollziehbares, überprüfbares und kontinuierlich aktualisiertes klinisches Entscheidungshilfesystem in Bereichen wie der Analyse des Krankheitsverlaufs, dem Abgleich mit Leitlinien, der Medikamentenverifizierung, der Nachsorgeplanung und der Patientenkommunikation zu werden.








