Command Palette
Search for a command to run...
Auf Basis Von 25.000 Klinischen Datenpunkten Veröffentlichte Die Stanford University Mit Merlin Das Erste Native 3D-Abdomen-CT-Bildgebungsmodell Mit Visueller Sprache, Das Bei 752 Aufgaben Führend ist.
Die Computertomographie (CT) ist ein gängiges bildgebendes Verfahren in der klinischen Diagnostik und Therapie und wird häufig zur Diagnose von Erkrankungen in verschiedenen Körperregionen eingesetzt. Statistiken zeigen, dass weltweit jährlich etwa 300 Millionen CT-Untersuchungen durchgeführt werden, wobei etwa ein Viertel davon auf den Abdomenbereich entfällt. Da die medizinische Diagnostik und Therapie zunehmend auf bildgebende Verfahren angewiesen sind, steigt der Bedarf an bildgebender Diagnostik stetig. Allerdings benötigt ein Radiologe im Durchschnitt 20 Minuten, um eine einzelne CT-Aufnahme des Abdomens zu interpretieren, und die diagnostische Effizienz kann mit dem rasant steigenden klinischen Bedarf kaum Schritt halten. Noch gravierender ist der akute Mangel an Radiologen; Prognosedaten zeigen, dass…Bis 2036 werden einige Regionen mit einem Mangel von mehr als 19.000 Radiologen konfrontiert sein, was das wachsende Ungleichgewicht zwischen Angebot und Nachfrage in der Branche verdeutlicht.
Maschinelles Lernen kann dank seiner ausgefeilten Datenverarbeitung und seiner Fähigkeit zur Hochdurchsatzanalyse schnell Merkmale extrahieren und große Mengen medizinischer Bilder intelligent identifizieren. Dadurch werden die Schwächen der traditionellen manuellen Bildinterpretation, wie geringe Effizienz und Personalmangel, effektiv behoben. Insbesondere Vision-Language-Modelle (VLMs), die auf der Contrastive Language-Image Pretraining (CLIP)-Vortrainingstechnologie basieren, ermöglichen die Ausrichtung von Text- und Bilddarstellungen in einem gemeinsamen Einbettungsraum und unterstützen so die Überwachung visueller Modelle mithilfe natürlicher Sprache.Als grundlegendes Modell ermöglicht dieser Modelltyp nicht nur das Lernen ohne vorherige Übung, sondern kann, nach der Kombination mit einem großen Sprachmodell und dem Training mit klinischen Daten, auch schnell an die Analyse radiologischer Bilder und Befunde angepasst werden.
Über die theoretischen und technologischen Fortschritte hinaus zeigen aktuelle VLM-basierte Methoden ein immenses Anwendungspotenzial in der Radiologie. Modelle wie BiomedCLIP, LLaVA-Rad und Med-PaLMM werden erfolgreich implementiert. Technologischer Fortschritt und die Implementierung von Modellen bedeuten jedoch nicht automatisch eine ausgereifte Anwendung. VLMs stehen in der Praxis weiterhin vor zahlreichen Herausforderungen, die ihre breite Akzeptanz und ihren zuverlässigen Einsatz im klinischen Alltag behindern.
Erste,Die gängigen Methoden konzentrieren sich hauptsächlich auf zweidimensionale Bilder wie Röntgenaufnahmen, was die effiziente Verarbeitung dreidimensionaler Bilder wie z. B. CT-Scans des Abdomens erschwert. Die Methode der Analyse des gesamten Volumens durch Schichtaggregation ist äußerst ineffizient.Zweitens,Derzeit existiert kein öffentlich zugänglicher Datensatz für abdominale CT-Untersuchungen zur Schulung und Evaluierung von VLMs. Private Modelle integrieren multimodale klinische Daten wie Diagnosekodierungen und radiologische Befunde nicht vollständig, und es fehlt ein einheitlicher Benchmark für dreidimensionale abdominale CT-Untersuchungen. Dies führt zu einer erheblichen Lücke im Trainings- und Evaluierungssystem der entsprechenden Basismodelle.
Angesichts der oben genannten HerausforderungenEin Forschungsteam der Stanford University hat Merlin vorgestellt, das erste native 3D-Bildsprachemodell für CT-Scans des Abdomens, zusammen mit einem Datensatz, der 25.494 gepaarte CT-Scans des Abdomens und radiologische Befunde enthält. Merlin wurde auf einer einzelnen NVIDIA A6000 GPU mit strukturierten und unstrukturierten Daten aus realen Krankenhäusern trainiert, darunter gepaarte CT-Scans, Diagnosecodes aus elektronischen Patientenakten (EHR) und radiologische Befunde. Das Forschungsteam führte eine interne Validierung an 5.137 CT-Scans und eine externe Validierung an 44.098 CT-Scans sowie zwei öffentlich verfügbaren Datensätzen mit Fokus auf abdominale CT-Scans (VerSe und TotalSegmentator) durch. Die Validierungsergebnisse zeigen, dass Merlin spezifische Benchmark-Modelle bei Benchmark-Aufgaben deutlich übertrifft.
Die zugehörigen Forschungsergebnisse mit dem Titel „Merlin: ein auf Computertomographie basierendes Bild-Sprach-Grundlagenmodell und Datensatz“ wurden in Nature veröffentlicht.
Forschungshighlights:
* Diese Studie stellt Merlin vor, das erste native 3D-Bildsprache-Grundlagenmodell für abdominale CT-Scans, das die Einschränkung bisheriger Modelle überwindet, die sich nur auf 2D-Bilder konzentrierten.
* Die Studie veröffentlichte einen umfangreichen Datensatz mit 25.494 gepaarten CT-Scans des Abdomens und radiologischen Befunden und schloss damit eine Lücke im Bereich der Datensätze.
* Diese Forschung integriert auf innovative Weise strukturierte EHR-Daten und unstrukturierte radiologische Berichte als Überwachungssignale und schlägt ein mehrstufiges Vortrainingsmodell vor, das Multitasking-Lernen und phasenweises Training kombiniert.

Papieradresse:
https://www.nature.com/articles/s41586-026-10181-8
Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „Merlin“, um das vollständige PDF zu erhalten.
Schließen der Datenlücke für das Training und die Evaluierung von VLMs
Um die Lücke im Mangel an öffentlich verfügbaren abdominalen CT-Datensätzen für das Training und die Evaluierung von 3D-VLMs zu schließen, nutzte das Forschungsteam eine große Menge an konformen Daten aus realen medizinischen Zentren.Letztendlich wurde ein qualitativ hochwertiger klinischer Datensatz mit 18.321 Patienten veröffentlicht, der gepaarte CT-Scans, unstrukturierte radiologische Befunde und strukturierte elektronische Patientenakten umfasste.In:
* CT-Scandaten:
Die Daten stammen aus Ganzbauch-CT-Scans, die jeweils mehrere Sequenzen umfassen. Um den Informationsgehalt zu maximieren, wurde die Sequenz mit den meisten axialen Schichten ausgewählt. Dadurch entstanden 10.628.509 zweidimensionale Bilder aus 25.528 CT-Scans.
* Radiologischer Befund:
Die Studie erfasste die radiologischen Befunde aller CT-Untersuchungen. Diese Befunde bestehen aus mehreren Teilen, wobei die Abschnitte „Befunde“ und „Eindrücke“ die wichtigsten sind. Erstere enthalten detaillierte Beobachtungen der einzelnen Organsysteme, während letztere die wichtigsten klinischen Befunde zusammenfassen. Aufgrund der Detailtiefe der bereitgestellten Informationen und der Validität vorheriger Arbeiten wurde für das Training ausschließlich der Abschnitt „Befunde“ verwendet, der insgesamt 10.051.571 Tokens umfasste.
* EHR:
Die Daten dienten dem Training des Modells anhand von Diagnoseinformationen in Form von ICD-Codes (Internationale Klassifikation der Krankheiten), die den entsprechenden CT-Scan-Aufzeichnungen der Patienten zugeordnet waren. Der Datensatz umfasst insgesamt 954.013 ICD-9-Codes (davon 5.686 eindeutige Codes) und 2.041.280 ICD-10-Codes (davon 10.867 eindeutige Codes).
Hinsichtlich der Datenpartitionierung wurde der Trainingsdatensatz in drei Teildatenbanken unterteilt: 60% (15.331 CT-Scans), 20% (5.060 CT-Scans) und 20% (5.137 CT-Scans). Diese dienten dem Training, der Validierung bzw. dem Testen. Um zu vermeiden, wurden mehrere CT-Scans desselben Patienten nicht in derselben Teildatenbank gespeichert.
Auch,Für die externe Validierung des Experiments wurden außerdem 44.098 Datenpunkte von drei unabhängigen Institutionen herangezogen, die allesamt für die Tests verwendet wurden.Die Einzelheiten sind wie folgt:
* Externer Datensatz 1: Enthält 6.997 CT-Scans des Abdomens
* Externer Datensatz 2: Enthält 25.986 CT-Scans des Abdomens
* Externer Datensatz 3: Enthält 4.872 Abdomen-CT-Scans und 6.243 Thorax-CT-Scans.
Die beiden anderen öffentlich zugänglichen Datensätze für abdominale CT-Scans sind VerSe und TotalSegmentator. Der VerSe-Datensatz umfasst 160 CT-Scans, der TotalSegmentator-Datensatz 401. Von diesen wurden 34 Scans für das Vortraining und Testen der Vorhersage mehrerer Aufgaben und Krankheiten verwendet. Die verbleibenden 367 Scans wurden in 80% (293 Scans) für das Training und 20% (74 Scans) für die Validierung aufgeteilt.
Multitasking-Lernen und phasenweise Trainingsstrategien sowie differenzierte Lösungen gewährleisten die hohe Effizienz von Merlin.
Im Hinblick auf die Modellarchitektur,Merlin erreicht die Bild-Text-Ausrichtung durch den Einsatz einer Dual-Encoder-Architektur, die aus einem Bild-Encoder und einem Text-Encoder besteht.Der Bildkodierer verwendet I3D ResNet152, welches die Gewichte des zweidimensionalen vortrainierten Modells durch „Inflation“ wiederverwendet und in die dritte Dimension des dreidimensionalen Faltungskerns kopiert. Der in dieser Arbeit verwendete Kodierer ist Clinical Longformer, der im Vergleich zu anderen biomedizinischen vortrainierten Modellen und allgemeinen CLIP-Kodierern längere Texte verarbeiten kann. Er unterstützt 4.096 lange Kontexte und ist somit optimal auf die Anforderungen langer Textberichte abgestimmt.
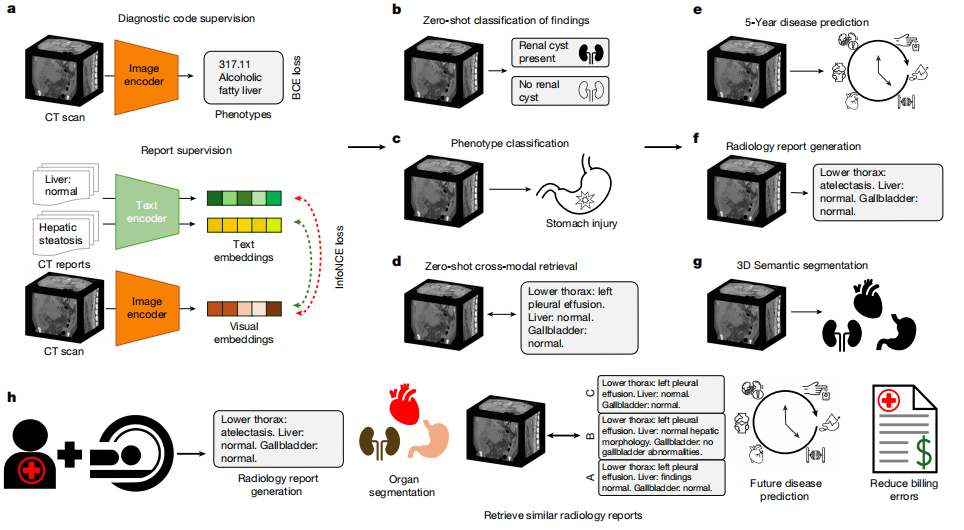
Für das Modelltraining verwendet Merlin zwei Verlustfunktionen, um die phänotypische Klassifizierung bzw. radiologische Befunde zu verarbeiten:Zur phänotypischen Klassifizierung wurde die binäre Kreuzentropie-Verlustfunktion verwendet; zur Kontrastlernung radiologischer Befunde wurde die InfoNCE-Verlustfunktion verwendet.Die Einbettungsdimension für Bilder und Text wurde einheitlich auf 512 gesetzt, analog zur Einbettungsdimension des ViT-Base-Modells in den OpenCLIP-Experimenten. Anschließend wurde Gradienten-Checkpointing für den visuellen und den Text-Encoder in der Trainingsstrategie aktiviert und ein FP16-Mixed-Precision-Training durchgeführt.
Als Optimierer wurde AdamW mit einer anfänglichen Lernrate von 1 × 10⁻⁵ und β = (0,9; 0,999) verwendet. Ein Kosinus-Lernraten-Scheduler wurde eingesetzt, der die Anzahl der Trainingsepochen, in denen die Lernrate auf 0 bis 300 abfiel, festlegte. Die Hardware bestand aus einer einzelnen 48-GB-A6000-GPU mit einer maximalen Batchgröße von 18.
Zusätzlich zum Training mit EHR-Phänotypen und radiologischen Befunden im Rahmen eines Multitasking-AnsatzesDie Studie berücksichtigte auch ein gestaffeltes Ausbildungsprogramm.Konkret wird der Merlin-Bildencoder zunächst in einem ersten Schritt mit EHR-Diagnosecodes trainiert; anschließend erfolgt in einem zweiten Schritt ein vergleichendes Training mit radiologischen Befunden. Um zu verhindern, dass die im ersten Schritt erlernten EHR-Informationen in Vergessenheit geraten, wird die phänotypische Verlustfunktion im zweiten Trainingsschritt mit geringeren Gewichtungen verwendet.
Die erste Stufe verwendet den AdamW-Optimierer mit einer anfänglichen Lernrate von 1 x 10⁻⁴, β = (0,9, 0,999), einen exponentiellen Lernraten-Scheduler mit γ = 0,99 und eine einzelne A6000-GPU mit einer Batchgröße von 22. Die in der zweiten Stufe verwendeten Hyperparameter sind die gleichen wie diejenigen, die beim Multi-Task-Training verwendet werden.
Zusammenfassend lässt sich sagen, dass Multitasking-Lernen und phasengesteuertes Training differenzierte Designs für die beiden Strategien ermöglichen und das Forschungsteam Verbesserungen zur Vermeidung von Vergessen beim phasengesteuerten Training erzielt hat. Diese differenzierte Trainingsstrategie ist das Kerndesign, das die Effizienz und Genauigkeit von Merlin gewährleistet und in nachfolgenden Ablationsversuchen weiter validiert wurde.
Eine umfassende Auswertung von 752 Aufgabenkategorien zeigt, dass Merlin alle anderen übertrifft.
Im Rahmen des experimentellen Prozesses führte das Forschungsteam eine interne Validierung auf Basis von 5.137 CT-Scans und eine externe Validierung auf Basis von 44.098 CT-Scans sowie zwei öffentlich verfügbaren Datensätzen (VerSe und TotalSegmentator) durch, wobei der Schwerpunkt auf abdominalen CT-Scans lag.Es gibt insgesamt 6 Hauptkategorien von Bewertungsaufgaben mit insgesamt 752 spezifischen Teilaufgaben.Zu den wichtigsten Aufgabenkategorien gehören Zero-Shot-Klassifizierung (31 Unteraufgaben), phänotypische Klassifizierung (692 Unteraufgaben), Zero-Shot-Crossmodal-Retrieval (23 Unteraufgaben), 5-Jahres-Krankheitsvorhersage (6 Unteraufgaben), Erstellung von Radiologieberichten und 3D-Segmentierung.
Im Rahmen der Zero-Shot-Klassifizierung der Befunde wurden 30 abdominale CT-Scans aus internen und externen klinischen Daten analysiert.Merlin erzielte einen F1-Score von 0,741 auf dem internen Validierungsdatensatz (Konfidenzintervall von 95%, 0,727–0,755) und einen durchschnittlichen F1-Score von 0,647 auf dem externen Validierungsdatensatz (Konfidenzintervall von 95%, 0,607–0,678).Diese Werte waren signifikant höher als die des 2D-OpenCLIP-Modells mit k=1-Pooling und des feinabgestimmten 2D-BioMedCLIP-Modells mit Average-Pooling (P < 0,001). Siehe Abbildung unten:
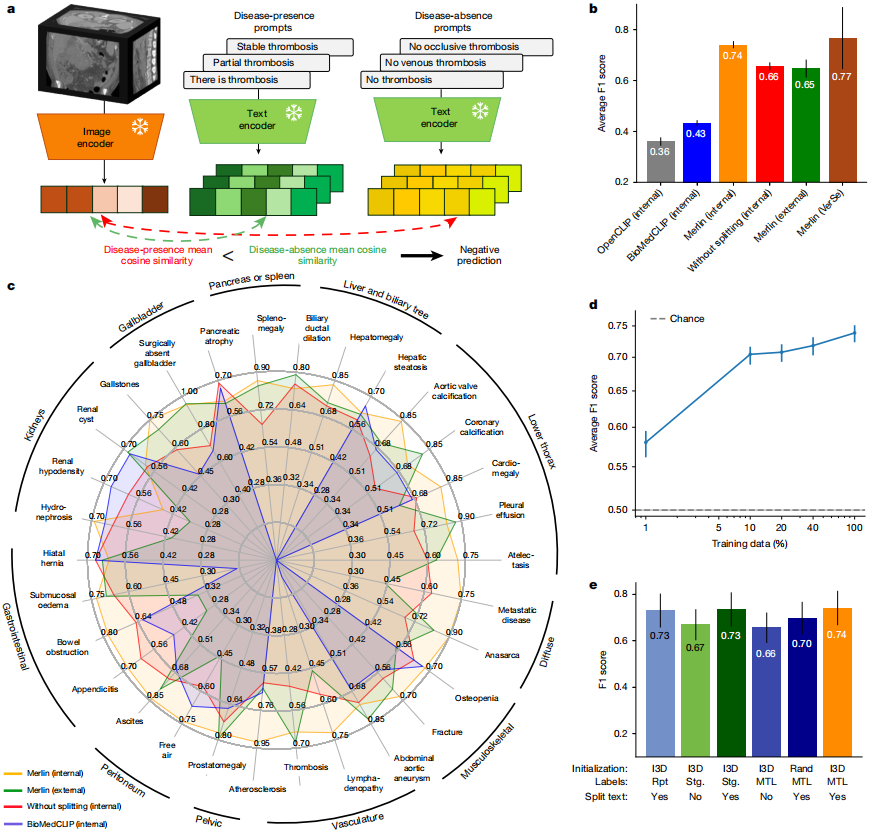
Aus qualitativer Sicht,Merlin erzielt auch bei externen Datensätzen für Krankheiten mit signifikanten Merkmalen, wie z. B. Pleuraerguss und Aszites, eine hohe Leistungsfähigkeit.Die Leistungsfähigkeit nimmt jedoch bei der Erkennung feiner Merkmale wie Appendizitis und Lymphadenopathie leicht ab. Ohne Segmentierung des radiologischen Befundes erreichte Merlin auf dem externen Evaluierungsdatensatz einen durchschnittlichen F1-Score von 0,656 (Konfidenzintervall 95%).
Im Ablationsexperiment VergleichDas Merlin-Modell, das mit einem erweiterten 3D-Netzwerk initialisiert wird, weist die beste Leistung auf.Der F1-Score betrug 0,741 (Konfidenzintervall 95%: 0,727–0,755). Bei Segmentierung der Radiologieberichte lag der Modell-Score unter Einbeziehung von EHR-Daten und Radiologieberichten bei 0,735 (Konfidenzintervall 95%: 0,719–0,748). Das Modell, das ausschließlich Radiologieberichte nutzte und eine Berichtssegmentierung implementierte, erreichte mit einem F1-Score von 0,730 (Konfidenzintervall 95%: 0,714–0,744) den dritten Platz. Die Segmentierung der Radiologieberichte hatte den größten Einfluss auf die Modellleistung; ohne Berichtssegmentierung sank der F1-Score des Merlin-Modells im Durchschnitt um 7,9 Punkte (p < 0,01).
Erwähnenswert ist auch, dassZero-Shot Merlin übertrifft alle überwachten Vergleichsmethoden in überwachten Experimenten sowohl auf dem 10%- als auch auf dem 100%-Trainingsdatensatz.Bei Verwendung von 100% Trainingsdaten verbesserte sich der F1-Score um 29%, während er sich bei Verwendung von 10% Trainingsdaten sogar um 45% verbesserte. Experimente zeigen, dass Zero-Shot Merlin mit 100% Trainingsdaten Supervised Merlin deutlich übertrifft und den F1-Score um 16% verbessert.
Im Rahmen der Phänotypklassifizierung wurde die Leistung von Merlin bei der Vorhersage von 692 klinischen Phänotypen, die durch PheWAS definiert wurden, evaluiert. Dabei wurde eine mittlere Fläche unter der ROC-Kurve (AUROC) von 0,812 (95%-Konfidenzintervall: 0,808–0,816) erzielt. Insgesamt wiesen 258 Phänotypen AUROC-Werte über 0,85 und 102 Phänotypen AUROC-Werte über 0,9 auf. (Siehe Abbildung unten.)
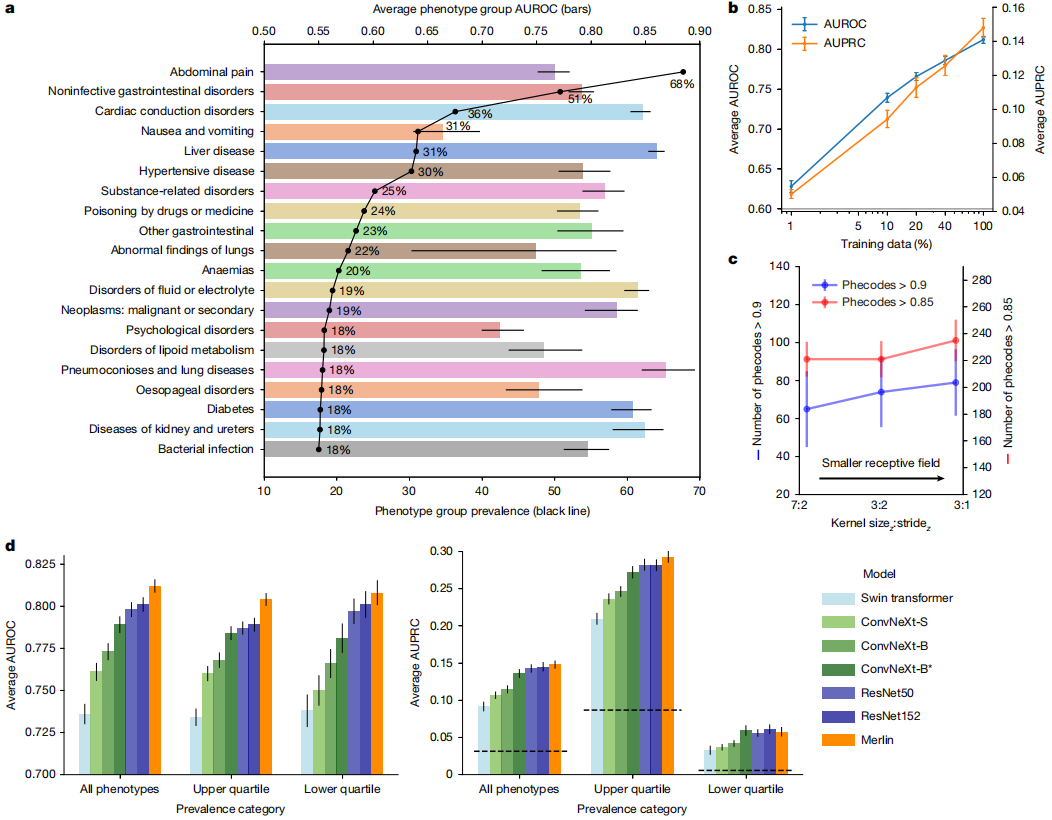
Bei der Analyse der 20 häufigsten Phänotypen mit den höchsten Inzidenzraten in internen Tests,Merlin zeichnet sich durch seine Fähigkeit aus, Erkrankungen mehrerer Organsysteme zu erkennen, darunter Leber, Nieren, Harnleiter und Magen-Darm-Trakt.
Bei der Zero-Shot-Cross-Model-Retrieval-Aufgabe besteht der erste Schritt aus einer Retrieval-Aufgabe, die auf der "Bilderkennung" mit 64 Fällen basiert.Merlin weist gegenüber OpenCLIP und BioMedCLIP deutliche Vorteile auf.Dies ist dem von Merlin verwendeten Text-Encoder Clinical Longformer zu verdanken, während OpenCLIP und BioMedCLIP maximale Token-Längen von 77 bzw. 256 Zeichen zulassen. Umgekehrt konnte Merlins hervorragende Leistung auch bei der Suche nach Bildern im Rahmen der „Discovery-Image“-Aufgabe anhand von 64 Fällen reproduziert werden. Siehe Abbildung unten:
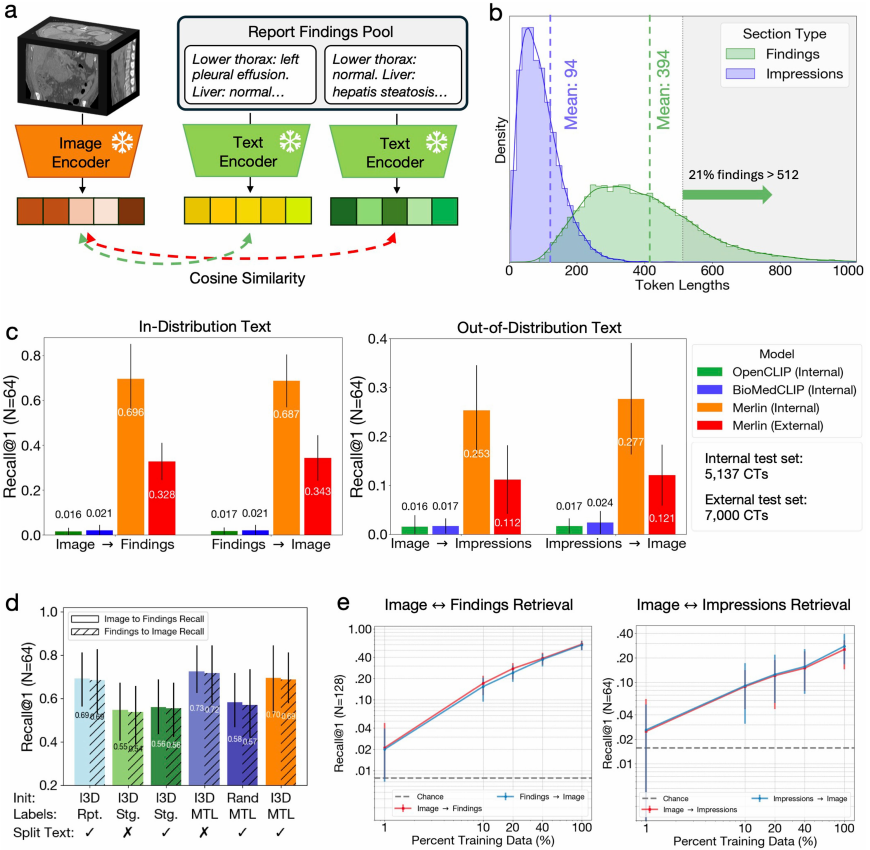
Ein wichtigerer Beweis ist, dass Merlin, selbst wenn er nur die im Bericht objektiv beschriebenen "Ergebnisse" für das Training zur visuellen Sprachausrichtung verwendet,Selbst bei der Verarbeitung stark verallgemeinerter Berichte („Eindrücke“) zeigt das System noch immer ein hohes Maß an domänenübergreifender Generalisierungsfähigkeit.Die Ergebnisse wurden anschließend in einer Reverse-Engineering-Aufgabe erneut verifiziert. Obwohl die Retrieval-Leistung von Merlin auf dem externen Testdatensatz im Vergleich zum internen Testdatensatz abnahm, war sie dennoch 5- bis 7-mal besser als die anderer externer Vergleichsmodelle.
Im Rahmen der Aufgabe zur Vorhersage mehrerer Krankheiten über einen Zeitraum von fünf Jahren wurde die Fähigkeit von Merlin zur Vorhersage des Risikos gesunder Patienten, innerhalb der nächsten fünf Jahre mehrere schwere chronische Krankheiten zu entwickeln, bewertet. Zu diesen Krankheiten zählten chronische Nierenerkrankungen, Osteoporose, Herz-Kreislauf-Erkrankungen, ischämische Herzkrankheit, Bluthochdruck und Diabetes.
Nach Feinabstimmung von Merlin und Verwendung des Downstream-Labels 100% erreichte der AUROC-Wert für die Vorhersage der Krankheitsinzidenz innerhalb von fünf Jahren 0,757 (Konfidenzintervall von 95%, 0,743-0,772).Diese Leistung ist um 71 TP3T höher als die des ImageNet-vortrainierten (I3D)-Modells, das nur Bilder verwendet.Selbst bei Verwendung von nur 10%-Labels erreicht Merlin für die Vorhersage der Krankheitsinzidenz innerhalb von fünf Jahren noch einen AUROC-Wert von 0,708 (Konfidenzintervall von 95%: 0,692–0,723) und übertrifft damit den Wert des mit ImageNet vortrainierten Modells von 4,4%. Siehe Abbildung unten:
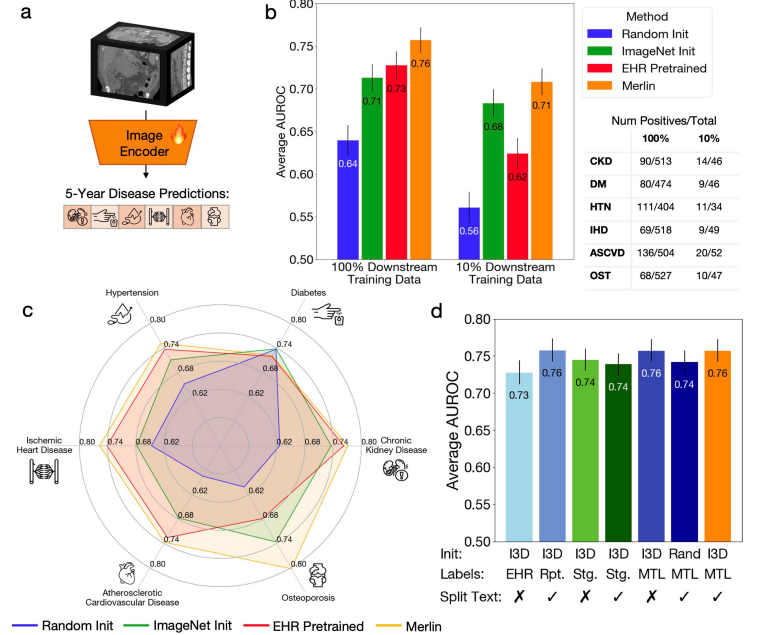
Zusätzlich,Selbst bei Verwendung von nur 1/10 der Trainingsdaten ist die Vorhersageleistung von Merlin vergleichbar mit der eines ImageNet-vorabtrainierten Modells, das mit 100% Daten trainiert wurde.Dies beweist eindrucksvoll Merlins Fähigkeit zum Nullschuss und seine hohe Übertragbarkeit.
Bei der Erstellung von radiologischen Befunden, im Vergleich zum Basismodell RadFM, in Tests, die auf quantitativen Metriken wie RadGraph-F1, BERT Score, ROUGE-2 und BLEU basieren,Merlin ist dem Vorgänger in allen Aspekten der anatomisch-logischen Struktur und der vollständigen Berichtsergebnisse überlegen.
Qualitativ liefert Merlin exzellente Berichte mit hochpräzisen Diagnosen, Lokalisierungen und Symptombeschreibungen. Gelegentlich trifft Merlin jedoch konservative Einschätzungen, beispielsweise bei der Unterbewertung von Befunden in manuell erstellten und CT-basierten Berichten. Dies ist auf die frühen Demonstrationen von aus CT-Scans generierten radiologischen Berichten zurückzuführen und wird sich mit steigender Berichtsqualität weiter verbessern.
Bei der semantischen 3D-Segmentierungsaufgabe übertrifft Merlin das nnUNet-Framework um 4,71 TP3T im makro-durchschnittlichen Dice-Koeffizienten, wenn nur 101 TP3T Trainingsdaten verwendet werden; bei Verwendung von 1001 TP3T Trainingsdaten schneidet das nnUNet-Framework etwas besser ab als das ursprüngliche Modell von Merlin, aber der Unterschied im Dice-Koeffizienten beträgt nur 0,006.
Bei 20 Organen im Testdatensatz erzielte Merlin höhere Dice-Werte als das nnUNet-Framework bei 12 Organen, wenn es mit 10%-Daten trainiert wurde, mit einer Verbesserung von bis zu 41% bei der Prostata-Segmentierung.
Darüber hinaus evaluierte das Forschungsteam Merlin in externen Validierungsstudien anhand von insgesamt 44.098 externen CT-Scans unter Verwendung eines Datensatzes von über 100.000 externen CT-Scans.Es zeigt eine stabile und genaue Leistung über verschiedene Standorte und anatomische Regionen hinweg und überwindet so die Verteilungsabweichung zwischen dem Trainingsdatensatz und dem externen Testdatensatz.Darüber hinaus übertraf seine Leistung durchweg andere Basismodelle und übertraf bei Aufgaben im Brustbereich sogar spezialisierte CT-Basismodelle für den Brustkorb.
Visuelle Sprachmodelle erschließen das Potenzial multimodaler medizinischer Daten in großem Umfang.
Neben dieser Studie werden fortlaufend weitere Fortschritte bei visuellen Sprachmodellen in der Medizin erzielt. So hat beispielsweise ein Forschungsteam der Stanford University einen multimodalen Transformer mit einheitlicher maskierter Modellierung (MUSK) vorgeschlagen. Dieser stellt ebenfalls ein Basismodell visueller Sprache dar und zielt darauf ab, umfangreiche, unbeschriftete und unverbundene Bild- und Textdaten zu integrieren.
Titel des Papers: Ein Bild-Sprach-Grundlagenmodell für die Präzisionsonkologie
Papieradresse:
https://www.nature.com/articles/s41586-024-08378-w
Das wissensbasierte, fallbasierte Modell KEEP, entwickelt von der Shanghai Jiao Tong University und anderen, adressiert das Problem, dass aktuelle Modelle primär datengetriebene Ansätze verfolgen und medizinisches Wissen nicht explizit integrieren. KEEP nutzt einen umfassenden Krankheitswissensgraphen mit 11.454 Krankheiten und 139.143 Attributen, um Millionen pathologischer Bild-Text-Paare in 143.000 semantisch strukturierte Gruppen zu reorganisieren, die der Krankheitsontologiehierarchie entsprechen. Diese wissensbasierte Vortrainingsmethode gleicht visuelle und textuelle Repräsentationen in einem hierarchischen semantischen Raum ab und ermöglicht so ein tiefes Verständnis von Krankheitsbeziehungen und morphologischen Mustern.
Titel der Dissertation: Wissensbasierte Vorschulung für ein Grundlagenmodell der visuell-sprachlichen Pathologie zur Krebsdiagnose
Papieradresse:
https://www.sciencedirect.com/science/article/pii/S1535610826000589
Zusammenfassend lässt sich sagen, dass visuelle Sprachmodelle mit ihren multimodalen Analysefähigkeiten ein enormes Potenzial in der Medizin und Radiologie aufweisen. Sie können medizinische Bilder, Fallberichte und klinische Leitlinien integrieren, um eine intelligente Läsionserkennung, Unterstützung bei der Fallanalyse und die automatische Erstellung von Diagnoseberichten zu ermöglichen. Dies bietet Ärzten nicht nur effiziente Hilfsmittel, sondern eröffnet auch neue Perspektiven für die Krankheitsvorhersage und beschleunigt den Wandel der modernen Medizin von einer erfahrungsbasierten zu einer datenbasierten Herangehensweise.








